高效的敏捷测试第十三课 自动化测试、用例测试、接口测试、大数据测试
第41讲:质效合一:自动化测试和手工测试的完美融合
今天主要讲敏捷测试在执行阶段的策略。在前面讲了很多测试自动化的内容,也讲了不少探索式测试。不知道你想过没有,在产品的一次迭代开发中,什么样的测试适合自动化,什么样的测试适合手工测试?自动化测试和手工测试怎么结合才能达到更好的质量和效率?据我了解,不少团队对这些问题是缺乏思考和明确指导的。
一个案例
这里举一个测试团队的真实经历,该团队非常重视测试自动化,自主研发了自动化测试平台,平均测试自动化率达到了 65%。但是自动化测试在每个项目中平均只能发现 10% 的有效缺陷,绝大多数的缺陷还是通过手工测试发现的。测试团队的负责人认为自动化测试应该发现更多的缺陷才更有价值,而之所以效果不理想是因为下面两点。
第一,能做测试自动化的人手不足:脚本开发由专门的测试开发人员完成,大部分的测试人员只做手工测试,这就造成了测试脚本的开发进度比较慢。对于一个新产品,往往在好几个版本迭代之后,到了项目中后期测试脚本才勉强开发完。这时候大部分的缺陷已经通过手工测试发现了。
第二,测试开发人员不怎么参与具体的测试执行,对产品和业务的了解不够。因此在设计测试脚本时对业务场景的考虑不够全面。
于是团队要求每一个测试人员开发自己负责的功能模块的测试脚本。经过一系列的培训,这个目标最终达到了,测试人员自己编写的测试脚本在业务流程和功能点的验证方面确实也更全面。
既然人力不足的问题解决了,团队负责人认为测试脚本的开发自然是越早越好。于是,团队要求每个项目都要争取在一次迭代内把新功能的部分能自动化的尽量自动化。这样测试脚本就可以尽早投入执行,可以发现更多的缺陷。但是推行了一两个项目之后,发现很难做到。测试人员也抱怨:他们花在脚本开发和调试上的时间太多了,还不如手工测试能更快地发现缺陷。后来,这项要求也就不了了之了。
应该说,这个团队在普及自动化测试能力这方面做得不错。但是在测试执行过程中,测试负责人要求尽早地开始测试脚本开发是不切实际的。
因为迭代开发中的需求和设计往往是逐渐明确的,新的功能也是逐渐成长起来的。用户故事的需求在一开始往往不清楚,常常在开发和测试之间不断的尝试,团队成员在不断地讨论中才逐渐确定下来。当功能的需求不明确时,无论是 UI 还是接口的自动化测试都会困难重重,因为界面设计和接口定义都会更改,验收标准也有可能会更改。这时候就开始开发测试脚本只能经历反复修改,并不能在本次迭代中尽早地投入使用,带来效益。
新功能手工测试,回归测试自动化
对于当前迭代的新功能,更有效的方式是借助手工测试,即采用探索式测试的方式。开发人员完成一个特性,测试人员就可以立即展开测试、发现问题,立即和其他团队成员进行沟通,及时纠正,而且能更有效地发现缺陷。敏捷模式实施持续构建,每天都有可工作的软件,但每次要验证的新软件变更并不多,况且人最具有灵活性,增加什么就测什么,改了哪儿就测哪儿。探索式测试不需要写测试用例,效率更高、更灵活、更能应对变化。
新功能不适合做自动化测试,但回归测试需要依赖高度的测试自动化。在敏捷开发环境中,一个迭代周期通常是 2~4 周,最后验收测试只有几天时间,每次迭代都会增加新的功能。在经过一次一次的迭代,回归测试范围在不断增加,如图 1 所示。在非常有限的时间里,既要完成新功能的测试,又要完成越来越多的回归测试,如果没有自动化测试,几乎不太可能。
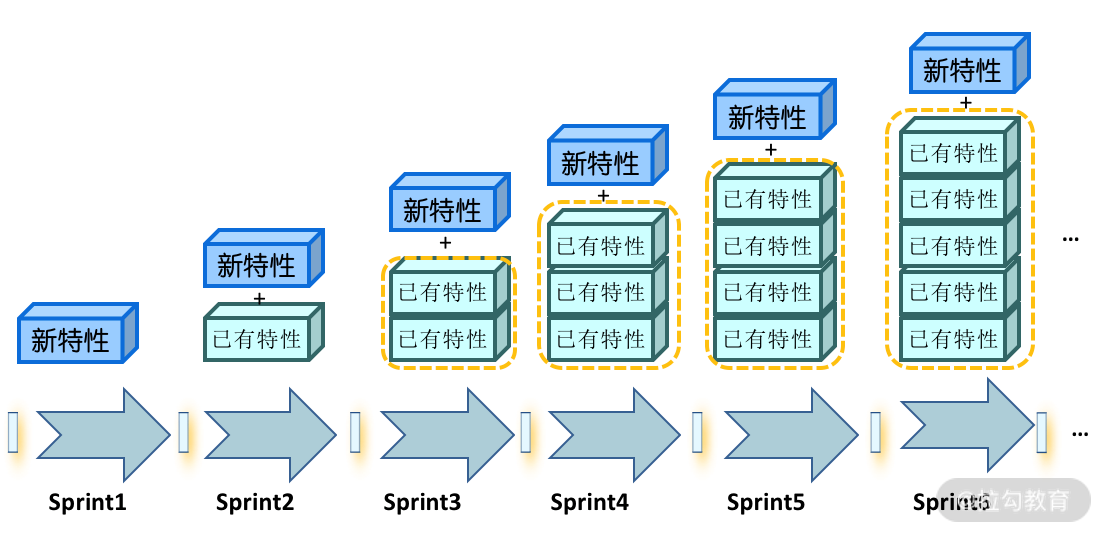
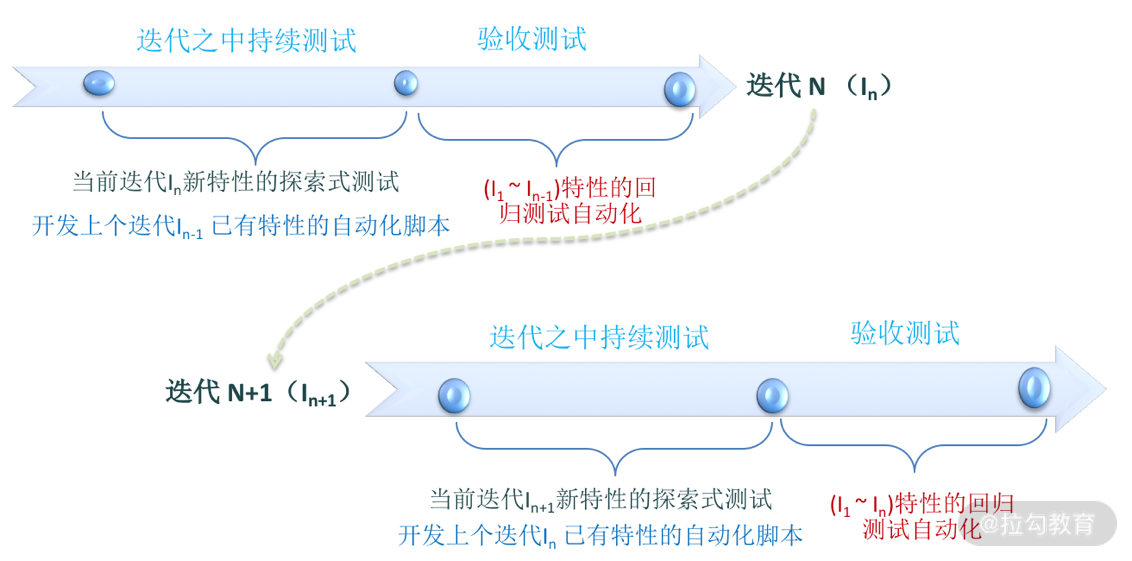
探索式测试不用写测试用例,节省下来的时间可以用来开发自动化测试脚本,但并非针对本次迭代的新功能,否则你就会遇到和案例里面那个团队同样的问题。测试人员应该开发上一个迭代已实现功能的自动化测试脚本。因为这时候,上一次迭代的功能特性已相对稳定,自动化脚本开发和调试都没什么障碍,效率也相对较高。新开发的测试脚本添加到自动化回归测试集,尽量保证回归测试可以全部自动化。
这就是我建议的自动化测试和手工测试有机结合的策略:新功能采用探索式测试,回归测试尽量全部自动化,针对上一次迭代实现的功能进行脚本开发,如图 2 所示。
探索未知的,自动化已知的
这几年我一直倡导要重新认识软件测试,对于软件测试我给出了一个新的公式:
测试 = 检测 + 试验
对于软件产品,可以检测的部分是产品中具有确定性的功能特性,也就是已知的部分。这部分功能的测试目标、测试需求和测试的验证准则等都是明确的,具有良好的可测试性。
而对产品中具有不确定性的功能特性,也就是未知的部分,只能通过试验来验证。不确定性主要是这几个原因造成的:功能需求定义不清楚、处于经常变更的状态、测试范围和数据是无限的,很难直接进行验证。软件系统中未知的、不确定性的部分越来越多,因为我们已经处于移动互联、大数据和人工智能时代,软件系统输入和输出的复杂性、多样性以及快速变化等特性,都增加了不确定性。
将上述公式再展开,就成为:
测试 = 检测已知的 + 试验未知的
测试过程中,判断测试结果是否通过,Test Oracle 举足轻重。Test Oracle 可以翻译为测试预言,就是决定一项测试是否通过的一种判断机制。对于已知的、具有确定性的功能特性,一般会运用相对明确的 Test Oracle,比如清晰的 Spec、竞品参照、一致性测试预言(Consistency Oracle);已知的部分,适合采用测试自动化的方式进行测试,因为输入和输出都是明确的,Test Oracle 也是明确的。
针对未知的,具有不确定性的功能特性,不论输入还是输出,都需要不断尝试。Test Oracle 也是启发式的,需要综合判断。未知的实验分为两部分:
- 通过工具实验,产生随机、半随机(变异/模糊)的数据,进行变异测试/模糊测试等,这里可以用统计准则,或造成系统异常(如系统崩溃),容易判断,用于安全性测试、稳定性测试等;
- 通过测试人员的试验,不断地质疑系统,根据系统的反馈来做出判断,也就是探索式测试的方式。
随着大数据和人工智能(AI)的发展,对未知进行测试时遇到的困难,也可以通过人工智能来解决。结合工具的随机/半随机测试和人的探索,未知的试验进一步提升为人工智能,不断学习、不断进行数据(输入、输出、log 等)挖掘,不断构造/完善验证的规则/准则,完成自动的测试,从未知逐步走到已知。
因此, 可以将测试新公式“测试=检测+试验 ”再进一步明确为:
测试=基于模型的、脚本的自动化测试 + 基于人工或 AI 的探索式测试
从测试一开始,即测试需求分析开始,就将测试的范围(测试项)分为两部分:已知的(包括确定性的/稳定的)、未知的(包括不确定的/动态的)。已知的测试项,理论上都可以实现自动化;未知的部分,也可以用工具进行测试(模糊测试/随机测试等),更多的是依赖人的探索式测试。
测试执行中的 ET 和 TA 有机结合的测试就是一个具体的应用。因为迭代中的测试范围也可以分为两部分:相对稳定的、有明确的测试项的已实现功能,和不确定的、容易变更的新功能。当新功能处于容易变更的状态时,就采用探索式测试的方式。而对上次迭代中已经实现的功能进行回归测试的脚本开发/调试。
自动化回归测试怎么做?
对于一个长期的软件产品来说,因为功能不断增加,回归测试所占的比重越来越大,即使回归测试实现了高度自动化,一个完整的回归测试也常常需要十几个小时甚至几天的时间才能执行完毕。在敏捷测试里,回归测试是持续测试的一部分,每次回归测试都重新运行所有的测试用例是不切实际的。所以也需要考虑有效的回归测试策略。
第 30 讲介绍过精准测试,通过代码依赖性分析和代码差异分析优化回归测试范围,即根据每个版本的代码变更选择回归测试的范围。这对于提高回归测试的效率非常有帮助,尤其是在版本即将交付前,修复了一些缺陷但在非常有限的时间里根本来不及做完整的回归测试。
如果没有引入精准测试,那团队在选择回归测试策略时需要兼顾效率和风险两个方面,根据项目的进度和状态进行动态的调整。平时就多测、持续测,充分利用自动化测试的优势,比如把测试分配到不同的测试机上并行执行,把大量的回归测试安排到夜间及周末运行。利用自动化测试平台和 CI/CD 环境的集成,创建定时的测试任务,自动启动测试工具和运行测试脚本。在晚上执行测试任务,第二天上班一早就能拿到测试结果;周末执行测试任务,周一上班就能拿到测试结果。
在产品交付之前,如果有代码变更,需要基于风险和基于操作剖面选择测试等策略相结合。基于操作剖面选择测试,即选择测试用例是依据哪些功能是用户最常用的,如 80/20 原则,其中 20% 的常用功能,用户有 80% 的时间在用它们,这部分的测试用例大部分会在 BVT 的测试范围内,作为持续集成测试的一部分。
AI 助力,让测试更完美
再回到敏捷测试的执行策略:探索式测试应用于新的功能特性,自动化测试应用于回归测试。就今天来看,无论是手工的探索式测试还是基于机器的自动化测试都有其局限性,还不能达到完美的质效合一。
就自动化测试来说,测试脚本还需要人来编写、维护,另外,发现缺陷的能力不够强也是事实。而且,无论是自动化测试还是手工测试,都面临对业务逻辑、应用场景考虑不全的问题。系统越复杂,测试应该达到的覆盖率和实际覆盖率差距就越大。
今天这些问题借助 AI 也许能得到令人满意的解决。
一方面,AI 可以和基于模型的测试技术(MBT)相结合,自动生成测试脚本,从而实现更加彻底的测试自动化,大幅提高测试效率。这方面的 AI 测试工具已经有不少,比如 Retest,使用人工智能猴子来完成应用程序自动化测试,不仅可以自动生成测试脚本,在自动化回归测试中还可以自动对比页面上的变更并且提供可视化的报告。
另一方面,探索式测试也可以和 AI 结合,对于新的功能特性,测试人员先进行探索式测试,给 AI “喂”数据,通过机器学习加速 AI 模型的训练,在补全测试场景的同时自动生成测试脚本,这样可以针对业务完善测试覆盖率。这方面的 AI 测试工具有 Mabl。
目前,精准测试技术所建立的代码与测试用例之间的映射关系往往是静态的,不能随时更新。其实测试范围的选择不仅仅要考虑代码覆盖率,还需要结合项目所处的状态、客户反馈信息、以前发现的缺陷等多种因素。通过机器学习就可以对多种信息进行数据挖掘,更加智能的优化回归测试范围。
AI 应用于测试的例子已经有很多,希望你能体会到一场新的测试革命正在到来,测试机器人在不久的将来会成为测试的主要力量。有了 AI 助力的软件测试会更加完美。
今天这一讲到这里就结束了,我主要讲解了三个部分:
- 采取测试自动化和手工测试结合的方式实现质量和效率的统一;
- 软件测试的新公式及其具体应用,比如自动化已知的、探索未知的;
- AI 技术助力软件测试可以提高测试覆盖率、测试效率,从而让质效合一更完美。
今天要给你出的思考题是:除了上面提到的 AI 和软件测试结合的方向,你认为还会有其他方向吗?
第42讲:单元测试必须 TDD 吗?
单元测试必须 TDD(等同于第 20 讲中提到的 UTDD)吗?这个问题的答案很简单,回答“No”就可以。通过本专栏前面课程的学习,咱们已经被“上下文驱动思维”武装起来了,认定不会只存在一种情况,而是根据上下文(比如所处的行业、产品特点、团队能力等)有不同的选择,即使在众多互联网公司中间,其单元测试也是参差不齐。所以,你既可以按 TDD 方式进行,也可以按普通的方式进行,即先写一个产品代码类,然后再写一个测试类。但有一点需要强调,无论是哪一种方式,单元测试都要尽早做、持续做,编程和单元测试相当于一对双胞胎,形影不离。
但也有守护敏捷开发模式的铁杆人士,会认为 TDD、持续集成是敏捷开发的内核、核心实践,必须推行 TDD,虽然我更强调,要做好敏捷开发,ATDD 则是必需的。
如果没有 TDD,自然就处于 996 工作模式,干的苦但效果还不好,常常像网络上人们所抱怨的如下情景:
需求分析,还没理解清楚,就开始写代码;
结果,代码写了一半写不下去了,因为需求细节不明确,
只好去跟业务人员确认;
沟通好几次,终于写完这个单元的代码;
然后编译…准备跑程序来做测试,结果跑不起来,只好调试;
调试也没有那么容易,调试好久,终于可以运行了;
提测,即交付给测试,结果 QA 测出一批 bug;
开发只好 debug、改代码,debug、改代码……再提测;
几个来回,终于,代码可以工作了。
过一段时间,换一个程序员,再看这些代码,烂得一塌糊涂,不敢动;
但又不得不动,结果引起大量的回归缺陷,测试只好加班,还夹带着抱怨...
