t-sql执行结果_解释T-SQL查询的执行计划
t-sql执行结果
In this article, we will analyze a simple T-SQL query execution plan with different aspects. This will help us to improve our practical skills instead of discussing theoretical knowledge.
在本文中,我们将分析一个具有不同方面的简单T-SQL查询执行计划。 这将帮助我们提高实践技能,而无需讨论理论知识。
The execution plan is a very significant point to figure out what is going on behind the query execution process. For this reason, if we want to boost the performance of a query in which we experience poor performance, we need to understand clearly what this guide tells us. In fact, execution plans are an output of the query optimizer, so we’ll try to understand how the query optimizer behaves. Firstly, let’s go over some of the main concepts that will be used in this article.
执行计划对于弄清楚查询执行过程背后发生的情况非常重要。 因此,如果我们要提高性能差的查询的性能,则需要清楚地了解本指南告诉我们的内容。 实际上,执行计划是查询优化器的输出,因此我们将尝试了解查询优化器的行为。 首先,让我们研究一下本文将要使用的一些主要概念。
什么是Transact-SQL(T-SQL)? (What is Transact-SQL (T-SQL)?)
SQL stands for Structured Query Language and is designed to query the database system, and it is also compliant with the ANSI standard. However, Transact-SQL (T-SQL) is an advanced form of the SQL language that is particularly used to query Microsoft SQL databases.
SQL代表结构化查询语言 ,旨在查询数据库系统,并且还符合ANSI标准。 但是, Transact-SQL(T-SQL)是SQL语言的高级形式,特别用于查询Microsoft SQL数据库。
什么是查询优化器? (What is a query optimizer?)
The query optimizer is a very crucial component of the database engine that analyzes queries and tries to generate effective (optimal) execution plans. Every executed query will consume resources, such as I/O, CPU, Memory. The optimizer calculates the estimated cost of these resources and chooses an optimum query plan based on this calculation.
查询优化器是数据库引擎中非常关键的组件,它分析查询并尝试生成有效的(最佳)执行计划。 每个执行的查询都会消耗资源,例如I / O,CPU,内存。 优化器计算这些资源的估计成本,并根据此计算选择最佳查询计划。
什么是执行计划? (What is an Execution Plan?)
The execution plan can be thought of as a flight data recorder that tells us the execution details of a query. The actual execution plan generated after a query includes detailed information about the runtime metrics. On the other hand, a query optimizer can create a query plan based on the estimation method, and this query plan is called an Estimated Execution Plan.
可以将执行计划看作是飞行数据记录器,它告诉我们查询的执行细节。 查询后生成的实际执行 计划包括有关运行时指标的详细信息。 另一方面,查询优化器可以基于估计方法创建查询计划,该查询计划称为估计执行 计划 。
如何显示执行计划? (How to display an execution plan?)
We can enable the Actual Execution Plan of a query on the SQL Server Management Studio (SSMS) toolbar. Only we need to click the Include Actual Execution Plan button, as shown below, or we can press the Ctrl+M key combination at the same time.
我们可以在SQL Server Management Studio(SSMS)工具栏上启用查询的实际执行计划。 如下所示,只需要单击“ 包括实际执行计划”按钮,或者可以同时按Ctrl + M组合键。

After the execution of the query, we can see the actual execution plan.
执行完查询后,我们可以看到实际的执行计划。
先决条件 (Pre-requisites )
In this article, we will use a very simple table that can be created through the following T-SQL query.
在本文中,我们将使用可以通过以下T-SQL查询创建的非常简单的表。
CREATE TABLE TestTable
(Id INTPRIMARY KEY IDENTITY(1, 1), CityName VARCHAR(100), CountryName VARCHAR(100))
Tip: Primary Key constraint is a column or set of columns that uniquely identify the rows in the table. When we create a Primary Key constraint on the table, the clustered index will be created automatically for the underlined table if we don’t explicitly specify it as a unique nonclustered index. You can refer to Learn SQL: Primary Key article to learn more details about the primary key.
提示: 主键约束是一列或一组列,它们唯一地标识表中的行。 当我们在表上创建主键约束时,如果未将其显式指定为唯一的非聚集索引,则会为带下划线的表自动创建聚集索引。 您可以参阅“ 学习SQL:主键”一文,以了解有关主键的更多详细信息。
I used ApexSQL Generate to generate 1M test data for this table, and it only takes 2.27 seconds.
