时间序列数据库的秘密(3)——加载和分布式计算
加载
\\
如何利用索引和主存储,是一种两难的选择。
\\
- 选择不使用索引,只使用主存储:除非查询的字段就是主存储的排序字段,否则就需要顺序扫描整个主存储。\\t
- 选择使用索引,然后用找到的row id去主存储加载数据:这样会导致很多碎片化的随机读操作。\
没有所谓完美的解决方案。MySQL支持索引,一般索引检索出来的行数也就是在1~100条之间。如果索引检索出来很多行,很有可能MySQL会选择不使用索引而直接扫描主存储,这就是因为用row id去主存储里读取行的内容是碎片化的随机读操作,这在普通磁盘上很慢。
\\
Opentsdb是另外一个极端,它完全没有索引,只有主存储。使用Opentsdb可以按照主存储的排序顺序快速地扫描很多条记录。但是访问的不是按主存储的排序顺序仍然要面对随机读的问题。
\\
Elasticsearch/Lucene的解决办法是让主存储的随机读操作变得很快,从而可以充分利用索引,而不用惧怕从主存储里随机读加载几百万行带来的代价。
\\
Opentsdb 的弱点
\\
Opentsdb没有索引,主存储是Hbase。所有的数据点按照时间顺序排列存储在Hbase中。Hbase是一种支持排序的存储引擎,其排序的方式是根据每个row的rowkey(就是关系数据库里的主键的概念)。MySQL存储时间序列的最佳实践是利用MySQL的Innodb的clustered index特性,使用它去模仿类似Hbase按rowkey排序的效果。所以Opentsdb的弱点也基本适用于MySQL。Opentsdb的rowkey的设计大致如下:
\\
\[metric_name][timestamp][tags]
\\
举例而言:
\\
\Proc.load_avg.1m 12:05:00 ip=10.0.0.1\Proc.load_avg.1m 12:05:00 ip=10.0.0.2\Proc.load_avg.1m 12:05:01 ip=10.0.0.1\Proc.load_avg.1m 12:05:01 ip=10.0.0.2\Proc.load_avg.5m 12:05:00 ip=10.0.0.1\Proc.load_avg:5m 12:05:00 ip=10.0.0.2
\\
也就是行是先按照metric_name排序,再按照timestamp排序,再按照tags来排序。
\\
对于这样的rowkey设计,获取一个metric在一个时间范围内的所有数据是很快的,比如Proc.load_avg.1m在12:05到12:10之间的所有数据。先找到Proc.load_avg.1m 12:05:00的行号,然后按顺序扫描就可以了。
\\
但是以下两种情况就麻烦了。
\\
- 获取12:05 到 12:10 所有 Proc.load_avg.* 的数据,如果预先知道所有的metric name包括Proc.load_avg.1m,Proc.load_avg.5m,Proc.load_avg.15m。这样会导致很多的随机读。如果不预先知道所有的metric name,就无法知道Proc.load_avg.*代表了什么。\\t
- 获取指定ip的数据。因为ip是做为tags保存的。即便是访问一个ip的数据,也要把所有其他的ip数据读取出来再过滤掉。如果ip总数有十多万个,那么查询的效率也会非常低。为了让这样的查询变得更快,需要把ip编码到metric_name里去。比如ip.10.0.0.1.Proc.load_avg.1m 这样。\
所以结论是,不用索引是不行的。如果希望支持任意条件的组合查询,只有主存储的排序是无法对所有查询条件进行优化的。但是如果查询条件是固定的一种,那么可以像Opentsdb这样只有一个主存储,做针对性的优化。
\\
DocValues为什么快?