开发的日子就这样日复一日、年复一年。
为何 TDD 是必需的? 说 TDD 是必需的,也有很强的理由,主要有以下几点。
质量是构建的,一次把事情做对,效率是最高的。正如美国质量大师克劳士比极力推崇零缺陷质量管理,为此写了一本《质量免费》,也就是纠正人们错误的观点——要想获得更高质量,就需要付出更高的代价。如果第一次把事情做对,这时效率是最高的,成本也是最低的。在代码层次推行 TDD,先写测试代码,再写产品代码,一方面会逼着开发人员把需求搞清楚、澄清需求细节,而不是像前面所说,没搞清楚就写代码,写了一半就写不下去了;其次,所有写的代码是让测试通过,也就是充分的保证第一次把代码写对。这样,真正推行了 “零缺陷质量管理”,研发效率是最高的。
在《单元测试的艺术》一书中就给了一个案例:开发能力相近的两个团队 A、B,同时开发相近的需求。A 团队进行单元测试,B 团队不做单元测试,虽然 A 团队在编码阶段花费的时间要长一倍,从 7 天增加到 14 天。但是,A 团队在集成、系统测试上却表现得非常好,Bug 数量很少、定位 Bug 很快等。最终,相对 B 团队,A 团队整体交付时间短、缺陷数少。
单元测试,只能是自己做,不适合交给别人做。开发人员自己做测试,如果先实现产品代码,再进行测试,会有思维障碍和心理障碍。测试的思维会受实现的思维影响,一般都会认为自己的实现是正确的,就像我们平时写文章,有明显的错误自己看不见,其他人一眼就能看出,似乎印证了“当局者迷,旁观者清”;其次,心理障碍是指开发人员对自己的代码不会穷追猛打,发现了一些缺陷,很可能会适可而止。
我们知道,实际上缺陷越多的地方越有风险,越要进行足够的测试。有一幅漫画生动说明:开发人员测试自己的代码和测试人员测试开发的代码,其场面完全不一样,如图 1 所示。如果是采用 TDD 实践,开发先写测试代码,测试在前,就不存在思维障碍和心理障碍,这样才能更好地保证测试的有效性、充分性,也就更好地确保代码的质量。

图1 开发测试自己代码和测试人员的测试之对比
(from https://hugelol.com/lol/651590)
TDD 是测试在前,开发在后,自然也保证了代码的可测试性,而且确保 100% 的测试覆盖率,是最为彻底的单元测试,相当于测试脚本在每个时刻都是就绪的,任何时刻看,单元测试都已经是先于代码完成的,真正能做到持续交付,即真正确保敏捷的终极目标——持续交付的实现。没有 TDD,也就没有真正的持续交付。
当初在极限编程(eXtreme Programming,XP)提出 TDD,设计 TDD 那样的模式,如图 2 所示,也是考虑“写新代码”和“代码重构”共用一个模型。而在敏捷开发中,开发节奏快,代码经常需要重构,而重构的前提是单元测试的脚本就绪,你才敢大胆地重构、有信心重构。所以从代码重构角度看,TDD 也是必需的。TDD 做得好,重构会持续进行,代码修改一般也不出什么缺陷,即使出 1~2 个 Bug,都是小问题,很容易修改,并及时补上测试代码。代码的坏味道能及时被消除,代码整洁。
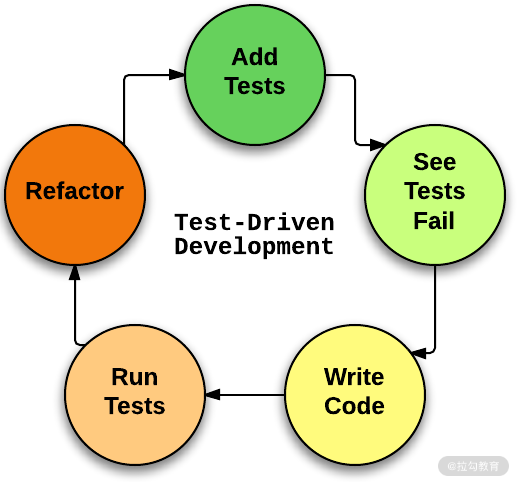
图2 TDD 流程示意图
如何做好 TDD 呢? TDD 从根本上改变了开发人员的编程态度,开发人员不能再像过去那样随意写代码,要求写的每行代码都是有效的代码,写完所有的代码就意味着真正完成了编码任务。而在此之前,代码写完了,实际上只完成了一半工作,远没有结束,因为单元测试还没执行,可能会发现许多错误,一旦缺陷比较多,缺陷就比较难以定位与修正。
那么开发人员如何做好 TDD 呢? Kent Beck 在极限编程中给实施 TDD 定义了两个简单的规则:
- 只有在自动化测试失败时,才应该编写新的业务代码;这一点就是确保编写新的业务代码是在测试的指引下,也是确保了彻底的 TDD,否则今天退让一点,明天再退让一点,最后还是会放弃 TDD;
- 应该消除发现的任何重复,使测试代码简单、易于复用,有利于测试维护。
更为苛刻的规则是三条:
- 除非是为了使一个失败的 unit test 通过,否则不允许编写任何产品代码,确保任何产品代码都来自需求;
- 在单元测试中,只允许编写刚好能够导致失败的一个测试用例(脚本),确保测试的单一性,容易维护;如果单元测试的颗粒度过大,不仅使测试长时间不能通过,增加开发人员的压力,而且后期测试维护成本过高;
- 只允许编写刚好能够使一个失败的 unit test 通过的产品代码,否则产品代码的实现超出当前测试的功能,那么这部分代码就没有测试的保护。
上述这些规则,使开发人员更为关注业务需求,关注可持续的快速开发,用最快的方式实现一个个产品的小需求(小步快跑)。
TDD 是逐步构建的,所以单元测试是持续的,每次测试的东西也比较少,发现问题很容易定位,运行很快,可以快速得到反馈。除此之外,测试代码一定要简单,易于阅读和理解,否则就进入死循环,即测试代码还需要测试。
测试是否容易开展,还取决于被测的对象——组件或具体的产品代码,如将程序组件打磨成高内聚、松耦合的组件,使测试容易进行,即单元测试能够独立执行,而且我们还构建持续集成的开发环境,确保研发环境能够对代码小的变化做出快速的响应。这也就要求用户故事分解到位,之前也提到过用户故事评审标准 INVEST 中的 small——即用户故事要足够的小。
不过,话说回来,定义这些规则是次要的,更重要的是开发人员能够认可 TDD 的价值,愿意主动地去做 TDD。如果是主动去做,在具体实践中遇到问题,也就会设法解决问题或做出改进。如果是被强制实施 TDD,即被动地去做 TDD,不仅不寻求改进,而且还可能会出现“上有政策、下有对策”的局面。
概括起来,TDD 带来的收益,主要有:
- TDD 促进高质量代码的开发,从而提高了研发效率,看似在编程之前花了比较多的时间,但在后期维护、重构中省时省力;
- TDD 克服了开发的惯性思维和心理障碍,确保单元测试的有效性;
- TDD 确保了可测试性,并确保单元测试的充分性;
- TDD 缩短了编程反馈循环,单元测试始终就绪,彻底支持持续交付。
这一讲就讲到这里,最后出一个思考题,TDD 说起来很好,有那么多收益,但现实中,很少有公司能做好 TDD 的,或者说绝大多数的公司都没做。问题是:为什么 TDD 就推不起来呢?最大的障碍是什么?
第43讲:优先实现面向接口的测试
从原理上来说,接口测试是模拟客户端向服务器端发送请求,然后检查能否获得正确的返回信息。这里说的面向接口的自动化测试和 API 测试是一回事。在第 16 讲中介绍测试金字塔模型的时候已经说过,相对上层 UI 测试,自动化测试更适合进行 API 测试。这里的 API 测试是指面向接口的系统功能测试。接口测试越来越重要,不仅因为接口测试与 UI 测试相比性价比更高,还因为目前软件系统的开发模式和架构风格带来的必然需求。
接口(API)测试越来越重要
目前,前后端分离是业界主流的软件系统开发模式。前端设备种类越来越多,不同的前端与后端都是通过事先定义好的 API 进行交互,前后端分离当然也应该在开发过程中分别测试。前端测试可以搭建一个 Mock Server 模拟后端给出的响应;后端,即服务器端,就可以通过调用 API 直接对其进行接口测试。另外,后端系统的性能测试基本都要依赖接口进行测试,关注在各种并发情况下服务器端的响应时间、资源使用情况等。另外,需要通过接口测试对后端系统进行安全性测试,比如验证前后端传输信息是否加密等。
微服务架构是目前主流的软件系统架构的设计风格。一个软件系统的微服务之间通过 HTTP、RPC 等协议进行通信,通常是基于 HTTP 协议的 RESTful API,比如主流的 Spring Boot 开发框架等。这种架构带来的主要优点是每个微服务可以独立开发、独立部署,自然需要单独验证每个微服务的功能,而验证的方式就是 API 测试。
不仅软件系统自身正趋向于 API 化,软件产品也通过对外开放的 API 提供和外部系统的集成能力。现在人们更倾向于把 API 作为产品和服务,API 的消费者既包括外部合作伙伴,也包括企业内部的系统或开发人员。做好这类 API 的测试也是软件测试的目标之一。
接口测试示例
根据接口所遵循的协议,常见的接口包括 HTTP 接口、Web Services 接口、RPC 接口等。HTTP 接口支持 HTTP 应用传输协议,Web Services 接口一般采用 SOAP 协议;而 RESTful 既可以用于 HTTP 接口,也可以用于 Web Services 接口。
可以支持接口测试的开源工具有很多,第 19 讲已经介绍过。对于常用的 Postman、JMeter、REST-Assured 等,就不拿来做例子了。这里我介绍一款大家可能不太熟悉的,但是非常好用的接口测试工具 Karate,并且结合 Karate 来介绍 RESTful API 的接口测试。
Karate 是基于 Cucumber-JVM 构建的开源测试工具,目前已经位列 TOP10 最好用的 API 测试工具之一。和 Cucumber 一样,它也使用 Gherkin 语言以 Given-When-Then 格式来描述测试场景,因此也是 BDD 风格的工具。
另外,Karate 还具有以下特点:
- 支持多线程并发测试;
- 不仅支持包括 Restful API 和 SOAP 不同风格的 Web Service 接口测试,也支持 UI 测试和性能测试;
- 可以像标准 Java 项目一样运行测试并生成界面友好的 HTML 报告;
- 可以在配置文件里添加全局的配置信息,作用于每个测试用例,比如可以设置全局变量、连接超时时间、retry 等。
不过,相比其他测试工具,Karate 最显著的优点是不需要额外编写 Java、Python 等语言的测试代码,因此非常容易上手使用。Karate 的安装配置也非常简单,具体可以参考其官网上的介绍以及大量的代码示例: https://github.com/intuit/karate。
现在我用 Karate 来开发一个接口测试的测试用例。假定需要对一个可以增、删、改、查用户信息的 RESTful API 进行测试。
第一个场景是请求所有用户信息,它返回的 Response 信息为 JSON 格式的用户列表,如图 1 所示。
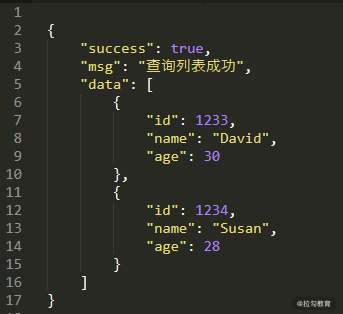
图1 用户查询返回的 Response 信息
第二个场景是添加 3 个新的用户。第三个场景是更新用户 ID 为 1234 的用户信息。第四个测试场景是删除用户 ID 为 1233 的用户。测试用例代码 .feature 文件如图 2 所示。
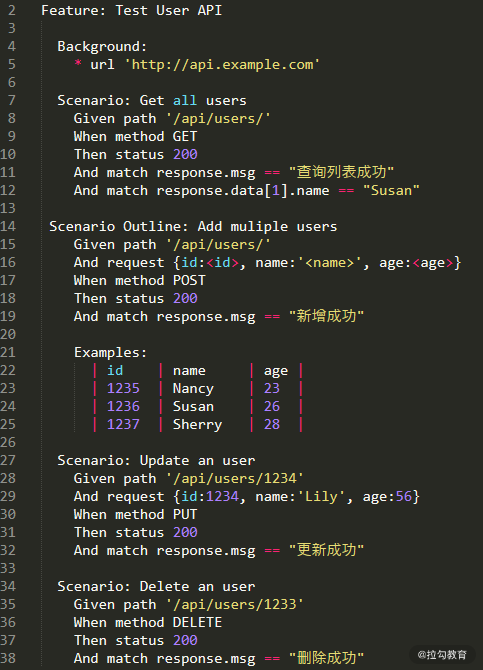
图2 Karate 接口测试代码示例
上面是一个单接口测试的例子,并不足以展示 Karate 支持复杂场景的强大功能。在实际的测试中,一个业务场景往往是由多个接口的串行调用完成的。并且,一个业务操作会触发后端一系列 API 的级联调用,而后一个 API 需要使用前一个 API 返回结果中的某些信息才能进行测试。图 3 是 Karate 官网中的一段测试代码,在这段代码中,第二个 API 的调用地址就是第一个 API 返回结构中的 ID 信息。
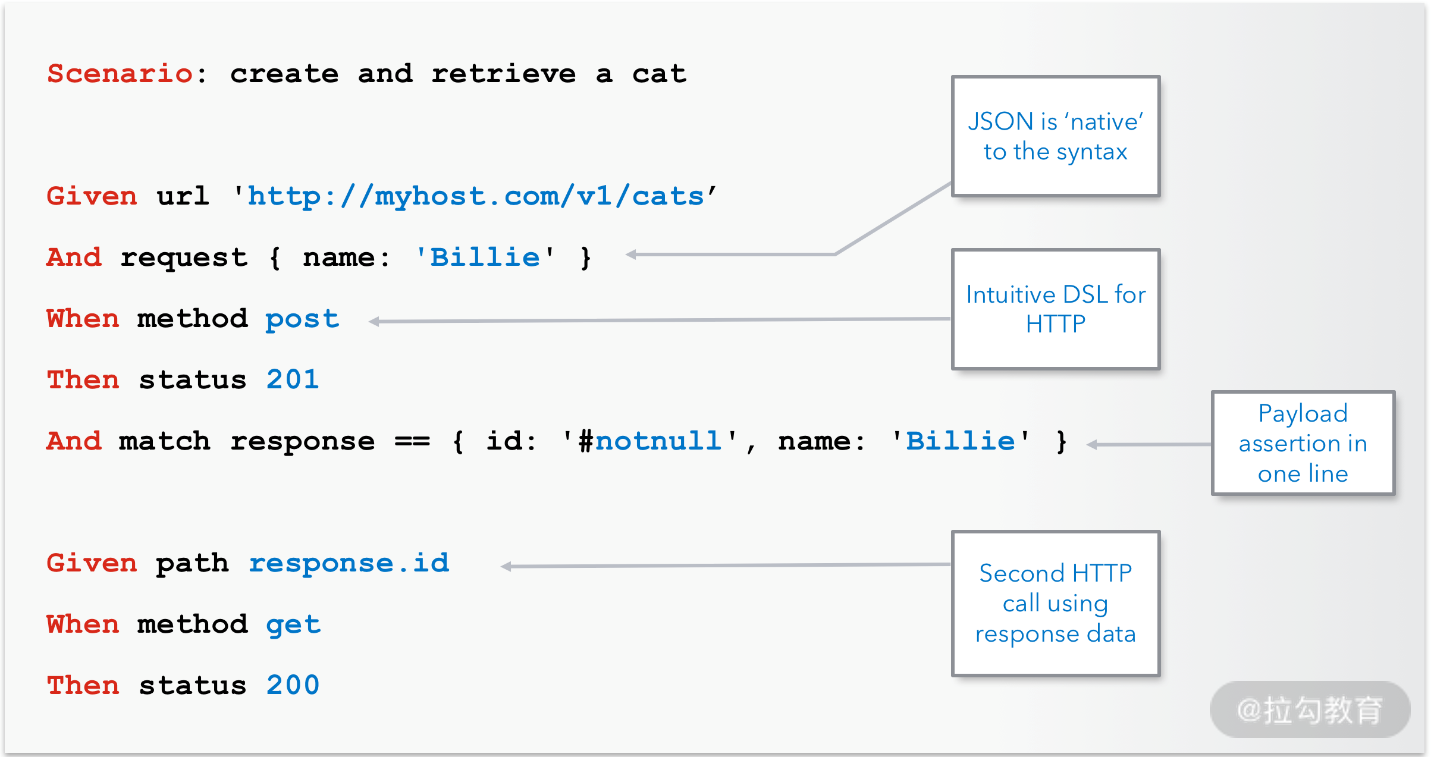
图3 Karate 接口调用链的测试
如果只是单接口的测试,使用 Postman 工具进行调试会更方便。在实际工作中,我建议你把 POSTMAN 和 Karate 结合起来使用。先用 Postman 进行单个接口的测试,验证返回的响应信息是否正确,等单个接口调试好了再用 Karate 编写测试脚本把多个 API 串联起来完成面向业务的接口测试。
如何获取接口信息
获得完整的接口信息是开展接口测试的基础,否则测试人员怎么知道系统定义了哪些 API 需要测试,每个 API 的请求信息怎么写,响应结果根据什么来验证?而接口文档是获取接口信息的重要途径。如果没有接口文档,测试人员只能通过抓包工具 (如 Fidder、WireShark 等)访问前端界面获取接口信息,费时费力不说,而且相当被动,对于接口的变动总是后知后觉。
接口文档的主要内容应该包括:调用地址 URL、调用方式(如 GET、PUT 等)、请求信息的格式、响应信息的格式及示例等。在前后端分离的系统中,因为前端和后端的交互只能通过接口来实现。良好的接口文档是加强前后端开发协作的基础,否则很容易发生接口不匹配,从而影响前后端的集成。而对于微服务架构的软件系统,微服务之间的调用关系往往非常复杂,需要定义的 API 也非常多,不同的微服务可能由不同的团队负责开发,接口信息的管理和维护更是一个挑战。
如果是开发人员手工编写接口文档,维护工作量比较大,很难做到实时更新。下面介绍两种比较好的接口文档管理方式。
第一种是利用 Swagger 工具动态生成接口文档。Swagger 是一套工具包,提供 API 文档编辑、生成、呈现及共享等功能,还可以执行 API 自动化测试。其中,Swagger UI 通过在产品代码中添加 swagger 相关的注释,生成 json 或 yaml 格式的 API 文件,然后通过 Web 界面呈现出来,供文档的用户访问查询。
Swagger UI 对 Spring Boot 的项目提供了很好的支持。由 Swagger 生成的接口文档如图 3 所示。我找了一个使用 Swagger 生成在线文档的开源项目作为例子(https://gitee.com/yidao620/springboot-bucket/tree/master/springboot-swagger2),建议用 Intellij IDEA 打开,POM.xml 中需要添加一个依赖:
<dependency><groupId>javax.xml.bind</groupId><artifactId>jaxb-api</artifactId><version>2.3.0</version>
</dependency>
编译成功后启动 com.xncoding.jwt 目录下的 Application,然后访问 http://localhost:9095/swagger-ui.html 就得到如图 4 所示的在线接口文档了。
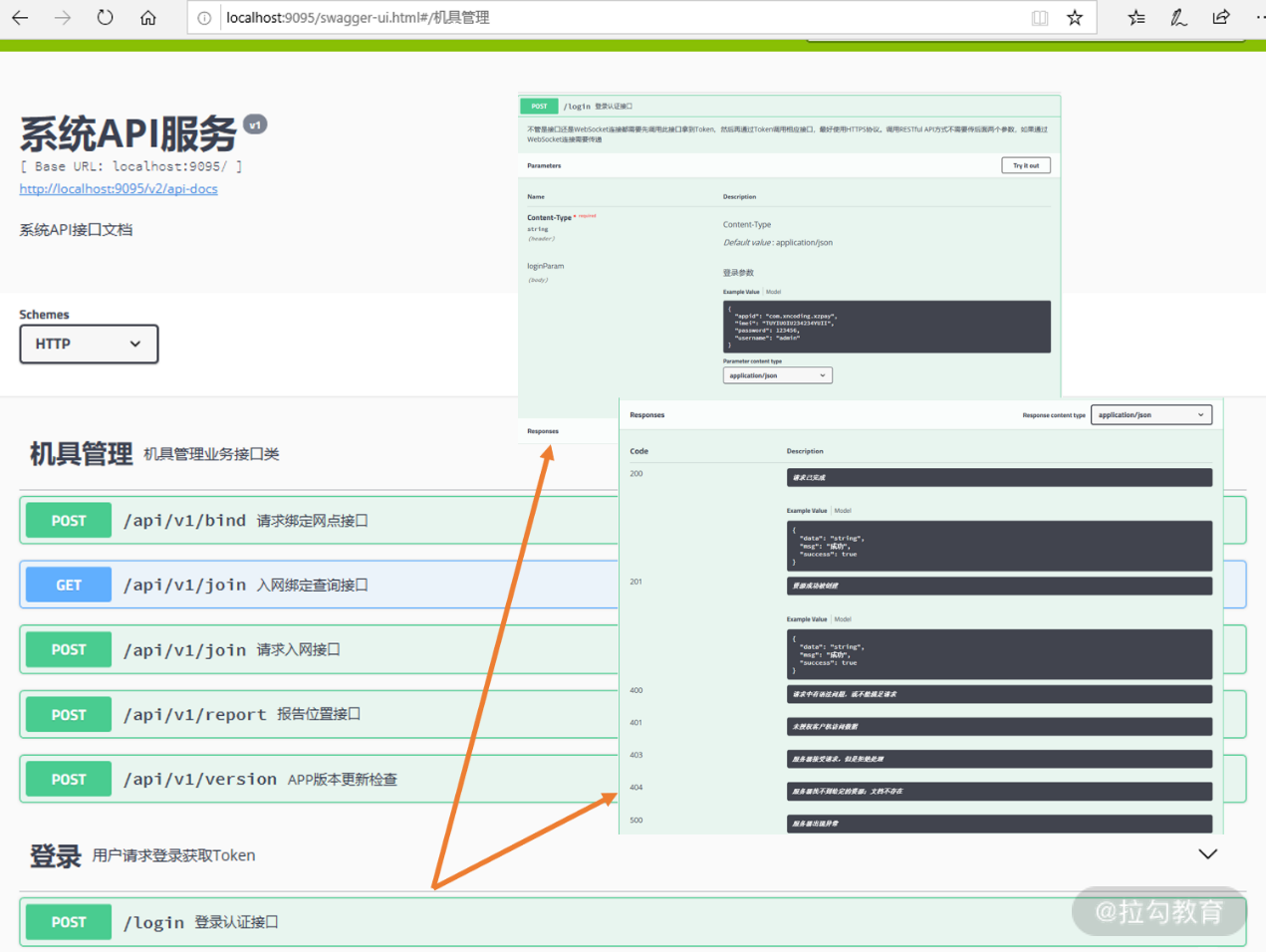
图 4 Swagger 生成的动态接口文档示例
另外一种方式是契约形式的接口文档,契约规定的是接口的调用者和被调用者之间约定的 Request 和 Response 数据交互格式。这里不得不提一下契约测试方法,又叫消费者驱动的契约测试(Consumer Driven Contract, CDC),在契约测试里,接口的调用者被称为消费者,被调用者称为提供者。其核心思想在于从消费者业务实现的角度出发,由消费者自己定义需要的数据格式及交互细节,并驱动生成一份消费者契约。然后开发者根据契约分别实现自己的业务逻辑,并在服务提供者端进行测试,验证所调用的接口是否按照契约规定的内容返回正确的信息。主流的契约测试工具包括 PACT、Spring Cloud Contract。通过契约测试可以生成需要的契约文档,存放在代码仓库里。
前端根据这份契约,可以搭建一个 Mock Server 模拟后端服务器的响应,在对前端的测试中所有需要和后端交互的场景下请求都发往这个 Mock Server,以此达到前后端调试的解耦。
契约测试和微服务的接口测试
对于微服务来说,应用契约测试的方法进行接口测试比较高效,只要验证被调用的接口组合(已实现的业务逻辑),没有被调用的接口(用不到的逻辑)无须测试。另外,开展微服务的接口测试也需要根据契约,搭建 Mock Server 来实现微服务之间的解耦。一个大型软件系统由多个微服务组成,通常完成一个业务操作需要调用多个服务才能完成。但是,微服务之间的相互调用和依赖关系又比较复杂,如图 5 所示。
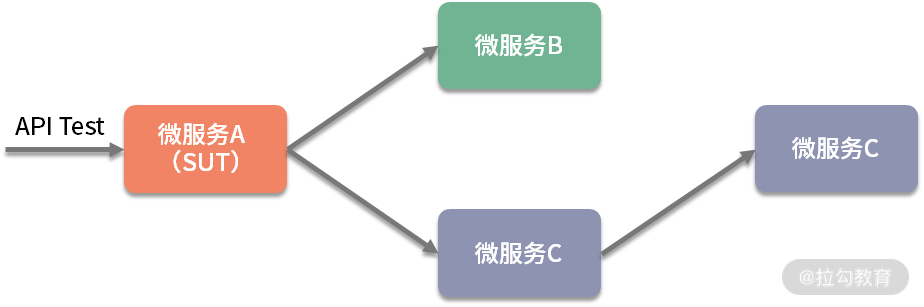
图5 微服务之间的依赖关系
当我们对 A 进行接口测试时,A 又会调用 B 和 C,C 又会调用 D,因为微服务都是独立开发的。当 B、C 或者 D 中的任何一个处于不可用状态时,针对 A 的接口测试无法进行。要想在测试中解除微服务 A 对其他服务的依赖,就要用到 Mock 技术。这里是指启动 Mock Service 代替 B 和 C 来响应服务 A 发出的请求,而这时服务 C 对 D 的调用也无须再关心,如图 6 所示。
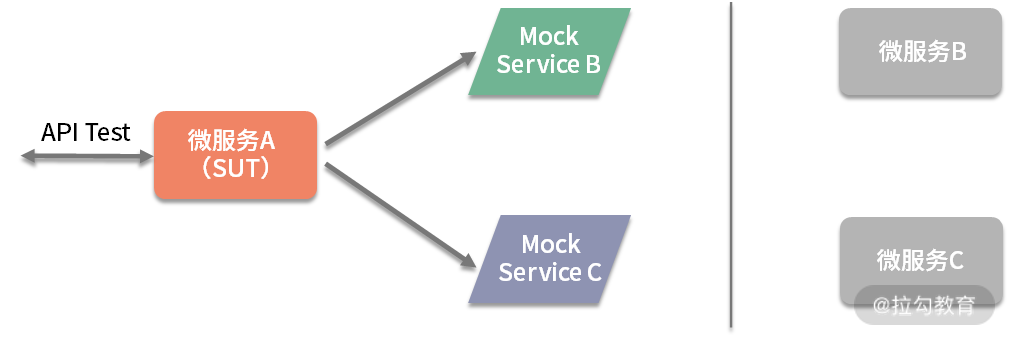
图6 利用 Mock 技术解除微服务之间的依赖
像 WireMock 和第 15 讲介绍过的服务虚拟化工具 Hoverfly 都提供了在 API 层面 Mock 微服务的功能,另外还有不少 Mock 框架比如 Mokito、Moco 等。Mock Server 在搭建过程中,一个重要方面就是定义出需要模拟的请求和响应,上面说的契约文档在这里就发挥了作用。可以根据微服务 A 和 B、A 和 C 之间的契约文件很容易创建出 Json 格式的请求和响应信息文件,如图 7 所示。当 Mock Service 启动后,不必启动真实的应用,我们再执行如图 2 所示的测试 GET 的测试用例,Mock Service 就可以代替真实应用给出响应。
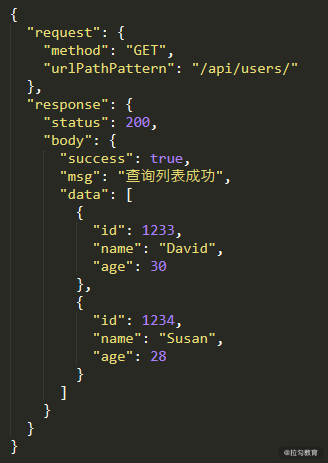
图7 Mock 请求和响应信息示例
AI 助力接口测试
对于 UI 自动化测试来说,接口测试确实具备更大的优势,但同时,也需要负责接口测试的人员具备更高的技术能力,包括对系统架构和接口设计的了解,熟练使用各种工具和技术编写测试脚本、执行接口测试、分析接口信息及接口调用链信息等。
人们已经开始研究如何应用 AI 技术降低接口测试的复杂度。比如,当工程师在 UI 界面上进行操作,利用 AI 技术可以监控系统后台运行,通过分析获取的数据得到 API 调用序列,以及请求和响应信息,进而自动生成 API 测试用例。另外,还可以结合人工智能算法来完善接口测试需要的测试数据。相信在未来 AI 技术一定可以极大提高接口测试的效率。
今天这一讲到这里就结束了,主要结合 Karate 介绍了接口测试的开发、如何获取接口信息,以及微服务的接口测试如何实现服务之间的解耦,还有 AI 技术在接口测试中的应用前景。
今天给你出的思考题是:Karate 和你用过的其他接口测试工具相比,是否更有优势?
