算法 从 数中选出_算法可以选出胜出的nba幻想选秀吗
算法 从 数中选出
Note from Towards Data Science’s editors: While we allow independent authors to publish articles in accordance with our rules and guidelines, we do not endorse each author’s contribution. You should not rely on an author’s works without seeking professional advice. See our Reader Terms for details.
Towards Data Science编辑的注意事项: 尽管我们允许独立作者按照我们的 规则和指南 发表文章 ,但我们不认可每位作者的贡献。 您不应在未征求专业意见的情况下依赖作者的作品。 有关 详细信息, 请参见我们的 阅读器条款 。
I enjoy basketball. It’s a fast-paced competitive game and I’ve enjoyed both playing and watching it for a long time. The NBA is famous for generating very clean data, which has long been used by enthusiasts (like myself) for data visualizations, modeling and game predictions.
我喜欢篮球。 这是一款快节奏的竞技游戏,很长时间以来我都喜欢玩和观看它。 NBA以生成非常干净的数据而闻名,长期以来,发烧友(如我自己)一直将其用于数据可视化 , 建模和游戏预测 。
Recently, I was contacted by DraftKings regarding an interview for a potential job. As part of my preparations for the same, I started using their platform and competing in mock competitions to get acquainted with the DraftKings (DK) contest process. It was during this time period that I really started getting into the idea of using data to model and predict a winning roster.
最近, DraftKings就某项潜在工作的面试与我联系。 作为准备工作的一部分,我开始使用他们的平台并参加模拟竞赛,以了解DraftKings(DK)竞赛过程。 正是在这段时间里,我才真正开始使用数据建模和预测获胜者名单的想法。
I built the algorithm iteratively, and from scratch- starting with a naive version 1, a more robust version 2 and currently I’m working on a winning version 3.
我迭代地构建了算法,从零开始,从朴素的版本1开始,是功能更强大的版本2,目前我正在开发获奖的版本3。
I built the algorithm iteratively, and from scratch
我从头开始迭代构建算法
You can follow along my algorithm design journey in the rest of the article.
您可以在本文的其余部分中继续我的算法设计过程。
快速级别设置:评分和规则 (Quick Level Set: Scoring and Rules)
DK’s rules and scoring for their NBA classic fantasy contests are fairly intuitive, even if you have no prior basketball knowledge. In a nutshell, the objective is to:
即使您没有篮球知识,DK的NBA经典幻想比赛规则和得分也非常直观。 简而言之,目标是:
Create an 8-player lineup while staying under the $50,000 salary cap.
创建一个8人游戏阵容,同时将工资保持在50,000美元以下。
Players get different points for different actions (more details below) and the draft with the most number of points, at the end of all games in a night, wins. Sounds simple enough :)
玩家在不同的操作中获得不同的分数(更多详细信息,请参见下文),并且在一夜内所有游戏结束时,得分最高的选秀会获胜。 听起来很简单:)
The breakdown for different actions that result in positive (or negative) points can be seen below.
导致正(或负)分的不同动作的细分如下所示。

One last constraint which makes drafting slightly more complicated is player positions. According to DK: Lineups will consist of 8 players and must include players from at least 2 different NBA games.
最后一个使选秀稍微复杂一些的约束是球员位置。 根据DK: 阵容将由8名球员组成,并且必须包括至少2场不同NBA游戏中的球员。
Further, the 8 players are broken down by positions, which can be seen below.
此外,这8个玩家按位置细分,如下所示。

There you have it! A simple optimization problem with a set of constraints. Sounds like something an algorithms would excel at. Or would it?
你有它! 具有一组约束的简单优化问题。 听起来像算法会擅长的事情。 还是会?
算法版本1-天真 (Algorithm Version 1- Naive)
My goal with this algorithm was to build it as fast as possible, with little to no hopes of winning. Mainly because I was interested in setting up a strong foundation, without worrying about building complex logic early in the process. To do this, I downloaded a player dataset from DK and started a Jupyter notebook. If you’re interested, you can find the full raw data here and my notebook here.