\\
DocValues是一种按列组织的存储格式,这种存储方式降低了随机读的成本。传统的按行存储是这样的:
\\

\\
1和2代表的是docid。颜色代表的是不同的字段。
\\
改成按列存储是这样的:
\\

\\
按列存储的话会把一个文件分成多个文件,每个列一个。对于每个文件,都是按照docid排序的。这样一来,只要知道docid,就可以计算出这个docid在这个文件里的偏移量。也就是对于每个docid需要一次随机读操作。
\\
那么这种排列是如何让随机读更快的呢?秘密在于Lucene底层读取文件的方式是基于memory mapped byte buffer的,也就是mmap。这种文件访问的方式是由操作系统去缓存这个文件到内存里。这样在内存足够的情况下,访问文件就相当于访问内存。那么随机读操作也就不再是磁盘操作了,而是对内存的随机读。
\\
那么为什么按行存储不能用mmap的方式呢?因为按行存储的方式一个文件里包含了很多列的数据,这个文件尺寸往往很大,超过了操作系统的文件缓存的大小。而按列存储的方式把不同列分成了很多文件,可以只缓存用到的那些列,而不让很少使用的列数据浪费内存。
\\
按列存储之后,一个列的数据和前面的posting list就差不多了。很多应用在posting list上的压缩技术也可以应用到DocValues上。这不但减少了文件尺寸,而且提高数据加载的速度。因为我们知道从磁盘到内存的带宽是很小的,普通磁盘也就每秒100MB的读速度。利用压缩,我们可以把数据以压缩的方式读取出来,然后在内存里再进行解压,从而获得比读取原始数据更高的效率。
\\
如果内存不够是不是会使得随机读的速度变慢?肯定会的。但是mmap是操作系统实现的API,其内部有预读取机制。如果读取offset为100的文件位置,默认会把后面16k的文件内容都预读取出来都缓存在内存里。因为DocValues是只读,而且顺序排序存储的。相比b-tree等存储结构,在磁盘上没有空洞和碎片。而随机读的时候也是按照DocId排序的。所以如果读取的DocId是紧密相连的,实际上也相当于把随机读变成了顺序读了。Random_read(100), Random_read(101), Random_read(102)就相当于Scan(100~102)了。
\\
分布式计算
\\
分布式聚合如何做得快
\\
Elasticsearch/Lucene从最底层就支持数据分片,查询的时候可以自动把不同分片的查询结果合并起来。Elasticsearch的document都有一个uid,默认策略是按照uid 的 hash把文档进行分片。
\\
\\
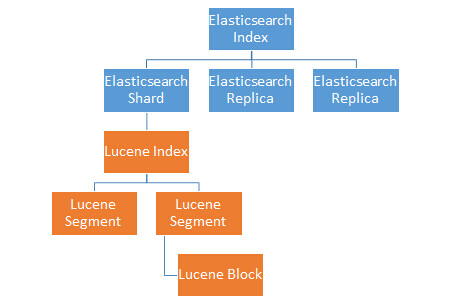
一个Elasticsearch Index相当于一个MySQL里的表,不同Index的数据是物理上隔离开来的。Elasticsearch的Index会分成多个Shard存储,一部分Shard是Replica备份。一个Shard是一份本地的存储(一个本地磁盘上的目录),也就是一个Lucene的Index。不同的Shard可能会被分配到不同的主机节点上。一个Lucene Index会存储很多的doc,为了好管理,Lucene把Index再拆成了Segment存储(子目录)。Segment内的doc数量上限是1的31次方,这样doc id就只需要一个int就可以存储。Segment对应了一些列文件存储索引(倒排表等)和主存储(DocValues等),这些文件内部又分为小的Block进行压缩。
\\
\\
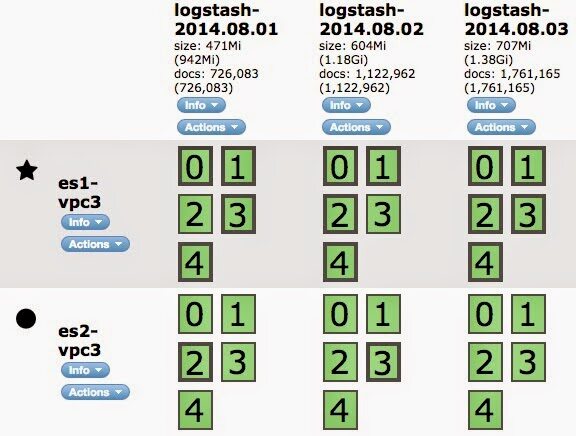
时间序列数据一般按照日期分成多个Elasticsearch Index来存储,比如logstash-2014.08.02。查询的时候可以指定多个Elasticsearch Index作为查找的范围,也可以用logstash-*做模糊匹配。
\\
美妙之处在于,虽然数据被拆得七零八落的,在查询聚合的时候甚至需要分为两个阶段完成。但是对于最终用户来说,使用起来就好像是一个数据库表一样。所有的合并查询的细节都是隐藏起来的。
\\
对于聚合查询,其处理是分两阶段完成的:
\\
- Shard本地的Lucene Index并行计算出局部的聚合结果;\\t
- 收到所有的Shard的局部聚合结果,聚合出最终的聚合结果。\
这种两阶段聚合的架构使得每个shard不用把原数据返回,而只用返回数据量小得多的聚合结果。相比Opentsdb这样的数据库设计更合理。Opentsdb其聚合只在最终节点处完成,所有的分片数据要汇聚到一个地方进行计算,这样带来大量的网络带宽消耗。所以Influxdb等更新的时间序列数据库选择把分布式计算模块和存储引擎进行同机部署,以减少网络带宽的影响。
\\
除此之外Elasticsearch还有另外一个减少聚合过程中网络传输量的优化,那就是Hyperloglog算法。在计算unique visitor(uv)这样的场景下,经常需要按用户id去重之后统计人数。最简单的实现是用一个hashset保存这些用户id。但是用set保存所有的用户id做去重需要消耗大量的内存,同时分布式聚合的时候也要消耗大量的网络带宽。Hyperloglog算法以一定的误差做为代价,可以用很小的数据量保存这个set,从而减少网络传输消耗。
\\
为什么时间序列需要更复杂的聚合?
