《社会调查数据管理——基于Stata 14管理CGSS数据》一3.4 Stata的一些术语及使用通则...
本节书摘来自异步社区《社会调查数据管理——基于Stata 14管理CGSS数据》一书中的第3章,第3.4节,作者 唐丽娜,更多章节内容可以访问云栖社区“异步社区”公众号查看
3.4 Stata的一些术语及使用通则
在讲解Stata术语及使用通则之前,首先了解一下Stata。简言之,Stata是一个统计软件,可用于统计分析和数据管理。Stata是付费软件,用户可以从Stata的官网上直接购买最新版的Stata 14。
安装Stata后,打开Stata,界面如图3-1所示。
Stata的主界面由六部分构成:工具栏、命令回顾窗口(Review)、结果窗口(Result)、命令窗口(Command)、变量窗口(Variables)和属性窗口(Properties)。
中间最大一部分是结果窗口,所有命令运行出的结果都显示在这个窗口里。最上边是工具栏,用户可以通过单击图标操作Stata,本书不建议用“单击”菜单的方法来分析数据和管理数据,而是通过Stata的do-file(详见3.4.1)来完成数据分析和数据管理工作。结果窗口的下面就是命令窗口,用户直接在此输入命令,按回车键(Enter键)即可运行。
结果窗口的左边是命令回顾窗口,打开Stata后,运行的所有命令都被保存在回顾窗口,如果用户想再次使用已经用过的命令,既可以在命令窗口重新输入一遍,也可以直接单击回顾窗口的命令,此时该命令就会直接出现在命令窗口。
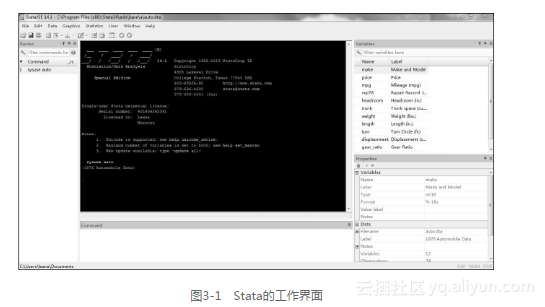
结果窗口的右上方是变量窗口,数据里的所有变量都会在此显示。右下方是属性窗口,该窗口有两个子窗口:变量(Variables)窗口和窗口(Data)数据。
在主窗口的左下方显示的是当前工作目录(current working directory)。
和以前的版本相比,Stata14新增了很多功能,如命令unicode,该命令能轻松解决不同语言之间的编码转换问题。在Stata14以前的版本中,经常会遇到汉字乱码问题,Stata14的unicode命令专门解决这类问题。
3.4.1 Stata中的常用术语
和其他程序一样,Stata里有一些常见的术语,理解这些术语的含义是学好Stata的基础,也是做好数据管理工作的基础。对于那些用过Stata的用户,下面要讲的这些概念多数都听说过,甚至都用过,但不见得真正理解了这些概念的全部。数据管理者在常规的数据管理工作中肯定会常常用到下面这些术语,因此强烈建议读者抽出一定的时间来消化吸收它们。
命令:就是让Stata做事情的指示,不同的命令让Stata做不同的数据分析或数据管理工作。例如:命令describe让Stata做描述分析,命令tabulate让Stata做频数分布表。
do-file:do文件就是Stata自带的文本编辑器,有一个独立的窗口,是包含命令语句的文本文件。用户可以把数据分析和数据管理用到的所有命令和注释都写在do文件里,并保存成一个后缀为.do的文件。例如:把讲解do-file的所有命令和注释都保存在文件doexample.do里,如图3-2所示。
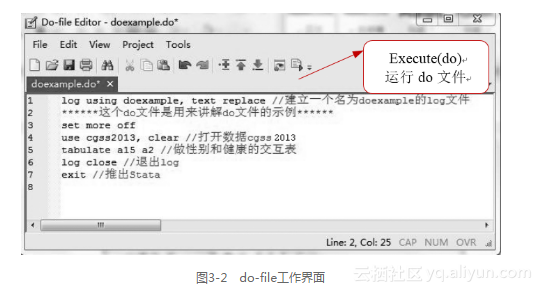
要想运行这个do文件,可以单击上面工具栏中的运行图标(如图3-2所示)——Execute(do),或者单击control+d,运行结果是:
. log using doexample, text replace //[4]建立一个名为doexample的log文件------------------------------------------------------------name: < unnamed> log: C:\Users\leana\Desktop\ssdm\doexample.log log type: text
opened on: 10 Jan 2016, 15:25:38. ******这个do文件是用来讲解do文件的示例******[5]
. set more off. use cgss2013, clear //打开数据cgss2013. tabulate a15 a2 //做性别和健康的交互表您觉得您目 |前的身体健 | 性别康状况是 | 男 女 | Total--------------+-----------------------+----------拒绝回答 | 1 1 | 2很不健康 | 156 178 | 334比较不健康 | 703 831 | 1,534一般 | 1,070 1,155 | 2,225比较健康 | 2,193 2,156 | 4,349很健康 | 1,633 1,361 | 2,994
