数据科学,会如何向我们撒谎?
【IT168 编译】原文作者: Dima Shulga,HiredScore数据科学家
原文链接: https://www.kdnuggets.com/2018/07/how-lie-data-science.html

最近我读了Darrel Huff写的《统计陷阱》(How to lie with statistics)这本书。这本书讲的是如何利用统计数据使人们得出错误的结论。我发现这是一个令人感兴趣的话题,认为它与数据科学非常相关。因此我想要写一个书中所举例子的“数据科学”版,其中有些是书中提到的,有些则是笔者在现实生活中看到的相关例子。
这篇文章所讲的并非如何通过数据科学进行撒谎。相反,它会告诉我们:我们会如何因为没有对信息渠道中不同部分的细节给予充分的关注而被愚弄。
图表(Charts)
现在,把自己想象成某个公司的新进数据科学家。这家公司之前已经有了一个数据科学团队,通过建立模型来预测一些重要的事情。你是一个非常有才华的数据科学家,一个月后,你能够将他们的模型精确度提高3%。难以置信!你希望向别人展示你的进步,所以你准备了下面这个表格:
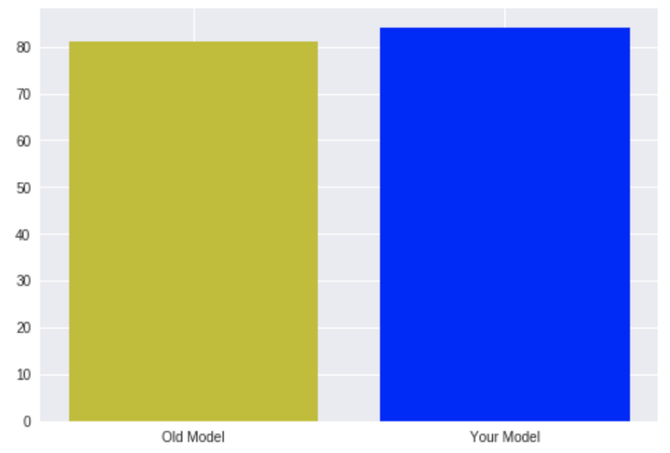
这个看起来不错,但似乎无法给人留下深刻的印象。而你想让大家都对你的成果印象深刻,那么你能做什么?(除了进一步优化你的模型)
为了更加突出地展示相同的数据,您需要做的就是稍微更改图表,你需要让表格专注于“变化”。所有在80%以下的数据不需要展现,它可以是这样的:
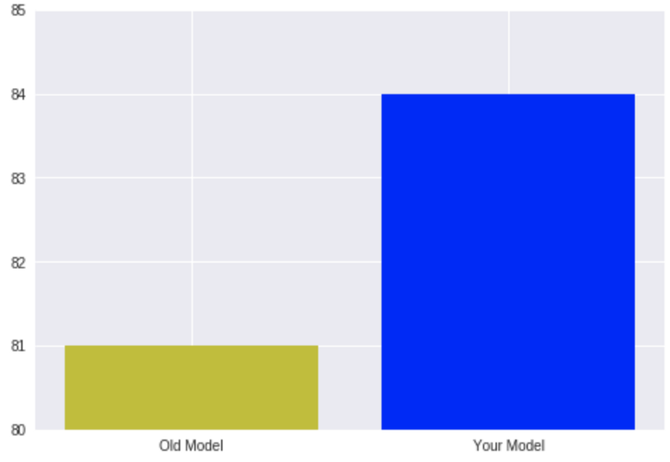
这样看起来,你的模型比旧模型好了四倍!当然,聪明人稍微一想就会确切地知道发生了什么,但这张图表看起来确实令人印象深刻——很多人会记住这个巨大的差距,而不是确切的数字。
我们可以做同样的事情。假设你和你的团队在做一些模型,最近几周你有了突破,所以你的模型性能提高了2%,它看起来像这样:
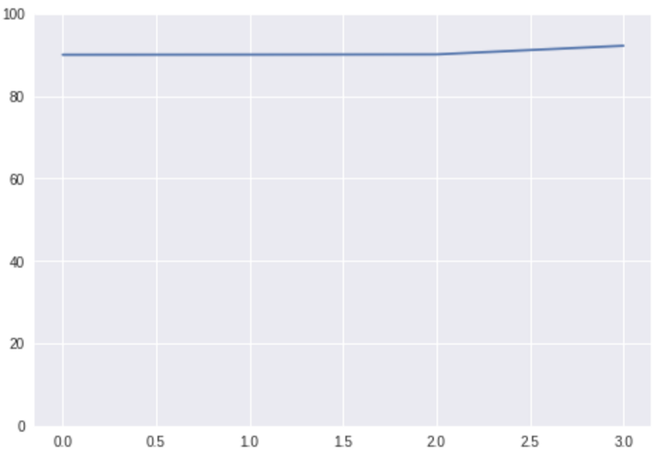
其中的变化很难直观看到,实际数字分别是[90.02、09.05、90.1、92.2]。同上,2%的增长或许是一个不错的进步,但在这个图表中并不十分友好。
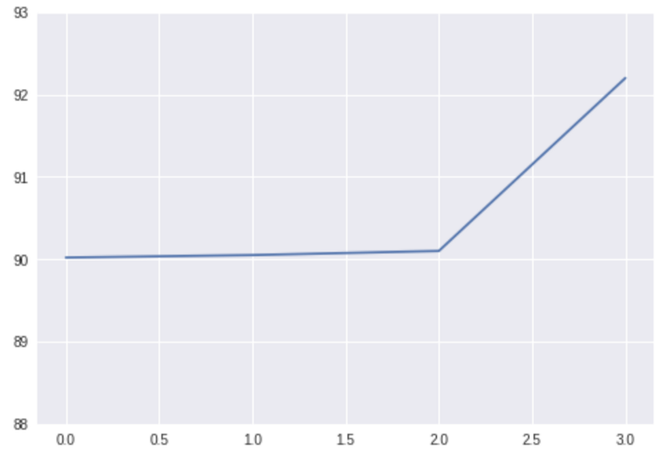
我们用与上述大致相同的方法对图表进行一次改进,数字是相同的,但这个图表看起来比前一个要好得多。
度量标准(Measurements)

通常来说,初级数据科学家往往对使用什么度量标准来度量他们的模型性能这件事缺乏认真考虑。这可能会让他们常常去使用一些默认的度量标准,而大多数情况下,这可能是错的。以准确性为例,在现实生活中(大多数情况下),这是一个非常糟糕的度量标准。因为在现实生活的大多数问题中,数据都是不平衡的。比如Titanic乘客生还预测模型,这是一个非常受欢迎的Kaggle入门项目。如果我告诉你,我建立的模型有61%的准确度,这个结果可以称作好吗?很难说,但总比没有结果强吧!让我展示一下我具体做了什么:
predicted = np.zeros(len(test_df))
print accuracy_score(predicted, test_df['Survived'])
是的,我所做的就是,预测所有的实例都为“0”(或“NO”),然后就可以得到这个准确率(61%),因为幸存的人比遇难的人要少。更极端的情况是数据非常不平衡,在这种情况下,即使99%的准确率可能也没有任何意义。这种极端不平衡数据的一个例子就是,当我们想要正确地分类一些罕见的疾病时,如果只有1%的人患有这种疾病,那么每次只要预测“不”,我们就能得到99%的准确率!
