第三篇: DDcGAN-用于多分辨率图像融合的双判别器生成对抗网络
参考博客1:DDcGAN:用于多分辨率图像融合的双判别器生成对抗网络
DDcGAN文章内容
![]()
![]()
![]()
G: 如图所示,输入可见图像v 和红外图像 i,经过生成器G得到融合图像f.
生成器由2个反卷积层(提高i的分辨率,并使i,v分辨率一样,进行通道相连作为编码器的输入),一个编码器网络(特征提取和融合,生成融合的featuremap)和一个对应的解码器网络(featuremap重构,融合图像f具有与可见图像相同的分辨率)组成,如下图所示。
D: 使用2个鉴别器,是为了分别
以v作为条件,去判断f;
以i作为条件,去判断f;
在训练时,要考虑D和G的对抗,以及,Dv和Di的平衡.
Dv和Di有同样的结构,卷积层的stride为2,最后一层使用Tanh函数生成标量,代表是源图像(real)而不是生成图像(fake)的概率.
对抗目标和损失函数
作者不将源图像v和i作为条件信息(condition) 提供给Dv 和 Di, 即判别器的输入时单通道,而不是一次能输入样本数据+作为条件信息的双通道。
因为当条件和待判别的样本相同时,判别任务被简化以判断输入图像是否相同,这对于神经网络来说太简单了。当生成器无法欺骗鉴别器时,对抗关系将无法建立,并且生成器将倾向于随机生成。 因此,该模型将失去其原始含义。对抗目标如下:
minGmaxDv,Di{E[logDv(v)]+E[log(1−Dv(G(v,i)))]+E[logDi(i)]+E[log(1−Di(ψG(v,i)))]}\begin{gathered} \min _{G} \max _{D_{v}, D_{i}}\left\{\mathbb{E}\left[\log D_{v}(v)\right]+\mathbb{E}\left[\log \left(1-D_{v}(G(v, i))\right)\right]\right. \left.+\mathbb{E}\left[\log D_{i}(i)\right]+\mathbb{E}\left[\log \left(1-D_{i}(\psi G(v, i))\right)\right]\right\} \end{gathered} GminDv,Dimax{E[logDv(v)]+E[log(1−Dv(G(v,i)))]+E[logDi(i)]+E[log(1−Di(ψG(v,i)))]}
ψ表示下采样操作,对应上方结构图。G 的训练目标可以表述为最小化,D的训练目标是使其最大化。注意:
上面没有条件, 不是
E[logDv(v|y)]
损失函数
LG=LGadv+λLcon\begin{gathered} \mathcal{L}_{G}=\mathcal{L}_{G}^{a d v}+\lambda \mathcal{L}_{c o n} \end{gathered} LG=LGadv+λLcon
LGadv=E[log(1−Dv(G(v,i)))]+E[log(1−Di(ψG(v,i)))]\mathcal{L}_{G}^{a d v}=\mathbb{E}\left[\log \left(1-D_{v}(G(v, i))\right)\right]+\mathbb{E}\left[\log \left(1-D_{i}(\psi G(v, i))\right)\right]LGadv=E[log(1−Dv(G(v,i)))]+E[log(1−Di(ψG(v,i)))]
Lcon =E[∥ψG(v,i)−i∥F2+η∥G(v,i)−v∥TV]\mathcal{L}_{\text {con }}=\mathbb{E}\left[\|\psi G(v, i)-i\|_{F}^{2}+\eta\|G(v, i)-v\|_{T V}\right]Lcon=E[∥ψG(v,i)−i∥F2+η∥G(v,i)−v∥TV]
上面是针对生成器的损失,下面是判别器Dv 与 Di 的损失:
LDv=E[−logDv(v)]+E[−log(1−Dv(G(v,i))]LDi=E[−logDi(i)]+E[−log(1−Di(ψG(v,i))]\begin{gathered} \mathcal{L}_{D_{v}}=\mathbb{E}\left[-\log D_{v}(v)\right]+\mathbb{E}\left[-\log \left(1-D_{v}(G(v, i))\right]\right. \\ \mathcal{L}_{D_{i}}=\mathbb{E}\left[-\log D_{i}(i)\right]+\mathbb{E}\left[-\log \left(1-D_{i}(\psi G(v, i))\right]\right. \end{gathered} LDv=E[−logDv(v)]+E[−log(1−Dv(G(v,i))]LDi=E[−logDi(i)]+E[−log(1−Di(ψG(v,i))]
conditional GAN:从纯生成到条件生成
参考文章2:【GAN专题】GAN系列一:条件生成
参考文章3:GAN的几个变种
CGAN概览
应用场景:
基于GAN的可控样本的生成
如:
根据一段文字描述,生成相应的图片。
图像翻译或图像与转换
如:
风格迁移:经典的工作包括马与斑马互换(CycleGAN)
StarGAN人脸属性编辑(换妆、换头发颜色、添加/去除眼镜、加胡子、变爷们或者女性化等)
用GAN换脸
从语义分割的图生成街景图、风景图(Pix2PixHD,GauGAN)
训练时:
通常我们会使用一个网络来对输入z做预测,回归出一个条件 y2y_2y2 ,再与条件y做某种误差计算,从而优化G的生成。
生成器G:
输入: 潜在分布z,如图片,和条件y,如文字描述
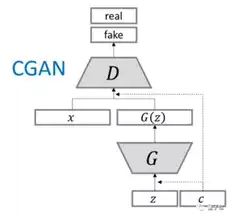
在实际输入时,z可能从高斯分布中采样得到; y可以为一个one-hot向量(某个位为1,表示要复合某种条件,可以是类别,也可以是特征),或者一个数值。
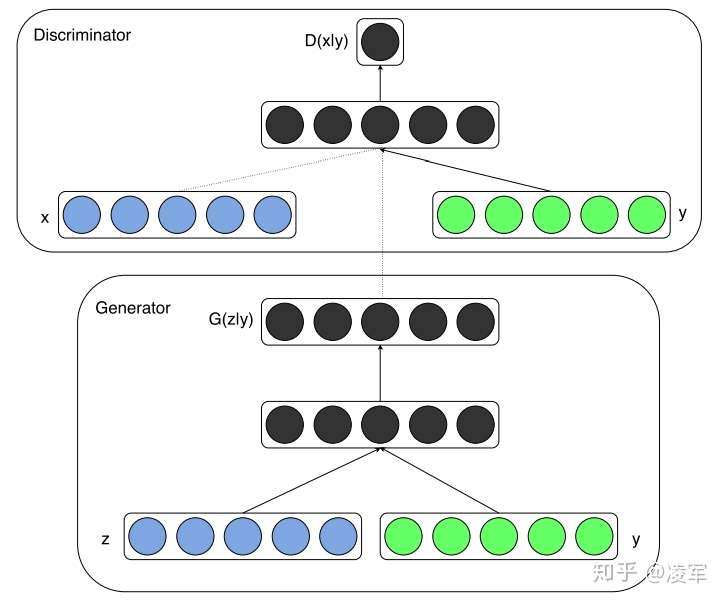
判别器D:
D(x∣y)D(x|y)D(x∣y),其中xxx是生成样本,或者原始数据。
对
真实样本与标签的配对需要接近于1,
对于生成样本与标签需要接近于0,
对于真实样本与不相符的标签,D的输出应该接近于0。
原始CGAN论文中
![]()
图片xxx以及条件yyy ,如果
标签与真实图片的标签相同,输出的数越接近于1越好,否则越接近于0,
第二项,包含了D(G(z∣y)∣y)D(G(z|y)|y)D(G(z∣y)∣y) ,用生成样本和标签y来优化D和G(在训练D时优化D,训练G时优化G)。
还可以使用两个判别器,分别判断图片是真实/生成的,以及输出条件,通过设置条件损失函数来对G生成的图片进行条件约束。
损失函数
D的损失函数:
V~=1m∑i=1mlogD(ci,xi)+1m∑i=1mlog(1−D(ci,x~i))+1m∑i=1mlog(1−D(ci,x^i)\tilde{V}=\frac{1}{m} \sum_{i=1}^{m} \log D\left(c^{i}, x^{i}\right)+\frac{1}{m} \sum_{i=1}^{m} \log \left(1-D\left(c^{i}, \tilde{x}^{i}\right)\right)+\frac{1}{m} \sum_{i=1}^{m} \log \left(1-D\left(c^{i}, \hat{x}^{i}\right)\right.V~=m1i=1∑mlogD(ci,xi)+m1i=1∑mlog(1−D(ci,x~i))+m1i=1∑mlog(1−D(ci,x^i)
其中,
第一项(c,x)(c,x)(c,x)是正确条件与真实图片的 pair,应该给高分;
第二项是正确条件ccc与仿造图片G(c,z)G(c,z)G(c,z)的pair,应该给低分(于是加上了“1-”);
第三项是错误条件ccc与真实图片的 pair,也应该给低分。
可以明显的看出,CGAN 与 GANs 在判别器上的不同之处就是多出了第三项
G的损失函数:
V~=1m∑i=1mlog(D(G(ci,zi)))\tilde{V}=\frac{1}{m} \sum_{i=1}^{m} \log \left(D\left(G\left(c^{i}, z^{i}\right)\right)\right)V~=m1i=1∑mlog(D(G(ci,zi)))
G想要骗过D,因此,这个得分越大越好。
算法实现
![]()
![]()
输入
![]()
![]()
- 为了把图片和条件结合在一起,往往会把
x丢入一个网络产生一个 embedding,condition也丢入一个网络产生一个 embedding,然后把这两个 embedding 拼在一起丢入一个网络中,这个网络既要判断第一个 embedding 是否真实,同时也要判断两个 embedding 是否逻辑上匹配,最终给出一个分数。 - 另外一种情况,可以将
图片x送入一个网络,得到real/fake分数,再将网络中间输出与条件一起送到另一个网络,判断条件c与图片是否符合一致,从而得到另一个Conditional fulfillment分数。
在有些任务上,对condition的描述非常细致,不是通过010101这类编码来标记的标签,比如连续标签,通常我们会使用一个网络来对输入x做预测,回归出一个条件 y2y_2y2 ,再与条件c做某种误差计算,从而优化G的生成。如做人脸属性编辑的StarGAN、STGAN就是使用了交叉熵损失,而非0/1的损失。GauGAN使用了语义图作为条件,也是用了这一类的损失函数。
代码理解
首先理解CGan
![]()
参考博文:
参考文章4:tf: 详解GAN代码之搭建并详解CGAN代码
参考文章5:Pytorch CGAN代码
下面是一些代码摘抄,为了展示算法的结构,仅有一些使用条件y的核心代码:
tf版的
生成器:
def generator(image, gf_dim=64, reuse=False, name="generator"):input_dim = int(image.get_shape()[-1]) #获取输入通道dropout_rate = 0.5 #定义dropout的比例with tf.variable_scope(name):if reuse:tf.get_variable_scope().reuse_variables()else:assert tf.get_variable_scope().reuse is False#第一个卷积层,输出尺度[1, 128, 128, 64]e1 = batch_norm(conv2d(input_=image, output_dim=gf_dim, kernel_size=4, stride=2, name='g_e1_conv'), name='g_bn_e1')........#第八个卷积层,输出尺度[1, 1, 1, 512]e8 = batch_norm(conv2d(input_=lrelu(e7), output_dim=gf_dim*8, kernel_size=4, stride=2, name='g_e8_conv'), name='g_bn_e8')#第一个反卷积层,输出尺度[1, 2, 2, 512]d1 = deconv2d(input_=tf.nn.relu(e8), output_dim=gf_dim*8, kernel_size=4, stride=2, name='g_d1').......#第八个反卷积层,输出尺度[1, 256, 256, 3]d8 = deconv2d(input_=tf.nn.relu(d7), output_dim=input_dim, kernel_size=4, stride=2, name='g_d8')return tf.nn.tanh(d8)
判别器:
def discriminator(image, targets, df_dim=64, reuse=False, name="discriminator"):with tf.variable_scope(name):if reuse:tf.get_variable_scope().reuse_variables()else:assert tf.get_variable_scope().reuse is Falsedis_input = tf.concat([image, targets], 3)#第1个卷积模块,输出尺度: 1*128*128*64h0 = lrelu(conv2d(input_ = dis_input, output_dim = df_dim, kernel_size = 4, stride = 2, name='d_h0_conv')).......#第4个卷积模块,输出尺度: 1*32*32*512h3 = lrelu(batch_norm(conv2d(input_ = h2, output_dim = df_dim*8, kernel_size = 4, stride = 1, name='d_h3_conv'), name='d_bn3'))#最后一个卷积模块,输出尺度: 1*32*32*1output = conv2d(input_ = h3, output_dim = 1, kernel_size = 4, stride = 1, name='d_h4_conv')dis_out = tf.sigmoid(output) #在输出之前经过sigmoid层,因为需要进行log运算return dis_out
在生成器和判别器中,image参数就是指的条件y,
并且在生成器的输入中,随机噪声被去掉了(仅仅输入了条件);
在判别器的输入中,条件image 和 待判别的图像targets被拼接(concat)了起来。
调用如下:
gen_label = generator(image=train_picture, gf_dim=64, reuse=False, name='generator') #得到生成器的输出dis_real = discriminator(image=train_picture, targets=train_label, df_dim=64, reuse=False, name="discriminator") #判别器返回的对真实标签的判别结果dis_fake = discriminator(image=train_picture, targets=gen_label, df_dim=64, reuse=True, name="discriminator") #判别器返回的对生成(虚假的)标签判别结果# 注意,下面的train_picture,train_label,gen_label应根据上面的参数来确定其含义EPS = 1e-12 #EPS用于保证log函数里面的参数大于零gen_loss_GAN = tf.reduce_mean(-tf.log(dis_fake + EPS)) #计算生成器损失中的GAN_loss部分gen_loss_L1 = tf.reduce_mean(l1_loss(gen_label, train_label)) #计算生成器损失中的L1_loss部分gen_loss = gen_loss_GAN * args.lamda_gan_weight + gen_loss_L1 * args.lamda_l1_weight #计算生成器的lossdis_loss = tf.reduce_mean(-(tf.log(dis_real + EPS) + tf.log(1 - dis_fake + EPS))) #计算判别器的loss