---------------+-----------------------+----------Total | 5,756 5,682 | 11,438. log close //退出logname: < unnamed>log: C:\Users\leana\Desktop\ssdm\doexample.loglog type: textclosed on: 10 Jan 2016, 15:25:38
------------------------------------------------------------
. exit //退出Stata
end of do-filedo文件就是一个用来记录命令的笔记本。通过交互模式中命令窗口输入的命令,都会暂时被保留在命令回顾(Review)窗口里,但只要关闭Stata,这些命令就会消失,用do文件可以把它们以文件的形式保存下来,不会因为关闭Stata就没有了。
打开do文件有两种途径:第一种途径是直接单击工具栏上的do文件编辑器图标(如图3-3所示);第二种途径是在命令窗口输入命令doedit,打开一个新的do文件,如果已经知道do文件的名字,如cgss13datacleaning,用命令doedit cgss13datacleaning可直接打开这个指定的do文件。
CGSS的管理工作中有99%都在do文件里实现,书中所有的数据管理也都用do文件完成,在数据分析和数据管理中不建议直接在命令窗口输入命令,这样一旦发现前面的某个命令输错了,需要把所有的命令都重新输入一遍。如果用do文件,可以找到错误命令把它改正过来,然后重新运行一次即可。而且,还可通过修改某个项目的数据管理do文件,直接用它来管理其他项目的数据,省时、省力。
Log-file:log文件是Stata的日志文件,它的强大之处在于不仅能把所有用过的命令(Review窗口的内容)都记录下来,而且能把所有命令的输出结果(结果窗口的内容)也都保存下来。
前面的文件doexample.do中就创建了一个名为example的log文件,它把doexample.do里的所有内容和结果窗口输出的所有内容都保存起来,如下所示:
------------------------------------------------------------name: <unnamed>log: C:\Users\leana\Desktop\ssdm\doexample.loglog type: textopened on: 10 Jan 2016, 15:11:59. set more off. use cgss2013, clear //打开数据cgss2013. tabulate a15 a2 //做性别和健康的交互表您觉得您目 |前的身体健 | 性别康状况是 | 男 女 | Total
----------------+----------------------+----------拒绝回答 | 1 1 | 2很不健康 | 156 178 | 334比较不健康 | 703 831 | 1,534一般 | 1,070 1,155 | 2,225比较健康 | 2,193 2,156 | 4,349很健康 | 1,633 1,361 | 2,994
----------------+----------------------+----------Total | 5,756 5,682 | 11,438. log close //退出logname: < unnamed>log: C:\Users\leana\Desktop\ssdm\doexample.loglog type: textclosed on: 10 Jan 2016, 15:11:59
------------------------------------------------------------Log文件的作用很多,如果想把数据分析的结果直接复制到文章里,直接从结果窗口复制容易出现乱码和格式不齐的问题,最简单的方法就是把数据分析的结果保存在log文件里,然后从log文件里复制。如果不小心把写好的do文件在没有保存的情况下关闭了,也可以把log文件复制到do文件里,去掉命令前面的圆点“.”并删掉输出结果,即可还原没有保存的do文件。