我使用此算法的目标是尽可能快地构建它,几乎没有希望获胜。 主要是因为我有兴趣建立一个强大的基础,而不必担心在此过程的早期就构建复杂的逻辑。 为此,我从DK下载了播放器数据集并启动了Jupyter笔记本。 如果你有兴趣,你可以找到完整的原始数据, 在这里 ,我的笔记本电脑在这里 。
Let’s see what our data looks like.
让我们看看我们的数据是什么样的。

Right off the bat, we can tell that for a simple algorithm, given our requirements and constraints, we’ll find the following columns useful: ID, Salary and AvgPointsPerGame (fantasy points). This would allow us to pick the “best” players while staying under the $50,000 salary cap. Sure, without positional information we could have overlaps etc. but that’s an issue for a later version. Remember, version 1 should be the simplest implementation of your product.
马上,我们可以说出,对于一个简单的算法,鉴于我们的要求和约束,我们将发现以下几栏有用:ID,Salary和AvgPointsPerGame(幻想点)。 这将使我们能够选择“最佳”球员,同时保持在50,000美元的薪金上限以下。 当然,如果没有位置信息,我们可能会有重叠等,但这对于更高版本是一个问题。 请记住,版本1应该是产品的最简单实现。
Given this data, our first pass optimization algorithm can be broken up into the following simple steps:
有了这些数据,我们的首过优化算法可以分解为以下简单步骤:
- Randomly select 8 players from the dataset.从数据集中随机选择8个玩家。
- If the sum of the salaries of the players is greater than $50,000: go back to step 1 (too expensive).如果玩家的薪金总和超过50,000美元:请返回步骤1(太贵)。
- Otherwise, sum the AvgPointsPerGame of each of the players in the roster and compare with a master maximum value. If greater, replace maximum value and roster.否则,对名册中每个玩家的AvgPointsPerGame求和,然后与主最大值进行比较。 如果更大,则替换最大值和花名册。
- Unless all possible combinations have been explored, return to step 1. Once no more combinations, return the maximum value and the roster.除非已探究所有可能的组合,否则请返回步骤1。不再组合时,请返回最大值和花名册。
There we have it: a simple naive algorithm that picks 8 players in random that will have the maximum expected fantasy points while staying under the $50,000 salary cap. But this algorithm has a few glaring issues:
我们有一个简单的天真的算法,该算法随机选择8个玩家,这些玩家将具有最大的预期幻想积分,同时保持在50,000美元的薪金上限以下。 但是此算法存在一些明显的问题:
- No control regarding the position of the players. Hence the algorithm could generate a roster which consists of >3 of one position (G/F), in which case the roster would be invalid.无法控制玩家的位置。 因此,该算法可以生成由一个位置(G / F)> 3组成的花名册,在这种情况下,该花名册将无效。
- No check on players who are injured or not scheduled to play. This would result in a most definitive loss as all player points are important for a winning draft.不检查受伤或未安排比赛的球员。 这将导致最确定的损失,因为所有球员得分对获胜选秀都很重要。
- Lastly, the algorithm is very inefficient. Considering that we need to check each possible roster: for a given number of players n and roster size r, the number of possible rosters would be-最后,该算法效率很低。 考虑到我们需要检查每个可能的名册:对于给定数量的n个玩家和名册大小r,可能的名册数量为-
C( n , r ) = n! / (n — r)! . r!
C(n,r)= n! /(n-r)! 。 !
To get an appreciation of this complexity, take a look at the table below which shows the number of checks if the total number of available players is 100.
要了解这种复杂性,请查看下表,该表显示了可用球员总数为100时的检查次数。
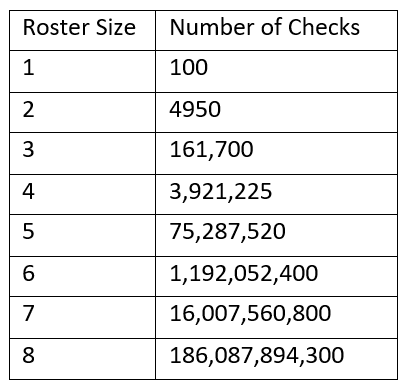
It’s safe to assume that our algorithm will take a VERY long time to output a roster of 8 players. But, because this is a first pass algorithm, we‘re happy with what we got. You can see the algorithm in action below, picking the top 5 players for a combined salary of $35,000. Not bad.