第44讲:大数据+AI 系统的测试设计与执行
人工智能时代的到来,也意味着大量的人工智能系统需要得到测试和验证。而人工智能的测试最早可以追溯到上个世纪五十年代,即 1950 年阿兰·图灵(A.M.Turing)在那篇名垂青史的论文《计算机器与智能》(Computing Machinery and Intelligence)中第一次提出了“图灵测试”。
图灵测试就是为了验证论文所提出的“机器能够思考吗”这样的问题,假如某台机器“表现得”和一个思考的人类无法区分,这并不要求百分之百无法区分,而只要有 30% 的机会能骗过裁判,那么就认为机器能够“思考”。机器想通过图灵测试,还真不容易,直到 64 年后——2014 年在英国皇家学会举行的图灵测试大会上,聊天程序 Eugene Goostman 冒充一个 13 岁乌克兰男孩而骗过了 33% 的评委,从而“通过”了图灵测试。
人工智能发展到今天,已经接近 70 年,比软件工程的历史还长近 20 年,经历了两次浪潮和两次低谷之后进入今天的第 3 次浪潮。之所以,能进入第 3 次浪潮,完全是由于大数据的推波助澜,有了数据,才能训练出更好的模型。当然,也离不开今天发达的网络、廉价的存储能力和超强的计算能力(如 GPU)。
我们进入了一个大数据 + 人工智能的时代,所以用一讲来讨论一下大数据 + 人工智能的测试设计与执行,虽然篇幅极其有限,希望能带给你一些启发和帮助,将来若有需要,可以专门开一个“大数据+人工智能测试”专栏。
大数据的测试
大数据的特点,大家应该比较清楚了,经常用 4V 来表示,即数据规模大(Volume)、变化快或动态性强(Velocity)、多样性(Variety)和低价值密度(Value)。
针对大数据测试,覆盖数据采集、数据存储、数据加工等各个方面的验证,重点是在数据输入/输出、处理过程 ETL(Extract-Transform-Load、抽取-转换-加载)以及基于数据模型的业务应用等的功能测试、性能测试、可靠性测试等多种测试类型。其中基于数据模型的业务应用,一般和人工智能直接相关,将作为下一个主题讨论,主要是算法、AI 模型等的验证。
大数据的性能测试是一个重点,不仅要处理大规模的数据(数据量很大),而且数据种类多、数据变化快,这给大数据的性能测试带来时空上的挑战,特别是在 Test Oracle 上,会面临更大的挑战。因为经过大数据的处理,结果是否正确,很难设计一个明确的判定标准,但同时又和 AI 融合在一起,导致算法、模型、数据质量等问题相互容易,难以分辨。所以,算法、代码评审更有价值,在整个 ETL 处理过程中能讲清楚、解释合理,就能增加我们对质量的信心。最终是否正确,需要实践检验,包括 A/B 测试。
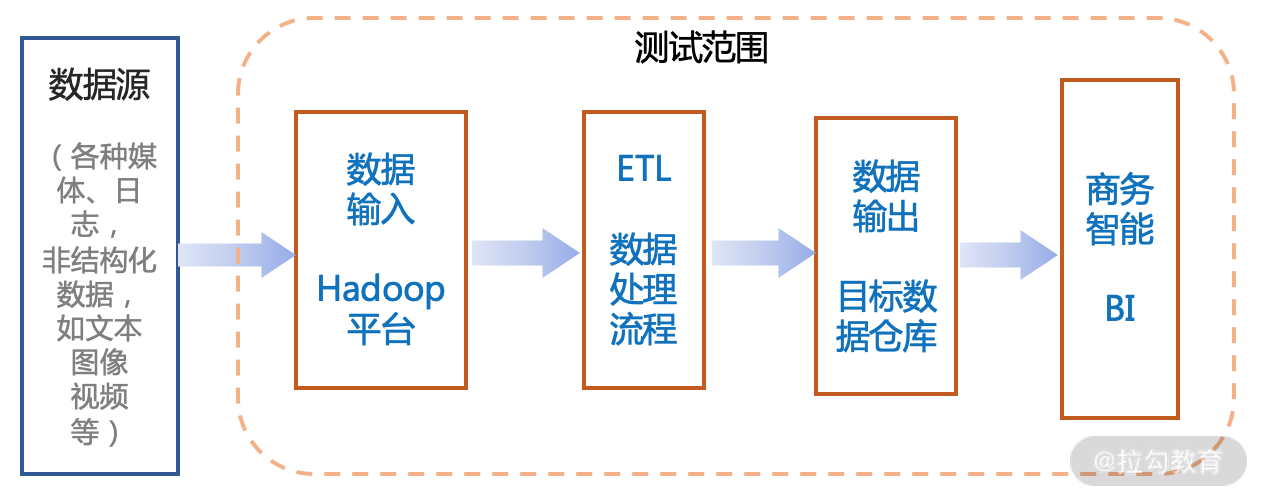
图1 大数据应用基本结构示意图
这里以 Hadoop、MapReduce 平台为例,具体测试分为 3 个阶段分别进行,通过过程的验证才能更好地保证输出的质量。
(1)数据阶段验证
这是数据预处理及其加载的验证,如使用工具 Talend 或 Datameer,验证下列内容:
- 验证来自各方面的数据资源,检查来自各个数据源的数据是否被加载到数据系统(如 Hadoop 系统)中;
- 检查相关数据是否以正确的格式、完整地被读入数据系统中;
- 检验上传数据文件过程中,是否有异常数据流入存储或运算系统中,如果突然中断,系统能否有提示、是否会挂起;
- 将源数据与加载到数据系统中的数据进行比较,检查它们是否匹配、一致;
- 验证数据是否正确地被提取并加载到数据存储管理系统(如 HDFS)中。
(2)数据计算验证
这个阶段侧重每个节点上的业务逻辑计算验证,一般需运行多个节点的分布计算后再进行验证,检查下列操作:
- 分布式计算(如 Map 与 Reduce 进程)能否正常工作;
- 在数据上能否正确地实现数据聚合或隔离规则;
- 业务逻辑处理是否正确、是否能正确生成键值对等;
- 验证数据在分布式计算(Map 和 Reduce 进程执行)后是否正确;
- 测试一些异常情况,比如数据输入中断、给算法喂的数据过大或过小等。
(3)输出阶段验证
对数据输出进行验证,包括对输出的数据文件及其加载等进行验证:
- 检查转换规则是否被正确应用;
- 输出结果的各项指标表现如何?
- 检查数据是否完整、准确,数据是否被及时加载到目标系统中;
- 用户可见的数据信息是否准确有序地呈现出来;
- 可视化图表的展示是否正确、美观;
- 通过将目标数据与 HDFS 文件系统数据进行比较来检查是否有数据损坏。
除此之外,只要是面对数据进行测试,就需要考虑数据的安全性、完整性、准确性、一致性等,例如:
- 数据安全性,数据存储是否安全,备份的间隔时间是多少,备份的数据能否及时、完整得到的恢复;
- 数据的完整性,数据各个维度是否覆盖了业务全部特性、数据的记录是否有丢失,或某条数据是否有部分字段信息丢失等。
但是为了提高测试效率,在进行功能测试而不是性能测试时,一般只选取少量典型的测试数据集进行测试,即选取那些能覆盖计算逻辑和边界场景的测试数据。这时就需要用到很普通的测试方法了,比如等价类划分、边界值分析方法和组合测试方法等。
人为构造的数据无论是在分布形态还是异常场景覆盖上都比不上真实的生产数据,而由于测试数据对异常场景的覆盖不足,在系统上线后,很有可能会导致算法失效或系统崩溃等严重问题。如果可能,要尽可能导入真实数据来进行测试。现在在大数据的性能测试中,流量回放就是人们开始采用的测试方法。
AI 的测试
人工智能的测试侧重算法验证、学习模型评估和特征项专项测试等,算法和模型的验证,会通过实验评估算法自身的度量指标,如准确率、灵敏度、召回率等进行验证,也会采用蜕变测试、模糊测试等方法来验证算法的可靠性和可解释性等。
- 即使在 AI 领域的测试,过去所学的测试方法,也有用武之地,比如采用不同数据集进行多次验证,验证算法在不同数据下的表现、探究算法的边界、算法在边界会不会出现异常情况。
- 可以采用白盒测试方法,基于算法的结构进行验证,如对神经元及其连接的覆盖,也可以采用黑盒方法,针对 AI 输出的结果进行验证。比如上面所说的图灵测试和 A/B 验证,A/B 测试将会在下一讲讨论。
- AI 测试可以是手工测试,直接让测试人员来进行验证,比如图灵测试或直接让特定领域的专业人士(如李世石、柯洁和 AlphaGo 对弈等)来完成测试;也可以进行自动化测试,让它们自我博弈,如 AlphaGo 的下一代产品 AlphaZero。
AI 系统的白盒测试
以现在最流行的深度学习神经网络算法为例来讨论如何进行白盒测试,并参考一些学者的论文(如 Youcheng Sun 等的论文 Testing Deep Neural Networks)。深度神经网络包含许多层连接的节点或神经元(Neuron),如图 2 所示,一个简单的人工神经网络模型,含有多层感知器。
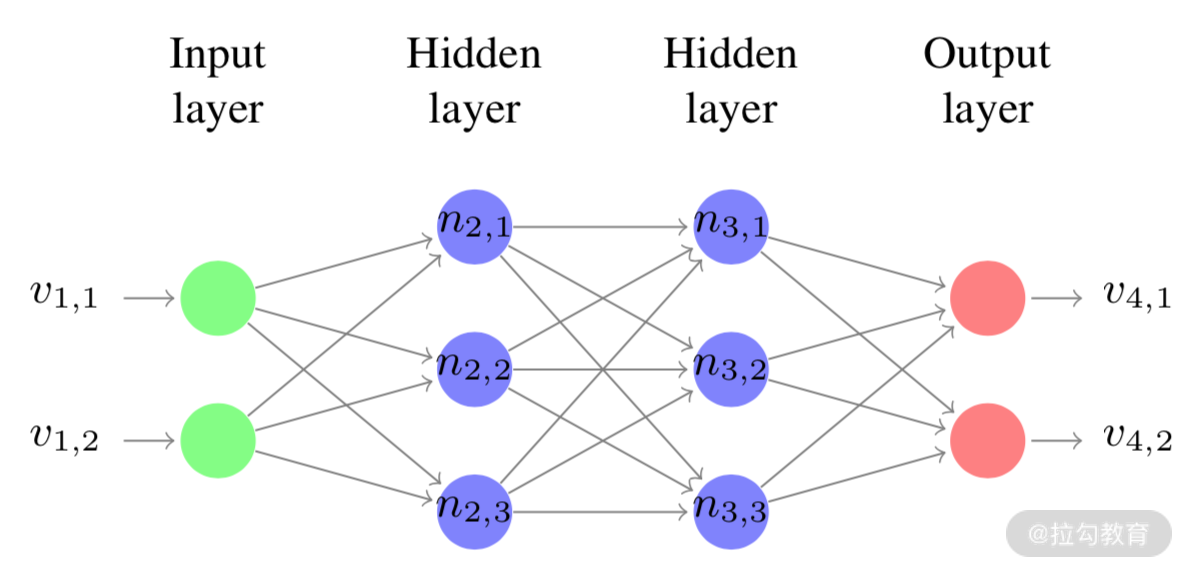
图2 简单的人工神经网络模型示意图
每个神经元接受输入值并生成输出值或输出矢量(激活值),每个连接都有权重,每个神经元都有偏差。根据输入值、输入连接的权重和神经元的偏向(Bias Unit,偏置单元),通过公式来计算输出值。传统的覆盖率度量对于神经网络并没有真正的用处,因为通常使用单个测试用例即可达到 100% 的语句覆盖率。 缺陷通常隐藏在神经网络本身中,所以必须采用全新的覆盖率度量方法,可以概括为 6 种度量方法。
- 神经元覆盖(Neuron Coverage):激活的神经元的比例除以神经网络中神经元的总数,如果神经元的激活值超过零,则认为该神经元已被激活。
- 阈值覆盖率(Threshold Coverage):超出阈值激活值的神经元的比例除以神经网络中神经元的总数,阈值介于 0 和 1 之间。
- 符号变更覆盖率(Sign Change Coverage):用正激活值和负激活值激活的神经元的比例除以神经网络中神经元的总数。激活值零被视为负激活值。
- 值变更覆盖率(Value Change Coverage):定义为激活的神经元的比例,其中其激活值相差超过变化量除以神经网络中神经元的总数。
- 符号-符号覆盖率(Sign-Sign Coverage):如果可以显示通过更改符号的每个神经元分别导致下一层中的另一个神经元更改符号,而下一层中的所有其他神经元保持相同(即它们不更改符号),则可以实现一组测试的符号覆盖。从概念上讲,此级别的神经元覆盖率类似于 MC/DC(修正的条件/判定覆盖)。
- 层覆盖(Layer Coverage):基于神经网络的整个层以及整个层中的神经元集合的激活值如何变化来定义测试覆盖率。
当前还没有成熟的商用工具来支持神经网络的白盒测试,但有几种实验性工具:
- DeepXplore,专门用于测试深度神经网络,提出了白盒差分测试算法,系统地生成涵盖网络中所有神经元的对抗示例(阈值覆盖);
- DeepTest,系统测试工具,用于自动检测由深度神经网络驱动的汽车的错误行为,支持 DNN 的符号-符号覆盖;
- DeepCover,可以支持上述定义的所有覆盖率。
AI 系统的算法验证
不同类型算法的验证,其关注的模型评估指标也不同,比如人脸检测算法评估指标主要有准确率(Accuracy)、精确率(Precision)、召回率(Recall)等,其次,相同类型算法在不同应用场景其关注的算法模型评估指标也存在差异。比如在高铁站的人脸检索场景中,不太关注召回率,但对精确率要求高,避免认错人或抓错人,造成公共安全事件。但在海量人脸检索的应用场景中,愿意牺牲部分精确率来提高召回率。
算法验证中,还会有一堆指标需要验证,例如:
- 受试者操作特征曲线(Receiver Operating Characteristic curve,ROC 曲线),以真阳性概率(TPR)为纵轴、假阳性概率(FPR)为横轴所构成的坐标图,它反映敏感性和特异性连续变化的综合指标,其上每个点反映出对同一信号刺激的敏感性,适用于评估分类器的整体性能,如图 3 所示;
- AUC(Area Under the Curve)是 ROC 曲线的面积,用于衡量“二分类问题”机器学习算法性能(泛化能力);
- P-R(Recall-Precision)曲线用来衡量分类器性能的优劣,如图 4 所示;
- Kappa 系数:度量分类结果一致性的统计量,是度量分类器性能稳定性的依据,Kappa 系数值越大,分类器性能越稳定。
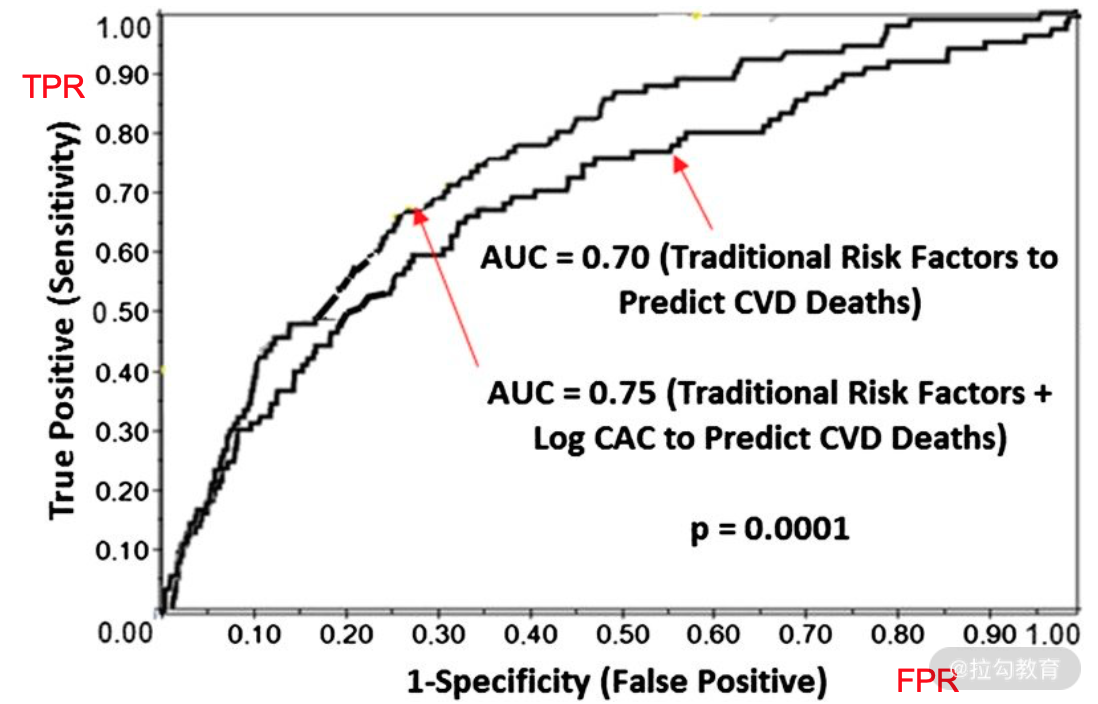
图3 ROC 曲线示意图
其中:
- 真阳性概率( TPR(True Positive Rate)= TP/(TP+FN);
- 假阳性概率 FPR(False Positive Rate = FP/(TN+FP);
- TP(True Positive),预测类别是正例,真实类别是正例;
- FP(False Positive),预测类别是正例,真实类别是反例;
- TN(True Negative),预测类别是反例,真实类别是反例;
- FN(False Negative),预测类别是反例,真实类别是正例。
而:
- 预测值与真实值相同,记为 T(True);
- 预测值与真实值相反,记为 F(False);
- 预测值为正例,记为 P(Positive);
- 预测值为反例,记为 N(Negative)。
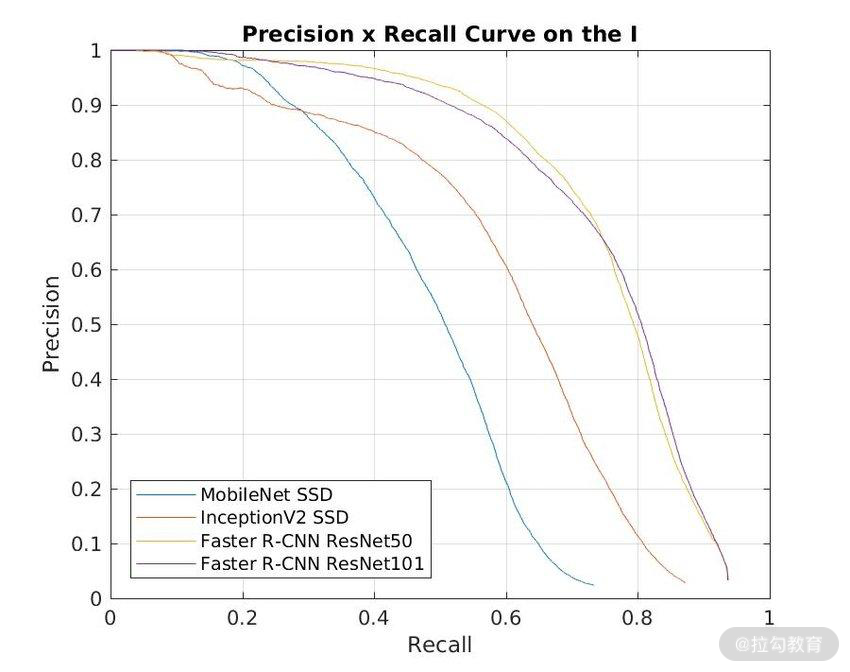
图4 P-R 曲线示意图
算法测试的核心是对机器学习模型的泛化误差进行评估,为此使用数据测试集来测试学习模型对新样本的差别能力,即以测试数据集上的测试误差作为泛化误差的近似。测试人员使用的测试数据集,只能尽可能地覆盖正式环境用户产生的数据情况,发现学习模型的性能下降、准确率下降等问题。
这样,如何选取或设计合适的测试数据集,将成为算法验证的关键,一般要遵循下列 3 个原则。
- 根据场景思考真实的数据情况,倒推测试数据集。例如,需要考虑模型评价指标、算法的实现方式、算法外的业务逻辑、模型的输入和输出、训练数据的分布情况等。
- 测试数据集独立分布。开发者选择一个数据集,会分为训练数据集和验证数据集,而测试集不能来自开发那个数据集,而应该独立去收集或获取一个全新的数据集,这就是我们通常所说的,机器学习需要三个数据集。
- 测试数据的数量和训练数据的比例合理,如果拥有百万数据,只需要 1000 条数据,便足以评估单个分类器,并且准确评估该分类器的性能。如果觉得还不够,可以选择 1 万条数据作为测试集。
除了上述算法模型评估指标,我们还常用 ROC、PR 曲线来衡量算法模型效果的好坏。
这一讲就讲到这里了,最后出一个思考题,学习完本讲之后,针对自动驾驶系统,可以列出其测试设计的几个要点吗?