pytorch版的
生成器
ngpu = 1 # 可利用的GPU数量,使用0将运行在CPU模式。
# 决定我们在哪个设备上运行
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")class Generator(nn.Module):def __init__(self, ngpu):self.ngpu = ngpusuper(Generator,self).__init__()self.gen=nn.Sequential(....)def forward(self, x):x=self.gen(x)return x# 创建生成器
netG = Generator(ngpu).to(device)判别器:
class Discriminator(nn.Module):def __init__(self, ngpu):super(Discriminator, self).__init__()self.ngpu = ngpuself.main = nn.Sequential(......)def forward(self, x):return self.main(x)# 创建判别器
netD = Discriminator(ngpu).to(device)
训练阶段
# 建立一个在训练中使用的真实和假的标记
real_label = 1
fake_label = 0
# 初始化 BCE损失函数
criterion = nn.BCELoss()netD.zero_grad()
# 使用所有真实样本批次训练
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, device=device)output = netD(real_cpu)
real_label_label = output[:, 0] # 第一维就是预测是否是真实图片# 对所有真实样本批次计算损失
errD_real = criterion(real_label_label, label)# 使用生成器G生成假图片
fake = netG(noise) # noise是GAN的输入
label.fill_(fake_label)
real_label_label = output[:, 0]
errD_fake = criterion(real_label_label, label)# 使用判别器分类所有的假批次样本
output = netD(fake.detach())
real_label_pic = output[:, 1:]
errD_fake_pic = criterion_pic(real_label_pic, data[1].cuda(device))# 把所有真样本和假样本批次的梯度加起来
errD = errD_real + errD_fake + errD_fake_pic然后,是DDcGan
详细代码在参考博文1中有,再贴一遍:
GitHub-official-Tensorflow
GitHub-unofficial-PyTorch
生成器
class Encoder(object):def __init__(self, scope_name):self.scope = scope_name...def encode(self, image):...
class Decoder(object):def __init__(self, scope_name):self.scope = scope_name...def decode(self, image):...class Generator(object):def __init__(self, sco):self.encoder = Encoder(sco)self.decoder = Decoder(sco)def transform(self, vis, ir):img = tf.concat([vis, ir], 3)code = self.encoder.encode(img)self.target_features = codegenerated_img = self.decoder.decode(self.target_features)return generated_img
判别器:
class Discriminator1(object):def __init__(self, scope_name):self.scope = scope_name...def discrim(self, img, reuse):...class Discriminator2(object):def __init__(self, scope_name):self.scope = scope_name...def discrim(self, img, reuse):...
