文本分类 特征选取之CHI开方检验
前文提到过,除了分类算法以外,为分类文本作处理的特征提取算法也对最终效果有巨大影响,而特征提取算法又分为特征选择和特征抽取两大类,其中特征选择算法有互信息,文档频率,信息增益,开方检验等等十数种,这次先介绍特征选择算法中效果比较好的开方检验方法。
开方检验最基本的思想就是通过观察实际值与理论值的偏差来确定理论的正确与否。具体做的时候常常先假设两个变量确实是独立的(行话就叫做“原假设”),然后观察实际值(也可以叫做观察值)与理论值(这个理论值是指“如果两者确实独立”的情况下应该有的值)的偏差程度,如果偏差足够小,我们就认为误差是很自然的样本误差,是测量手段不够精确导致或者偶然发生的,两者确确实实是独立的,此时就接受原假设;如果偏差大到一定程度,使得这样的误差不太可能是偶然产生或者测量不精确所致,我们就认为两者实际上是相关的,即否定原假设,而接受备择假设。
那么用什么来衡量偏差程度呢?假设理论值为E(这也是数学期望的符号哦),实际值为x,如果仅仅使用所有样本的观察值与理论值的差值x-E之和

来衡量,单个的观察值还好说,当有多个观察值x1,x2,x3的时候,很可能x1-E,x2-E,x3-E的值有正有负,因而互相抵消,使得最终的结果看上好像偏差为0,但实际上每个都有偏差,而且都还不小!此时很直接的想法便是使用方差代替均值,这样就解决了正负抵消的问题,即使用
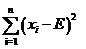
这时又引来了新的问题,对于500的均值来说,相差5其实是很小的(相差1%),而对20的均值来说,5相当于25%的差异,这是使用方差也无法体现的。因此应该考虑改进上面的式子,让均值的大小不影响我们对差异程度的判断
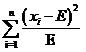 式(1)
式(1)
上面这个式子已经相当好了。实际上这个式子就是开方检验使用的差值衡量公式。当提供了数个样本的观察值x1,x2,……xi ,……xn之后,代入到式(1)中就可以求得开方值,用这个值与事先设定的阈值比较,如果大于阈值(即偏差很大),就认为原假设不成立,反之则认为原假设成立。
在文本分类问题的特征选择阶段,我们主要关心一个词t(一个随机变量)与一个类别c(另一个随机变量)之间是否相互独立?如果独立,就可以说词t对类别c完全没有表征作用,即我们根本无法根据t出现与否来判断一篇文档是否属于c这个分类。但与最普通的开方检验不同,我们不需要设定阈值,因为很难说词t和类别c关联到什么程度才算是有表征作用,我们只想借用这个方法来选出一些最最相关的即可。
此时我们仍然需要明白对特征选择来说原假设是什么,因为计算出的开方值越大,说明对原假设的偏离越大,我们越倾向于认为原假设的反面情况是正确的。我们能不能把原假设定为“词t与类别c相关“?原则上说当然可以,但此时你会发现根本不知道此时的理论值该是多少!你会把自己绕进死胡同。选择的过所以我们一般都使用”词t与类别c不相关“来做原假设。计算过程也变成了为每个词计算它与类别c的开方值,从大到小排个序(此时开方值越大越相关),取前k个就可以。
好,原理有了,该来个例子说说到底怎么算了。
比如说现在有N篇文档,其中有M篇是关于体育的,我们想考察一个词“篮球”与类别“体育”之间的相关性(任谁都看得出来两者很相关,但很遗憾,我们是智慧生物,计算机不是,它一点也看不出来,想让它认识到这一点,只能让它算算看)。我们有四个观察值可以使用:
1. 包含“篮球”且属于“体育”类别的文档数,命名为A
2. 包含“篮球”但不属于“体育”类别的文档数,命名为B
3. 不包含“篮球”但却属于“体育”类别的文档数,命名为C
4. 既不包含“篮球”也不属于“体育”类别的文档数,命名为D
用下面的表格更清晰:
|
特征选择 |
1.属于“体育” |
2.不属于“体育” |
总 计 |
|
1.包含“篮球” |
A |
B |
A+B |
|
2.不包含“篮球” |
C |
D |
C+D |
|
总 数 |
A+C |
B+D |
N |