第45讲:测试右移:在线测试与日志分析
到这里,你已经学习了敏捷测试专栏的 6 个模块,从敏捷测试的概念和文化、测试基础设施、再到敏捷测试的分析与计划、设计与执行,并且也讲解了测试左移。从这一讲将进入第 7 个模块,也是本专栏的最后一个模块——敏捷测试的收尾与改进。收尾只是针对即将交付的这一版软件来说,实际上,只要有新的版本发布,就会进入新的测试周期。在收尾过程中,既需要关注上线版本的运行情况、及时修复严重缺陷,又要收集和分析用户反馈和线上数据,为下一个版本的缺陷预防做准备。同时,团队也需要在实践中不断地反思和总结,持续地改进测试过程。
在这个模块的开篇要介绍的是测试右移。测试右移指的是软件发布之后的在线测试——在产品运行环境上进行测试(Testing in Production,TiP),ThoughtWorks Martin Fowler 2017 在其博客上有一篇文章专门介绍了 TiP。如果软件产品作为服务(SaaS)部署在研发公司自己的数据中心或者公有云上,在上线部署后,依然可以监控并分析系统的行为,有问题可以快速修复,并且像 A/B(易用性)测试、性能测试、安全监控等都可以在线进行。
但因为是在真实的生产环境中,数据也是真实的,所以在线测试就不能为所欲为,更多的是监控产品的应用过程,通过日志来分析系统的行为,发现软件的问题。同时,通过日志分析也可以获得用户行为相关的信息,为进一步提升用户体验提供依据。虽然这不能算是测试,但也是为了改进产品质量,也深具价值。
混沌工程:基于故障注入的测试
每年一些云平台都会发生一些不同类型的线上故障,其中阿里云对于其在 2018 年 6 月 27 日线上故障的说明中写道:“这一功能在测试环境验证中并未发生问题,从上线自动化运维系统后,触发了一个未知代码 bug”。由此可见对于大规模、高复杂度的服务器系统来讲,仅仅是在测试环境进行测试就已经无法满足质量需求了,如何在产品环境下进行测试必将会在现在及未来云时代中占据重要位置。
随着云平台越来越庞大、越来越复杂,普通的测试用例已经很难满足高可用的需求了,所以基于故障注入的测试(Failure Injection Testing,FIT) 也越来越重要。其中 Netflix 甚至在其产品环境中大规模的使用 FIT,而不仅仅是在测试环境中。Netflix 在其官方博客中发表了多篇关于 FIT 的文章,宣传其在产品环境中做了大量的 FIT 及其收益。在未来越来越复杂的云服务时代,对于一个追求质量的系统,FIT 肯定是必不可少的。
关于混沌工程,可以参考 Netflix 公司编写的电子书 Chaos Engineering,也可以参考阿里开源混沌工程工具 ChaosBlade,如图 1 所示。
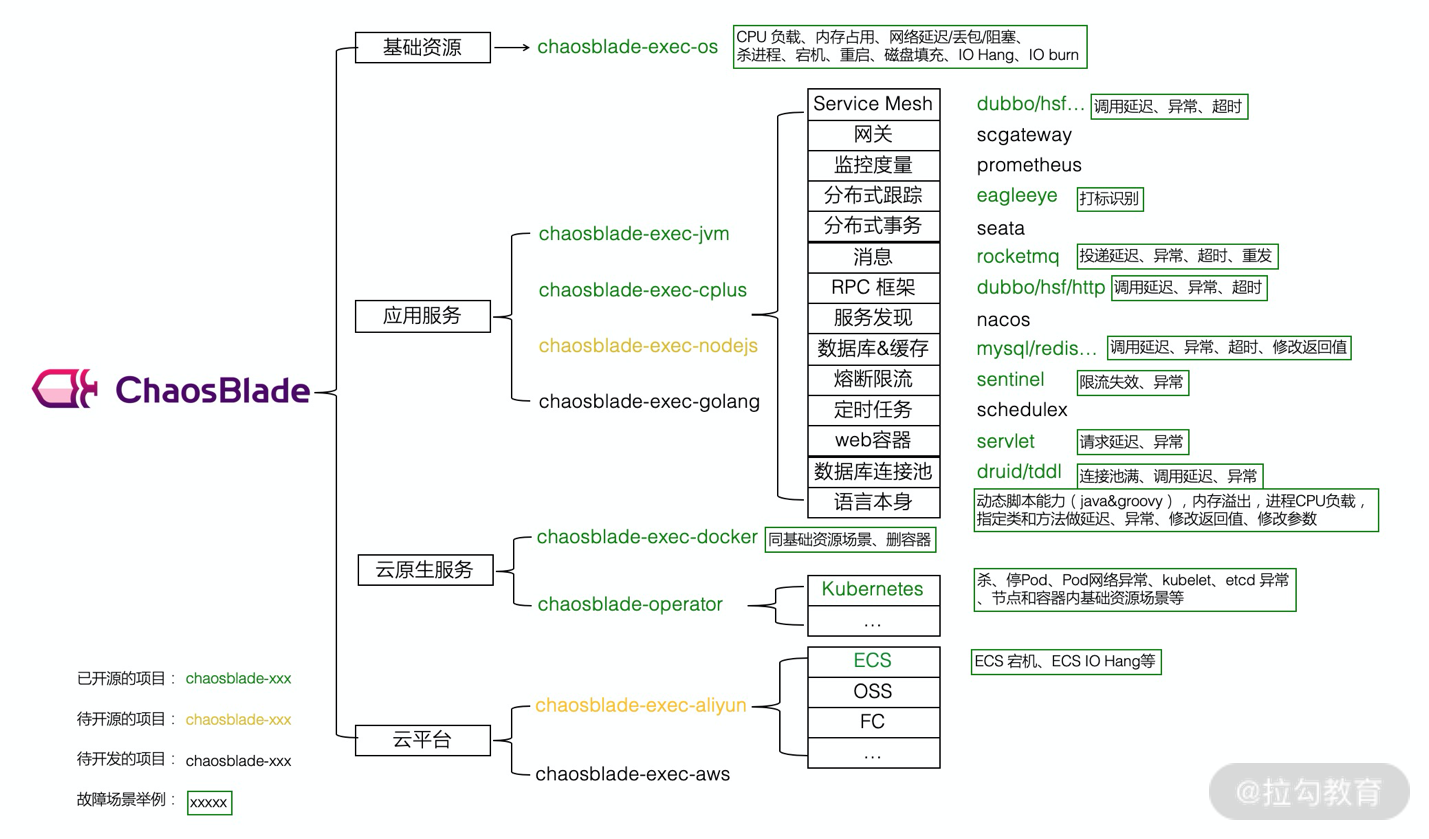
图1 混沌实验概貌(源自:https://github.com/chaosblade-io/)
在线性能测试
软件系统经过了研发过程中的性能测试,在研发环境中满足了性能需求。但是,庞大的用户群体、跨地区/跨国家的用户访问、数以万计的移动端设备种类和型号等生产环境中的真实场景,在研发环境中不可能全面覆盖。在线性能测试是指借助监控工具,监控系统性能的实际数据,因为是真实数据,比研发环境中通过工具产生负载得到的测试结果更客观,更有分析价值。
另外,对于规模较小的互联网公司,一个新产品上线时用户比较少,对于性能的要求不会太高,一般情况下用户数量是逐渐增加的。在研发环境中做完整的性能测试费钱又费时,可以考虑在系统上线后进行性能测试——在线性能监控,发现性能瓶颈、内存泄露等问题,实现持续测试、持续调优。这样不仅可以让公司节省一大笔开支,也赢得了快速发布的时间。
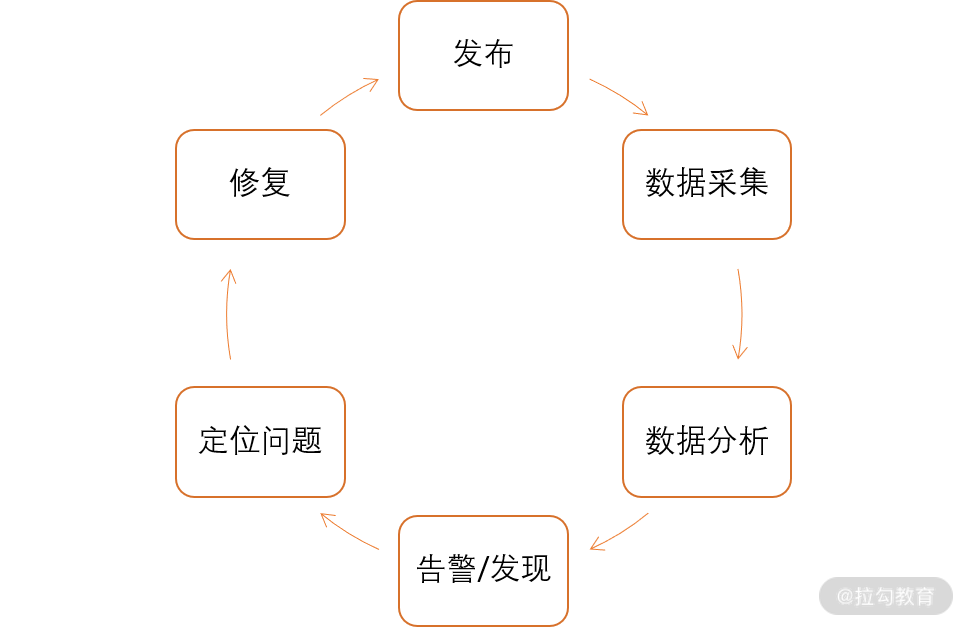
图2 在线性能监控流程
在线性能监控系统需要监控的点很多,包括前端、应用服务器、中间件、Web 服务器、队列、缓存、数据库、网络等。要监控的性能指标也很多,比如用户关心的页面加载时间、用户输入响应时间,业务角度需要关心的系统吞吐量、并发用户数,技术角度需要关心的内存、CPU 使用情况等。对于微服务架构的分布式软件系统,还需要通过追踪微服务调用链分析并定位链路上的性能瓶颈。
前面提到过的在线性能监控工具包括: AppDynamics、Datadog、DynaTrace、New Relic、CollectD、StatsD 等。还有分布式系统的链路及性能监控工具 SkyWalking、PinPoint 等。
在线安全监控
在研发阶段可以完成代码的静态分析、安全性功能验证、渗透测试等。产品上线后,通过监控、检查发现系统的安全性漏洞并及时修正也是一项重要的工作,这样的工作可以看作是系统安全性的在线测试。就是为了保障软件系统操作的合规性和数据的安全性,运用各种技术手段实时收集软件系统运行过程中的状态、数据的危险变更、用户操作活动等信息,以便集中记录、分析和报警。
实现在线安全监控需要建立一套相对完整的运维安全监控与审计框架,如图 3 所示,具备监控、审计、预防、恢复和支撑等功能。
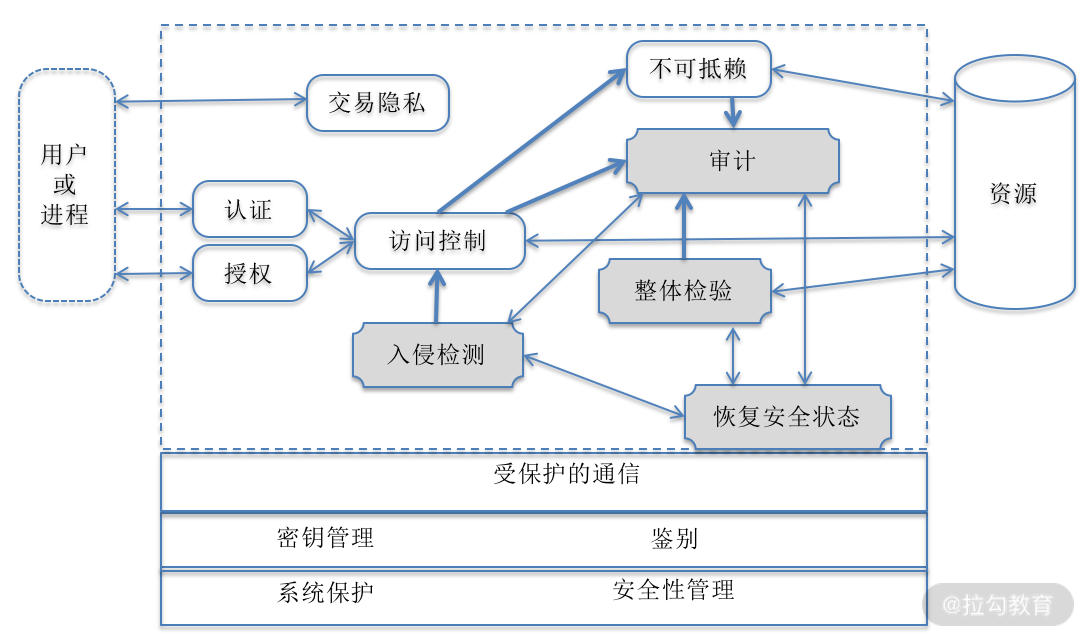
图3 系统运维安全监控与审计框架图
在线的安全性测试重点关注 4 个方面:
- 身份认证、授权、访问控制、不可抵赖等,已做到软件系统之内,经过之前的安全性功能测试和渗透测试,在运维环境中还可以进一步得到验证,这就是“审计”;
- 审计,对用户名、访问时间、操作、访问的资源地址等信息进行审计,判断这些信息是否符合规范和要求,有没有越权或其他不安全的资源访问等;
- 入侵检测,有没有一些用户越过访问控制机制进入到系统内部,包括访问者的 IP 地址、用户名、时间、频率等进行检测,如频率过高,就发出警报并暂时冻结该用户的访问;
- 整体检验,结合审计结果、入侵检测信息、资源访问日志等进行综合性判断,当前系统整体运行是否安全,如果不安全,则系统发出通知并启动安全保护模式。
A/B 测试
关于 A/B 测试的市场成功案例有很多。我们先来看看其中一个改动直观但结果对比明显的例子,以帮助你理解什么是 A/B 测试。
Fab 是一家在线电商,原来的购物车造型是图 4 中的老版本 A,和我们今天线上购物的体验一样,用户浏览商品时可以通过点击购物车把商品放进去。产品经理设计了两个新的方案 B1、B2,期望新的方案能够提高购物车的点击率,也就是转化率。
公司把集成的两个新方案的软件版本都发布到了线上和老版本同时运行,等价、随机选取同一地区的用户使用这三个版本中的一个,然后在线监控该地区用户转化率。运行一段时间后,得到的结果是:相比老版本 A, 新的版本 B1 和 B2 都不同程度地提升了转化率,B1 提升了 49%,B2 提升了 15%。因此,Fab 公司最终选择了方案 B1,向所有用户发布集成了 B1 的软件版本。今天在其网站上看到的购物车的样子就是纯文字“Add To Cart”的设计方案,这就是 A/B 测试。
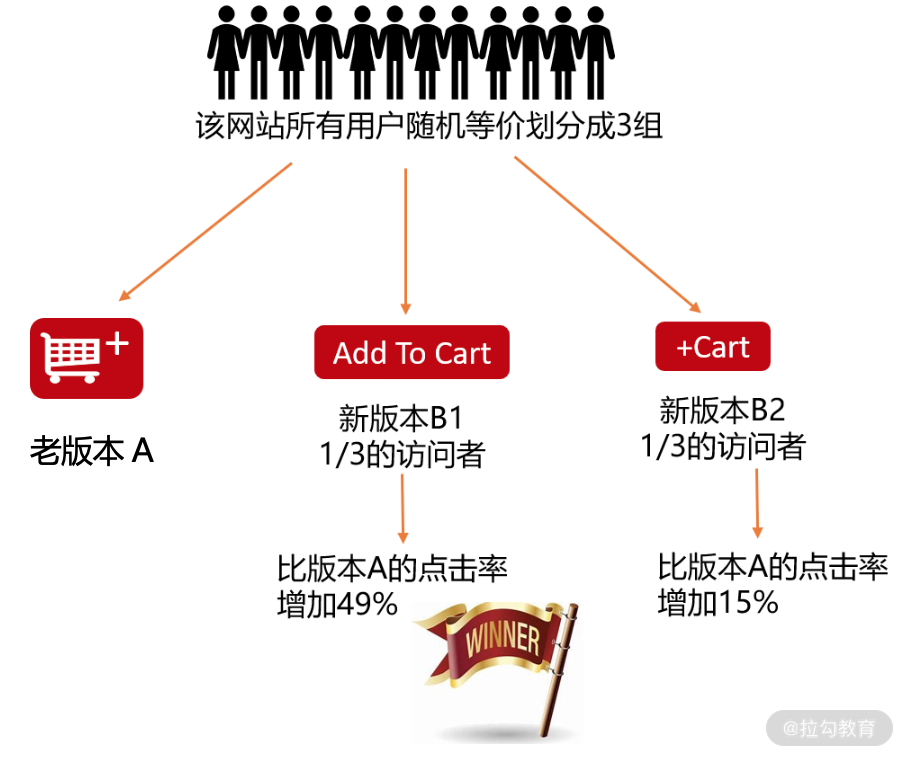
图4 购物车的 A/B 测试案例
更为典型的 A/B 测试往往只发布一个新版本 B 和老版本 A 进行比较。亚马逊也针对购物车做过大量的 A/B 测试;Google 也会做很多 A/B 测试,在 Google 的搜索页面,广告位左移几个像素,都很有可能会带来营收增长。虽然不能用理论解释,但也更加证实了 A/B 测试的价值。只有 A/B 测试才能告诉我们,产品新功能上线后究竟会有怎样的影响,并且用事实帮助人们做出正确的决定。
要做好A/B 测试,需要考虑随机流量的选择以及好的统计工具以保证试验结果的准确性。相比企业自己实施 A/B 测试,可以考虑使用第三方的 A/B 测试服务,将不同的方案通过第三方平台发布给用户,然后自由调整试验流量,根据数据反馈分析方案的好坏。
A/B 测试是一个持续的实验过程——快速轻量的进行迭代,每次尽量不要做复杂的大量改动的测试,这样便于追查原因,进行快速优化,然后再迭代、再优化,不断提高用户体验,不断增加公司的盈利。
流量回放技术
流量回放技术是指对线上真实流量数据导入到测试环境中,并借助特定技术进行回放,用来验证新开发的功能是否有问题。 在第 17 讲(下)我曾经介绍过影子测试,即采用了流量回放技术,具体过程如图 5 所示。核心业务的升级改造必须确保万无一失,因此利用真实的线上流量在测试环境中先进行验证再发布到生产环境中是比较稳妥的方式。另外,流量回放还可以用于在测试环境中对系统进行压力测试。GoReplay 是具有流量回放功能的开源工具。
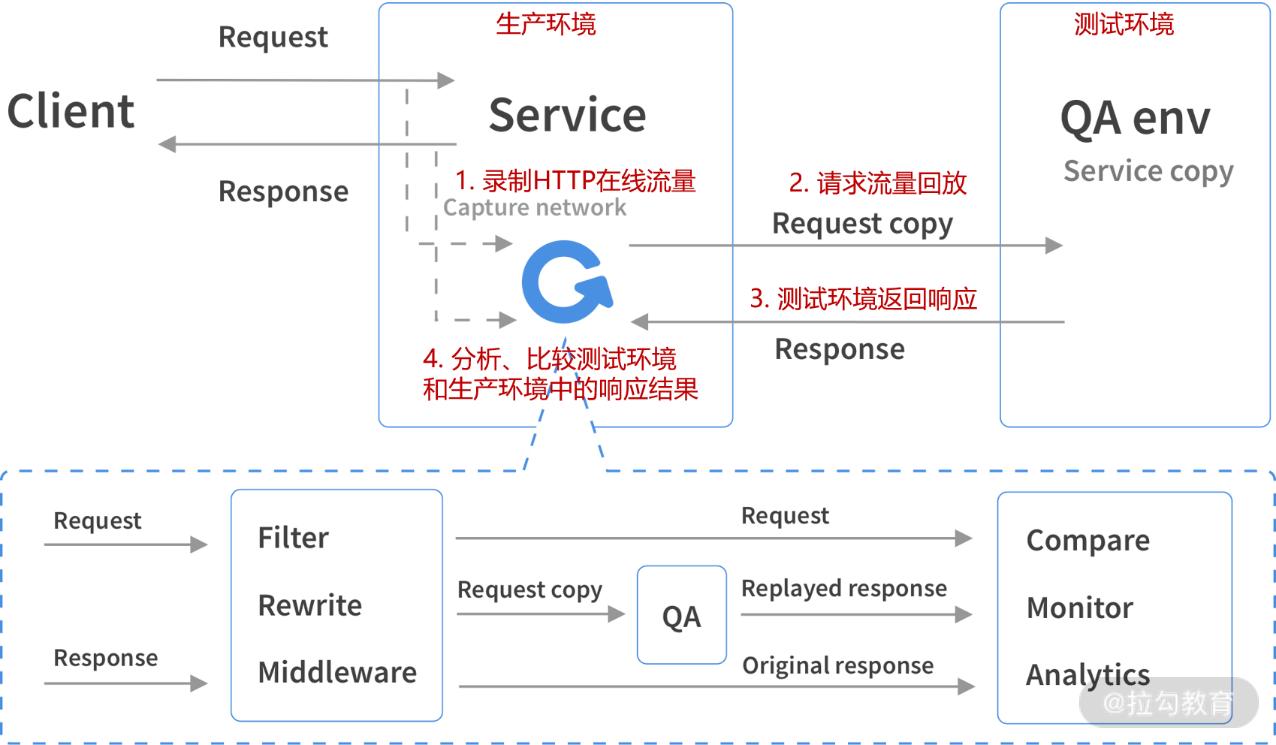
图5 影子测试中的流量回放技术
日志分析获得用户数据
A/B 测试可以看作是日志分析应用的一个实例,安全性测试也是通过日志审查发现存在的安全性漏洞。不仅如此,现在早已是大数据时代,数据产品化的趋势日益明显,企业也更加依赖数据驱动业务增长。通过对在线日志进行分析可以获得大量有价值的用户数据,帮助企业有效地改善产品的用户体验,提高用户满意度,进而帮助企业提高收入。
在这里举一个例子,大家都已经习惯使用在线 App 购物,你应该已经发现了,如果搜索过某类商品,当你下次再进入 App 的时候,页面上呈现的往往是你搜索过的同类商品。你知道是怎么实现的吗?在背后发挥作用的是个性化推荐系统。
推荐系统的核心就是利用大数据处理系统对用户的行为数据进行监测、收集和分析。用户对商品的点击、浏览、收藏、加购物车和购买等行为在用户与商品之间形成行为数据,这些都记录在用户购物路径日志中,对日志数据进行分析并结合用户的个人信息(性别、年龄、喜好等),就能够了解用户的个人偏好及购物习惯,然后筛选出符合条件的商品,并对结果进行排序,呈现给用户。
推荐系统的目标是通过推荐用户有购买意愿的商品,给用户最好的体验,提升下单转化率,并且增强用户黏性。几乎每一个互联网公司都在应用个性化推荐系统向用户推送新闻、广告、视频等,并取得了巨大的收益,推荐系统被认为是互联网的基石系统之一。
线上可以获得各种各样的日志,有系统输出的日志、程序的日志、数据库的日志、前端的日志等,而且日志数量巨大,需要借助工具来处理和分析。对于分布式架构的软件系统,日志的处理可以借助 Hadoop、Storm、Spark 等大数据处理的框架。另外,还有具体的日志分析工具,如商业的 Splunk 工具。开源的首选 ELK,其代表 3 个开源工具 ElasticSearch、Logstash、Kibana 组合而成的软件栈,分别实现了自动搜索与索引、日志收集、可视化展现等功能。
日志分析再进一步就是利用 AI 技术来收集用户反馈,进行数据挖掘、客户情绪分析、客户焦点分析等。比如,数据挖掘和机器学习在推荐系统里就得到了最广泛的应用,根据 AI 算法训练模型,让机器知道用户的偏好,对推送的内容进行筛选、排序,从而形成个性化的推荐。
关于用户体验度量
很多人认为产品的用户体验是无法度量的,因为体验是一种主观感受。而《用户体验度量:收集、分析与呈现》(第2版)这本书提出:用户体验也是可以度量的,即具有可测试性,而且是建立在一套可靠的测试体系上。这本书介绍了 4 种常见的用户体验度量类型:
- 绩效度量类,针对用户使用产品完成一个特定任务的情况进行度量,具体度量类型包括任务完成度、完成任务所需要的时间、任务过程中所出现的过失等;
- 基于问题的度量,对发现的可用性问题进行度量,比如对问题的严重性进行评估;