变量(variable):在Stata里,变量指的是用来存储数据的工具,从数据结构看,一列就是一个变量,一行就是一条记录,也叫一条观测值。
evarname:这里的e是extended的缩写。代表数据的_dta属于扩展名,可以把这个代表数据的名字当变量来处理,如命令note。
数据(data):类似一个电子表格,每一行就是一条观测值,每一列就是一个变量,变量有变量名,每个单元格里的数字或字符就是变量的取值。
数据集(dataset):由数据、变量标签、取值标签、格式、注释构成。
观测值(observation):在Stata里,每一行数据就是一条观测值,也叫一条记录(record),也可以称作一个样本(sample),还可以叫作一个案例(case)。
语法(syntax):即命令的使用方法和使用规则,和汉语语法、英语语法类似。Stata的人机对话做得很好,很多命令的用法就像把“汉语直接翻译成英语一样”。比如:创建一个名为happy的新变量,让它的取值等于0,如下所示:
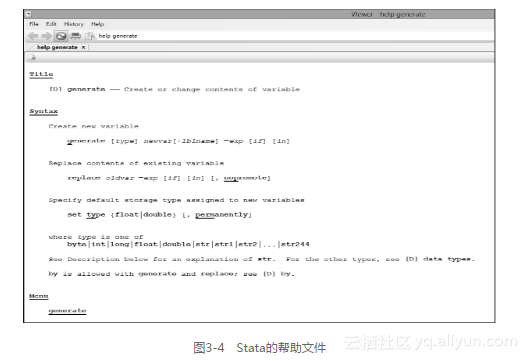
. generate happy = 0在Stata里,每个命令都有自己的用法,并都保存在用户手册里。电子版的用户手册内置在Stata中,被叫作帮助文件。用户可以在命令窗口输入help commandname,打开对应的帮助文件。以命令generate为例,在命令窗口输入:help generate,即可调出命令generate的帮助文件,该文件详细描述了命令generate的用法,如图3-4所示。
变量名(variable name):就是变量。当我们说变量gender时,gender本身就是性别这个变量的变量名。
在Stata里,变量名的长度有限制,最长不能超过32个字符。在Stata14之前的旧版本中,能用于变量名的字符只有数字(0~9)、字母(a~z,A~Z及所有的Unicode字母)和下画线“_”,而且变量名必须以字母或下画线开始。特别提醒:Stata14支持中文变量名。
Stata对大小写字母敏感,区分大小写字母,如变量id和ID,它们是两个不同的变量名。建议用户在给变量命名时尽量用小写字母、数字和下画线,这样后期做管理和分析时,方便输入,否则就需要用户经常在大小写之间切换,而且经常会因为大小写的问题找错变量。
用Stata管理数据一定要注意变量名的选择,除了上述规定外,用户不要用命令名(如describe、type、format)、预留字段/名字(reserved word/name)做变量名,否则很容易出错。
变量标签(variable label):是对变量所测量的内容的解释和描述。比如,“被访者的性别”就是变量gender的变量标签。
取值(value):是变量的取值,指的是调查对象某一特征的所有可能,可以是数字、文本、空格、“.”等。以性别为例,通常该变量的取值有两个:男和女。
取值标签(value label):取值标签是对变量的取值的解释,还是以性别为例,该变量的取值是1和2,其中1的标签是“男”,2的标签是“女”。取值标签还可以理解为对变量取值的定义,如给1的定义是“男”,2的定义是“女”。反之,也可以给2的定义是“男”,1的定义是“女”。
如果一个变量的取值都是文本,则无需取值标签,Stata也无法给字符变量添加取值标签。只有当一个变量的取值是数字且为数值变量时,才有可能需要取值标签,也才能给它添加取值标签。以家庭年收入为例,取值有可能是1000、2000、8500等,虽然是数字型取值,但无需标签数据,使用者也能看懂。如果是一个表示政治面貌的变量的取值是:1、2、3、4,数据使用者就会迷惑,此时提供取值标签:1党员、2民主党派、3共青团员、4群众,用户才能明白这个变量的取值代表什么。
注意:大多数情况下,取值和取值标签实际上都代表变量的取值,对性别这个变量来说,可以说它的取值是男、女(无取值标签),也可以定义它的取值是1、2(取值标签是:1男,2女,也可以是1女,2男),还可以定义它的取值是0、1(取值标签是:0男,1女,还可以是0女,1男)。另一种说法是,给性别的取值男和女进行编码,把男编码为1,把女编码为2。
由于数据管理是一项跨专业、跨学科的工作,同一个概念在不同专业、学科中的叫法有可能不一,初学者不必因此困扰,只需真正理解这个概念,就能消除因称呼不一而导致的迷惑。
下面是变量、变量名、变量标签、取值、取值标签在Stata的浏览窗口中的位置。在Stata里用下面的命令打开数据cgss2013及Stata的浏览窗口(图3-5):
