java爬去指定网页的内容_JAVA使用Gecco爬虫 抓取网页内容(示例代码)
JAVA 爬虫工具有挺多的,但是Gecco是一个挺轻量方便的工具。
先上项目结构图。
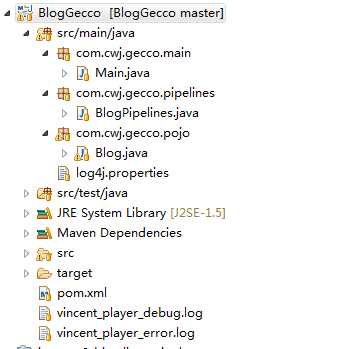
这是一个 JAVASE的 MAVEN 项目,要添加包依赖,其他就四个文件。log4j.properties 加上三个java类。
1、先配置log4j.properties
log4j.rootLogger =error,stdout,D,E
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern= [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
log4j.appender.D=org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File=vincent_player_debug.log
log4j.appender.D.Append= truelog4j.appender.D.Threshold=DEBUG
log4j.appender.D.layout=org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern= %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
log4j.appender.E=org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File=vincent_player_error.log
log4j.appender.E.Append= truelog4j.appender.E.Threshold=ERROR
log4j.appender.E.layout=org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern= %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
2、接下来着手写Blog.java,里面都有注释 不解释
packagecom.cwj.gecco.pojo;importcom.geccocrawler.gecco.annotation.Gecco;importcom.geccocrawler.gecco.annotation.HtmlField;importcom.geccocrawler.gecco.annotation.Request;importcom.geccocrawler.gecco.request.HttpRequest;importcom.geccocrawler.gecco.spider.SpiderBean;/***@authorcwj
* 2017年8月6日
* Blog实体类,运行主函数从这里开始解析
* matchUrl:要抓包的目标地址
* pipelines:跳转到下个pipelines*/@Gecco(matchUrl="http://www.cnblogs.com/boychen/p/7226831.html",pipelines="blogPipelines")public class Blog implementsSpiderBean{/*** 向指定URL发送GET方法的请求*/@RequestprivateHttpRequest request;/*** 抓去这个路径下所有的内容*/@HtmlField(cssPath= "body div#cnblogs_post_body")privateString content;publicHttpRequest getRequest() {returnrequest;
}public voidsetRequest(HttpRequest request) {this.request =request;
}publicString getContent() {returncontent;
}public voidsetContent(String content) {this.content =content;
}
}
3、BlogPipelines.java
packagecom.cwj.gecco.pipelines;importcom.cwj.gecco.pojo.Blog;importcom.geccocrawler.gecco.annotation.PipelineName;importcom.geccocrawler.gecco.pipeline.Pipeline;/***@authorcwj
* 2017年8月6日
* 运行完Blog.java 根据@PipelineName 来这里*/@PipelineName(value="blogPipelines")public class BlogPipelines implements Pipeline{/*** 将抓取到的内容进行处理 这里是打印在控制台*/
public voidprocess(Blog blog) {
System.out.println(blog.getContent());
}
}
4、最后便是在main中调用
packagecom.cwj.gecco.main;importcom.geccocrawler.gecco.GeccoEngine;public classMain {public static voidmain(String[] args) {
GeccoEngine.create()//工程的包路径
.classpath("com.cwj.gecco")//开始抓取的页面地址
.start("http://www.cnblogs.com/boychen/p/7226831.html")//开启几个爬虫线程
.thread(10)//单个爬虫每次抓取完一个请求后的间隔时间
.interval(5)//使用pc端userAgent
.mobile(false)//开始运行
.run();
}
}
5、抓取到内容,日志文件被我删除 有警告
附上源码地址 https://github.com/BeautifulMeet/Gecco
java爬去指定网页的内容_JAVA使用Gecco爬虫 抓取网页内容(示例代码)相关推荐
- python网页数据存入数据库_python网络爬虫抓取动态网页并将数据存入数据库MySQL...