我使用ApexSQL Generate生成此表的1M测试数据,仅需2.27秒。
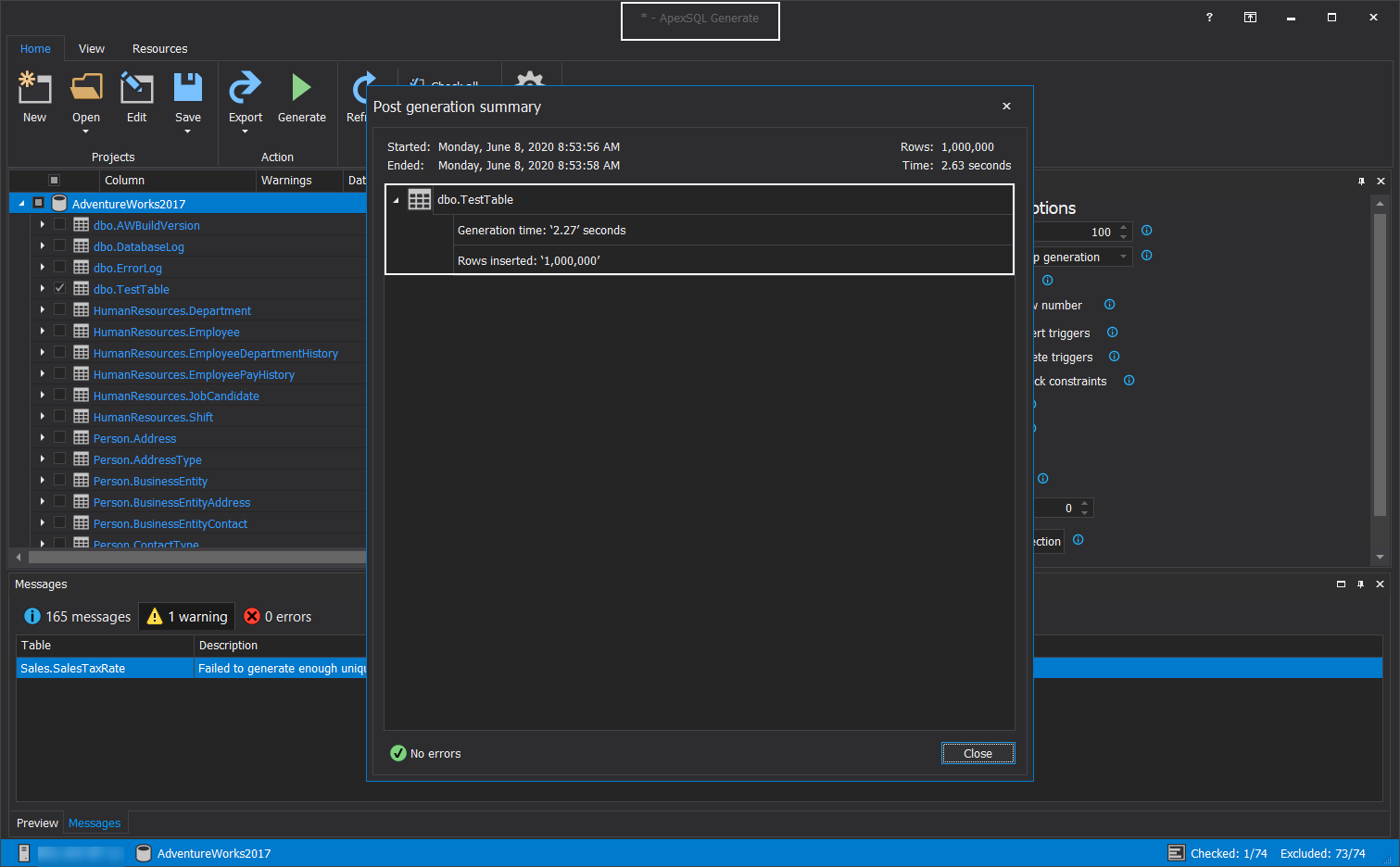
什么是聚簇索引查找和聚簇索引扫描运算符? (What is the clustered index seek and clustered index scan operators?)
A clustered index stores data of the rows’ in a logical sorted structure, so it is a very efficient way to read the rows using the clustered index structure. This data accessing method is called a clustered index seek. For example, the following query pinpoints the qualified rows using the clustered index seek operator.
聚簇索引以逻辑排序的结构存储行的数据,因此这是一种使用聚簇索引结构读取行的非常有效的方法。 这种数据访问方法称为聚簇索引查找。 例如,以下查询使用聚簇索引查找运算符精确定位合格的行。
SELECT CityName , CountryName from TestTableWHERE Id BETWEEN 2000 AND 30000
When we hover over the clustered index seek operator, a pop-up form will appear that involves detailed information about the index seek operator. In this form, the Number of Rows Read property indicates the total number of the rows which are read by the operator.