. use cgss2013
. browse变量串(varlist):顾名思义,就是一串变量,即多个变量。在Stata里,有些命令后面只能跟单个变量,有些命令后面可以接多个变量,即可以用变量串。读者在学习命令时,一定要注意这一点,很多时候命令不能运行,就是因为用户在它后面放置多个变量导致的。
数字串(Numlist):是一串数字,中间用空格或逗号隔开,例如:1 3 4 7 10 11就是一个数字串。
系统变量(下画线变量,_variable):Stata里有一些内置的系统变量,这些变量都以下画线"_"开头,所以也被叫作下画线变量,如_n,_N,_all等。
预留名字(reserved word):很多程序中都有一些关键字,也叫作预留字段,这些名字预留给Stata的程序员使用。创建变量名时,要避免使用这些关键字,以免程序不能工作。在Stata中,预留名字有:
_all float _n _skip
_b if _N str#
Byte in _pi strL
_coef int _pred using
_cons long _rc with
Double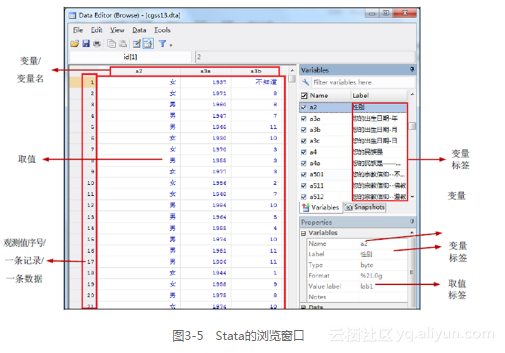
用户在给变量命名时,尽量不要用下画线开头的名字,因为理论上以下画线开头的名字都是Stata预留的内置变量名。
编码(encode):是计算机保存字符、文本的一种方式。绝大多数的统计方法都只是用于定量变量,因此对取值是字符型的变量,要把字符型取值转换成数值型取值,这个过程就是给字符型取值编码。例如,变量宗教信仰的取值有:佛教、道教、伊斯兰教、天主教、基督教和其他宗教,都是字符型取值,可通过编码将其数字化,佛教=1、道教=2、伊斯兰教=3、天主教=4、基督教=5、其他宗教=6。
操作符/运算符(operator):Stata程序中的运算符和数学课上学到的运算符一样(表3-1),遵循正常的数学规则和运算规则。表3-1中列出的18个运算符,运算优先顺序是:!(或~)、^、(负)、/、*、(减)、+、!=(或~=)、>、<、<=、>=、==、&和 | 。如果在一个表达式里既有除法、也有加法,但你想先做加法,再做除法,可以通过加括号“()”实现,如生成一个新变量表示家庭人均年收入,即等于上半年和下半年的家庭收入之和再除以家庭总人数,generate newar=(income1+income2)/famnum。
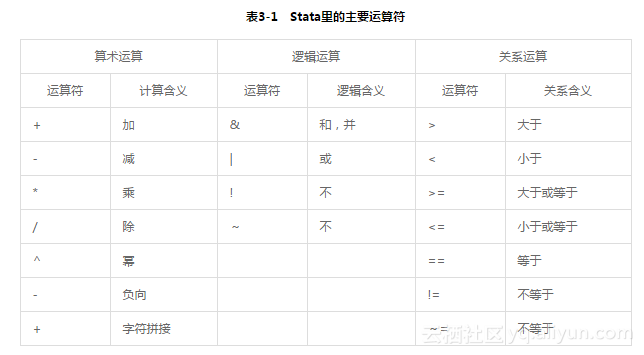
注意,在Stata里,等于用两个等号“==”表示。
操作数/运算对象(operand):即运算符作用的对象,可以是数字、字符、变量。
存储格式(storage type):问卷调查的内容都要以一定的格式保存在Stata里才能成为可用的数据,前面讲过在计算机里,变量就是用来存储数据的工具,因此这里的存储格式,也就是变量的存储格式。和其他程序一样,Stata有两种存储类型的变量:字符型和数值型。
数值型变量有5种存储格式,它们的差别在于存储的最大位数和存储精度,具体规定见表3-2。
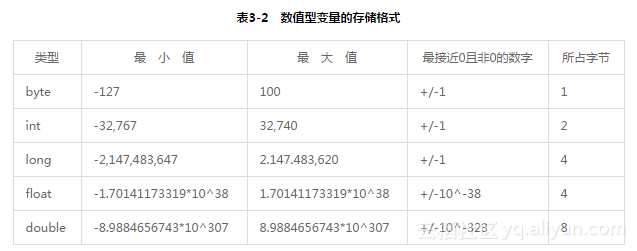
在这5种数值型存储格式中,前3种byte、int和long又被称作整数型存储格式,顾名思义,只能保存整数。若要保存带小数点的数据,则必须用float或double型,否则就会丢失精度。
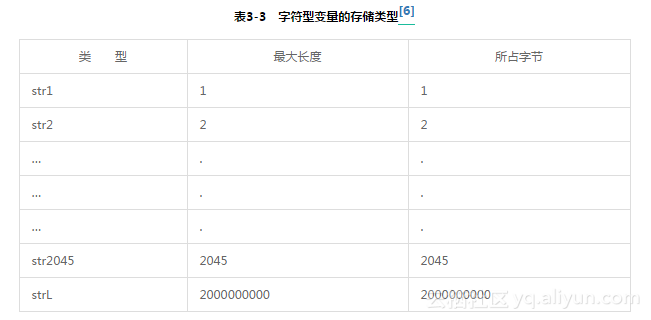
所有的字符都被保存成字符型变量,一共分为两大类:str#和strL,共包含2046种,其差别在于能保存的字符的最大长度。str#是固定长度字符,str1-str2045的最大长度就是str#后面的数字#,str1表示只能保存1个字符,str2045表示最多能保存2045个字符。
strL(string Long)是Stata里的长字符,能容纳20亿个字符。它的一大特性就是能节省空间,当不同观测值在同一个变量上有相同取值时,strL只保存其中一个,把取值相同的观测值在这个变量上的取值都指向内存里的同一个位置,这个过程被叫作合并(coalesce)。它的另一个功能是能够保存二进制字符串,前面的2045种字符型存储格式都无法保存含二进制字符串的变量,只能存储文本字符。简单地讲,二进制字符就是包含二进制数0的字符。如果想了解更多关于数据类型的知识,用户可以在Stata命令窗口输入help data type查看更多内容。字符型变量的存储类型见表3-3。
