阅读笔记-阿里妈妈AI智能文案
文章目录
- 之前解决文本多样性的方法
- 1. 修改loss
- 1.1 MMI-antiLM
- 1.2 MMI-bidi
- 2. 使用VAE模型
- AE vs. VAE
- 无监督句子编码
- VAE
- 相关基础工作
- 2.1 编解码模型
- 2.2 VAE和CVAE
- 2.3 SelfLabeling CVAE
- 3 数据集
- 4 实验
- 4.1 开放领域的对话生成
- 4.2 推荐理由生成
阿里妈妈AI智能文案
之前解决文本多样性的方法
1. 修改loss
主要代表是李继伟2016a的相关研究,提出了新的目标函数MMI对 Seq2Seq进行建模。
原始的目标函数采用log-likelihood建模,
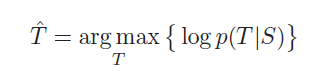
这个loss的问题是,如果一个回复在在训练集中出现得越多(越平常),在测试生成的时候生成这些回复的概率就会越高。所以基于**熵**对loss进行改进,使用互信息来衡量生成句子的优劣。
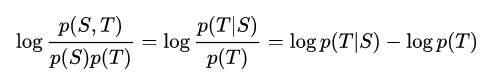
互信息对比与likelihood的区别在于,多了一项 logp(T)log p(T)logp(T) 的惩罚项, 这样对于在训练集中经常出现的回复T, 其语言模型 p(T)越大,最终得分越小。
最终目标函数可以写作:
T^=argmaxT{logp(T∣S)−logp(T)}\hat{T}=\underset{T}{\arg \max }\{\log p(T | S)-\log p(T)\} T^=Targmax{logp(T∣S)−logp(T)}
1.1 MMI-antiLM
将上述惩罚项乘以一个控制因子 λ\lambdaλ ,得到 anti-language model(antiLM),
T^=argmaxT{logp(T∣S)−λlogp(T)}\hat{T}=\underset{T}{\arg \max }\{\log p(T | S)-\lambda \log p(T)\} T^=Targmax{logp(T∣S)−λlogp(T)}
虽然他会降低常用回复的出现,但是这些常用回复是通顺的,所以这样降低之后,会导致一些不符合句法的句子被生成。因此,使用截断式语言模型U(T)U(T)U(T)来代替完整的语言模型p(T)p(T)p(T),
其中,
g(k)={1if k≤r0if k>rg(k)=\left\{\begin{array}{ll}{1} & {\text { if } k \leq r} \\ {0} & {\text { if } k>r}\end{array}\right. g(k)={10 if k≤r if k>r
可以看出,前者比后者多出来一个 g(k)g(k)g(k),这个参数就是减低重复回复的。回顾解码过程,生成一个词时,需要当前词和上一个生成的词,所以位于句子前面的词会涉及到后面所有词的解码,这样就会影响句子的多样性。所以当前词离得太远的词,就丢弃掉。此外,通过实验发现,解码过程越长,语言模型的影响力越大,句子出现不通顺的概率越大,所以通过限制距离,可以减少这种情况的发生。
1.2 MMI-bidi
考虑到贝叶斯公式,可以将MMI目标函数改成
logp(T)=logp(T∣S)+logp(S)−logp(S∣T)\log p(T)=\log p(T | S)+\log p(S)-\log p(S | T) logp(T)=logp(T∣S)+logp(S)−logp(S∣T)
这样
T^=argmaxT{logp(T∣S)−λlogp(T)}\hat{T}=\underset{T}{\arg \max }\{\log p(T | S)-\lambda \log p(T)\} T^=Targmax{logp(T∣S)−λlogp(T)}
就可以改写成
T^=argmaxT{(1−λ)logp(T∣S)+λlogp(S∣T)−λlogp(S)}=argmaxT{(1−λ)logp(T∣S)+λlogp(S∣T)}\begin{aligned} \hat{T}=\underset{T}{\arg \max }\{(1-\lambda) \log p(T | S)& \\+\lambda \log p(S | T)-\lambda \log p(S) \} \\=\underset{T}{\arg \max }\{(1-\lambda) \log p(T | S)+\lambda \log p(S | T)\} \end{aligned} T^=Targmax{(1−λ)logp(T∣S)+λlogp(S∣T)−λlogp(S)}=Targmax{(1−λ)logp(T∣S)+λlogp(S∣T)}
引入权重之后,目标函数既可以看做是p(S∣T)p(S|T)p(S∣T)和p(T∣S)p(T|S)p(T∣S)之间的tradeoff了.