当我们将鼠标悬停在聚集的索引查找运算符上时,将出现一个弹出表单,其中包含有关索引查找运算符的详细信息。 以这种形式,“ 读取的行数”属性指示操作员读取的行的总数。
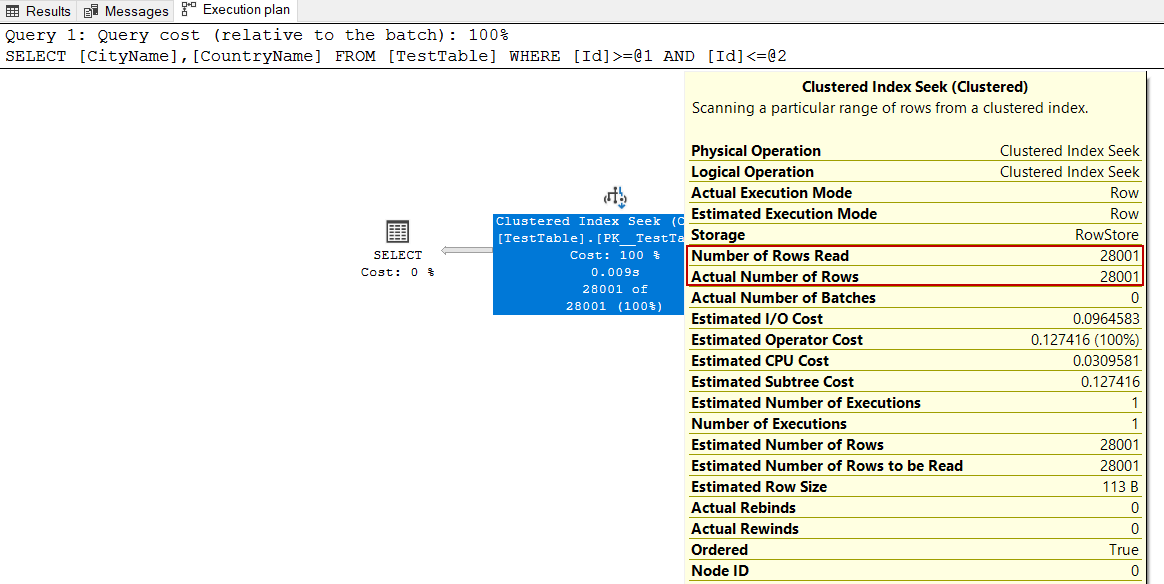
Particularly for this T-SQL query, the “Number of Rows Read” property value and the “Actual Number of Rows” property value is equal, so the index seeks operator has not performed unnecessary read. As a result, we can say that the clustered index seek operator is an efficient way to read the rows.
特别是对于此T-SQL查询,“读取的行数”属性值和“实际的行数”属性值相等,因此索引查找运算符未执行不必要的读取。 结果,我们可以说聚簇索引查找运算符是一种读取行的有效方法。
On the other hand, the query optimizer reads all clustered index pages to find the appropriate rows, and this operation is called a clustered index scan. Now we will execute the following query and analyze the execution plan.
另一方面,查询优化器读取所有聚簇索引页面以查找适当的行,此操作称为聚簇索引扫描。 现在,我们将执行以下查询并分析执行计划。
SELECT CountryName from TestTableWHERE CountryName LIKE 'A%'
When we take a glance at the Number of Rows Read attribute value of the clustered index scan operator, we will see that this operator reads 1M rows, which means it reads the whole rows of the tables, but it only transfers 62000 qualified rows into the next operator.
当我们看一看聚簇索引扫描运算符的“读取的行数”属性值时,我们将看到该运算符读取1M行,这意味着它将读取表的整个行,但仅将62000个合格的行传输到表中。下一个运算符。
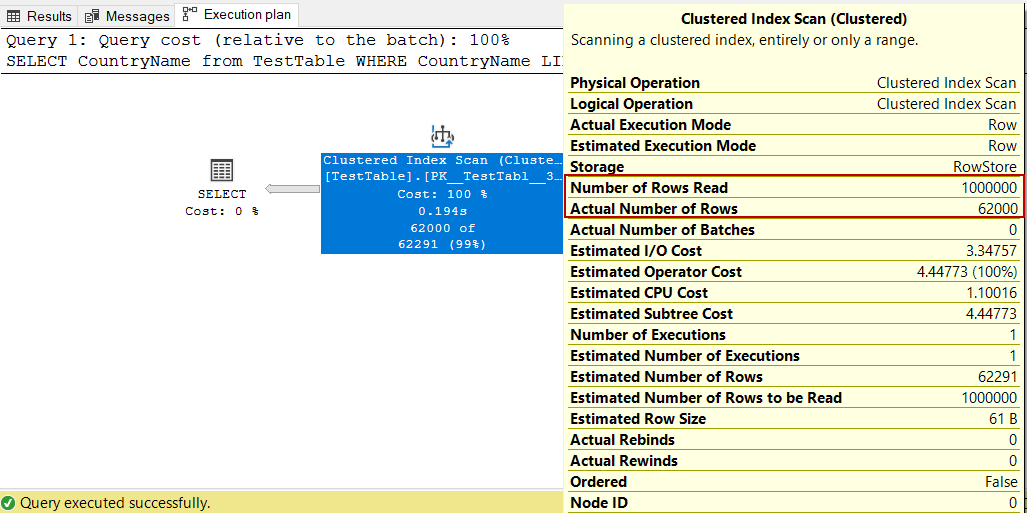
As a result, we can say that the clustered index scan operator touches every row of the table.
结果,我们可以说聚簇索引扫描运算符触及表的每一行。
什么是微不足道的执行计划? (What is a trivial execution plan?)