补充:位(bit) vs. 字节(byte)
位和字节都是计算机的存储单位。其中位,也叫比特,是计算机的最小存储单位,即二进制的0或1。字节是计算机的基本存储单位,一个字节包含8个二进制的字节。通常,一个标准英文字母占1个字节的存储空间,一个标准汉字占2个字节的存储空间。
字符串(string):一串字符就是一个字符序列,在Stata里,所有放在双引号里的都是字符串,比如:"3.148"和3.148,前一个是字符,后一个是数字,前者不能用于数学计算,后者可以。注意:不是所有的字符都必需用双引号括起。
引号不是字符串的一部分,用两个引号注明该字符串的起点和终点。
选项(option):选项是Stata命令的一部分,但不是所有的命令都有选项。以命令list为例,list [varlist] [if] [in] [, options]
选项必须放在逗号的后面,通常情况下,一个命令会有很多选项,用户可以根据自己的需要选择添加一个或多个选项。以cgss03为示例,列出前10条观测值的性别、出生年份,如下所示:
. use cgss03, clear. list sex birth in 1/10, abb(9) noob sep(2)+--------------+
| sex birth |
|--------------|
| 女 1966 |
| 男 1939 |
|--------------|
| 女 1965 |
| 男 1967 |
|--------------|
| 女 1951 |
| 女 1960 |
|--------------|
| 女 1965 |
| 女 1979 |
|--------------|
| 男 1982 |
| 男 1963 |
+--------------+条件(condition):在Stata里,用条件来限制命令的作用对象和作用范围,包括if条件和in条件[7]。绝大多数的Stata命令都允许用if和in条件。用法是:
command if exp
command in range放在命令的后面,逗号的前面(条件区别于选项,只有选项才能且必须放在逗号的后面),后面要加上表达式(expression,如gender==1,income=5000)或范围(如1/10,f/10,-10/1)。以cgss03为例,列出性别和年收入大于等于7万元的观测值,如下所示:
. list sex incyear if incyear>= 70000+----------------+| sex incyear ||----------------|
311. | 男 70000 |
522. | 男 80000 |
714. | 男 100000 |+----------------+如果要列出性别和年收入超过七万元的观测值,用if条件即可:
. list sex incyear if incyear > 70000+----------------+| sex incyear ||----------------|
522. | 男 80000 |
714. | 男 100000 |+----------------+结果显示年收入超过7万元的只有两人,且都是男性,他们的观测值编号为522和714。
缺省(default)设置:指的是Stata程序员在编写Stata程序时就已经规定好的设置,这些缺省设置值普通用户无法修改,但Stata的命令中有些选项可以改变缺省设置。以命令list为例,用数据cgss03.dta来看list的一些缺省设置。
打开cgss03,列出前7条数据的省份(province)、社区类型(commtype)和性别(sex),命令如下:
. use cgss03, clear //用于讲解缺省设置(default). list province commtype sex in 1/7+--------------------------------------------------------------+| province commtype sex ||--------------------------------------------------------------|1. | 内蒙古 集镇社区 女 |2. | 湖北 单一或混合的单位社区 男 |3. | 山东 单一或混合的单位社区 女 |4. | 吉林 未经改造的老城区(街坊型社区) 男 |5. | 贵州 单一或混合的单位社区 女 ||--------------------------------------------------------------|6. | 江西 新近由农村社区转变过来的城市社区 女 |7. | 广东 未经改造的老城区(街坊型社区) 女 |+--------------------------------------------------------------+可以看到:输出结果以5条数据为一组,用横线隔开。