如果有些特点你没看出来,那我说一说,首先,A+B+C+D=N(这,这不废话嘛)。其次,A+C的意思其实就是说“属于体育类的文章数量”,因此,它就等于M,同时,B+D就等于N-M。
好,那么理论值是什么呢?以包含“篮球”且属于“体育”类别的文档数为例。如果原假设是成立的,即“篮球”和体育类文章没什么关联性,那么在所有的文章中,“篮球”这个词都应该是等概率出现,而不管文章是不是体育类的。这个概率具体是多少,我们并不知道,但他应该体现在观察结果中(就好比抛硬币的概率是二分之一,可以通过观察多次抛的结果来大致确定),因此我们可以说这个概率接近
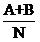
(因为A+B是包含“篮球”的文章数,除以总文档数就是“篮球”出现的概率,当然,这里认为在一篇文章中出现即可,而不管出现了几次)而属于体育类的文章数为A+C,在这些个文档中,应该有
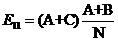
篇包含“篮球”这个词(数量乘以概率嘛)。
但实际有多少呢?考考你(读者:切,当然是A啦,表格里写着嘛……)。
此时对这种情况的差值就得出了(套用式(1)的公式),应该是

同样,我们还可以计算剩下三种情况的差值D12,D21,D22,聪明的读者一定能自己算出来(读者:切,明明是自己懒得写了……)。有了所有观察值的差值,就可以计算“篮球”与“体育”类文章的开方值
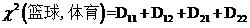
把D11,D12,D21,D22的值分别代入并化简,可以得到

词t与类别c的开方值更一般的形式可以写成
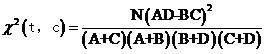 式(2)
式(2)
接下来我们就可以计算其他词如“排球”,“产品”,“银行”等等与体育类别的开方值,然后根据大小来排序,选择我们需要的最大的数个词汇作为特征项就可以了。
实际上式(2)还可以进一步化简,注意如果给定了一个文档集合(例如我们的训练集)和一个类别,则N,M,N-M(即A+C和B+D)对同一类别文档中的所有词来说都是一样的,而我们只关心一堆词对某个类别的开方值的大小顺序,而并不关心具体的值,因此把它们从式(2)中去掉是完全可以的,故实际计算的时候我们都使用
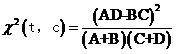 式(3)
式(3)
好啦,并不高深对不对?
针对英文纯文本的实验结果表明:作为特征选择方法时,开方检验和信息增益的效果最佳(相同的分类算法,使用不同的特征选择算法来得到比较结果);文档频率方法的性能同前两者大体相当,术语强度方法性能一般;互信息方法的性能最差(文献[17])。
但开方检验也并非就十全十美了。回头想想A和B的值是怎么得出来的,它统计文档中是否出现词t,却不管t在该文档中出现了几次,这会使得他对低频词有所偏袒(因为它夸大了低频词的作用)。甚至会出现有些情况,一个词在一类文章的每篇文档中都只出现了一次,其开方值却大过了在该类文章99%的文档中出现了10次的词,其实后面的词才是更具代表性的,但只因为它出现的文档数比前面的词少了“1”,特征选择的时候就可能筛掉后面的词而保留了前者。这就是开方检验著名的“低频词缺陷“。因此开方检验也经常同其他因素如词频综合考虑来扬长避短。
好啦,关于开方检验先说这么多,有机会还将介绍其他的特征选择算法。
附:给精通统计学的同学多说几句,式(1)实际上是对连续型的随机变量的差值计算公式,而我们这里统计的“文档数量“显然是离散的数值(全是整数),因此真正在统计学中计算的时候,是有修正过程的,但这种修正仍然是只影响具体的开方值,而不影响大小的顺序,故文本分类中不做这种修正。
文本分类 特征选取之CHI开方检验相关推荐
- 【文本分类】基于改进CHI和PCA的文本特征选择
摘要:改进CHI算法后,结合PCA算法,应用于文本的特征选择,提高了精度. 参考文献:[1]文武,万玉辉,张许红,文志云.基于改进CHI和PCA的文本特征选择[J].计算机工程与科学,2021,43( ...