训练时:
with tf.Graph().as_default(), tf.Session() as sess:SOURCE_VIS = tf.placeholder(tf.float32, shape = (BATCH_SIZE, patch_size, patch_size, 1), name = 'SOURCE_VIS')SOURCE_IR = tf.placeholder(tf.float32, shape = (BATCH_SIZE, patch_size, patch_size, 1), name = 'SOURCE_IR')### 融合以及鉴别G = Generator('Generator')generated_img = G.transform(vis = SOURCE_VIS, ir = SOURCE_IR)D1 = Discriminator1('Discriminator1')grad_of_vis = grad(SOURCE_VIS)D1_real = D1.discrim(SOURCE_VIS, reuse = False)D1_fake = D1.discrim(generated_img, reuse = True)D2 = Discriminator2('Discriminator2')D2_real = D2.discrim(SOURCE_IR, reuse = False)D2_fake = D2.discrim(generated_img, reuse = True)####### LOSS FUNCTION# Loss for GeneratorG_loss_GAN_D1 = -tf.reduce_mean(tf.log(D1_fake + eps))G_loss_GAN_D2 = -tf.reduce_mean(tf.log(D2_fake + eps))G_loss_GAN = G_loss_GAN_D1 + G_loss_GAN_D2LOSS_IR = Fro_LOSS(generated_img - SOURCE_IR)LOSS_VIS = L1_LOSS(grad(generated_img) - grad_of_vis)G_loss_norm = LOSS_IR /16 + 1.2 * LOSS_VISG_loss = G_loss_GAN + 0.6 * G_loss_norm# Loss for Discriminator1D1_loss_real = -tf.reduce_mean(tf.log(D1_real + eps))D1_loss_fake = -tf.reduce_mean(tf.log(1. - D1_fake + eps))D1_loss = D1_loss_fake + D1_loss_real# Loss for Discriminator2D2_loss_real = -tf.reduce_mean(tf.log(D2_real + eps))D2_loss_fake = -tf.reduce_mean(tf.log(1. - D2_fake + eps))D2_loss = D2_loss_fake + D2_loss_realsess.run(tf.global_variables_initializer())for epoch in range(EPOCHS):np.random.shuffle(source_imgs)for batch in range(n_batches):step += 1current_iter = stepVIS_batch = source_imgs[batch * BATCH_SIZE:(batch * BATCH_SIZE + BATCH_SIZE), :, :, 0]IR_batch = source_imgs[batch * BATCH_SIZE:(batch * BATCH_SIZE + BATCH_SIZE), :, :, 1]VIS_batch = np.expand_dims(VIS_batch, -1)IR_batch = np.expand_dims(IR_batch, -1)FEED_DICT = {SOURCE_VIS: VIS_batch, SOURCE_IR: IR_batch}it_g = 0it_d1 = 0it_d2 = 0# run the training stepif batch % 2==0:sess.run([D1_solver, clip_D1], feed_dict = FEED_DICT)it_d1 += 1sess.run([D2_solver, clip_D2], feed_dict = FEED_DICT)it_d2 += 1else:sess.run([G_solver, clip_G], feed_dict = FEED_DICT)it_g += 1g_loss, d1_loss, d2_loss = sess.run([G_loss, D1_loss, D2_loss], feed_dict = FEED_DICT)if batch%2==0:while d1_loss > 1.7 and it_d1 < 20:sess.run([D1_solver, clip_D1], feed_dict = FEED_DICT)d1_loss = sess.run(D1_loss, feed_dict = FEED_DICT)it_d1 += 1while d2_loss > 1.7 and it_d2 < 20:sess.run([D2_solver, clip_D2], feed_dict = FEED_DICT)d2_loss = sess.run(D2_loss, feed_dict = FEED_DICT)it_d2 += 1d1_loss = sess.run(D1_loss, feed_dict = FEED_DICT)else:while (d1_loss < 1.4 or d2_loss < 1.4) and it_g < 20:sess.run([G_GAN_solver, clip_G], feed_dict = FEED_DICT)g_loss, d1_loss, d2_loss = sess.run([G_loss, D1_loss, D2_loss], feed_dict = FEED_DICT)it_g += 1while (g_loss > 200) and it_g < 20:sess.run([G_solver, clip_G], feed_dict = FEED_DICT)g_loss = sess.run(G_loss, feed_dict = FEED_DICT)it_g += 1print("epoch: %d/%d, batch: %d\n" % (epoch + 1, EPOCHS, batch))if batch % 10 == 0:elapsed_time = datetime.now() - start_timelr = sess.run(learning_rate)print('G_loss: %s, D1_loss: %s, D2_loss: %s' % (g_loss, d1_loss, d2_loss))print("lr: %s, elapsed_time: %s\n" % (lr, elapsed_time))result = sess.run(merged, feed_dict=FEED_DICT)writer.add_summary(result, step)if step % logging_period == 0:saver.save(sess, save_path + str(step) + '/' + str(step) + '.ckpt')is_last_step = (epoch == EPOCHS - 1) and (batch == n_batches - 1)if is_last_step or step % logging_period == 0:elapsed_time = datetime.now() - start_timelr = sess.run(learning_rate)print('epoch:%d/%d, step:%d, lr:%s, elapsed_time:%s' % (epoch + 1, EPOCHS, step, lr, elapsed_time))第三篇: DDcGAN-用于多分辨率图像融合的双判别器生成对抗网络相关推荐
- 云检测2020:用于高分辨率遥感图像中云检测的自注意力生成对抗网络Self-Attentive Generative Adversarial Network for Cloud Detection
用于高分辨率遥感图像中云检测的自注意力生成对抗网络Self-Attentive Generative Adversarial Network for Cloud Detection in High R ...