这就是一个缺省设置,从下面的list帮助文件截图(图3-6)可知(长方框里的内容default is separator(5)),默认的输出结果都以5条数据为一组,用横线隔开。大多数的软件都有一些缺省值,如常用的办公软件word,打开一个新的word后,默认的字体大小是5号字,可以通过单击工具栏里的字体大小图标重新设置。
如果想让每两条数据为一组,用横线隔开,可以借助list的选项sep(#)[8]来实现:
. list province commtype sex in 1/7, sep(2)+---------------------------------------------------------+| province commtype sex ||---------------------------------------------------------|1. | 内蒙古 集镇社区 女 |2. | 湖北 单一或混合的单位社区 男 ||---------------------------------------------------------|3. | 山东 单一或混合的单位社区 女 |4. | 吉林 未经改造的老城区(街坊型社区) 男 ||---------------------------------------------------------|5. | 贵州 单一或混合的单位社区 女 |6. | 江西 新近由农村社区转变过来的城市社区 女 ||---------------------------------------------------------|7. | 广东 未经改造的老城区(街坊型社区) 女 |+---------------------------------------------------------+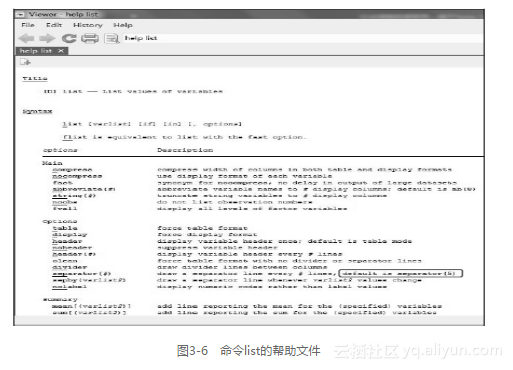
这次的输出结果就是两条数据为一组,关于list的更多内容,请在Stata中输入help list,阅读list的完整帮助文件。
3.4.2 Stata命令中的通则
在汉语中,语法指的是在一句话里每个字/词的排列位置。在Stata里,命令语法的含义和汉语中的基本一致,指的是命令、变量、条件、选项和标点符号的位置排列规则。
1.命令的语法结构
Stata的一个强大之处就在于命令语法的一致性。大多数的Stata命令都遵循下面的语法。
[ prefix: ] command [varlist] [if] [in] [weight] [ ,options] 前缀 + 命令主体 + 变量/变量串 + 条件 + 范围 + 权重 +“,”+ 选项
下面是命令list的语法结构:
list [varlist] [if] [in] [,options]命令主体是:list
命令作用对象(变量、变量串、文件):这里的作用对象是varlist(变量串,即可以同时列出多个变量)
条件:if条件和in条件
逗号后面是选项:options,该命令支持的选项很多,常见的有abbreviation(#) 、noobs、separator(#)、sepby(varlist)。绝大多数的Stata命令都有很多可选择的选项,用户可根据需要自行选择添加。所有命令的选项都可以在Stata的帮助文件中找到。
注意:list的语法结构中没有[weight],表明该命令无法用权重这个选项。
2.命令中的下画线“_”
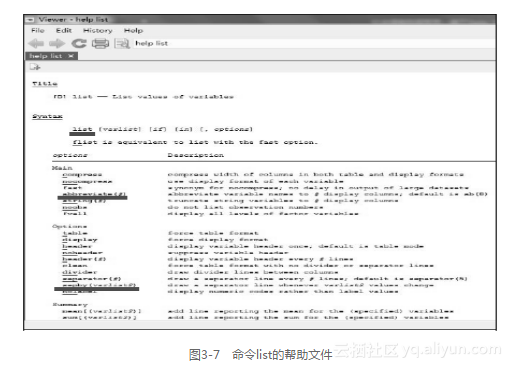
在Stata里,很多命令/选项都可以缩写,但不能无限缩写,那么,每个命令/选项最少可以缩写到几个字母呢?每个命令/选项下的下画线部分就表示该命令可以最少缩写到哪几个字符。如果一个命令/选项的下面没有下画线,就表明该命令不能被缩写。以list命令为例,可以把命令list缩写成一个英文字符“l”,可以把它的选项abbreviation(#)缩写成ab(#),但不能缩写选项sepby(varlist2)。命令list的帮助文件如图3-7所示。