准确性的问题只是其中一个个例。当我们阅读一些研究/试验/论文的结果(或者如果我们发布了我们的结果)时,我们需要确保所使用的度量标准适合我们试图去度量的问题。
我们需要做的另一件重要的事情是了解结果的好坏。即使我们使用了正确的度量标准,有时也很难知道它们是好是坏。90%的精度对于一个问题来说可能是很好的,但是对于其他问题来说就很糟糕了。一个不错的办法是设定一个基准,创建一个非常简单的(甚至是随机的)模型,并将您/其他人的结果与它进行比较。对于泰坦尼克号的问题,我们已经知道,只要输出结果都为“NO”,我们就会有61%的准确率,所以当某个算法拥有70%的准确率时,我们就可以说这个算法有所贡献——当然,它可能做得更好。
漏洞(Leaks)

我想谈谈我在数据科学领域中遇到过的三种漏洞。特征工程/选择漏洞、依赖数据漏洞和不可用数据漏洞。
特征工程/选择漏洞: 在大多数情况下,我们需要对数据进行预处理和/或特征工程,然后再将其放入一些分类器中。很多时候使用一些类(Transformer)很容易做到这一点,这里有一个sklearn示例:
X, y = get_some_data()
X = SomeFeaturesTransformer().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = SomeClassifier().fit(X_train, y_train)
在第一行中,我使用某种方法获取数据。然后我使用SomeFeaturesTransformer类从数据中提取特征。然后我把数据分成训练和测试,最后训练分类器。
看到漏洞了吗?大多数时候,特征提取/选择是模型的一部分,所以,由于是在分割之前执行这个步骤,致使我正在测试集上训练模型中的一部分!一个简单的例子是,当我们想要使用一些关于特征的统计数据时。例如,我们的一个特征可能是偏离均值。假设我们有一个关于房子大小-价格的预测,我们想用当前房子大小和平均房子大小的不同作为一个特征。通过计算整个数据的平均值(而不仅仅是训练集),我们将关于测试集的信息引入到了我们的模型中。(数据的平均值是模型的一部分)。在这种情况下,我们可能在测试集上得到突出的结果,但是当我们在生产中使用这个模型时,它将产生不同的/更糟糕的结果。
我们的模型不仅仅是渠道末端的分类器。我们需要确保模型的任何部分都不能访问关于测试集的任何信息。
依赖数据泄漏: 在我的论文中,我建立了一个系统,试图将话语的记录分为典型和非典型的话语。我有30个参与者,每15个话语重复4次。总共有30*15*4=1800次录音。这是非常少的数据,所以我想做交叉验证来评估我的算法,而不是把它分解成训练和测试。但是,我需要非常小心,即使没有交叉验证,当我随机选择我的一些数据作为一个测试集时,我将会(高概率)得到测试集中所有参与者的记录!这就意味着我的模型是在参与者身上训练的,他们将在上面进行测试!当然,我的结果会很好,但是我的模型将学会的是识别不同参与者的不同声音,而不是典型的或非典型的话语!我会得高分,但实际上,我的模型并没有价值。
正确的方法是在参与者级别上分割数据(或进行交叉验证),即将5人作为测试组,另外25人作为训练组。
这种类型的依赖数据可能出现在不同的数据集中。另一个例子是当我们尝试在工作和候选人之间创建匹配算法时。我们不希望向我们的模型作业显示将出现在测试集中的数据。我们需要确保模型的所有部分绝对不会看到来自测试集中的任何数据。