改写之后的函数就是MMI-Direct decodeing(MMI-bidi)
实际实验中,使用目标函数的第一项(1−λ)logp(T∣S)(1-\lambda) \log p(T | S)(1−λ)logp(T∣S)来生成N个回答,然后使用第二项即λlogp(S∣T)\lambda \log p(S | T)λlogp(S∣T)对N个回答重新排序。
这种方法的优点是得到的答案都是语法通顺的,因为是标准的seq2seq模型的答案,但是在排名上只是局部最优的。
不足
这些方法没有优化 encoder-decoder,不适合解决多目标数据,因为受限于准确性和多样性的tradeoff
2. 使用VAE模型
VAE方法引入了一个中间隐变量,并假设每一个隐变量的配置都对应于一个可行的响应。所以可以通过从变量中采样来得到不同的隐变量响应。但是VAE和CVAE都会遇到 KL-消逝的问题,即decoder在生成文本时,根本没有用到隐变量。
AE vs. VAE
对于AE,AE中学习的是 encoderencoderencoder 和 decoderdecoderdecoder ,只能从一个 XXX,得到对应的重构 XXX 。但是无法生成新的样本。而 VAE可以让重构后的XXX尽量符合某个指定的分布,只需要从这个分布中采样出来就可以恢复输入(比如一张图片)
无监督句子编码
标准的rnn的解码过程是利用当前词和上一个解码结果来生成下一个词的。这种方法虽然有效但是没有学到一个完整句子的词向量表示,都是一个词一个词学的。为了能学到这个全句子的隐向量,首先要找到句子和词向量的映射关系。有三种方法,句子AE,其中编码器和解码器都是rnn,但是这个模型在提取全局语义方面表现不好。剩下两种方法skip-thought和paragraph vector可以很好的对句子进行编码,但是不能用于generating settings,因为前者是一种无监督学习模型,输出是下一个句子而不是本身;后者是没有rnn的,
标准的AE的包栝编码 φenc\varphi_{enc}φenc、解码p(x∣z⃗=φenc)p(x|\vec{z}=\varphi_{enc})p(x∣z=φenc),给定 z⃗\vec{z}z最大化得到xxx的概率、得到xxx的编码。
VAE
是对标准
AE做了标准化处理,在ae的架构上引入了随机隐变量。VAE 从 data 学到的是在 latent space 的 region,而不是单个点。换句话说是 encode 学到了一个概率分布 q(z⃗∣x)q(\vec{z}|x)q(z∣x), 其中z⃗\vec{z}z是一个对角gaosigao’si’fen’bu补。
引入 KL divergence 让后验 q(z|x)接近先验 p(z)。这里的 motivation 在于如果仅用 reconstruction loss,q(z|x)的 variances 还是会很小(又和原有的单个点差不多了)
不管是VAE还是CVAE都会遇到KL消逝的问题。这是由于这类方法目标函数本身造成的。很有方法试图基于此改进,但无非是减弱解码器,或者增强编码器,由此对目标函数进行修改。
相关基础工作
2.1 编解码模型
源于机器翻译的Seq2Seq 模型,给定一个句子输出一个句子。不适合一对多,而且没有多样性。虽然有MMI作为损失函数的改进,把那些常出现的回答过滤了,但是不能解决多目标数据的问题,因为每次只考虑一个target。而在机器翻译中常用的BS方法,更容易将前缀相同的句子返回,所以生成结果看起来还是非常相似的,不能解决多样性。
2.2 VAE和CVAE
在生成时引入了隐变量,目标函数是 ELBO
logp(x)≥Eq(z∣x)[logp(x∣z)]−KL(q(z∣x)∥p(z))\log p(x) \geq \mathbb{E}_{q(z | x)}[\log p(x | z)]-K L(q(z | x) \| p(z)) logp(x)≥Eq(z∣x)[logp(x∣z)]−KL(q(z∣x)∥p(z))
其中,q(z∣x)q(z|x)q(z∣x) 和 p(z∣x)p(z|x)p(z∣x)的都有参数的。可以看到输入 xxx在编码时引入了概率分布,而不是固定的,不同的概率分布就可以有不同的结果生成。
如果考虑到上下文,那么模型就是基于某种条件的,成为 CVAE,其目标函数也是 ELBO
logp(x∣c)≥Eq(z∣x,c)[logp(x∣z,c)]−KL(q(z∣x,c)∥p(z∣c))\begin{array}{c}{\log p(x | c)} \\ { \geq \mathbb{E}_{q(z | x, c)}[\log p(x | z, c)]-K L(q(z | x, c) \| p(z | c))}\end{array} logp(x∣c)≥Eq(z∣x,c)[logp(x∣z,c)]−KL(q(z∣x,c)∥p(z∣c))
KL消失问题
ELBO会带来kl消失问题,也称为posterior collapse problem。就是说,从输入拿到的用于后验生成的信息异常,可能是噪声太多,也可能是信息太少,使得decoder没有使用从qϕ(z∣x)q_{\phi}(z|x)qϕ(z∣x)得到的隐变量zzz.