可以肯定地说,我们的算法将花费很长时间才能输出8名球员的花名册。 但是,由于这是首过算法,因此我们对所获得的结果感到满意。 您可以在下面看到该算法的运行情况,以最高薪水35,000美元选出前5名球员。 不错。

Because we’re on a mission to build a winning algorithm, let’s talk about version 2 optimizations.
因为我们肩负着构建成功算法的使命,所以让我们谈谈版本2优化。
算法版本2-中级体育博彩者 (Algorithm Version 2- Intermediate Sports Bettor)
Now, this is where our algorithm goes from being a naive optimizer to an intermediate-level sports bettor. Based on the drawbacks of version 1, and the factorial time complexity, I decided to implement a few data and algorithm level optimizations.
现在,这是我们的算法从单纯的优化器发展为中级体育博彩者的地方。 基于版本1的缺点和阶乘时间复杂度,我决定实施一些数据和算法级别的优化 。
First, I cleaned the data to only include players who’re confirmed to play games. This was an easy way to decrease the total number of available players from ~100 to ~85. This might look like a small increase, but in reality, for a roster of 8 players, our number of checks drastically decreases when the total number of players decreases. The change in the number of checks can be seen below.
首先,我清除了数据,只包括经确认可以玩游戏的玩家。 这是将可用玩家总数从100个减少至85个的简便方法。 这看似有点增加,但实际上,对于名额8人的名单,当总人数减少时,我们的支票数会急剧减少。 支票数量的变化可以在下面看到。
- C (100, 8) = 186,087,894,300C(100,8)= 186,087,894,300
- C (85, 8) = 48,124,511,370C(85,8)= 48,124,511,370
Our total number of operations (or checks) in the algorithm went down by ~75%!
我们在算法中的操作(或检查)总数下降了约75%!
Next up, I modified the algorithm itself to pick specific positions. Now, instead of picking every possible roster from the total number of players available, the algorithm picks 3 guards from only all available guards, followed by 3 forwards and lastly 1 center. As you can see, the total here is only 7 players and leaves the last pick to the user. This is a quick way to save some additional time on the algorithm as the user can manually find the best remaining player (highest expected points given the salary remaining).
接下来,我修改了算法本身以选择特定位置。 现在,该算法不再从可用球员总数中选择所有可能的花名册,而是仅从所有可用后卫中挑选3个后卫,然后是3个前锋和最后1个中锋。 如您所见,此处的总数仅为7位玩家,而最后的选择权留给了用户。 这是一种节省算法上额外时间的快速方法,因为用户可以手动找到剩余的最好的球员(给定剩余的薪水,可以获得最高的期望积分)。
This was a huge optimization because the number of guards vs the total number of players is ~40 vs 85. The number is similar for forwards and even less for centers. Note, there’s a slight overlap between the players in each category as some players play multiple positions but this was easy to deal with: I removed played who were already picked as Guards, before picking Forwards etc. The performance boost as a result of the above changes can be seen below:
这是一个巨大的优化,因为后卫人数与球员总数之比约为40比85。前锋的人数相似,中锋的人数更少。 请注意,每个类别中的玩家之间都有一点重叠,因为有些玩家扮演多个职位,但是这很容易解决:我删除了已经被选为后卫的角色,然后再选择Forwards等。由于上述原因,性能提升更改如下所示:
- C (85 , 8) = 48,124,511,370C(85,8)= 48,124,511,370
- C (40 , 3) x C (40 , 3) x C (20, 1) = 1,952,288,000C(40,3)x C(40,3)x C(20,1)= 1,952,288,000
This is huge. Now, the algorithm is conducting almost ~95% fewer operations and we have the best possible roster broken up by positions and under our salary cap. Let’s test our results!
这是巨大的。 现在,该算法的运算量减少了约95%,并且按职位和工资帽划分的人员名单可能最好。 让我们测试一下结果!