\\
关系型数据库支持一些很复杂的聚合查询逻辑,比如:
\\
- Join两张表;\\t
- Group by之后用Having再对聚合结果进行过滤;\\t
- 用子查询对聚合结果进行二次聚合。\
在使用时间序列数据库的时候,我们经常会怀念这些SQL的查询能力。在时间序列里有一个特别常见的需求就是降频和降维。举例如下:
\\
\12:05:05 湖南 81\12:05:07 江西 30\12:05:11 湖南 80\12:05:12 江西 32\12:05:16 湖南 80\12:05:16 江西 30
\\
按1分钟频率进行max的降频操作得出的结果是:
\\
\12:05 湖南 81\12:05 江西 32
\\
这种按max进行降频的最常见的场景是采样点的归一化。不同的采集器采样的时间点是不同的,为了避免漏点也会加大采样率。这样就可能导致一分钟内采样多次,而且采样点的时间都不对齐。在查询的时候按max进行降频可以得出一个统一时间点的数据。
\\
按sum进行降维的结果是:
\\
\12:05 113
\\
经常我们需要舍弃掉某些维度进行一个加和的统计。这个统计需要在时间点对齐之后再进行计算。这就导致一个查询需要做两次,上面的例子里:
\\
- 先按1分钟,用max做降频;\\t
- 再去掉省份维度,用sum做降维。\
如果仅仅能做一次聚合,要么用sum做聚合,要么用max做聚合。无法满足业务逻辑的需求。为了避免在一个查询里做两次聚合,大部分的时间序列数据库都要求数据在入库的时候已经是整点整分的。这就要求数据不能直接从采集点直接入库,而要经过一个实时计算管道进行处理。如果能够在查询的时候同时完成降频和降维,那就可以带来一些使用上的便利。
\\
这个功能看似简单,其实非常难以实现。很多所谓的支持大数据的数据库都只支持简单的一次聚合操作。Elasticsearch 将要发布的 2.0 版本的最重量级的新特性是Pipeline Aggregation,它支持数据在聚合之后再做聚合。类似SQL的子查询和Having等功能都将被支持。
\\
总结
\\
时间序列随着Internet of Things等潮流的兴起正变得越来越常见。希望本文可以帮助你了解到那些号称自己非常海量,查询非常快的时间序列数据库背后的秘密。没有完美的数据库,Elasticsearch也不例外。如果你的用例根本不包括聚合的需求,也许Opentsdb甚至MySQL就是你最好的选择。但是如果你需要聚合海量的时间序列数据,一定要尝试一下Elasticsearch!
\\
作者简介
\\
陶文,曾就职于腾讯IEG的蓝鲸产品中心,负责过告警平台的架构设计与实现。2006年从ThoughtWorks开始职业生涯,在大型遗留系统的重构,持续交付能力建设,高可用分布式系统构建方面积累了丰富的经验。
\\
感谢张凯峰对本文的策划,丁晓昀对本文的审校。
\\
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群 )。
)。
时间序列数据库的秘密(3)——加载和分布式计算相关推荐
- ElasticSearch学习_陶文1_时间序列数据库的秘密(1)—— 介绍
什么是时间序列数据?最简单的定义就是数据格式里包含timestamp字段的数据.比如股票市场的价格,环境中的温度,主机的CPU使用率等.但是又有什么数据是不包含timestamp的呢?几乎所有的数据都 ...