简述 以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网 ...
- java抓取网页代码_java 抓取网页内容实现代码
复制代码 代码如下: package test; import java.io.BufferedReader; import java.io.IOException; import java.io.I ...
- java 输出字符集合里的字_Java基础 -- 字符串(格式化输出、正则表达式)(示例代码)...
一 字符串 1.不可变String String对象是不可变的,查看JDK文档你就会发现,String类中每一个看起来会修改String值的方法,实际上都是创建一个全新的String对象,以包含修改后 ...
- java利用htmlparser得到网页html内容
java利用htmlparser得到网页html内容,利用org.htmlparser.Parser包我们可以很轻松取到任何页面的源代码,方法如下: /*** 返回网页内容* * @param pat ...
- requests.get()爬去中文网页乱码解决方法
requests.get()爬去中文网页乱码解决方法 当我们使用requests.get()爬取百度首页时会发现,返回的html代码中的中文发生乱码. import requestsheaders = ...
- java爬虫抓取网页数据论坛_Java爬虫抓取网页
Java爬虫抓取网页原作者:hebedich 原文链接 下面直接贴代码: import java.io.BufferedReader; import java.io.InputStreamReade ...
- java socket抓取资源_Java 通过 Socket 的形式抓取网页内容
package com.hmw.net; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.IO ...
- Java爬虫抓取网页
Java爬虫抓取网页 原作者:hebedich 原文链接 下面直接贴代码: import java.io.BufferedReader; import java.io.InputStreamRead ...
- java抓取页面表格_用java实现爬虫抓取网页中的表格数据功能源码
[实例简介] 使用java代码基于MyEclipse开发环境实现爬虫抓取网页中的表格数据,将抓取到的数据在控制台打印出来,需要后续处理的话可以在打印的地方对数据进行操作.包解压后导入MyEclipse ...
最新文章
- 熟悉scala命令,scala语言运行超级素数和猴子大王
- C++ ODB 框架(未实践使用)
- 怎么查看linux是不是as7u4,Linux下搭建Android开发环境
- clipboard_monitor_in_win7
- 学习动态性能表(20)--v$waitstat
- PTA 1002 Business (35分)
- js有默认参数的函数加参数_函数参数:默认,关键字和任意
- 信息学奥赛一本通C++语言——1110:查找特定的值
- STM32工作笔记0062---定时器中断实验
- [学习笔记]拉格朗日中值定理
- 安装mysql输入_安装mysql
- 数据库:数据库设计与数据建模及建模工具(PowerDesigner)
- 禁用电子邮件服务器,启用或禁用对邮箱中的邮箱的 POP3 或 IMAP4 Exchange Server
- ORAN专题系列-19:5G O-RAN FrontHaul前传接口M Plane互操作性测试IOT规范
- 基于php047园林植物检索系统网站
- 【微信小程序】获取用户手机号的实现
- 数据库:关系模型基本介绍
- ElasticSearch 使用教程之_score(评分)介绍
- UCOS-III笔记
- 机器学习基础概念——过拟合和欠拟合
热门文章
- WordPress编辑器支持Word文档一键粘贴
- 2022年初级会计职称考试经济法基础练习题及答案
- 2021年初级会计职称《初级会计实务》考试真题和答案
- showdialog wpf 如何关闭_使用ShowDialog()阻止所有其他Windows的WPF模态窗口
- Itext实现pdf文件Encryption
- 【场景图生成】Unbiased Scene Graph Generation from Biased Training
- ZOJ-4107 Singing Everywhere 2019浙江省省赛
- 电视和计算机屏幕有哪三中颜色组成,合成彩色电视机和计算机屏幕上艳丽画面的色光是:[]A.红、绿、蓝...
- 40k~65k, 区块链架构师技能包一览: 多语言、多平台、多算法...别慌, 先投简历再说...
- 践行公益担当 | 关爱留守儿童,暖到“心理”