- 自我报告度量,即用户的直接反馈,来自用户的评论、用户对产品的有效性、易用性、易学性及满意度的评分等;
- 行为和生理度量,收集用户在使用产品时的情感体验也是可测量到的行为和情绪变化,度量方法包括眼动追踪、情感投入和紧张情绪,这需要用到技术类的测试方法,包括眼动追踪技术、情感计算技术等。
总之,这本书提供了一套科学完善的度量体系,值得一读,A/B 测试、推荐系统都可以在这本书里找到理论依据。 根据用户体验度量的结果,企业就可以获得关于用户体验的可靠信息,比如用户会推荐这个产品吗?和竞品相比,这个产品的用户体验如何? 并根据这些信息做出合理的决策。
从测试左移 ATDD/BDD,以业务驱动测试,再到测试右移,在线测试、在线监控,收集和分析用户反馈,再输入到下一个软件版本的需求中,形成闭环,充分提升产品的业务价值。
最后总结一下这一讲的内容:
- 介绍了测试右移的概念,以及其中的在线性能测试、在线安全监控、A/B 测试等;
- 还简单介绍了混沌工程、在线回放技术在测试中的应用;
- 还通过互联网行业广泛应用的推荐系统讲解了通过在线日志获取用户数据的价值和数据分析工具;
- 最后推荐了一本书《用户体验度量:收集、分析与呈现》。
今天留给你的思考题是:在哪些情况下不能用在线性能测试代替研发阶段的性能测试呢?
第46讲:如何分析测试结果和评估测试工作的质量?
软件测试中每一项测试活动都会产生测试结果,通过测试结果来评估产品的质量体现了测试的目的和价值。而通过测试结果评估测试工作本身的质量也非常重要,能让我们及时发现测试中存在的问题,并及时改正,是测试工作进行持续改进的基础。
相比传统的软件测试,敏捷测试更强调持续改进,根据上下文不断调整测试计划和设计,因此更需要在测试过程中对测试质量提供持续反馈。这一讲就来介绍如何对敏捷测试过程进行评估,如何实现量化管理,以及如何分析测试工作的质量。
如何评估敏捷测试过程
传统的测试过程比较好理解,测试分析、计划、设计、执行是分阶段按顺序开展的,测试过程的评估和管理就是针对这几个测试阶段展开的。敏捷测试仍然需要过程管理,因为良好的过程才能产生良好的测试结果和质量,但是和传统测试过程相比需要考虑以下不同的几点。
1)为了适应变化和改进的需要,敏捷测试中的测试分析、计划、设计和执行并不是按照顺序分阶段进行的,而是交替循环进行。可以把它们看作是相对独立的测试活动,前面几个模块也大体上是对上述各项活动分别讲解的,因此可以对上述各项测试活动进行评估。
2)敏捷测试中的持续测试几乎包括了迭代中所有的测试执行活动:设计评审、代码评审、单元测试、BVT、自动化回归测试和新功能的探索式测试,也包括性能测试、安全测试等专项测试。在评估体系中应根据每项测试的特点建立各自的评估标准,比如探索式测试可以从测试的充分性、有效性,以及测试效率等方面进行评估。自动化回归测试应评估自动化测试在总的测试中所占的比重。单元测试应重点关注代码覆盖率和脚本质量。
3)传统的软件测试中会安排测试过程评审,定期或不定期的针对某个测试阶段或某项测试活动进行评审。评审的目的是了解测试过程是否存在问题,以及测试是否达到了测试目标等。敏捷测试也应该有过程评审,但敏捷测试作为敏捷开发的一部分,对测试过程的评估应该结合敏捷开发流程开展。
Scrum 流程中在每个迭代结束前安排 Sprint Review,检查 DoD 中的每一项任务是否已经完成。在第 35 讲中已经提到过,DoD 中的每一项几乎都和某项测试活动有关,比如新增代码要通过代码评审、单元测试覆盖率 80% 以上、需求覆盖率 100% 等。那么在 Sprint Review 中,就是根据每项测试活动的结果进行检查,如果没有达标,应该分析原因,这也相当于通过分析测试结果对测试过程进行评审。
每次迭代结束后的**回顾会议(Retrospective)**更适合对测试过程进行一个阶段性的评估,这时一个完整的迭代已经结束,通过收集、分析这个阶段的测试结果发现在今后的迭代中哪些方面需要改进。
测试过程的评估有定性和定量两种方式。定性的评估是把计划的测试活动和实际执行的活动进行比较,了解测试计划执行的情况和效果,比如 SBTM 中调整了多少个新 Session,调整的比重,哪些没有执行?哪些是计划外的 Session? 原因是什么?另外,还可以通过收集团队成员的直接反馈,通过了解测试实际执行情况发现问题并且分析原因。
但是,过程管理不能仅凭定性管理,量化管理是更好的管理方式,通过数字来反映真实情况,更加及时、客观、明确。再进一步,结合可视化的测试结果和质量的呈现工具,不需要正式的过程评审,团队内外可随时可以了解当前测试和质量的状态,真正做到持续评价、持续改进、持续控制。
下面就仔细谈谈如何进行量化评估——度量体系。
敏捷测试过程的度量体系
对测试过程实现量化管理需要建立一套系统的度量指标体系。不同的产品、不同的研发团队需要建立的度量体系是不一样的,这里以通常的商业应用软件系统为例来进行讲解。
需要度量哪些方面?测试质量和测试效率是需要度量的两个最基本的目标。团队可以梳理出一些能直接或间接反映质量和效率的指标。
- 测试质量直接的度量指标包括测试覆盖率、遗漏的缺陷率等。
- 测试效率的直接度量指标包括:每人•日设计多少用例/执行多少用例、自动化测试率以及缺陷验证周期等。间接的测试质量度量指标可以是度量测试环境的稳定性、可靠性等。
理论上可以用来度量测试质量和效率的指标有很多,如果所有的指标都进行度量,那么分析的工作量大不说,也容易让过程管理失去重点。团队应该根据自身情况选择合适的度量指标,基本的指导思想是:看重什么就度量什么;想提高什么,就度量什么。这也符合敏捷思维。
如何体现系统性?在建立的度量体系中,虽然应该有重点、有取舍,但也要保证测试过程动态平衡的发展。就拿测试质量和效率来说,具有一定的独立性,但也会相互影响,既相互促进,也相互制约。一方面,测试的质量高,一次就把事情做对,会促进测试效率的提高;反过来,高效赋予测试更多时间进行更充分的测试,测试质量必然会提高,而低效往往会减少测试时间,给测试质量带来更大的风险。
但另一方面,如果一味地追求快,只跟踪测试效率相关的指标,比如每人•日执行多少测试用例、测试自动化率等,很可能会顾此失彼,导致测试质量出现问题,比如发现的缺陷数量不多,但上线后问题多、用户反馈不佳等。
如何体现对过程的度量? 在敏捷测试中,测试分析、计划、设计、执行等活动可以分别进行度量。但是对过程的度量更应该保持持续性:每次迭代从开始到结束、每个要交付的版本以及产品的整个生命周期,随时发现问题,解决问题。并且在迭代之间、版本之间比较它们的测试质量、测试效率,通过度量的持续性和可视化获得测试改进的持续性和可视化。
另外,测试过程的度量还应包括产品质量的度量,因为产品质量和测试的质量也息息相关,前一个版本的测试质量不好,就会影响当前版本的产品质量。
综上所述,一个敏捷测试过程的度量体系如图 1 所示,从测试质量、测试效率、产品质量三个方面进行度量,覆盖了测试设计、执行、缺陷报告等重要活动。测试计划和分析的质量会体现在测试覆盖率和缺陷相关的度量指标中;而测试计划和分析在敏捷测试中本来就力求简单有效,因此没有考虑对其进行效率方面的度量。
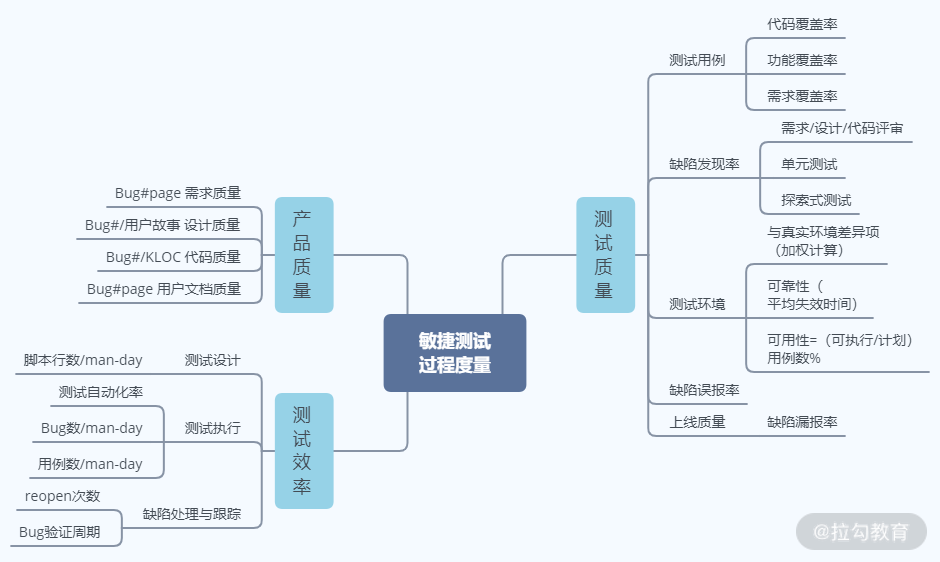
图1 软件测试过程的度量体系
测试工作质量的分析
测试活动有两个最重要的输出:一个是测试用例(包括测试脚本),一个是发现的缺陷。通过图 1 可以看出,测试质量的度量指标大多数是根据这两项内容制定的。度量指标对测试工作质量的量化分析提供了基础。因此可以说,测试工作的质量是通过对测试结果的分析来评估的。根据测试结果计算每一个度量指标,通过度量指标分析、发现测试过程中的质量问题,在此基础上不断改进、完善。
下面就从测试用例和缺陷两个方面来介绍如何分析测试工作的质量。
基于测试覆盖率分析测试工作质量
评价测试质量的好坏首先要分析测试结果是否达到了既定的测试目标,测试目标是测试计划中最重要的内容之一,一般会用测试覆盖率来衡量测试目标的实现。测试覆盖率是对测试充分性的量化指标,指已执行测试覆盖的数据和事先定义/要求的目标之间的比值,趋向于或达到 100%,说明覆盖率足够高。通常从三个方面来衡量:代码覆盖率、功能覆盖率和业务覆盖率。
1. 代码覆盖率
它是代码级测试的衡量指标,在测试中借助测试覆盖率分析工具统计测试脚本对被测对象代码的语句、路径或条件的覆盖率。最常用的是语句覆盖率,即实际执行的代码行数和总的代码行数的比值。
度量公式如下所示:
测试用例代码覆盖率 = 运行 TC 覆盖的 LOC 数 / OUT 的总 LOC 数
也可以用分支覆盖率衡量,度量公式如下所示:
测试用例分支覆盖率 = 运行 TC 覆盖的 BOC 数 / OUT 的总分支数
度量公式中测试用例用 TC(Test Case)表示;被测对象用 OUT(Object under test)表示,含 SUT(被测系统)、被测单元/组件/类等;代码行用 LOC(Lines Of Code)表示;分支用 BOC(Branches Of Code)表示。
以 JaCoCo 工具为例,可以逐层显示每个软件包、类、方法的(代码行、分支等)测试覆盖率,如图 2 与图 3 所示。如果代码覆盖率没有达到测试计划中的既定目标,需要分析是哪些模块没有达到,团队中应该由谁负责补充相应的测试脚本。
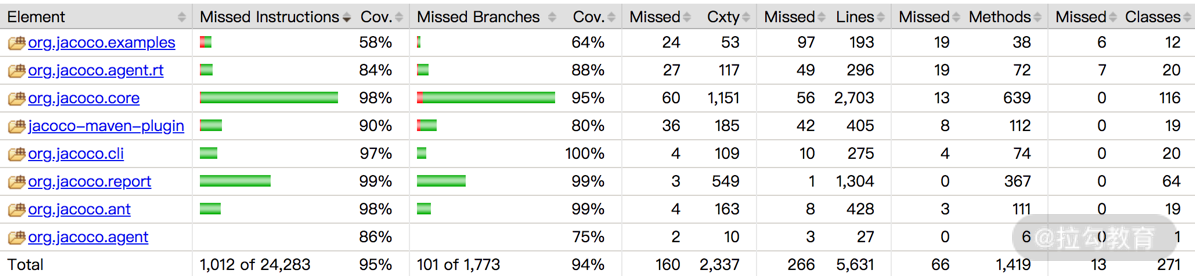
图2 软件包的测试覆盖率列表
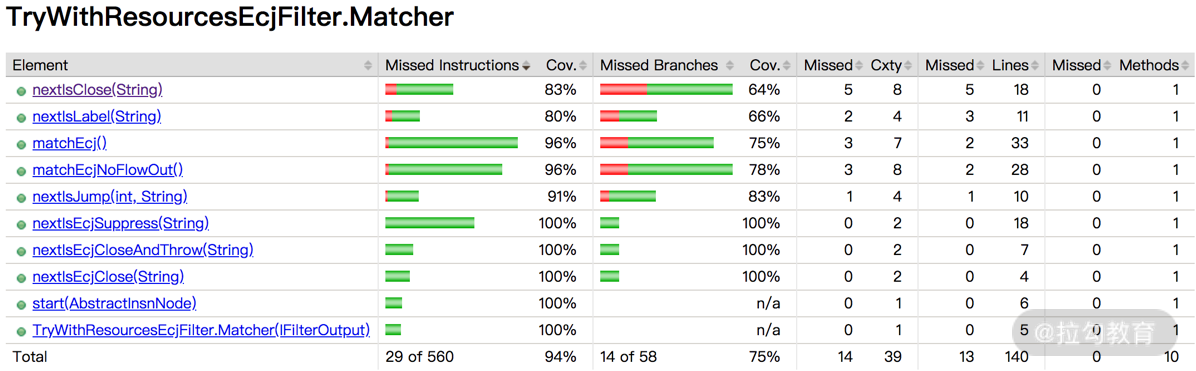
图3 类的测试覆盖率列表
2. 功能覆盖率
对于功能测试,可以用功能覆盖率来衡量测试质量,用大的功能特性来衡量覆盖率没有意义。因为一个功能特性会对应几十、上百个测试用例,可以从被测系统的功能结构出发将功能分解为子功能、子子功能,最后分解成一个个的功能点(FP)。功能点和测试用例之间应该有对应关系,呈现出层次结构。因此,应该用功能点的测试覆盖率来衡量并分析功能测试的质量。
功能覆盖率的度量公式如下所示:
功能覆盖率 = 运行 TC 覆盖的 FP 数 / OUT 的总 FP 数
3. 业务覆盖率
第 36 讲介绍过如何从业务需求出发设计测试用例,在引入 BDD 的情况下,从业务需求到功能特性、用户故事、场景、最后到测试用例的逐步分解。从最顶端的业务需求来度量测试覆盖率同样没有实际意义,因为粒度太大,一个业务需求可能对应几百条甚至几千条测试用例。但如果用场景覆盖率来衡量,每个用户场景对应几条测试用例,测试覆盖率的衡量就有价值和可操作性。如果没有引入 BDD, 业务需求覆盖率就需要根据业务流程图来度量。
基于用户场景的业务覆盖率度量公式如下所示:
测试场景覆盖率 = 测试执行已覆盖的场景数 / 需要测试的场景数
基于缺陷分析测试工作质量
缺陷作为测试活动的另一项重要输出,也可以作为评估测试质量的指标,包括缺陷在测试活动中的误报率、缺陷的遗漏率。
缺陷的误报率的度量公式如下:
缺陷的误报率 = 无效的 bug 数 / 所报告的总 bug 数
通常情况下,缺陷的误报率应该掌握在 5~10% 以内。无效的 bug 数越多,研发团队在处理分析这类 bug 上花费的时间就越多,这会挤压处理有效缺陷和开发、测试活动的时间,自然需要控制其数量。但是,误报的原因一般比较复杂。有时候跟团队采用的缺陷报告策略有关系,比如,敏捷开发中新功能的测试往往是在需求不太明确的情况下进行的。遇到这类问题,往往测试人员拿不准是不是缺陷的时候,一般先澄清需求,再决定是否报告缺陷,还是先报告缺陷,再去做需求澄清?