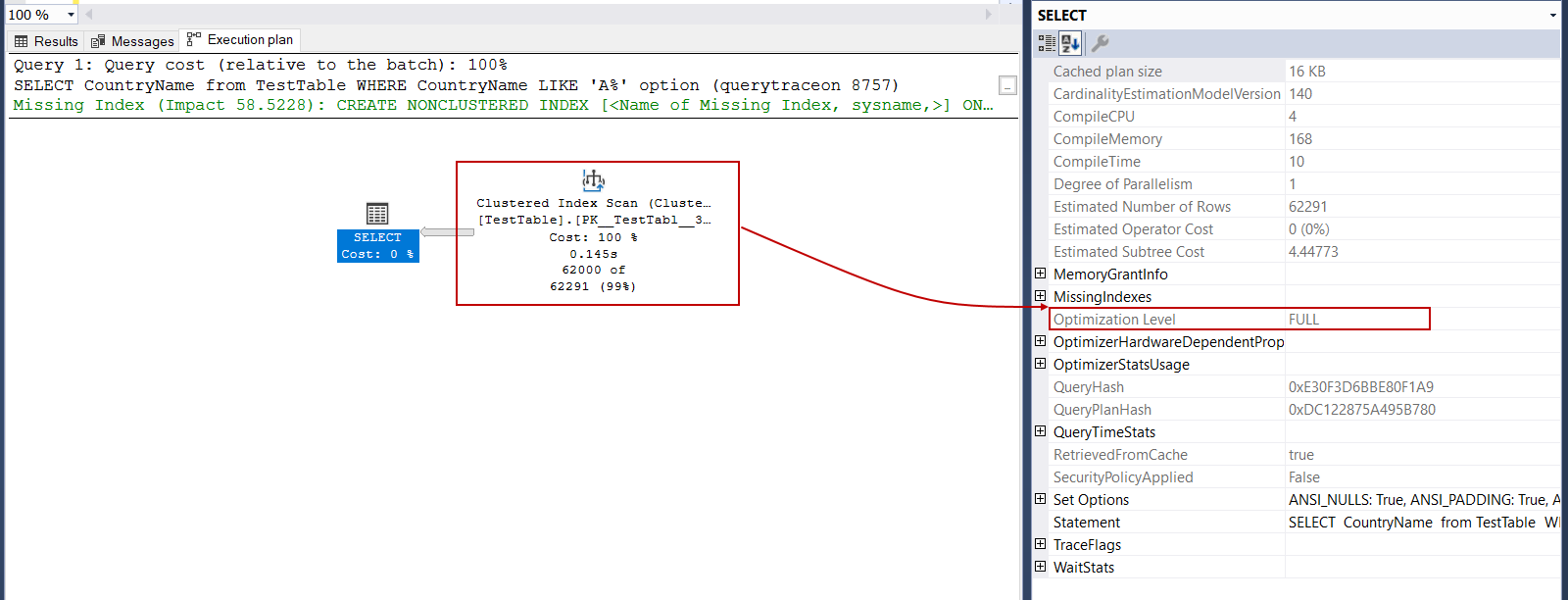
Query optimizer decides to create a trivial execution plan when a query is pretty simple so that it avoids consuming time to find out an effective execution plan. When we re-analyze the above query plan of the above query, the optimizer has generated a trivial execution plan. The Optimization Level attribute value shows clearly this situation.
当查询非常简单时,查询优化器决定创建一个简单的执行计划,从而避免浪费时间查找有效的执行计划。 当我们重新分析以上查询的以上查询计划时,优化器生成了一个简单的执行计划。 优化级别属性值清楚地显示了这种情况。
In fact, query optimizer valid reason to create a trivial query plan because it has only one option to use to access the data of the TestTable. However, a trivial plan does not offer any missing index recommendations because it skips some of the query optimization phases. Trace flag 8757 can be used to eliminate trivial execution plan and force the optimizer to complete the full cycle of the query optimization process. Now we will use trace flag 8757 to our example T-SQL query.
实际上,查询优化器创建琐碎查询计划的合理理由是,它只有一个选项可用于访问TestTable的数据。 但是,普通计划不会提供任何缺少的索引建议,因为它跳过了某些查询优化阶段。 跟踪标志8757可用于消除琐碎的执行计划,并迫使优化器完成查询优化过程的整个周期。 现在,我们将对示例T-SQL查询使用跟踪标志8757。
SELECT CountryName
FROM TestTable
WHERE CountryName LIKE 'A%'
OPTION(QUERYTRACEON 8757);
什么是基数估计?
(What is the Cardinality Estimation?