实际结果 (Real World Results)
If you’ve made it so far, congratulations. You’ve worked through the technical stuff, now it’s time for the results! I tried the algorithm’s pick over the course of three days on DK’s classic multiplier contests. Each time my entry fee was $1 and the payoff was $3 for the top 30% of the finishers. You can see the lineups generated by the algorithm and the results below.
到目前为止,如果您做到了,那就祝贺您。 您已经完成了技术性工作,现在是时候取得成果了! 我在DK的经典乘数比赛中尝试了3天的算法选择。 每次我的报名费是1美元,而前30%的完成者的回报是3美元。 您可以在下面查看算法生成的阵容和结果。


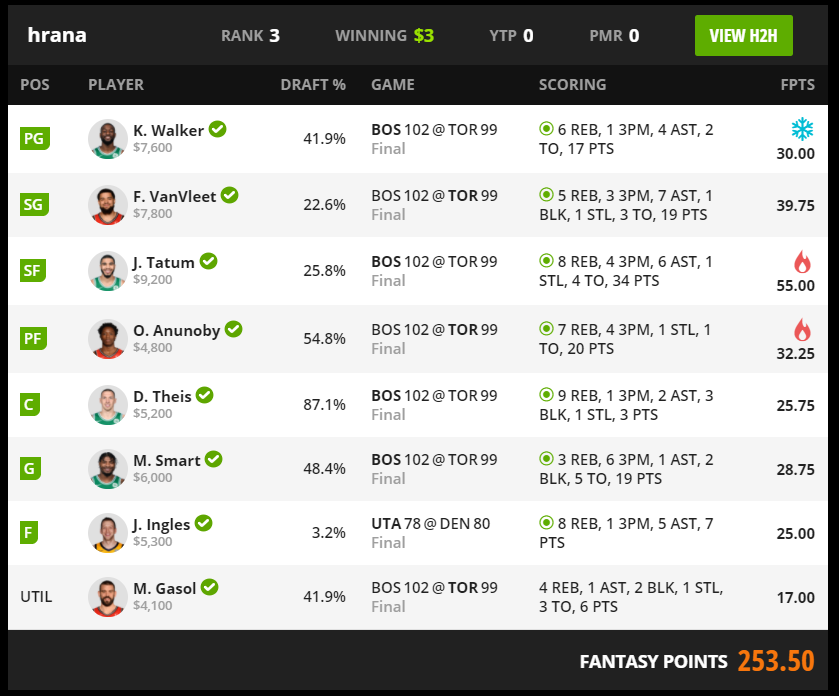
As you can see from the above results, the real world outcomes of the competition have been good! Out of the three days that I created lineups using the algorithm, we lost twice and won once. Our intermediate-level sports bettor algorithm has done better than I expected, but there’s still a long way to go.
从以上结果可以看出,比赛的真实结果是不错的! 在我使用算法创建阵容的三天内,我们输了两次,赢了一次。 我们的中级体育博彩算法比我预期的要好,但是还有很长的路要走。
I noticed few nuances about the results, including that our algorithm (before the v2 optimization) made a mistake on day 1 where an injured player was drafted into the team (P. Beverley) which resulted in a weak draft. This was fixed in version 2 and will not be repeated again. Additionally, once cool thing has been that despite the mixed results, the algorithm has consistently created lineups which get >200 fantasy points, which is pretty high!
我注意到关于结果的细微差别,包括我们的算法(在v2优化之前)在第1天犯了一个错误,即一名受伤的球员被征召入队(P. Beverley),导致选秀不力。 此问题在版本2中已修复,将不再重复。 此外,一旦出现有趣的结果是,尽管得到了混合结果,该算法仍会持续创建阵容,获得超过200个幻想点,这是非常高的!
下一步是什么? (What’s next?)
