预训练模型应用工具 PaddleHub情感分析、对话情绪识别文本相似度
文章目录
- 1. 预训练模型的应用背景
- 1.1 多任务学习与迁移学习
- 1.2 自监督学习
- 2. 快速使用PaddleHub
- 2.1 通过Python代码调用方式 使用PaddleHub
- 2.1.1 CV任务
- 原图展示
- 人像扣图
- 人体部位分割
- 人脸检测
- 关键点检测
- 2.1.2 NLP 任务
- 2.2 通过命令行调用方式 使用PaddleHub
- 3. PaddleHub提供的预训练模型
- 4. 使用自己的数据Fine-tune PaddleHub预训练模型
- 4.1 安装PaddleHub
- 4.2 数据准备
- 4.3 模型准备
- 4.4 训练准备
- 4.5 组建Fine-tune Task
- 4.6 启动Fine-tune
- 5. 相关参考链接
十行代码能干什么? 相信多数人的答案是可以写个“Hello world”,或者做个简易计算器,本章将告诉你另一个答案,还可以实现人工智能算法应用。基于PaddleHub,可以轻松使用十行代码完成所有主流的人工智能算法应用,比如目标检测、人脸识别、语义分割等任务。
PaddleHub是飞桨预训练模型应用工具,集成了最优秀的算法模型,旨在帮助开发者使用最简单的代码快速完成复杂的深度学习任务,另外,PaddleHub提供了方便的Fine-tune API,开发者可以使用高质量的预训练模型结合Fine-tune API快速完成模型迁移到部署的全流程工作。
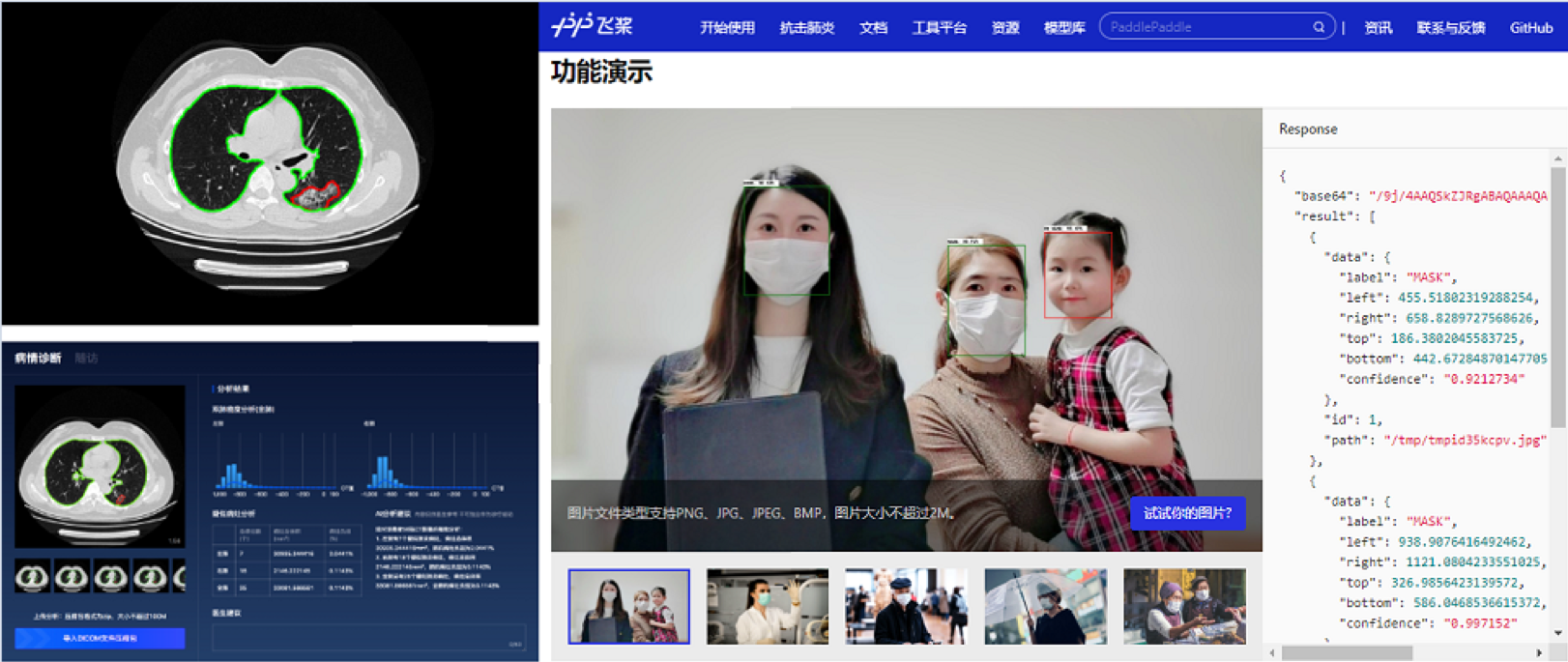
图1是2020年疫情期间,PaddleHub提供的十行代码即可完成根据肺部影像诊断病情的任务,以及检测人像是否佩戴口罩的任务。
图1:PaddleHub产业应用
运行如下代码,快速体验一下
安装