- .NET Core用数据库做配置中心加载Configuration
本文介绍了一个在.NET中用数据库做配置中心服务器的方式,介绍了读取配置的开源自定义ConfigurationProvider,并且讲解了主要实现原理. 1. 为什么用数据库做配置中心 在开发youz ...
- 【Youtobe trydjango】Django2.2教程和React实战系列八【渲染数据库数据与模板加载顺序探究】
[Youtobe trydjango]Django2.2教程和React实战系列八[渲染数据库数据与模板加载顺序探究] 1. 准备数据 2. 渲染数据库数据到模板 3. 如何在app里加载django ...
- ElasticSearch学习_陶文3_时间序列数据库的秘密(3)——加载和分布式计算
加载 如何利用索引和主存储,是一种两难的选择. 选择不使用索引,只使用主存储:除非查询的字段就是主存储的排序字段,否则就需要顺序扫描整个主存储. 选择使用索引,然后用找到的row id去主存储加载数据 ...
- 南大通用数据库-Gbase-8a-学习-14-LOAD加载数据
一.测试环境 名称 值 cpu Intel® Core™ i5-1035G1 CPU @ 1.00GHz 操作系统 CentOS Linux release 7.9.2009 (Core) Gbase ...
- Navicat操作数据库时一直显示加载中
用Navicat for mysql操作mysql数据库,其中一个表怎么也打不开,一直加载,还不能关闭.从网上搜索原因,主要是以下几个原因: 原因一: 表死锁,会出现这样的情况,锁不释放,无论多久都读 ...
- 干货丨时序数据库DolphinDB文本数据加载教程
DolphinDB提供以下4个函数,将文本数据导入内存或数据库: loadText: 将文本文件导入为内存表. ploadText: 将文本文件并行导入为分区内存表.与loadText函数相比,速度更 ...
- Navicat操作数据库时候一直显示加载中
一.原因有如下几点: 1.表死锁,锁不释放,无论多久都显示正在加载中 2.表中的数据量太大造成的 3.网络比较慢,卡顿,数据无法传输导致的 二.分析结果: 大部分的原因都是原因一导致的. 三.解决办法 ...
- 微信小程序云数据库触底分页加载,下拉无限加载,第一次请求数据随机,随机获取数据库的数据
效果图 小程序云开发分页加载代码 <!--pages/chatList/chatList.wxml--> <view class="pageTitle">家 ...
最新文章
- AlexNet- ImageNet Classification with Deep Convolutional Neural Networks
- nyoj7——街区最短问题
- Google Map API 学习六-设置infoWindow的长宽
- BZOJ 1412 狼和羊的故事
- Java常见容器(Container)关系图
- 自己初学时的随笔记录
- android开机logo制作工具,Android 开机Logo制作
- FTP下载利器FlashFXP【原创 HOHO】
- 网络编程之 socket编程
- oracle开启未活动连接清理,Oracle inactive session的清理
- [读书笔记] 机器学习 (一)绪论
- 使用ThinkPHP扩展,实现Redis的CURD操作。
- 2023上海大学电气工程及其自动化考研必看上岸经验指导
- 杰理AC692X系列---关于692x及693x的打开在线调EQ功能(4)
- 单片机程序编写常使用的程序架构
- python学习之数据爬取及其可视化分析(一)
- 满减优惠用多了,想过怎么运作的吗?
- 服务器端获取数据(一)
- 3蛋白wb_有这3个工具!蛋白实验不愁!
- java实现记账本功能_java基础实战项目一:实现家庭记账本的简易记账功能
热门文章
- Cluster coefficient的理解
- mysql 源代码16384_MySQL源码:Innobase文件系统管理
- python提取每个单词首字母_Python 2:str.title()(使字符串每个单词首字母大写)...
- 软件测试矩阵,什么是过程/数据矩阵(U/C矩阵)?
- python 中的转义序列
- 从书上截取一段TCP三次握手和四次挥手
- 信息系统项目管理师教材【下载PDF】
- 笔记-信息化与系统集成技术-区块链的技术架构
- 《系统集成项目管理工程师》必背100个知识点-37项目进度管理的过程
- AndroidStudio报错:Emulator: I/O warning : failed to load external entity file:/C:/Users/Administrator