Well, there you have it. So far, I’ve spent $3 on entree fees and made $3 on winnings, for a grand total of $0 change! I have $25 left to spend on this project before my inner alarm bells start ringing, so I clearly need to improve this algorithm. After talking to some of my friends, who know a lot more about basketball than myself, I have a few hypotheses to test out. Some of these include:
好吧,那里有。 到目前为止,我已经在主菜费用上花费了$ 3,并在奖金中赚了$ 3,总共有$ 0的找零! 在我的内部警钟开始鸣响之前,我还有25美元可用于该项目,所以我显然需要改进此算法。 与我的一些朋友交谈后,我比我更了解篮球,我有一些假设可以检验。 其中一些包括:
Using additional player data over the last n games. This way the model would have more context, instead of just a snapshot value
在过去n场比赛中使用其他玩家数据。 这样,模型将具有更多上下文,而不仅仅是快照值
- Using prior team match-up data to adjust weights placed on certain games. For example, this could help avoid picking a player in a match-up where (based on previous meets) the player has failed to perform使用先前的球队比赛数据来调整某些游戏的权重。 例如,这可以帮助避免在对战中选择一名球员(基于先前的见面)而该球员未能完成比赛
- Exploring dual optimization strategies探索双重优化策略
And more! If you have any ideas about how to improve this project please feel free to reach out to me on LinkedIn or over email which you can find on my Website. Additionally, all the data and code for this project can be found on my Github repository, so feel free to clone/fork it and test your own hypotheses! And, as always, any and all feedback is greatly appreciated.
和更多! 如果您对如何改善此项目有任何想法,请随时通过LinkedIn或通过我的网站上找到的电子邮件与我联系。 此外,该项目的所有数据和代码都可以在我的Github存储库中找到,因此随时可以克隆/分叉它并测试自己的假设! 而且,一如既往,我们非常感谢任何反馈。
Stay safe out there everyone and keep building cool stuff.
每个人都应该保持安全,并继续制作有趣的东西。
翻译自: https://towardsdatascience.com/can-an-algorithm-pick-a-winning-nba-fantasy-draft-c05342f130f2
算法 从 数中选出
http://www.taodudu.cc/news/show-995333.html
相关文章:
- 插入脚注把脚注标注删掉_地狱司机不应该只是英国电影历史数据中的脚注,这说明了为什么...
- 贝叶斯统计 传统统计_统计贝叶斯如何补充常客
- 因为你的电脑安装了即点即用_即你所爱
- 团队管理新思考_需要一个新的空间来思考讨论和行动
- bigquery 教程_bigquery挑战实验室教程从数据中获取见解
- java职业技能了解精通_如何通过精通数字分析来提升职业生涯的发展,第8部分...
- kfc流程管理炸薯条几秒_炸薯条成为数据科学的最后前沿
- bigquery_到Google bigquery的sql查询模板,它将您的报告提升到另一个层次
- 数据科学学习心得_学习数据科学时如何保持动力
- python多项式回归_在python中实现多项式回归
- pd种知道每个数据的类型_每个数据科学家都应该知道的5个概念
- xgboost keras_用catboost lgbm xgboost和keras预测财务交易
- 走出囚徒困境的方法_囚徒困境的一种计算方法
- 平台api对数据收集的影响_收集您的数据不是那么怪异的api
- 逻辑回归 概率回归_概率规划的多逻辑回归
- ajax不利于seo_利于探索移动选项的界面
- 数据探索性分析_探索性数据分析
- stata中心化处理_带有stata第2部分自定义配色方案的covid 19可视化
- python 插补数据_python 2020中缺少数据插补技术的快速指南
- ab 模拟_Ab测试第二部分的直观模拟
- 亚洲国家互联网渗透率_发展中亚洲国家如何回应covid 19
- 墨刀原型制作 位置选择_原型制作不再是可选的
- 使用协同过滤推荐电影
- 数据暑假实习面试_面试数据科学实习如何准备
- 谷歌 colab_如何在Google Colab上使用熊猫分析
- 边际概率条件概率_数据科学家解释的边际联合和条件概率
- 袋装决策树_袋装树是每个数据科学家需要的机器学习算法
- opencv实现对象跟踪_如何使用opencv跟踪对象的距离和角度
- 熊猫数据集_大熊猫数据框的5个基本操作
- 帮助学生改善学习方法_学生应该如何花费时间改善自己的幸福
算法 从 数中选出_算法可以选出胜出的nba幻想选秀吗相关推荐
- 算法时间复杂度lg是多少_算法时间复杂度空间复杂度(附github)
(*useful)标记:目前觉得有用的函数 //FIXME 标记:待补充 基本初等函数: 幂函数: 一般地,形如y=xα(α为有理数)的函数,即以底数为自变量,幂为因变量,指数为常数的函数称为幂函数. ...