- 【文本分类】混合CHI和MI的改进文本特征选择方法
摘要:改进CHI算法.改进MI算法,结合改进CHI+改进MI,应用于文本的特征选择,提高了精度. 参考文献:[1]王振,邱晓晖.混合CHI和MI的改进文本特征选择方法[J].计算机技术与发展,2018 ...
- 基于libsvm的中文文本分类原型
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本 .非线性及高维模式识别 中表现出许多特有的优势,并能够推广应用到函数拟合等 ...
- html文本分类输出,构建中文网页分类器对网页进行文本分类
网络原指用一个巨大的虚拟画面,把所有东西连接起来,也可以作为动词使用.在计算机领域中,网络就是用物理链路将各个孤立的工作站或主机相连在一起,组成数据链路,从而达到资源共享和通信的目的.凡将地理位置不同 ...
- 用朴素贝叶斯和SVM进行文本分类
写在前面的感悟: 测试集文件删除一定要shift+delete!!!!!要不然回收站直接爆炸,用几个小时打开,然后再用几个小时清空.文本分类的数据集看似只有几个G那么大,但是架不住文件数量多,导致各种 ...
- 文本分类入门(十)特征选择算法之开方检验
前文提到过,除了分类算法以外,为分类文本作处理的特征提取算法也对最终效果有巨大影响,而特征提取算法又分为特征选择和特征抽取两大类,其中特征选择算法有互信息,文档频率,信息增益,开方检验等等十数种,这次 ...
- 文本特征选择 java代码_文本分类入门(十)特征选择算法之开方检验
前文提到过,除了分类算法以外,为分类文本作处理的特征提取算法也对最终效果有巨大影响,而特征提取算法又分为特征选择和特征抽取两大类,其中特征选择算法有互信息,文档频率,信息增益,开方检验等等十数种,这次 ...
- 文本分类之特征简约算法说明
见 http://blog.csdn.net/aalbertini/archive/2010/07/20/5749883.aspx 用数值衡量某个特征的重要性. 1 df: 用df衡量重要性. df就 ...
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
文本分类入门(番外篇)特征选择与特征权重计算的区别 在文本分类的过程中,特征(也可以简单的理解为"词")从人类能够理解的形式转换为计算机能够理解的形式时,实际上经过了两步骤的量化- ...
最新文章
- mysql原理~undo
- JavaMelody开源系统性能监控
- Hive安装问题简述
- C语言 编写程序:请将Fibonacci数列前30项中的偶数值找出来,存储到一维数组中。其中,Fibonacci数列如下:1,1,2,3,5,8,13,21,34...该数列除前两项之外,其他任意
- Python中抓网页的小陷阱
- PMT_Header-节目映射表的数据结构2
- java中new与newitance_你真的弄明白 new 了吗
- Arm汇编 位置无关代码 adr 指令
- 妙招防止非法入侵Win2000/XP系统(转)
- 豆瓣已玩烂,来爬点有逼格的 ——IMDB 电影提升你的品位
- Stack Frame JAVA运行时数据区域之栈帧
- 数据分析|基础概念/excel/tableau自学笔记
- 关于马克思《青年在选择职业时的考虑》的读书报告
- 【练习】基于Vue全家桶的仿小米商城系统
- python+request 哔哩哔哩视频下载
- 站斧浏览器——用实力,说实话
- 以下内容选自雷军的博客
- Apollo配置中心命名空间介绍
- 实时城市路面积水面积检测(源码&教程)
- 魔塔之拯救白娘子~我的第一个VB6+DX8做的小游戏源码~17开始游戏-移动方向处理