不可用数据漏洞: 这是很常见的。有时,我们的数据中有的列在将来是不可用的。这里有一个简单的例子:我们想要预测用户对我们网站上的产品的满意度。我们有很多历史数据,所以我们用它来建立模型。我们有一个叫用户满意度的字段,它是我们的目标变量。从调查结果看,用户满意度还不错。然而,当我们在生产中使用我们的模型时,它会造成绝对非理性的预测行为。结果表明,除了总体用户满意度之外,用户还提供了其他字段,比如用户是否满意交付、发货、客户支持等等。对我们来说,这些字段在预测时是不可用的,并且与一般用户满意度有很大的相关性(和预测性)。我们的模型使用它们来预测总体的满意度,并且做得很好,但是当这些领域不可用的时候(我们把它们归为一类),这个模型就不需要占太大的比重。
机会和运气

让我们回到典型与非典型话语问题。正如我说的,只有30个参与者,所以如果我做一个简单的20%-80%的训练-测试分级,我只会让6个参与者来测试。6个参与者非常少,我可能只是碰巧把其中的5个分类正确,因为运气。这将给我100%的准确性!这个结果可能看起来很优秀,当我发布我的结果时,它看起来会非常令人印象深刻,但事实上这个分数并不重要(甚至并不真实)。
这里正确的方法是“省略一个交叉验证”,并使用所有的参与者作为测试。
人
将学习算法与人类进行比较是很有吸引力的。这在很多医学领域都很常见。然而,比较人类和机器并不是一件小事。假设我们有一个可以诊断罕见疾病的算法。我们已经看到,对于不平衡的数据,使用精度作为测量标准不是一个好主意。在这种情况下,如果我们使用精度和查全率来进行模型评估和比较,可能会更好。我们可以使用精度和一些医生的查全率,并将其与我们的算法进行比较。然而,在精确和查全率之间总有一个权衡,我们并不总是清楚我们想要的是什么,高精确度还是高查全率。如果我们的算法有60%的准确率和80%的查全率,医生有40%的准确率和100%的查全率,谁更好?我们可以说算法精度更高,因此算法“优于人类”。此外,作为一种算法,我们可以控制这种权衡,我们需要做的就是更改分类阈值,并将精度(或查全率)设置为我们想要的程度(看看查全率会发生什么)。
因此,更好的选择是使用ROC AUC评分或“平均精度”进行模型评估。这些度量考虑了精确-查全率权衡,并提供了关于我们的模型如何“预测”的更好的度量方法。人类没有ROC自动控制系统,也没有“平均精度”。我们(在大多数情况下)不能控制任何一个医生的这个阈值。有不同的技术可以为一组人类决策者提供精确的查全率曲线,但这些技术几乎从未使用过。这里有一篇关于这方面的文章,非常棒,而且要详细得多:
机器真的能打败医生吗?ROC曲线和性能指标
医学的深度学习研究现在有点像美国西部淘金时代:有时你会发现金子,有时你会发现……
结论
在这篇文章中,我展示了当我们尝试发布一些算法结果或解释其他结果时可能出现的不同陷阱。我认为从中得出的主要观点是“当它(结果)看起来好得让人难以置信时,它很可能真的不可信”。当我们的模型(或其他模型)看起来非常好时,我们必须确保过程中的所有步骤都是正确的。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31473948/viewspace-2168759/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31473948/viewspace-2168759/
数据科学,会如何向我们撒谎?相关推荐
- python 数据科学书籍_您必须在2020年阅读的数据科学书籍
python 数据科学书籍 "We're entering a new world in which data may be more important than software.&qu ...