3.命令中的[ ]
在Stata的命令中,用中括号“[ ]”括起来的都是可选项。
补充:Stata用中括号表示下标var[ _n–1 ]、var[_n+1]、var[_n]、var[3]。
4.命令中的字体
和中括号相对应的是字体倾斜与否。斜体表示可选可不选,非斜体代表必选。也就是说,用户如果要用这条命令,所有非斜体的命令必须都要用上,否则该命令将无法运行。
5.帮助文件中的蓝色字体
在Stata的帮助文件中,有些单词或词组显示为蓝色,什么意思呢?蓝色的字体表示链接,单击蓝色字体会打开相对应的链接,这也是Stata帮助文件的强大之处。
6.命令中的空格
Stata一般情况下,每个单词或符号的后面都加1个空格,两个单词之间一定要加1个空格,否则Stata会把这两个单词看成是一个单词,导致无法识别。
3.4.3 Stata的帮助文件
Stata自带帮助文件,用命令help即可调用相关的帮助文件。注意,这是一个在线帮助文件,因此使用时用户要确保自己的电脑处于在线状态。Stata的帮助手册编写得非常完备且详尽,无论是新用户,还是高级用户,都能从中找到自己需要的信息和技术。
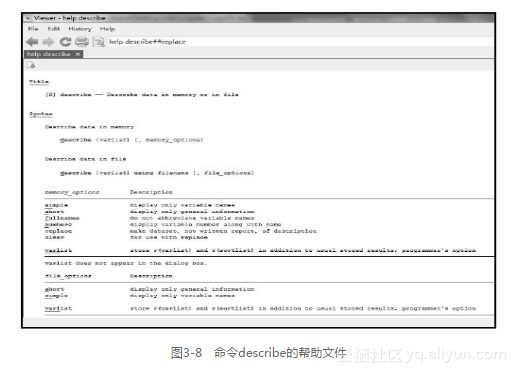
要调用Stata的帮助文件,方法很简单,直接在命令窗口输入命令help keywords,这里的关键词指的是用户想让Stata实现的功能,如描述数据,输入help describe,即可调出和描述数据有关的帮助文件,如图3-8所示。
对用户来说,Stata的帮助文件是极好的自学帮助参考手册。实际上,用Stata做数据管理时遇到的绝大多数问题,Stata都提供了解决方案。很多用户无法解决的问题,都是因为用户不知道Stata里有相应的技术和知识,或者找不到。因此,用户使用Stata做数据管理时,一定要养成勤用、善用Stata帮助文件的习惯。
3.4.4 Stata 14的特点
和以前的版本相比,Stata 14.1最大的变化莫过于编码(详见第4章)。
3.4.5 Stata的其他帮助资源
除了Stata的帮助文件外,随着Stata应用的普及性不断提高,用户越来越多,市面上的著作也很多,但良莠不齐。Stata公司有自己的出版社(Stata Press),网址是:http://www. stata-press.com/,该出版社出版的相关书籍都不错。
用户编写的程序(user-written programs),又称附加程序(add-on programs)。Stata的一大优势是:除了Stata自带的功能和命令外,所有的用户都可以开发、编写、发布自己编写的Stata程序。比如:本书在附录“国家行政区划代码及转码小程序”详细讲解了作者本人写的一个关于中国地区代码转换的小程序。这些程序需要用户自行下载安装。具体操作方法是:首先,用命令findit keyword搜索,这个搜索引擎会搜出所有和keyword有关的相关资料,从中找到安装包,单击“install”,Stata会自动安装这个程序,安装完成后给出安装成功提示,即可在电脑上使用这个程序了。
Stata的官网www.stata.com/support/提供了很多学习资源和学习途径,包括上面提到的书籍、Stata的在线课程、Statalist、Stata Journal以及其他包含Stata信息的网站。其中,Statalist(www.statalist.org)是独立运作的一个服务器,托管在哈佛大学的公共卫生学院。它给全世界的Stata用户提供了一个公开交流的网络平台,该平台非常活跃,在这个网络社区中充满着丰富且详尽的Stata知识和以往用户提到的各种问题,无论是初学者,还是专家,都可以通过浏览问题列表、阅读以往资料,来学习自己感兴趣的知识和技术。
Stata Journal(http://www.stata-journal.com/)刊登的都是用Stata做分析的文章,一年四刊,每季一刊,现刊需要付费订阅,但用户可以从网站上免费下载3年前的文章。
Stata里有些命令看起来很复杂,但理解起来很容易,毕竟编写Stata软件的工程师也是人类吗,写代码时也都是基于常识和人类的思维逻辑,学习时切忌死记硬背,理解了每个命令背后隐藏的道理和逻辑,自然就能记住这个命令。
《社会调查数据管理——基于Stata 14管理CGSS数据》一3.4 Stata的一些术语及使用通则...相关推荐
- 《社会调查数据管理——基于Stata 14管理CGSS数据》一第2章 数据管理的流程及内容2.1 数据管理的工作流程...