PaddleHub并升级到最新版本。# 下载安装paddlehub到最新版本,仅第一次运行项目时执行此命令 !pip install paddlehub==1.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple #指定版本安装PaddleHub,使用清华源更稳定、更迅速 !pip install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple #升级到最新版本,使用清华源更稳定、更迅速- 1
- 2
- 3
使用
Paddlehub实现口罩人脸检测,只需要几行命令。其中,test_mask_detection.jpg是一张测试图片。! wget https://paddlehub.bj.bcebos.com/resources/test_mask_detection.jpg #下载测试图片 ! hub install pyramidbox_lite_mobile_mask==1.3.0 #加载预训练模型 ! hub run pyramidbox_lite_mobile_mask --input_path test_mask_detection.jpg #运行预测结果- 1
- 2
- 3
本节将从如下几个方面介绍PaddleHub:
- 预训练模型的应用背景;
PaddleHub的快速使用方法和PaddleHub支持的模型列表;- 通过一个完整的案例,介绍如何使用自己的数据
Fine-tune PaddleHub的预训练模型。
1. 预训练模型的应用背景
众所周知,深度学习任务依赖较多的数据完成神经网络的训练。在实际场景中,数据量的大小与成本成正比,常遇到语料数据或者图像数据较少,不足以支持完成神经网络模型训练的场景。
经过不断的探索,人们发现有两种思路可以解决训练数据不足的问题。
1.1 多任务学习与迁移学习
人们发现处理很多任务所依赖的信息特征是相通的,比如从图片中框选出一只猫的任务与识别一个生物是不是猫的任务,均需要提取出标识猫的有效特征。这是符合认知的,人类处理一件任务也会不自觉的运用上从其他任务上学习到的知识和方法,比如我们学习英语的时候,也会代入已经掌握的很多中文语法习惯。