- 好生学习!数百篇GAN论文已下载好!搭配一份生成对抗网络最新综述!
欢迎点击上方蓝字,关注啦~ 相关阅读: GAN整整6年了!是时候要来捋捋了! 有点夸张.有点扭曲!速览这些GAN如何夸张漫画化人脸! 天降斯雨,于我却无!GAN用于去雨如何? 脸部转正!GAN能否让侧 ...
- GAN属于计算机视觉领域嘛_【图像上色小综述】生成对抗网络的GAN法
本文首发于公众号[机器学习与生成对抗网络],欢迎关注.回复 GAN 获取分类好的论文集,后台会邀您加入CV&GAN交流群一起讨论) 戳我,查看GAN的系列专辑~! 0,图像上色及其分类 图像上 ...
- 四天搞懂生成对抗网络(三)——用CGAN做图像转换的鼻祖pix2pix
点击左上方蓝字关注我们 [飞桨开发者说]吕坤,唐山广播电视台算法工程师,PPDE飞桨开发者技术专家,喜欢研究GAN等深度学习技术在媒体.教育上的应用. Pix2Pix的不甘の野望 也许是CycleGA ...
- 飞浆论文复现:用于图像到图像翻译的具有自适应层实例化的非监督的生成对抗网络
Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to ...
- ECCV2022 | 生成对抗网络GAN论文汇总(图像转换-图像编辑-图像修复-少样本生成-3D等)...
图像转换/图像可控编辑 视频生成 少样本生成 图像外修复/结合transformer GAN改进 新数据集 图像增强 3D 图像来源归属分析 一.图像转换/图像可控编辑 1.VecGAN: Image ...
- Text to image论文精读 DM-GAN: Dynamic Memory Generative Adversarial Networks for t2i 用于文本图像合成的动态记忆生成对抗网络
Text to image论文精读 DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis ...
- PcGAN:一种用于一次学习的噪声鲁棒条件生成对抗网络∗
简 介: 在本文中,我们为智能交通系统提出了一种基于条件生成对抗网络的新型交通标志分类方法.所提出的 PcGAN是一个端到端网络,网络框架包含交替更新模块,即数据重建模块和退化生成模块,以及用于退化消 ...
- 【杂谈】有三AI秋季划增加生成对抗网络小组,你准备好大GAN一场了吗
文/编辑 | 言有三 作为被誉为"下一代深度学习技术",同时已经在工业界能够真正成熟稳定应用的GAN,有三AI一直在关注相关的技术,并输出了大量的内容. 那如何从理论上和实践上更好 ...
- 文本生成图像简述4——扩散模型、自回归模型、生成对抗网络的对比调研
基于近年来图像处理和语言理解方面的技术突破,融合图像和文本处理的多模态任务获得了广泛的关注并取得了显著成功. 文本生成图像(text-to-image)是图像和文本处理的多模态任务的一项子任务,其根据 ...
最新文章
- share_ptr_c++11
- iphone系统更新 3002错误
- 【细无巨细,包你学会】自学Python运行时会遇到的异常与解决方法
- How to find CRM system's integrated ERP system
- 使用DataTable更新数据库
- 443. 压缩字符串
- 一步一步教你使用AgileEAS.NET基础类库进行应用开发-基础篇-演示ORM中的查询
- 吐嘈OpenCV的图像旋转功能 _7
- Switching Between HTTP and HTTPS Automatically
- 算法:求两个数最大公约数
- 西门子PLC开关量选择
- Adobe CS5 序列号及配置方法
- UG 6.0软件安装教程
- 2016ICPC北京现场赛打铁退役之旅
- cmos逻辑门传输延迟时间_组合逻辑电路详解、实现及其应用
- 根据用户名字刷账户(取用户名的字母)
- CSR867x — 说说蓝牙音频常用的编解码格式
- Linux文件目录管理、文件内容查看以及文件内容查询命令(详细命令)
- 智慧公交站台:EasyCVR智能视频平台助力城市智慧交通建设
- C:\Users\用户名\AppData里面的文件可以删除吗