- 如何学习数据挖掘和数据科学的7个步骤
前言 概括 1 学习语言 2 工具:数据挖掘,数据科学和可视化软件 3 教科书 4 教育:网络研讨会,课程,证书和学位 5 数据 6 比赛 7 互动:会议,团体和社交网络 more 前言 最近一直一再 ...
- GPU—加速数据科学工作流程
GPU-加速数据科学工作流程 GPU-ACCELERATE YOUR DATA SCIENCE WORKFLOWS 传统上,数据科学工作流程是缓慢而繁琐的,依赖于cpu来加载.过滤和操作数据,训练和部 ...
- python包 wget_Python数据科学“冷门”库
原标题 | Lesser Known Python Libraries for Data Science 作者 | Parul Pandey 译者 | CONFIDANT(福建师范大学).Seabis ...
- 数据科学Python训练营课程:从初级到高级 Python for Data Science Bootcamp Course:Beginner to Advanced
通过代码实现.示例等,掌握您需要了解的关于Python.Pandas和Numpy的一切! 你会学到什么 通过代码实现.示例等,掌握您需要了解的关于Python.Pandas和Numpy的一切! 学习高 ...
- .net里鼠标选中的text数据怎么获取_Python数据科学实践 | 爬虫1
点击上方蓝色字体,关注我们 大家好,基于Python的数据科学实践课程又到来了,大家尽情学习吧.本期内容主要由智亿同学与政委联合推出. 前面几章大家学习了如何利用Python处理与清洗数据,如何探索性 ...
- 《数据科学R语言实践:面向计算推理与问题求解的案例研究法》一一2.1 引言...
本节书摘来自华章计算机<数据科学R语言实践:面向计算推理与问题求解的案例研究法>一书中的第2章,第2.1节,作者:[美] 德博拉·诺兰(Deborah Nolan) 邓肯·坦普·朗(Dun ...
- 数据科学究竟是什么?
数据科学是一门将数据变得有用的学科.它包含三个重要概念: 统计 机器学习 数据挖掘/分析 数据科学的定义 如果你回顾一下数据科学这个术语的[早期历史](),会发现有两个主题密切相连: 大数据意味着计算 ...
- 《机器学习与数据科学(基于R的统计学习方法)》——2.11 R中的SQL等价表述...
本节书摘来异步社区<机器学习与数据科学(基于R的统计学习方法)>一书中的第2章,第2.11节,作者:[美]Daniel D. Gutierrez(古铁雷斯),更多章节内容可以访问云栖社区& ...
- 《Python数据科学指南》——1.8 使用迭代器
本节书摘来自异步社区<Python数据科学指南>一书中的第1章,第1.8节,作者[印度] Gopi Subramanian ,方延风 刘丹 译,更多章节内容可以访问云栖社区"异步 ...
最新文章
- 虚拟化如何做实?详解戴尔2.0版解决方案
- IBatis.Net学习笔记四--数据库的缓存模式
- Java入门教程五(数字和日期处理)
- 计算机网络实验课,【课堂】师生同上一节计算机网络实验课
- 关于单车创新的一两点思考
- sqlserver注释巧清理
- java类无法调用值,Kotlin无法调用到Java中定义的interface类的问题记录
- IOCP模型TCP服务器
- DNS 服务器 4013警告信息的解决
- 朱松纯:AI 需由“心”驱动,实现“心”与“理”的动态平衡
- handbrake下载太慢_handbrake使用教程
- 框架合集:Java框架自学视频教程-动力节点
- 联想启天m430安装黑苹果 10500 big sur 11.6
- 微信公众帐号迁移流程指引
- Enigma密码机原理图解
- iOS 应用签名原理
- django—APIView详细讲解
- B2B2C系统亮点是什么?如何助力珠宝首饰企业打造全渠道多商户商城管理体系
- 自动控制原理第4章——根轨迹法(思维导图)
- 手游虚拟机中连接不到服务器,自由幻想手游模拟器进不去游戏 登录失败解决办法...