本节书摘来自异步社区<社会调查数据管理--基于Stata 14管理CGSS数据>一书中的第2章,第2.1节,作者 唐丽娜,更多章节内容可以访问云栖社区"异步社区"公众号 ...
- 《社会调查数据管理——基于Stata 14管理CGSS数据》一2.2 数据管理的工作标准...
本节书摘来自异步社区<社会调查数据管理--基于Stata 14管理CGSS数据>一书中的第2章,第2.2节,作者 唐丽娜,更多章节内容可以访问云栖社区"异步社区"公众号 ...
- 《社会调查数据管理——基于Stata 14管理CGSS数据》一3.2 和统计有关的术语
本节书摘来自异步社区<社会调查数据管理--基于Stata 14管理CGSS数据>一书中的第3章,第3.2节,作者 唐丽娜,更多章节内容可以访问云栖社区"异步社区"公众号 ...
- 《社会调查数据管理——基于Stata 14管理CGSS数据》一1.2 数据管理内容不清
本节书摘来自异步社区<社会调查数据管理--基于Stata 14管理CGSS数据>一书中的第1章,第1.2节,作者 唐丽娜,更多章节内容可以访问云栖社区"异步社区"公众号 ...
- 《社会调查数据管理——基于Stata 14管理CGSS数据》一2.3 数据管理的工作规范...
本节书摘来自异步社区<社会调查数据管理--基于Stata 14管理CGSS数据>一书中的第2章,第2.3节,作者 唐丽娜,更多章节内容可以访问云栖社区"异步社区"公众号 ...
- 《社会调查数据管理——基于Stata 14管理CGSS数据》一第3章 概念与术语3.1 和计算机及软件有关的术语...
本节书摘来自异步社区<社会调查数据管理--基于Stata 14管理CGSS数据>一书中的第3章,第3.1节,作者 唐丽娜,更多章节内容可以访问云栖社区"异步社区"公众号 ...
- 《社会调查数据管理——基于Stata 14管理CGSS数据》一3.3 和社会调查有关的术语...
本节书摘来自异步社区<社会调查数据管理--基于Stata 14管理CGSS数据>一书中的第3章,第3.3节,作者 唐丽娜,更多章节内容可以访问云栖社区"异步社区"公众号 ...
- 《社会调查数据管理——基于Stata 14管理CGSS数据》一1.4 数据伦理
本节书摘来自异步社区<社会调查数据管理--基于Stata 14管理CGSS数据>一书中的第1章,第1.4节,作者 唐丽娜,更多章节内容可以访问云栖社区"异步社区"公众号 ...
- 《社会调查数据管理——基于Stata 14管理CGSS数据》一1.5 本书简介和使用说明...
本节书摘来自异步社区<社会调查数据管理--基于Stata 14管理CGSS数据>一书中的第1章,第1.5节,作者 唐丽娜,更多章节内容可以访问云栖社区"异步社区"公众号 ...
- 【精益生产】数字化转型探索之路——基于精益生产管理的数据决策分析体系
随着"工业4.0"."两化"融合.<中国制造2025>等理念或政策的提出,粗放式的制造生产模式的弊端被越来越多的暴露出来,中国制造昔日冠以" ...
最新文章
- 服务器用户没有读取权限,Windows找不到文件或没有读取权限怎么办
- ubuntu 如何关闭离线模式_如何在macOS中打开或关闭Mac暗黑模式
- windows 10占用cpu和内存过高
- 各种 分页存储过程整理
- Jenkins部署Python项目实战
- GPU Gems1 - 14 透视阴影贴图(Perspective Shadow Maps: Care and Feeding)
- Sql 行转列问题总结
- 【转载】分布式之redis复习精讲
- ad17编辑界面怎么检查未连线_软件账务处理流程之——凭证审核与检查
- STM32学习之TFTLCD
- mysql 多个表union查询_mysql查询两个表,UNION和where子句
- android ListView 九大重要属性详细分析
- JavaScript 是如何工作的:WebRTC和对等网络的机制!
- 安装Ubuntu后必须要做的几件事(一)--基础应用篇
- 《麻省理工学院公开课:人工智能》笔记三
- 【原生JavaWeb】网页前端页面如何调用后端Java程序
- Linux 升级glibc-2.18
- Java Scaner类详解_动力节点Java学院整理
- 【校招VIP】产品经理之明确活动目的
- 国产化信创CPU、操作系统、数据库、中间件笔记