- matlab中存档算法代码,Matlab中的FCM算法代码及中文详解
Matlab中的FCM算法代码及中文详解 转自:http://xiaozu.renren.com/xiaozu/106512/336681453 function [center, U, obj_fc ...
- 【老生谈算法】matlab实现车牌识别中值滤波算法——车牌识别中值滤波算法
基于Matlab的车牌识别中值滤波算法的研究与实现 1.原文下载: 本算法原文如下,有需要的朋友可以点击进行下载 序号 原文(点击下载) 本项目原文 [老生谈算法]基于Matlab的车牌识别中值滤波算 ...
- 国密局公开SM2和SM3算法或预示中国商密算法将走向开放
临近2010年年底的时候,在国密局的网站上公布了基于椭圆曲线ECC的SM2公开密钥国密算法和SM3杂凑算法.加上原来的SM1商密对称算法,中国定义的算法终于开始成熟并且以一个大方的姿态展示出来了. 此 ...
- 在算法研究过程中如何进行算法创新
创新一直是一个令人纠结的话题,研究生毕业设计多数需要算法的创新,而博士生毕业更需要大量的创新才行.这里,我们就团队这几年来的工作经验,谈谈如何进行合理的算法创新. 一.创新角度 通常,我们使用一个算法 ...
- lru算法实现 redis_Redis中的lru算法实现
lru是什么 lru(least recently used)是一种缓存置换算法.即在缓存有限的情况下,如果有新的数据需要加载进缓存,则需要将最不可能被继续访问的缓存剔除掉.因为缓存是否可能被访问到没 ...
- matlab中值滤波法算法,基于MATLAB中值滤波算法的优化与实现
总第238期2014年第4期 舰 船 电 子 工 程 Ship Electronic Engineering Vol.34No.437 基于 MATLAB中值滤波算法的优化与实现* 赵建春 刘力源 ( ...
- 算法在ros中应用_烟火检测算法——中伟视界人工智能算法AI在智慧工地、石油中的应用_腾讯新闻...
烟火检测算法功能说明及实现原理等 一. 软件概述 视频智能分析基于目前先进的深度学习算法,通过大量的项目现场素材训练模型,通过本站大量采集的工作服素材,高精度的识别人.安全帽.工作服等识别,本项目主要 ...
- 机器学习算法实践-SVM中的SMO算法
前言 前两篇关于SVM的文章分别总结了SVM基本原理和核函数以及软间隔原理,本文我们就针对前面推导出的SVM对偶问题的一种高效的优化方法-序列最小优化算法(Sequential Minimal Opt ...
最新文章
- 第三代测序技术的主要特点及其在病毒基因组研究中的应用
- pull to load more data
- C++Quick sort快速排序的实现算法之一(附完整源码)
- Python import以及os模块
- 不变性真的意味着线程安全吗?
- ffmpeg 使用ffplay 进行 hls 拉流 分析 1
- html-超链接标签
- extends 抽象方法_关于abstract抽象类的理解
- 如何预防后台被攻击?Tomcat 的安全配置来啦!
- Android写的一个设置图片查看器,可以调整透明度
- 网站长尾关键词优化指南
- 移动端的click事件延迟触发的原理是什么?如何解决这个问题?
- Android中的隐藏API和Internal包的使用之获取应用电量排行
- Java实验报告2021
- 7塞班贝拉系统下载_远观JAVA,近观鸿蒙,盘点那些年我们用过的手机系统
- STM32解析SBUS信号例程详解
- 04、Hadoop框架HDFS NN、SNN、DN工作原理
- Android学习--04(打地鼠小游戏App源码+提示框Toast+提示窗口Dialog+菜单Menu+下拉框Spinner)
- 读《爱因斯坦文集》第一卷
- 高德地图自定义点标记大小_自定义高德地图的标记样式和内容