信息太少了是指qϕ(z∣x)≃qϕ(z)=N(a,b)q_{\phi}(z | x) \simeq q_{\phi}(z)=\mathcal{N}(a, b)qϕ(z∣x)≃qϕ(z)=N(a,b),参数μ\muμ和σ\sigmaσ和输入xxx都没什么关系了,μ\muμ和σ\sigmaσ坍塌(collaspe)回一个常数,没有办法区分不同的输入。
噪声太强了是指μ\muμ和σ\sigmaσ都不稳定,这样产生的zzz也是不稳定的,decoder没法用,只能从现有的结果中选一个输出。
那z的产生和x无关之后又怎么样呢?会有 q(z∣x)=p(z)q(z | x)=p(z)q(z∣x)=p(z),这样一来ELBO的第二项就等于0了;又根据琴生不等式,Ep(z)[logp(x∣z)]≤log∑z[p(x∣z)p(z)]=logp(x)E_{p(z)}[\log p(x | z)] \leq\log \sum_{z}[p(x | z) p(z)]=\log p(x)Ep(z)[logp(x∣z)]≤log∑z[p(x∣z)p(z)]=logp(x)(当且仅当x和z无关时,等号成立。)
那么当x和z无关时,ELBO目标函数回退到原始的log(p)log(p)log(p),VAE模型也会退到最简单的模型了。
2.3 SelfLabeling CVAE
想要利用不同的z生成不同的x,首先需要每一个z通过解码都可以得到一个不同的x,其次,z需要满足先验分布p(z)p(z)p(z)。
再看一下ELBO的目标,是想最大化log概率,就是想让第一项尽可能大,第二项尽可能小。第二项小说明z和x 的分布越来越像,这就会造成kl消逝的问题。
3 数据集
电商语料库,商家和用户评论及推荐。商家描述文本是属性词的堆砌,作为source,来生成像人写的推荐理由。有三百多万的source,平均每一条source有3.8个target。
4 实验
4.1 开放领域的对话生成
使用的是开源数据集 DailyDialog
4.2 推荐理由生成
使用的是自己构建的EGOODS数据集,模型是PyTorch,编码向量长度是128.
阅读笔记-阿里妈妈AI智能文案相关推荐
- 公式推导出创意,阿里妈妈“AI智能文案”通过图灵测试!
"经典小黑裙,穿出赫本式性感" "电动脱毛仪,上演极度的诱惑" "一伞在手,遮阳挡雨全都有" ······ 这些都是人工智能写出来的文案,对 ...
- 阿里妈妈Dolphin智能计算引擎基于Flink+Hologres实践
作者:徐闻春(花名 陌奈) 阿里妈妈事业部技术专家 本文整理至Flink+Hologres实时数仓Workshop北京站,点击查看视频回放>>> 阿里妈妈数据引擎团队负责广告营销计算 ...
- KDD2021 放榜,6 篇论文带你了解阿里妈妈AI技术
关于 KDD ACM SIGKDD(国际数据挖掘与知识发现大会,简称 KDD)是国际数据挖掘领域的顶级会议,由 ACM 的数据挖掘及知识发现专委会(SIGKDD)主办,被中国计算机协会推荐为A类会议. ...