)
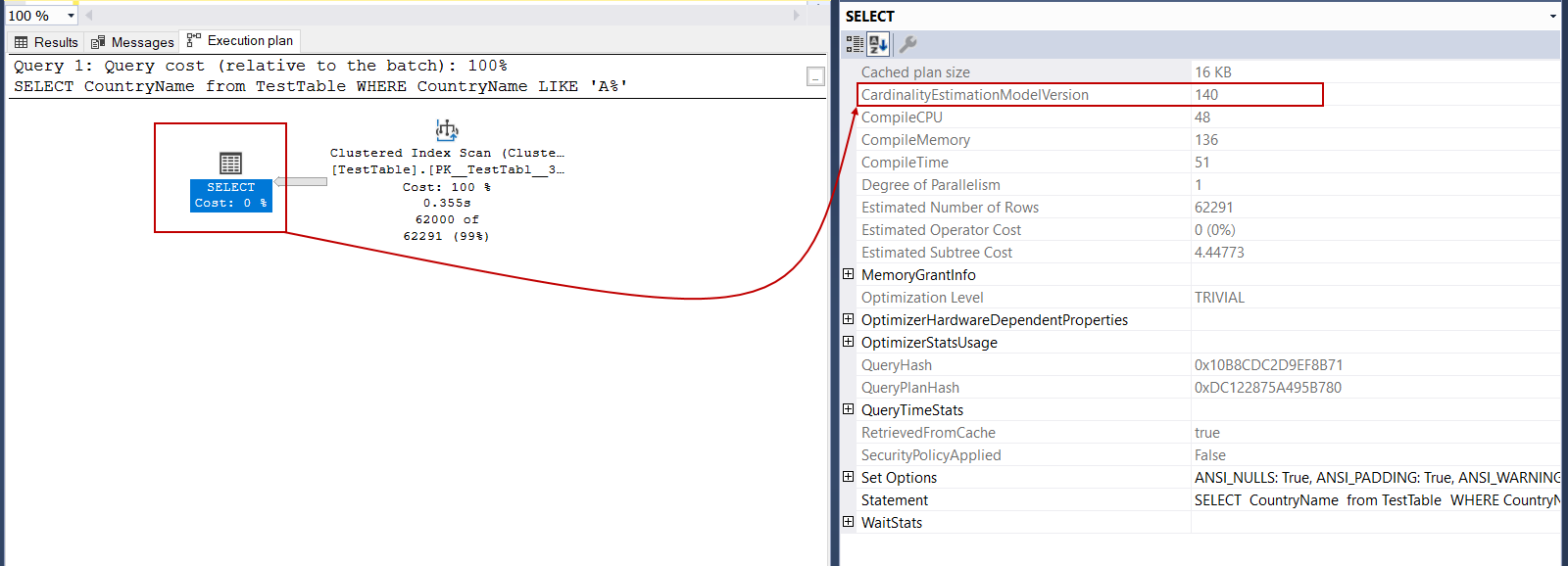
The query optimizer uses statistics to estimate how many rows are returned from each operator of the query plan. According to this estimation, optimizer calculates the total cost of the (CPU, I/O, Memory) T-SQL query. In this context, the more accurate estimations help to obtain effective query plans for the optimizer. The CardinalityEstimationModelVersion indicates the version of the cardinality estimator. For our example, CardinalityEstimationModelVersion value is 140, and it shows we are executing the query under the SQL Server 2017.
查询优化器使用统计信息来估计从查询计划的每个运算符返回多少行。 根据此估计,优化器将计算(CPU,I / O,内存)T-SQL查询的总成本。 在这种情况下,更准确的估算有助于为优化器获取有效的查询计划。 CardinalityEstimationModelVersion指示基数估计量的版本。 对于我们的示例,CardinalityEstimationModelVersion值为140,它表明我们正在SQL Server 2017下执行查询。
什么是并行执行计划?
(What is the parallel execution plan?
)
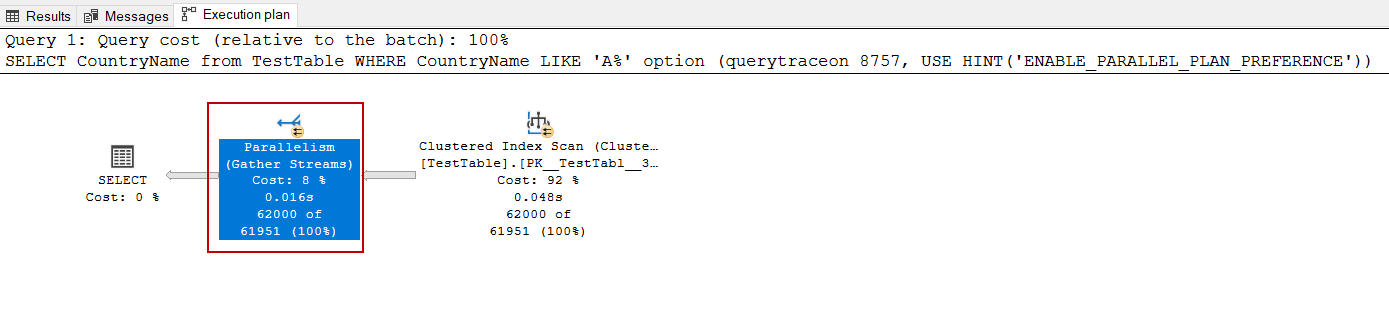
The query optimizer can process a query that requires excessive workload in discrete threads. In this approach, the main idea is to handle more rows in unit time, so it might reduce the query execution time. For our example of the T-SQL query, the query optimizer creates a serial execution plan, but we can force it to create a parallel execution plan with the help of the ENABLE_PARALLEL_PLAN_PREFERENCE hint.