另外,需要思考的是,缺陷的误报率是不是越低越好?误报率的目标定得越低,测试人员报告缺陷就越谨慎,花在分析和复现上面的时间就越多,会在一定程度上牺牲效率,并且可能遗漏真正有效的缺陷。
缺陷的遗漏率:
缺陷的遗漏率 = 交付后发现的 bug 数 / 总 bug 数
交付后用户发现的缺陷值得分析,究竟是什么原因导致在研发过程中没有发现?如果是因为产品的业务需求没有覆盖到,则需要产品负责人考虑是否在下一版加到业务需求中,比如对某个操作系统的某个新版本的支持。如果是因为测试质量的问题,那要看问题出在什么环节,是测试分析、测试设计、还是测试执行,是人的问题还是工具的问题,然后有针对性地改进,比如添加测试用例、加强人员技能培训,或者改进测试工具。
这一讲留给你的思考题:测试过程度量体系应该体现系统性,度量指标之间有直接或间接的关系,有的相互影响和制约,你能举出一些例子,并思考如何优化度量指标?
第47讲:如何获得良好的(测试与质量)可追溯性、可视化
上一讲介绍了如何度量和评估测试工作的质量,以及对测试过程进行量化管理。实现量化管理不仅要有度量体系,要实现度量指标的可视化才够完美,对于产品质量的评估也是如此,这就离不开一个数据统计、分析的呈现平台。
测试用例和缺陷需要测试管理系统进行跟踪管理。在此基础上实现三者之间的可追溯性,就能更容易解决需求变更、回归测试范围确定、质量评估等一系列重要的问题。
下面首先介绍测试管理系统。
测试管理系统
在测试管理系统中,管理的核心是测试用例和缺陷。一个测试管理系统的构成如图 1 所示。
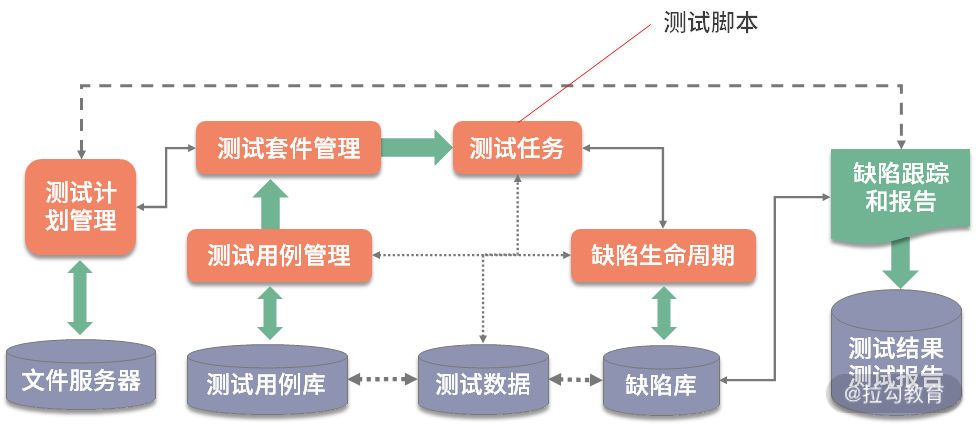
图1 测试管理系统的构成示意图
敏捷测试中的测试用例包括两部分:一部分是手工测试用例,另一部分是可以转化为自动化测试脚本的测试用例。对于探索式测试,虽然从粒度上来说,一个 Session 可以分解成十几条普通测试用例,但从管理的角度,可以把每个 Session 的 Charter 内容 (场景/测试点列表)放入测试用例管理系统中。因此下面讨论中提到的测试用例,是指 SBTM Charter 和自动化测试脚本。
- 测试套件(Test Suite,也叫测试集) 是测试用例的组合,而测试数据、测试环境配置等可以看作是测试用例的组成内容,测试执行结果就是测试用例在不同环境中运行的记录。在探索式测试中,测试套件对应 SBTM 的 Mission 或 Session。
- 缺陷是测试进度跟踪、质量评估等工作中所需要的重要依据。缺陷管理指的是如何更好地跟踪缺陷状态,如何针对缺陷记录进行各类统计分析和趋势预测等。
- 优秀的测试管理系统对测试用例的管理可以解决这些问题:如何设计、构造灵活的测试套件?如何有效执行测试计划中所要求的测试用例?如何跟踪测试执行的结果?
需求、测试用例、缺陷映射关系
在测试管理系统里面,很重要的一点就是在测试用例和缺陷之间建立必要的映射关系,即将两者完全地关联起来。其目的是建立测试用例和所发现的缺陷之间的可追溯性:
- 在系统里打开一个缺陷,就知道是由哪个测试用例发现的,如果没有对应的测试用例,则应该追加相关的测试用例;
- 可以列出任何一个测试用例所发现的缺陷情况,据此就知道哪些测试用例发现较多的缺陷,哪些测试用例从来没有发现缺陷,能够发现缺陷的测试用例当然更有价值,应该优先执行。
不仅如此,还应该建立起需求、产品特性/功能点同测试用例之间的映射关系,如图 2 所示。在敏捷开发中,是指 Epic、用户故事同测试用例之间的映射。一个用户故事需要 1 个或几个 Session 来覆盖,转化成测试脚本数量更多,因此一个用户故事会映射多个测试用例。需求变更在敏捷开发中更加频繁,借助这种映射关系和可追溯性,可以解决需求变化所带来的问题:
- 需求变化会影响哪些功能点?
- 功能点发生变化,需要修改哪些测试用例?
- 产品的某个特性或某个功能点存在的缺陷有哪些?其质量水平如何?
- 如果一个缺陷是由于设计、需求定义引起的,如何追溯到原来的需求上去解决?
- 通过对缺陷的分析,如何进一步改进设计和提高需求定义的准确性?
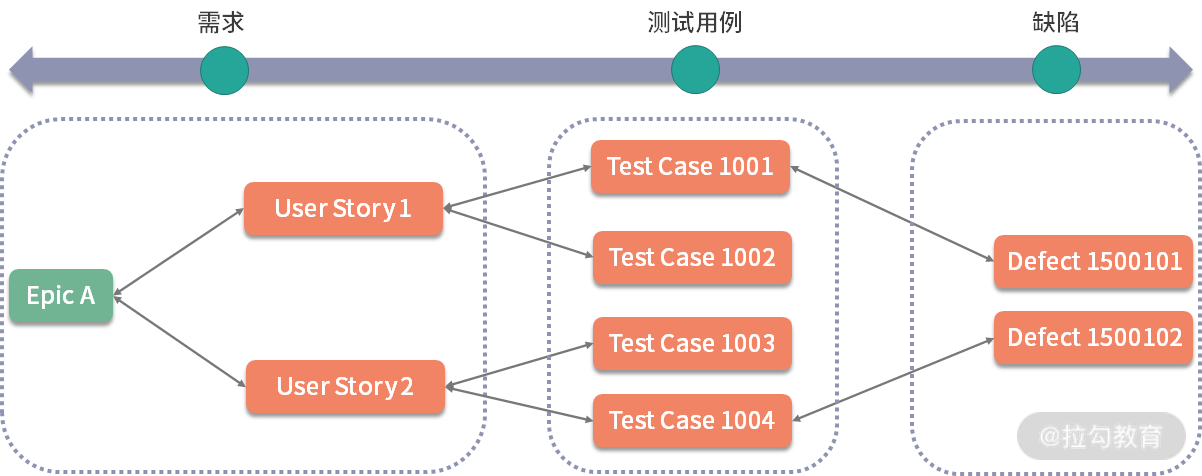
图2 需求、测试用例、缺陷之间的映射关系图
在测试管理工具中,测试用例的执行状态需要测试人员手工更新。对于有对应自动化测试脚本的测试用例,理想的状态是可以把自动化测试执行的结果自动同步到测试管理工具,自动更新测试用例的状态——是 Pass 还是 Fail。这可以通过测试管理工具和测试自动化工具的集成来实现,也可以通过测试管理工具和 CI 工具的集成来实现。
Jira + Zephyr 实现可追溯
Jira 是支持敏捷开发的、常用的项目管理工具,围绕着 Jira 又发展出一批测试用例管理工具。Jira 提供从 Epic 到用户故事的需求管理以及缺陷跟踪。测试用例管理工具和 Jira 的集成可以实现需求、测试用例与缺陷的映射关系。目前有一些测试用例工具以插件的形式和 Jira 进行集成,比如 Zephyr、Xray 等。
Zephyr 是主流的测试用例管理工具之一。Zephyr for Jira 以插件形式运行在 Jira 系统中,其利用了 Jira 的管理界面,可以在 Jira 里生成测试用例并直接关联到 Epic 和用户故事、缺陷。
Zephyr for Jira 可以和多种自动化测试工具集成,将自动化测试的结果自动同步到 Jira 中。可以集成的自动化测试工具包括 SoapUI Pro、Cucumber for Jira、Selenium、JUnit、TestNG 等。
另外,Jira、Zephyr for Jira 还可以和 CI 调度工具 Jenkins 集成,把在持续集成环境中自动运行的自动化测试的结果自动同步到 Jira 中,如图 3 所示。
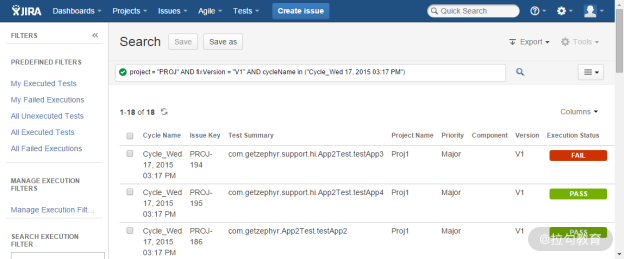
图3 Jira 和 Jenkins 集成同步测试结果
另外,Zephyr 也提供了独立安装的 Standalone 版本,有单独的管理界面,在测试用例的计划、执行、报告方面的用户体验会更好一些。Zephyr Standalone 也可以通过配置和 Jira 集成,实现需求、测送用例、缺陷的映射关系。图 4 展示了需求和测试用例的双向追溯, 而图 5 则显示了如何在一个失败的测试用例中关联缺陷。
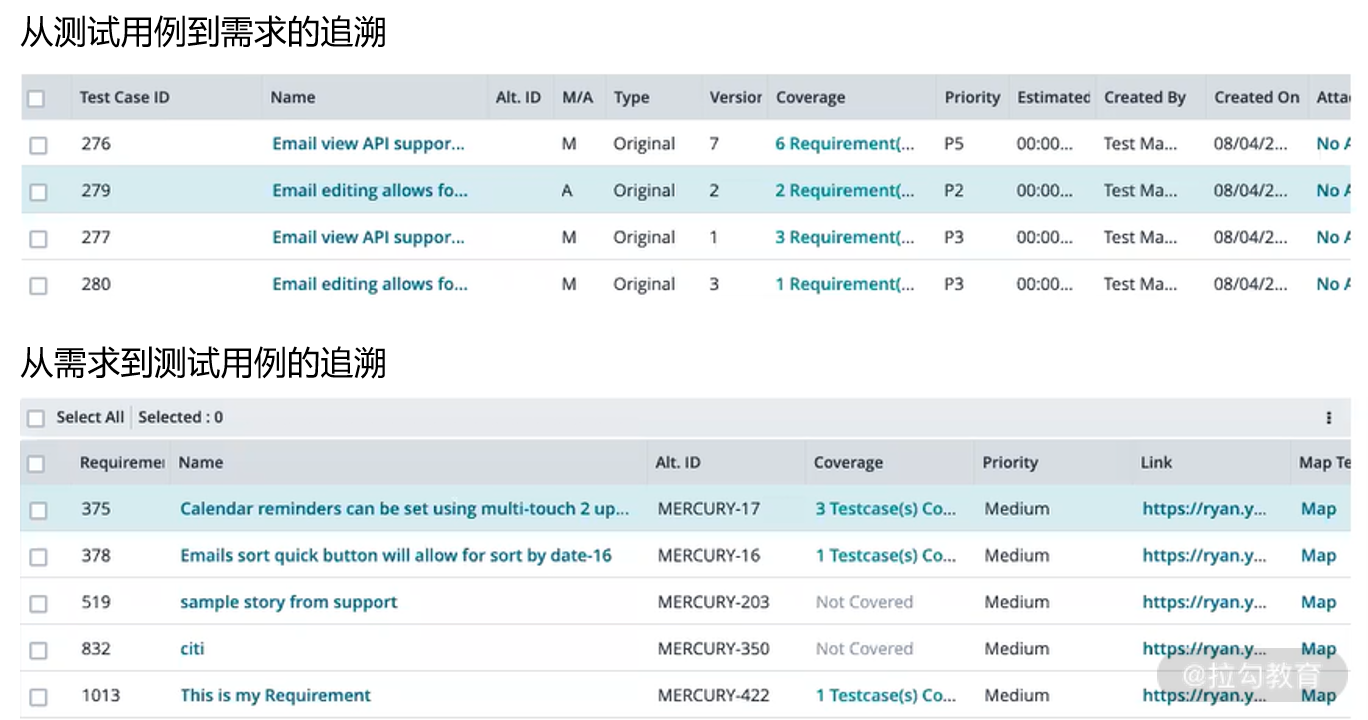
图4 需求和测试用例的双向追溯
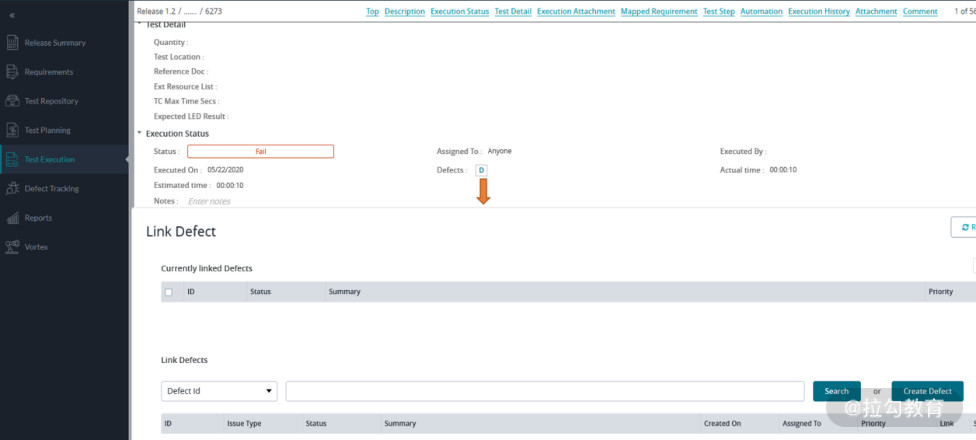
图5 关联缺陷到失败的测试用例
测试与质量度量的可视化
测试结果与软件质量的度量结果以可视化的形式呈现出来非常有意义,一方面可以帮助研发团队及时掌握项目及研发进度,并发现项目的瓶颈及风险,理清关键路径,集中解决关键问题,保证项目得以顺利进行。另一方面,也提供给高层领导和其他团队了解目前软件质量状况的窗口。对当前状态有统一的认识,是进一步解决问题的关键。
如果要实现多项目、多团队、多数据源的测试数据的呈现,研发团队往往会考虑自己开发一个数据呈现平台,从测试管理系统、CI 系统中得到各种测试数据,通过界面呈现出来;也可以借助一些数据统计呈现工具打造综合的可视化面板。下面介绍三种常用工具。
基于 SonarQube
在第 18 讲介绍静态测试的时候讲过,SonarQube 可以作为代码质量(缺陷)数据呈现工具,其本身还是一个代码静态分析工具,另外还可以和多种代码静态分析工具集成获得更丰富的代码扫描规则。SonarQube 可以度量缺陷、安全性漏洞、代码坏味道和单元测试覆盖率,其 Quality Gate 界面如图 6 所示。如果达到质量要求,那么界面标题栏中会显示“Passed”(A 级);如果达不到,会按照 B 级、C 级、D 级、E 级列出各种质量问题的数量,并以不同颜色标记,其中 B 级对应的质量问题最轻,E 级对应的质量问题最严重。它还可以把代码规模、复杂度等度量集成到一起,通过一个页面统一呈现出来;还可以单击 Bugs、Coverage 等查看详细内容。
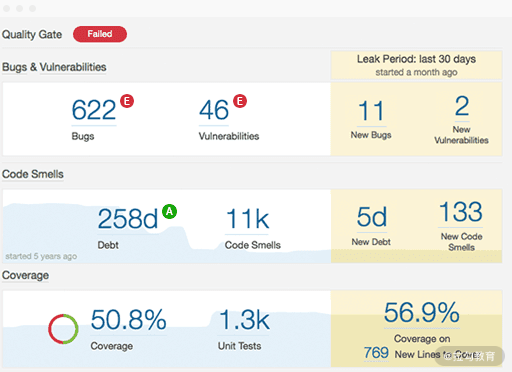
图6 SonarQube 工具中的 Quality Gate 界面图
基于 Grafana 和 InfluxDB
除了代码质量度量信息的呈现,研发团队还应考虑如何呈现其他测试结果,提供给团队内外成员全面了解当前软件质量的渠道,这些测试包括 BVT、性能测试、自动化回归测试等。第 18 讲还介绍了采用 Grafana 和 InfluxDB 结合可以按照时序呈现持续集成环境中的自动化测试结果,可以通过监控面板按照时间顺序呈现每次持续集成的测试结果,以及自动化回归测试结果。
例如,Grafana、InfluxDB 和 JMeter 集成可以呈现性能测试的实时统计数据:JMeter 添加 Backend Listener,用于在测试过程中实时发送统计指标数据给时序数据库 Influxdb,配置 Grafana 数据源连接到 Influxdb,就可以得到呈现实时测试数据的可视化看板。如图 7 所示,可以呈现包括累计请求数、累计失败的请求数、吞吐量、响应时间等。
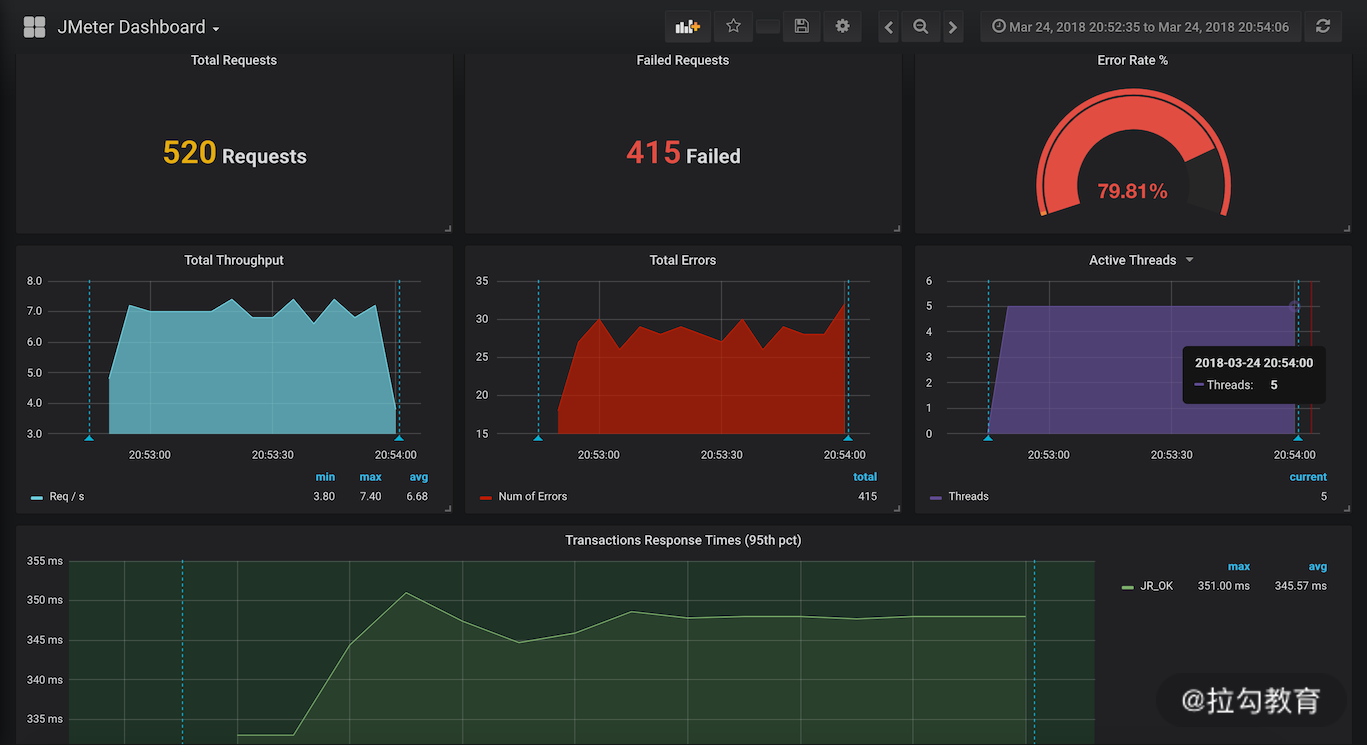
图7 JMeter 性能测试实时统计数据的可视化
基于 Microsoft Power BI
Microsoft Power BI 是一款商业的数据可视化工具,通过和测试管理工具的集成,可以用来打造呈现测试结果、质量度量、缺陷报告等数据的综合性的可视化面板。如图 8 所示,在 Power BI 面板中呈现了 Jira 中的缺陷数据统计信息。
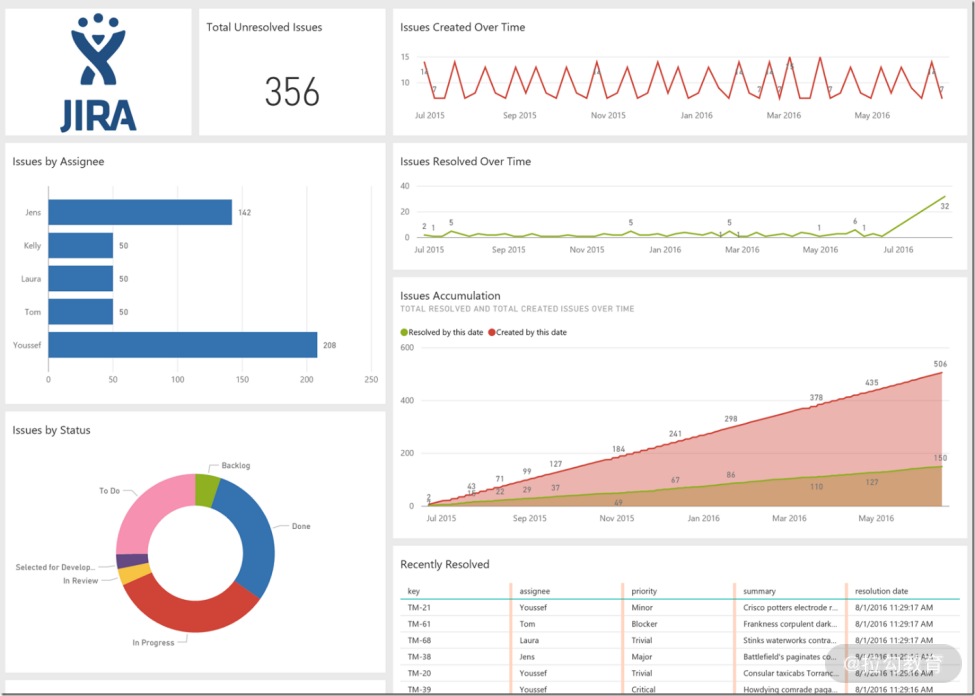
图8 Power BI 呈现 Jira 缺陷统计信息
质量雷达图
有的企业还会开发一个全局的雷达图来显示企业中不同级别团队的所有开发组的质量情况,然后通过大屏触摸显示器呈现。图 9 是一个具有 4 层组织架构企业的质量雷达图,四层的雷达图使得不同部门的管理层既能从中看到整体的技术债得分,也能看到个体的得分,还能看到个体占据整体的比重。
环形面积大小表示代码行数比例,面积越大,则代码行数占比越大;环形颜色表示技术债率等级。同时点击各个扇形可以下钻到各级部门和团队:
- 圆心(最内圈) 表示整个组织级的代码总行数及技术债率值;
- 第一层环表示一级团队各自的代码行数及技术债率值;
- 第二层环表示下一层开发部门各自的代码行数及技术债率值;
- 第三层环(最外层环) 表示各个项目组的代码行数及技术债率值。
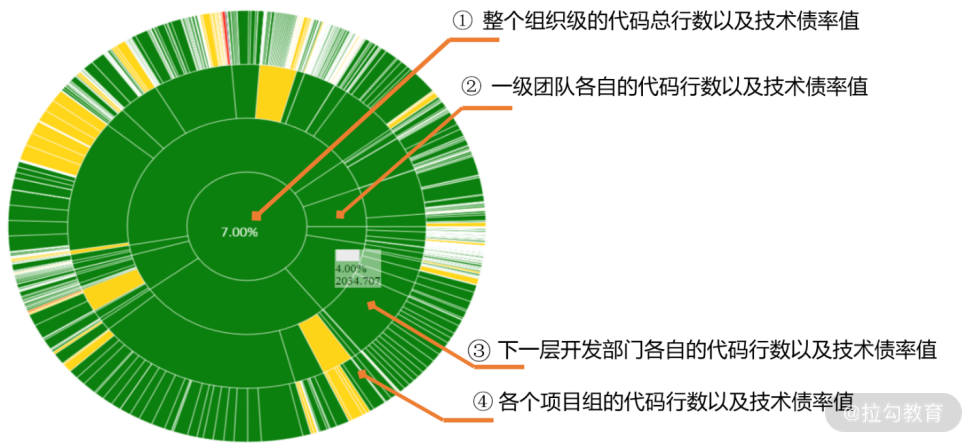
图9 企业级的质量雷达
这一讲主要介绍了两个部分的内容:如何实现需求、测试用例、缺陷的可追溯,以及如何实现测试结果和软件质量度量的可视化。同时介绍了 3 种实现可视化的数据统计呈现工具:SonarQube 专注于代码质量的呈现,另外,还有开源的数据统计呈现工具 Grafana 和商业软件 Microsoft Power BI。