- 阿里妈妈内容风控模型预估引擎的探索和建设
作者:徐雄飞.金禄旸.滑庆波.李治 内容作为营销的重要载体,能够促进信息的交流和传播.在营销场景中,广告高曝光的特性放大了风险外漏带来的一系列问题,因此对内容的风控审核就显得至关重要.本文将为大家分享 ...
- 请查收 | 2021 阿里妈妈技术文章回顾
2021年5月13日,「阿里妈妈技术」正式与大家见面了~ 在过去的237天里,我们分享了50篇原创内容,覆盖了广告算法实践.算法工程&引擎&系统建设.智能创意.风控.数据科学等多个技术 ...
- 阿里妈妈技术团队 5 篇论文入选 TheWebConf 2022
近日,第31届国际万维网大会(The Web Conference / WWW)审稿结果出炉, 阿里妈妈技术团队有5篇论文入选. TheWebConf 成立于1989年,原名为"The In ...
- 电商智能写作:阿里妈妈创意中心智能文案引擎
本篇为电商智能写作第一篇,笔者跟踪电商智能写作领域有些日子了,目前已知有成型电商智能写作产品的有: 阿里的阿里妈妈(还有其他的几篇该领域的论文,不知道有木有做成产品使用起来),京东AI闪电,宝尊电商等 ...
- AI智能写作用boardmix,文案、论文、爆款、小说一键生成!
随着Chat GPT的出圈,人工智能逐渐渗透各行各业,尤其是文案和论文的产出,AI能够帮助我们更加高效的创作,为内容提供一些灵感和思路.那么,有没有类似Chat GPT的AI写作工具,有观念.有角度. ...
- AI:周志华老师文章《关于强人工智能》的阅读笔记以及感悟
AI:周志华老师文章<关于强人工智能>的阅读笔记以及感悟 导读 关于人工智能,长期存在两种不同的目标或者理念.一种是希望借鉴人类的智能行为,研制出更好的工具以减轻人类智力劳动 ...
最新文章
- swift 基础学习之属性修饰符
- 使用python处理实验数据-yechen_pro_20171231
- 视频 + PPT 下载 | 《财富管理数字化转型现状与趋势洞察报告》解读第一讲
- 眺望全真互联时代!TVP音视频技术闭门会闪耀上海
- 导航跳转后保持选中状态 jquery高亮当前选中菜单
- 2008-10-13 XEIM 2.0 beta 准时发布
- 【AI视野·今日Robot 机器人论文速览 第十二期】Tue, 22 Jun 2021
- Git是目前世界上最先进的分布式版本控制系统(没有之一)。
- Digilent提供的PmodOLEDrgb驱动程序
- Windows移动开发(三)——闭关修炼
- MariaDB 10.3 解决掉了UPDATE不支持同一张表的子查询更新
- php 签名 bom,PHP与Unicode签名(BOM)
- linux 改变用户组、文件拥有者、文件属性
- 不均衡分类问题 之 class weight sample weight
- 学生个人信息管理系统(mysql)
- 线代笔记:行列式的性质及定理
- 一名合格的数据分析师,需要满足哪些条件
- 小型数控钻铣床C31
- zynq+linux+ramdisk can调试
- hive正则表达式regexp_extract
热门文章
- 2022P气瓶充装考试试题及在线模拟考试
- RabbitMQ安装rabbitmq_delayed_message_exchange插件(死信队列所需插件)
- Js获取图片主色调,近似色,互补色,以及根据图片颜色获取主题配色方案详解、插件。
- 魂断“中国百慕大”?GIS斩祸根!
- [附源码]SSM计算机毕业设计校园新闻管理系统JAVA
- w10电脑c盘满了怎么清理_win10系统如何清理c盘空间容量
- 2021年中国水果罐头行业进出口贸易及发展前景分析[图]
- 微信小程序开发-仿今日头条(二)
- R语言广义线性模型函数GLM、glm函数构建泊松回归模型(Poisson regression)、泊松回归模型系数解读、查看系数的乘法效应(Interpreting the model para)
- linux双系统没有引导,Ubuntu双系统没有可引导设备如何解决