查询优化器可以处理在离散线程中需要大量工作量的查询。 在这种方法中,主要思想是在单位时间内处理更多的行,因此可以减少查询的执行时间。 对于我们的T-SQL查询示例,查询优化器创建了一个串行执行计划,但是我们可以在ENABLE_PARALLEL_PLAN_PREFERENCE提示的帮助下强制其创建并行执行计划。
SELECT CountryName
FROM TestTable
WHERE CountryName LIKE 'A%' OPTION(QUERYTRACEON 8757, USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));
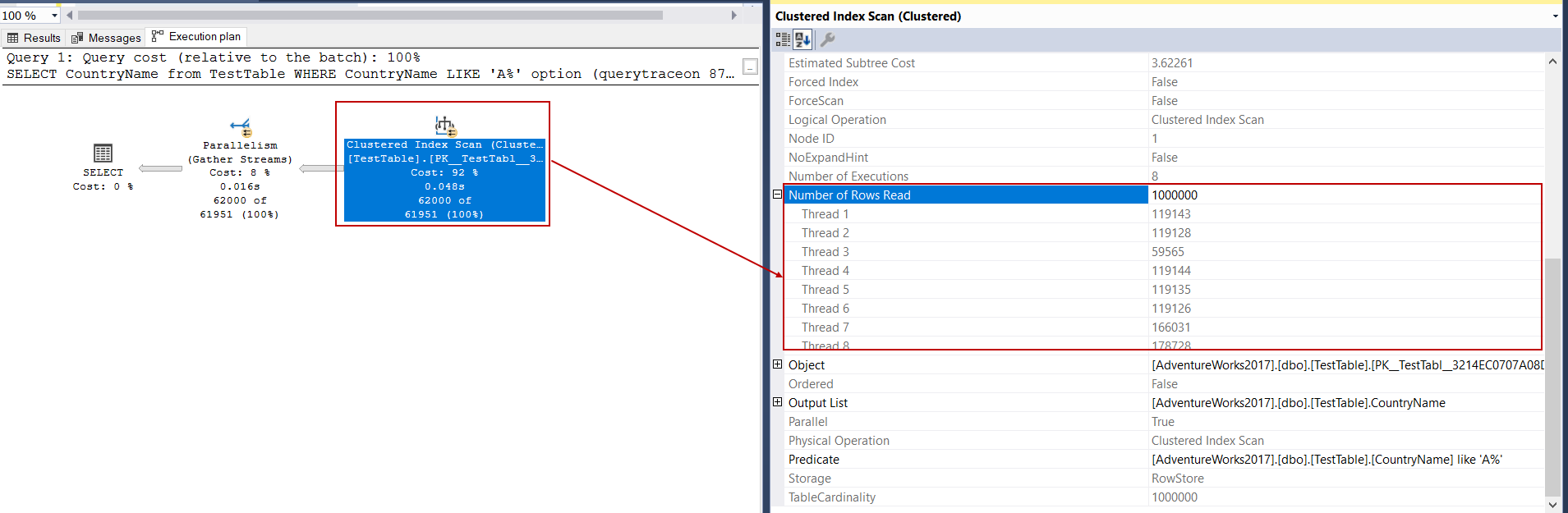
In the above image, we can see that how many rows have been read by each thread. The Gather Stream operator merges all these multiple thread inputs into the single output.
在上图中,我们可以看到每个线程读取了多少行。 Gather Stream运算符将所有这些多线程输入合并到单个输出中。
查找有关执行计划的更多秘密
(Find some more secret about execution plans
)
As we stated, the execution plan includes too much information about the query execution backstage. When we observe the select operator of the sample query, we will see an OptimizerStatsUsage property. When we expand it, we can see which statistics are used by the optimizer.