第48讲:敏捷测试优秀实践
谈起敏捷测试的优秀实践,其实我们已经在第 7 讲中介绍过一家优秀公司——Etsy 公司的实践。该公司建立了“代码即艺匠(Code as Craft)”这样优秀的工程师文化和质量内建文化,开发阶段的测试由开发人员负责,但 Etsy 拥有独立的测试(QA)团队,主要负责下列一些工作:
- 针对新功能和新产品进行探索式测试、集成测试及跨平台的兼容性测试;
- 针对移动端的发布进行验证测试;
- 验证用户可感知的改变。
这一讲,将介绍微软、谷歌、亚马逊、Facebook、奈飞等几家优秀公司的敏捷测试实践。
Microsoft 的优秀实践之前谈起软件测试,一定会竖起微软这杆大旗。在传统软件测试领域,微软的确做得很好,不少同学应该都看过《微软的软件测试之道》这本书,而且在高峰期的时候,有些团队开发:测试比是 1:2,没错,测试人员比开发人员多。即使在移动互联的今天,微软也没有辜负大家的期望,最近几年转型很成功,市值 1.39 万亿,超过苹果,成为世界第一。
微软搞敏捷比较迟,2008 年参加微软的软件研发高峰论坛,那时微软还是在提每日构建、每日集成,还没有提“持续集成”和敏捷。直到 2011 年 7 月,微软公司副总裁 Brian Harry 才正式宣布:微软郑重承诺开始全面实施敏捷,这种对敏捷的承诺是由商业需求驱动的,也就是为了让企业具有更大的活力、竞争力和生命力,必须改变过去每隔几年才交付一个新的软件版本,为此,微软别无选择,只能选择敏捷。在 2014 年微软大刀阔斧进行了组织变革,除了在操作系统团队保留了 300 左右的专职测试人员,一万多专职的测试人员彻底消失了,其中 80% 的专职测试人员(SDET)头衔都统一改为“软件工程师”,融入整个敏捷团队中去了,既做测试,也做开发或运维。
2015 年 10 月 27、29 日,Steve Denning 连续写了两篇文章《惊奇:微软是敏捷的》(Surprise: Microsoft Is Agile)和《微软实现大规模敏捷的 16 个关键》(Microsoft's 16 Keys To Being Agile At Scale),对微软实施敏捷的肯定。在第一篇文章中,作者的习惯性认识被颠覆了,之前认为微软这样拥有十几万员工的大公司,就像一艘航空母舰那样(如图 1 所示),很难掉头,变革困难,前进的速度很慢,难以快速交付产品。甚至 Scrum 创始人之一 Ken Schwaber 在其博客中都在质疑像微软这样的大公司是否能够从官僚主义体制中解放出来。

图1 之前对微软的错误认识
但在作者走进微软公司之后,感到惊奇,原来公司已被成功改造成无数个小团队,航空母舰大部队被分解成乘坐快艇的快速反应部队(如图 2 所示)。即实现了今天我们熟悉的多管道快速发布的机制,发布周期从几年到现在几周,的确震撼。

图2 走进微软之后的真实印象
这段旅程,不会那么顺利,而是跌宕起伏,其间做对了一些事情,也做错了一些事情,经历了痛苦,但最终还是成功了,这也从微软的股票市值上得到了验证。微软的一些优秀的实践,可以概括为永远用最优秀的工程师和最优秀的工程实践,包括下列几点:
- 一体化的工程系统(One Engineering System,1ES)团队是 Microsoft 的 Cloud + AI Platform 部门的一部分,以帮助改善设计和研发人员的工程经验,包括提升内部源代码质量、产品和服务的可访问性、安全性和合规性,类似华为2012实验室之下的研发能力提升中心;
- 推行积极的“自我托管(self-hosting)” 文化,一方面确保本地团队运行自己的构建并解决发现的任何问题,另一方面公司内部首先部署公司开发的最新内部版本,及时发现缺陷;
- 专注于为客户提供价值,特别强调向用户交付价值,即按照对客户的影响决定积压工作的优先级,并建立了客户反馈系统(Customer Feedback Systems),了解系统运行状况、可用性、性能及服务质量(QoS)等质量指标,更好地理解用户使用系统的情况,形成产品完整的闭环,从而持续地改进产品,提升用户体验;
- 测试即服务(Testing as a Services),测试不仅为研发提供服务,而且也为运维提供服务,主动发现性能方面的异常,并判断造成这种情况的原因,消除产生各种问题的根源,只有做好测试服务,才能更好地保证产品质量;
- 强大的基础设施,逐步将 IT 系统全部迁移至微软的公有云 Azure 之上,同时在内部全面推行 Azure DevOps 平台作为统一的 DevOps 工具链,以及构建数据驱动质量(Data-Driven Quality,DDQ)平台。
Google 的优秀实践Google 和微软在实践方面有许多的相同点,包括只招聘最优秀的人才、构建强大的基础设施、内部尝鲜、金丝雀发布(灰度发布)、不断提高迭代速度等,而且在更早的时候 Google 就去掉了 SET(Software Engineer in Test)的角色,将测试团队转化为工程效率(Engineering Productivity)团队,为整个软件研发提供自动化测试技术和工具支持。
这里侧重讨论 Google 的两大实践:整洁的代码和又快又好的测试。
整洁的代码
要求代码遵守代码规范,之前许多公司的 C++/Java 语言规范都是以谷歌的代码规范为榜样的,在 Google,诸如库、程序和测试这些构建实体,均由高级的**声明式构建规范(DBS)**进行声明,描述具体的每一个实体,比如实体的名称、源文件、相关的库文件或所依赖的其他实体。构建文件可以自动生成和更新,并确保构建系统通过分析构建文件而不是源文件来快速地确定依赖关系,并以此避免了构建系统和编译器,或者用于支撑其他编程语言的分析工具之间的过度耦合。
所有源代码主库的变更都必须经过除作者外至少一个以上的工程师审查,每一个项目都要开代码评审会;如果发现一个错误,通常会追踪到引入此项错误的变更和原代码的评审意见,并指出问题在哪里,以便让原始作者和评审人员都了解问题所在,而且开发了优秀的基于 Web 的代码评审工具。整个评审流程疏而不漏且高效。在 Google 的团队中定期扫描各个组件中未关闭的 Bug 是十分常见的,优先关注这些 Bug 并合理地将它们分配给相应的工程师。
又快又好的测试
又快又好的测试,强调任何单个测试超过 60 秒都没有价值,测试执行越快越有价值,每天执行近 1 亿个测试用例。
单元测试是 Google 公司非常提倡和广泛采用的工程实践。产品线上所有的代码都要求进行单元测试,如果新添加的源文件没有进行相应的测试,那么代码审核工具会将它们突显出来。
所有的构建都需要经过测试。如果测试失败,则几分钟内系统就能自动通知作者及其评审人员,从而添加新的变更来修复失败,新的变更会再次合并到新版本分支,再重新构建和重新测试。直到测试全部通过后,将构建好的可执行文件和数据文件一起打包。所有这些步骤都是自动执行的,因此发布工程师只需要运行一些简单的命令就能完成。
集成测试和回归测试也得到了广泛的应用。一旦候选版本已经完成打包,则通常部署到 staging 服务器上,进一步完成集成测试,而且采用先进的技术和高效的策略来完成测试。例如,从产品线上发送一份请求的 copy 到 staging 服务器,即采用真实的数据请求完成测试。自动化系统频繁地运行测试,只要有代码改动就进行回归测试,迅速而准确地检测到问题的发生。
2018 年,Google 更是推出了一款全新的持续集成和持续交付(CI/CD)工具,即 Google Cloud Build,能用来快速且大规模构建、测试和部署软件。可以在 Google Cloud Build 中设置持续构建流水线,自动执行构建和测试工作;而且它能够发现持续集成中出现的问题,可以提供分析和建议,用户还可以通过历史错误、警告和过滤器来识别那些可能会阻碍程序构建与部署的问题。
Amazon 的优秀实践之前人们关注 Amazon 公司不多,今天它的股票价格超过 2440 美元,市值超过一万亿美元,超过 Google,值得我们好好研究。说起 Amazon,就想起他们一直提倡建立“两个比萨的团队(Two-Pizza Teams)” ——真正的敏捷团队(5 ~ 9 人,中餐两个比萨可以让团队吃饱)、扁平化的组织结构,对人才也非常重视,在招聘上很下功夫,专门在公司设立 200 ~ 300 人的 Bar Raiser,提高新人加入公司的门槛。
Amazon 现在是世界上最大的云服务供应商,它的基础设施不容怀疑,完全可以和微软、Google 媲美,甚至超越他们。在 AWS 弹性云上实现持续集成、持续交付以及 DevOps 的各种服务,如 AWS CodeDeploy,平均每秒钟超过一次的部署活动,也能做到一键回滚。
Amazon 做得最好的方面是把“以客户为中心”这样的质量文化做到极致,不仅把“以客户为中心”写到企业愿景中,真正痴迷于客户,有着特殊的“空椅子文化”: 在开会的时候总是在会议室放一把留给客户的空椅子,以此提醒与会者,这里有最重要的人——客户。这种仪式感可以帮助参加会议的人员把自己带入到客户角色,从客户的角度思考问题,制定决策。而且围绕客户需求而制定了 400 个量化指标来衡量运营表现,追求细节,即便是最细微的网页载入延迟也不是小事,必须找到原因,尽快纠正。因为根据 Amazon 的统计,0.1 秒的网页延迟,会直接导致客户活跃度下降 1%。
以极致的“以客户为中心”质量文化为基础,始终强调敏捷的核心实践之一“质量内建”, 这包含了今天倡导的许多敏捷测试和 DevOps 的优秀实践,比如测试左移、持续集成、持续交付、测试右移等。而且开发人员通过承担编码、测试、部署,甚至是线上运维的责任,真正做到对自己的代码质量负责。其次,还体现在架构优化上,架构从单体结构演化成面向服务的 SOA 架构、再演化成微服务结构、一切皆 API,彻底解耦,系统组件/服务之间的依赖度降低,团队间的代码冲突减少,而且错误被隔离到单个微服务中,绝大部分的测试都可以基于接口开展,做得又快又好。
除此之外,还有其他质量内建的具体实践,比如:
- 通过技术上的创新不断提升用户体验;
- 相互之间的代码评审以便尽早发现代码的缺陷;
- 编写各种测试脚本,比如单元测试、集成测试、性能测试;
- 通过自动化的部署管道把软件部署到测试环境、类生产环境、生产环境中;
- 监控生产环境中软件的运行情况。
除了上面介绍的三大公司的优秀实践之外,Facebook、Netflix 等优秀公司也做得不错。Netflix 成熟的质量保障之道、强大的基础设施、混沌工程、微服务实践等也闪闪发光。Facebook 和 Google 一样,都有工程师文化,代码为王,并强调用正确的工程方法、思路来完成工作的文化,这也能极大地激发开发人员的内驱力和创造力。例如,Facebook 搭建了强大的试验框架,在任何一个时刻都可以测试上千个不同版本的 Facebook 服务,和 Google 类似,可以做到又快又好的测试,很好地支持快速迭代、持续交付的目标。
由于篇幅所限,这一讲就讲到这里,最后出一个思考题,学习完本讲之后,结合自己公司的实际情况,上面所介绍的哪些优秀实践,你会想马上采用、实施?
第49讲:敏捷过程的反思与持续改进
专栏内容回顾与总结
时间过得很快,陪伴大家快四个月了,终于来到最后一讲的内容了。这一讲将回顾一下过去 48 讲主要聊了些什么?如果把 48 讲的标题全都过一遍,估计这一讲的时间就差不多用完了,所以咱们就只能快速回顾一下七大模块。
- 基础:澄清什么是敏捷测试,侧重讨论了敏捷测试的思维方式、流程,并定义了一个新的敏捷测试四象限,相信对你会很有启发,并能领会敏捷测试的本质。
- 人与组织:从测试和质量这样的视角去探讨敏捷团队的各种形态和所具有的精神、文化与协作,包括敏捷中专职的测试人员、Test Owner 等职责,以及如何构建有质量意识的学习型团队等。
- 基础设施:是敏捷测试做得又快又好的基础之一,借助虚拟化、容器、自动化测试等技术支持持续测试,并将静态测试、自动部署与 CI/CD、DevOps 等集成起来,实现持续交付。
- 测试左移:测试要做得又快又好,测试的左移是不可少的。在传统测试中也做需求评审、设计评审,在敏捷中更应该提倡 ATDD、BDD 和需求实例化,将需求转化为可执行的活文档——需求是可执行的自动化脚本,在时间轴上是最彻底的自动化测试。
- 分析与计划:不论采用什么先进技术,也不论测试是否左移,测试的分析与计划依旧是测试最重要的工作之一、也是测试设计和执行的基础。这一部分针对这一主题进行了全方位的探讨,从上下文驱动思维、分析技能、风险、策略、代码依赖性分析、探索式测试、SBTM 等维度介绍其方法和优秀实践。
- 设计与执行:敏捷测试也一样,最终要落地。例如,如何面对用户故事来完成测试的设计、如何彻底地实现自动化测试?单元测试必须 TDD 吗?如何做到质量和效率的平衡、质效合一?这些都是本模块要回答的问题,并提供了很好的解决方案办法或策略。
- 收尾与改进,测试右移、测试工作评估、测试可视化、敏捷测试优秀实践等。
如果这些内容学好了,你就掌握了敏捷测试的思想、方法及其实践,可以成为一名真正的敏捷测试“绝地武士”;如果团队在这些方面做好了,敏捷测试不再是形似而神不似,就能实现高效的敏捷测试。
反思与改进分析无论是学习和工作,都是无止境的,也正如敏捷模式中所提倡的,每个迭代之后要反思,反思自己理解不透、做得不好的地方,然后采取行动去改进。如何衡量敏捷测试做得好不好呢?可以从不同的维度去分析,比如本专栏侧重讲解的维度如下:
- 敏捷测试的思维方式、质量文化;
- 团队的技术能力、测试能力、沟通协作能力等;
- 敏捷测试的流程,流程常常也是一个改进的维度,产品就是基于这个流程被研发出来的;
- 基础设施,是否拥有良好的自动化测试?是否很好的支持 CI/CD、持续测试?
- 测试左移和右移是否到位?
- 测试的分析是否到位、测试计划是否简捷有效?
- 测试的设计和执行是否满足或适合敏捷测试的诉求?
为此,你可以建一个评估团队敏捷测试水平的雷达图,给每一个维度去打分,无论是 5 分制还是 10 分制,了解自己团队所处的位置,从而发现团队在某些维度的弱势,有针对性地改进。如图 1 所示,从六个维度去评估自己团队的敏捷测试水平,发现团队、测试左移两项比较弱,得分只有 3.0,刚及格,就可以给自己的团队设定一个新的目标——提升自己团队的敏捷思维能力和技术能力,做好测试左移工作,特别是 ATDD,在开发前细化用户故事验收标准,并和开发、产品、业务人员评审验收标准,达成共识。
更有人建议要将敏捷测试分得更细,分为 20 个领域,如图 2 所示。这样也许会更好,分解得越细,就越明确,比如自动化测试能力、探索式测试能力、反馈速度、可跟踪性等,的确需要我们关注,但“任务”、“库”有些含糊,或者说敏捷的特征不显著。
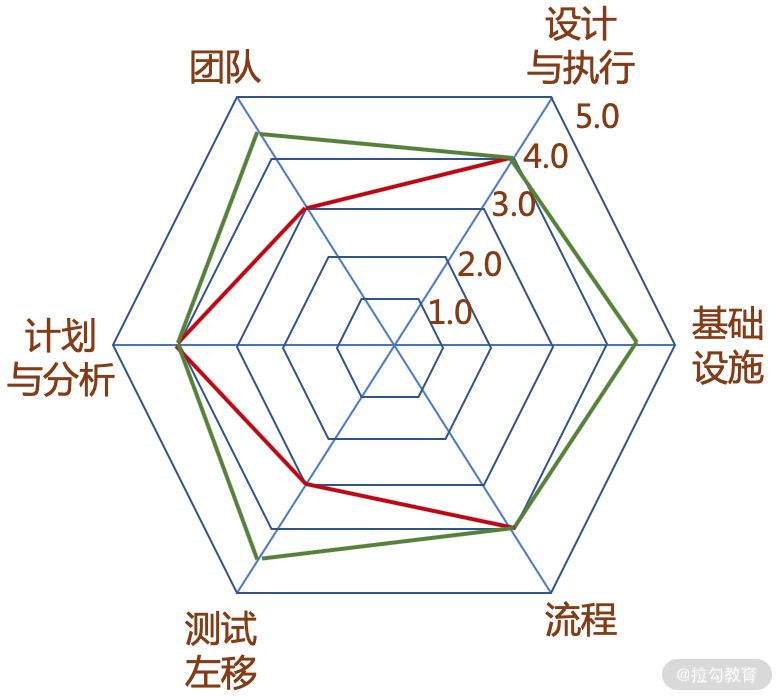
图1 评估团队敏捷测试水平的雷达图

图2 团队敏捷测试水平需要评估的各个方面
在敏捷实施过程中,也可以按照“守”、“破”、“离”三个阶段来实施和改进。
- 首先,严格按照专栏中所说的各种流程、方法和要求来实施敏捷测试,即先“固守”人们已探索出来的优秀实践,即使不理解,也照搬照抄,按照成熟的方法实施,那些方法和实践是经过实践和探索总结出来的,经过了实践的检验。
- 在实施一段之后,慢慢能领会为什么这样做的背后原因,再结合自己团队的实际情况,进行局部的“突破“ 和创新,提升敏捷测试水平。
- 经过不断实践、创新、再实践,慢慢形成自己一套完整的敏捷测试方法和实践,熟练运用,这里所讲的内容慢慢就感觉不存在了,彻底 “脱离“ 了别人的框架和方法。此时的敏捷测试已是神似,如同练武之人所说,达到了“手中无剑、心中有剑”的境界。
数据驱动改进没有度量就不知道自己身处什么位置,如果想改进,就必须进行度量,例如第 46、47 讲中所讨论的内容,过程改进离不开度量,有了数据,就可以更准确、客观地知道问题在哪里。我们采取了改进措施之后,基于度量数据,才能知道这些改进措施有没有发挥作用、发挥了多大作用,准确、客观地了解是否得到了改进。数据驱动改进,一般要做好下面 5 个方面的事情:
- 做好测试过程、产品质量相关的数据收集;
- 做好数据的抽取与分析,包括测试充分性、测试效率等分析工作;
- 度量结果的数据可视化呈现;
- 随着敏捷测试改进的不断深入,度量指标会更多、更细,完善度量指标体系;
- 更深入的数据挖掘,找出更有价值的数据。
微软公司也提倡数据驱动的质量管理,强调从业务价值相关数据开始分析,深入到用户体验分析,包括用户的价值、易用性分析等,最终驱动构建健康的系统——良好的性能、可用性、可靠性等。为此,建立了一个数据驱动质量模型,如图 3 所示。
![]()

图3 微软公司的数据驱动质量模型图
PDCA 循环改进不能三天打鱼两天晒网,而是要持续改进。PDCA 就是一个用于持续改进的简单但有效的模型,代表由四个部分“计划(Plan)、执行(Do)、检查(Check)和行动(Action)”构成的一个循环过程,如图 4 所示。
- 计划(P),分析敏捷测试目前现状,发现测试过程中存在的主要问题,找出问题产生的根本原因,制定测试过程改进的目标,形成覆盖测试不同维度的改进计划,包括改进的方法、所需资源、面临的风险与挑战、采取的策略、时间表等。
- 执行(D),执行是计划的履行和实现,按计划去落实具体的对策,实施测试过程的监控和度量数据的收集,使活动按预期设想前进,努力达到计划所设定的目标。
- 检查(C),对执行后效果的评估,并经常进行内部审核、过程评审、文档评审、产品评审等活动,但实际上,检查自始至终伴随着实施过程,不断收集(测试要素、关键质量特性等)数据的过程,并通过数据分析、结果度量来完成检查。检查方法,一般在计划中就基本确定下来了,即在实施前经过了策划。
- 行动(A),检查完结果后,要采取措施,即总结成功的经验、吸取失败的教训,改善流程、提升人员能力、开发新的工具等。行动是 PDCA 循环的升华过程,没有行动就不可能有提高。
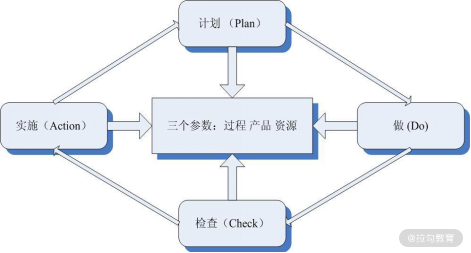
图4 PDCA 也适合敏捷测试的改进
在 PDCA 循环中,检查是承上启下的重要一环,是自我完善机制的关键所在。没有检查就无法发现问题,改进就无从谈起,只是这种检查,最好要依据客观的数据,即上面所说的度量。
PDCA 循环方法是闭合的,同时具有螺旋上升的必然趋势。PDCA 循环告诉我们,只有经过周密的策划才能付诸实施,实施的过程必须受控,对实施过程进行检查的信息要经过数据分析形成结果,检查的结果必须支持过程的改进。处置得当才能起到防止相似问题的再次发生,以达到预防的效果。例如,标准要求建立的预防机制:对测试、评审、监控中发现的软件缺陷,除及时纠正外,还需要针对产生的原因制定纠正措施,对纠正措施的评审、实施的监控及实施后的效果进行验证或确认,达到预防缺陷的目的,改进过程或体系,进而保证持续、稳定的开发高质量的产品。
根因分析在改进过程中,一定会遇到问题,那就要进行根因分析(Root-cause Analysis),找到问题产生的根本原因,进而制定策略或采取措施消除根本原因,彻底解决问题。每当彻底解决了一个问题,我们就前进了一步。如果只是解决了表面问题,类似的问题还会发生,这样解决问题的话,就没有进步。根因分析可以分为三个步骤:
- 识别是什么问题,比如是遗漏的缺陷还是客户新的需求?
- 找出造成问题的根本原因,例如,为什么遗漏缺陷?可能是缺少测试用例,也有可能是有用例没有被执行;如果是缺少测试用例,那又是为什么呢?可能回答,想不到?那为什么想不到,是缺少知识还是没有认真对待?一般问五次 “为什么“ 就可以找到根本原因。这是最简单的办法,还有鱼骨图(因果树)、决策表、FMEA 等方法,图 5 就是根因分析之鱼骨图法的一个示例。
- 找到解决问题的方法、措施,然后实施解决方案,解决问题。
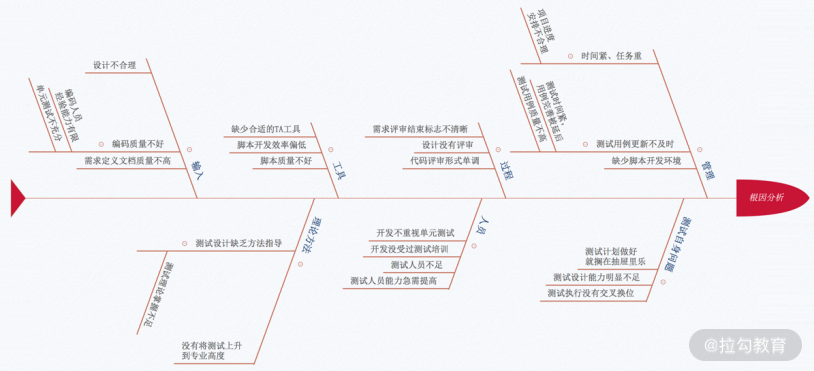
图5 用鱼骨图法进行根因分析的示例图
在敏捷测试中,每个迭代之后团队都需要反思,反思整个迭代过程中做得不够好的地方,然后一起讨论如何改进,借助数据、PDCA 和根因分析等工具持续改进,日复一日、年复一年,团队就在不知不觉中快速地成长起来。
专栏内容到这里就接近尾声了,要和大家说再见的时候了,倒是依依不舍。写这个专栏前后历时 4 个月,虽然时间非常紧张,但还是几经修改,总想把最新、最好的理念和技术带给你。“终身学习、终身成长”作为共勉的座右铭,留给你,也留给我。
如果你觉得课程不错,从中有所收获的话,不要忘了推荐给身边的朋友哦,希望大家都有所提高、不断成长,谢谢!
高效的敏捷测试第十三课 自动化测试、用例测试、接口测试、大数据测试相关推荐
- 乐玩自动化测试模块_深圳大数据测试培训推荐班
推荐就业服务.很多培训机构都有推荐就业的服务,比如就有终身就业推荐服务,如果学员找的工作不满意,的就业老师会一直为他免费推荐工作.深圳大数据测试培训推荐班4.企业内推.有的培训机构会和企业建立比较深入 ...
- 高效的敏捷测试第十一课 敏捷测试分析、策略和方法
第26讲:基于上下文驱动思维的测试分析 从这一讲开始,我们就进入了第 5 部分内容的学习:敏捷测试分析与计划.在这一部分你将学到:测试需求分析.测试风险的识别.测试策略及测试计划的制定.今天先从基于上 ...
- 高效的敏捷测试第一课 敏捷测试介绍,与传统测试对比
开篇词:重剑无锋.大道至简 你好,我是朱少民,欢迎来到我的"敏捷测试"专栏.2000 年至今,我已在测试行业摸爬滚打 20 年,因为热衷分享应该有不少同行认识我.可能是因为读过我写 ...
- 高效的敏捷测试第十课 BDD实践和深化
第24讲:BDD 及其自动化实践 在第 20 讲,我介绍了 TDD.UTDD 和 ATDD,主要讨论了需求的可测试性,通过测试先行的敏捷开发理念,比如先建立用户故事的验收标准,来提升需求的质量.今天在 ...
- 高效的敏捷测试第四课 测试的团队协作
第08讲:借助 Tet Owner 角色,完成团队转型? 三年前的一天,我碰到了一个之前在思科的老同事,问了下他现在软件开发采用的是什么模式? 他回答:"已全面实施敏捷开发模式了,有些团队都 ...
- 敏捷测试金字塔和持续自动化测试(最详解)
目录 背景 测试金字塔 持续自动化测试 背景 背景:云测CloudTest 敏捷和DevOps开发模式下,产品要具备随时可发布的能力,本文介绍如何应用测试金字塔和CI/CD持续自动化测试实现高效的测试 ...
- 测试开发:聊一聊自动化测试框架,值得收藏!
01.什么是自动化测试 自动化测试是指在没有任何人干扰的情况下,可以自动执行测试用例并获得测试结果的软件程序. 自动化测试在很大程度上节省了人力和时间,也没有或很少出现测试误差.一旦自动化测试用例编写 ...
- 自动化测试和软件测试的区别,自动化测试和手动测试之间的区别
随着移动技术的发展,人们越来越离不开互联网和移动应用.现在,移动和Web应用程序已成为我们日常活动的组成部分.现在大多数行业已经将应用程序革命与移动技术一起采用.要为用户提供一款安全好用的移动应用,就 ...
- 10个自动化测试框架,测试工程师用起来
快速实现质量是必要的,因此质量保证得到了很多关注.为了满足卓越的质量和更快的上市时间的需求,自动化测试将被优先考虑.对于微型.小型和中型企业(SMEs)来说,自动化自身的测试过程是非常必要的,而最关键 ...
- OpenGL教程翻译 第二十三课 阴影贴图(一)
第二十三课 阴影贴图(一) 原文地址:http://ogldev.atspace.co.uk/(源码请从原文主页下载) 背景 阴影和光是紧密联系在一起的,因为如果你想要产生一个阴影就必须要光.有许多的 ...
最新文章
- [入门]MyEclipse+tomcat搭建java web环境
- Elasticsearch全文检索对比:match、match_phrase、wildcard
- Qt-qwidget项目入门实例
- node搭建服务器,写接口,调接口,跨域
- JavaScript (If...Else和Switch和循环遍历) 语句以及常用消息框
- 学习Oracle SQL loader 的使用
- 计算机的关机键,怎么让电脑按关机键后不关机?让电脑主机上关机键失效的方法...
- 开源项目之Windows读取Ext4分区的工具 Ext2Read
- catia车灯设计——一些设置
- mybatis三表联合查询
- Educational Codeforces Round 89 (Rated for Div. 2)
- 什么是BPM系统?BPM流程管理系统介绍
- Python数据分析实战之北京二手房房价分析
- mysql 存储视频_数据库中怎样存储视频?谢谢各位
- P3488 [POI2009]LYZ-Ice Skates
- 淘宝开店不看这个,难怪你不挣钱!
- WordPress数据库文章表(字段说明)
- python组件化软件策划_Vue组件化开发
- java古诗_古诗自动生成程序JAVA
- 学计算机为什么上岗之前要培训,浙江公务员面试模拟题华图解析
热门文章
- 九度OJ题目1000: A + B(数学)
- 还怕没女朋友吗?用python做个表白吧
- java课程设计代码_java(课程设计之记事本界面部分代码公布)
- Understanding The Linux Virtual Memory Manager
- 乘法分配律逆运算是什么意思_聚类,我们先操弄一下Kmeans,看看什么是非监督学习...
- 跳转外部地址 带header_微信公众号如何加入超链接?个人订阅号实现点击跳转链接的方法!...
- arcmap地图与mapinfo地图的转换
- 地图下载区 哪家好用
- 内容管理系统CMS学习总结
- 产业互联网周报:滴滴被处以80亿元巨额罚款;消息称中国正启动欧洲企业到中国上市计划;字节跳动确认自研专用芯片...