如前所述,执行计划包含太多有关后台查询执行的信息。 当我们观察示例查询的select运算符时,我们将看到OptimizerStatsUsage属性。 扩展它时,我们可以看到优化器使用了哪些统计信息。
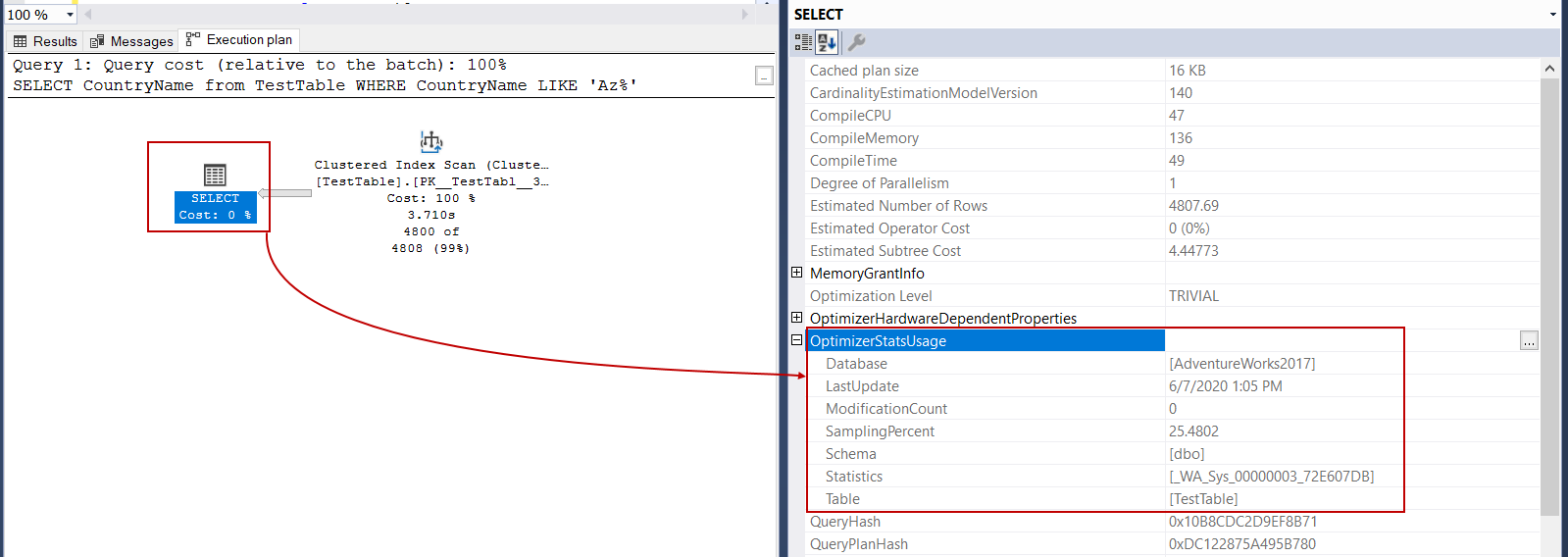
The LastUpdate property shows when statistics were last updated, and SamplingPercent indicates how many percents of rows of data are using to create histograms. When we update statistics with the FULLSCAN option, it computes statistics by searching all rows in the table.
LastUpdate属性显示统计信息的最新更新时间, SamplingPercent指示要使用多少百分比的数据行来创建直方图。 当我们使用FULLSCAN选项更新统计信息时,它将通过搜索表中的所有行来计算统计信息。
UPDATE STATISTICS TestTable WITH FULLSCAN
Now, we will execute the sample query again and analyze the execution plan.
现在,我们将再次执行示例查询并分析执行计划。
SELECT CountryName from TestTableWHERE CountryName LIKE 'A%'
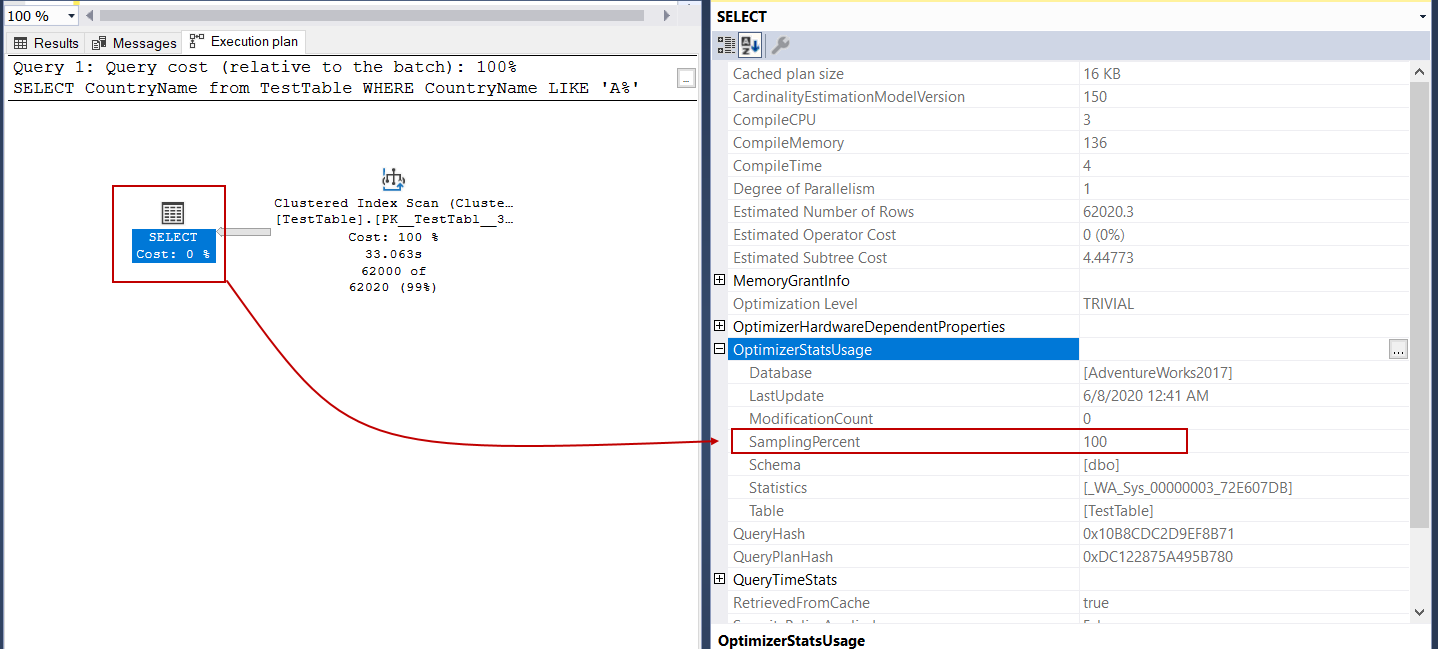
As we can see, the SamplingPercent attribute value has changed after updating the statistics.
如我们所见,更新统计信息后, SamplingPercent属性值已更改。
结论 (Conclusion)
In this article, we discussed the execution plan details of a very simple T-SQL query. Understanding the execution plan of a query is the starting point to solve the performance issues of the queries. For this reason, in this article, we have interpreted a very simple query execution plan to improve practical experience. Let’s quickly recall the below that we have learned in this article:
在本文中,我们讨论了一个非常简单的T-SQL查询的执行计划细节。 了解查询的执行计划是解决查询性能问题的起点。 因此,在本文中,我们解释了一个非常简单的查询执行计划,以提高实践经验。 让我们快速回顾一下我们在本文中学到的以下内容:
- Clustered index seek and clustered index scan operators 聚集索引查找和聚集索引扫描运算符
- Trivial execution plans 琐碎的执行计划
- Parallel execution plans 并行执行计划
- Cardinality Estimation 基数估计
- How to find out which statistics were used during query execution 如何找出查询执行期间使用了哪些统计信息
翻译自: https://www.sqlshack.com/interpreting-execution-plans-of-t-sql-queries/
t-sql执行结果
t-sql执行结果_解释T-SQL查询的执行计划相关推荐
- in ms sql 集合参数传递_神奇的 SQL → 为什么 GROUP BY 之后不能直接引用原表中的列?...
GROUP BY 后 SELECT 列的限制 标准 SQL 规定,在对表进行聚合查询的时候,只能在 SELECT 子句中写下面 3 种内容:通过 GROUP BY 子句指定的聚合键.聚合函数(SUM ...
- sql server死锁_如何解决SQL Server中的死锁
sql server死锁 In this article, we will talk about the deadlocks in SQL Server, and then we will analy ...
- sql server死锁_如何报告SQL Server死锁事件
sql server死锁 介绍 (Introduction) In the previous article entitled "What are SQL Server deadlocks ...
- sql limit 子句_具有并行性SQL Server TOP子句性能问题
sql limit 子句 TOP操作员基础 ( Basics of TOP Operator ) The TOP keyword in SQL Server is a non-ANSI standar ...
- sql server 并发_并发问题– SQL Server中的理论和实验
sql server 并发 介绍 (Introduction) Intended audience 目标听众 This document is intended for application dev ...
- sql server 锁定_关于锁定SQL Server的全部
sql server 锁定 .SQLCode { font-size: 13px; font-weight: bold; font-family: monospace;; white-space: p ...
- mysql经典sql语句大全_常用经典SQL语句大全完整版--详解+实例 (存)
下列语句部分是Mssql语句,不可以在access中使用. SQL分类: DDL-数据定义语言(CREATE,ALTER,DROP,DECLARE) DML-数据操纵语言(SELECT,DELETE, ...
- sql 删除依赖_关系数据库标准语言SQL(二)
声明:最近在准备考试,故整理数据库原理笔记. 视图 视图的创建和删除 CREATE VIEW <视图名 > [ <列名 > , --, <列名 >)] AS &l ...
- 刚装的系统没有sql server(mssqlserver)_数据库与SQL学习
本篇是数据分析系统学习专栏的第四篇文章--数据库与SQL学习.如果想要了解写作初衷,可以先行阅读如何系统学习数据分析. 数据库和SQL的基本概念 推荐阅读:怎么简单地理解数据库的概念? 核心概念: 数 ...
最新文章
- 2022-2028年全球与中国闪光棉市场研究及前瞻分析报告
- 用友 传入的 json 格式无效_用友网络股吧:被错杀的半导体材料龙头,全年或60%高增长,刚刚走出黄金坑...
- USB接口供电蓝牙彩色灯带控制器
- 在linux将一些程序放到后台运行的方法(nohup/screen/daemonize)
- python算法与数据结构-双向链表
- 属性页中的ON_UPDATE_COMMAND_UI
- 怎么在alert里加图片_麻辣烫里加牛奶,创意吃法,麻辣鲜香吃得超过瘾
- Hive 执行计划之Reduce Output Operator
- Docker系列(一)什么是Docker
- arcgis dem栅格立体感_arcgis中DEM如何生成等高线
- 维纳滤波python 函数_python实现逆滤波与维纳滤波示例
- 六一儿童节海报合集,一起重拾童年吧~
- 基于IIS Live Smooth Streaming技术流媒体直播系统
- 原创 导出微信收藏到电脑
- JAVA+SSM+MySql CRM客户关系管理系统(附带源码)
- 【计算机算法】贪心算法——看电影、活动选择问题
- 谢孟军:中国 Go 语言领军人创业第五年
- Windows10鼠标右键增加新项
- 足球比赛数据分析系统
- 【php】基于Xajax的在线聊天室、直播间