基于迁移学习的思想,我们可以将模型先在数据丰富的任务上学习,再使用新任务的小数据量做Fine-tune(网络参数的微调,继承了从数据丰富任务上学习到的知识),最终达到较好的效果。
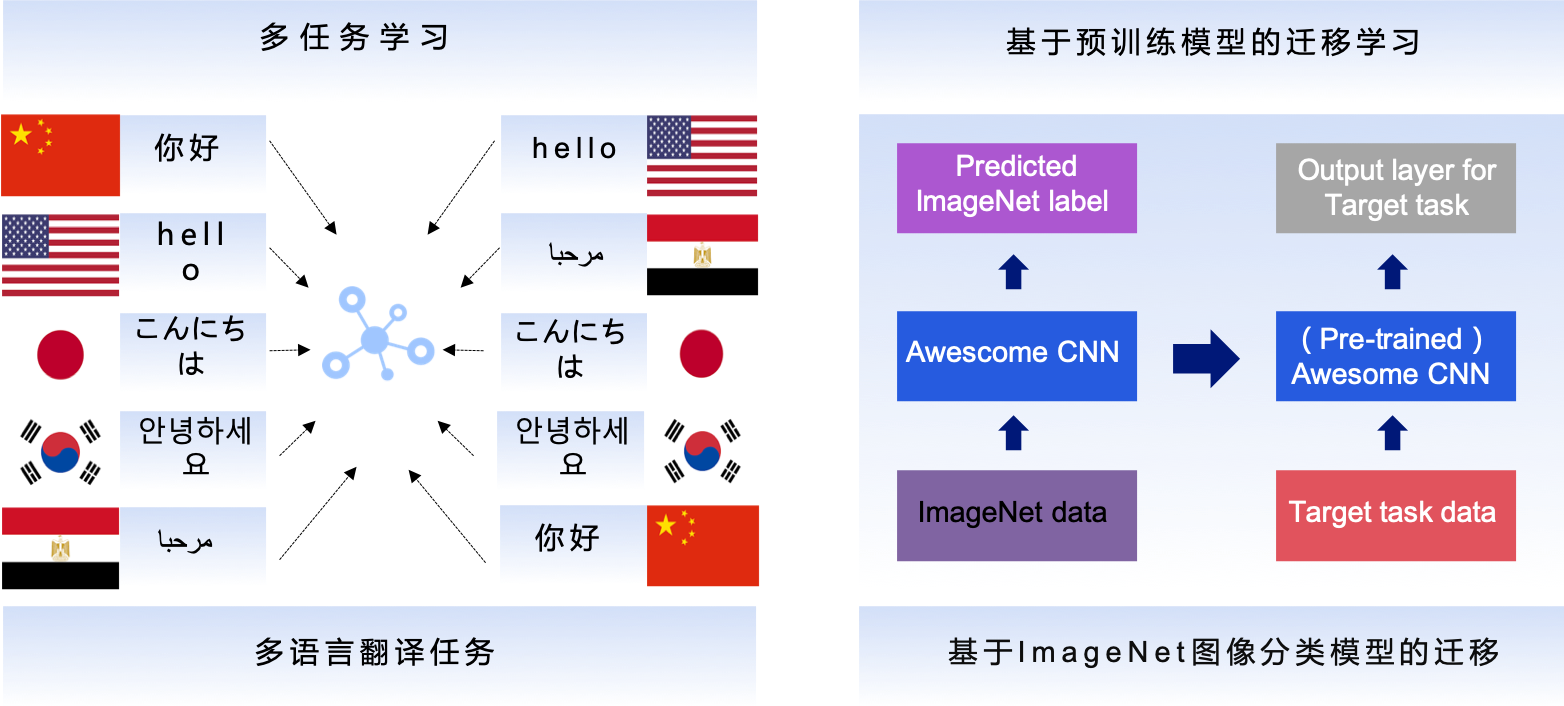
图2展示了对于不同的自然语言任务,很多本质的信息和知识是可以共享的。词性标注、句子句法成分划分、命名实体识别、语义角色标注等NLP任务适合采用多任务学习来解决。PaddleHub提供了预训练好的语义表示库ERNIE,它是这方面的佼佼者。
图2:多任务学习与迁移学习
1.2 自监督学习
通过一些巧妙的方法,我们可以将一些无监督的数据样本转变成监督学习,来学习数据中的知识。如图3所示,按照通常的理解,一张无标签的图片和一段自然语言文本是无监督的数据。但我们可以将部分图像进行遮挡,未遮挡的部分作为监督模型的输入,遮挡的部分作为模型需要预测的输出。同样的,也可以将一段文本中的部分短语遮挡,未遮挡的部分作为监督模型的输入,遮挡的部分作为模型需要预测的输出。
图3:自监督学习

PaddleHub中预置了大量的预训练模型,均采用了上述两种技术,并结合了百度在互联网领域海量的独有数据积累,数十种广受开发者欢迎的模型均是PaddleHub独有的。
2. 快速使用PaddleHub
既然PaddleHub的使用如此简单,功能又如此强大,那么读者们是否迫不及待了呢?下面我们就展示下快速使用PaddleHub的两种方式:Python代码调用和命令行调用。
2.1 通过Python代码调用方式 使用PaddleHub
首先以计算机视觉任务为例,我们选用一张测试图片test.jpg,分别实现如下四项功能:
- 人像扣图(deeplabv3p_xception65_humanseg)
- 人体部位分割(ace2p)
- 人脸检测(ultra_light_fast_generic_face_detector_1mb_640)
- 关键点检测(human_pose_estimation_resnet50_mpii)
注:有关调用的模型名字参考官方文档。
2.1.1 CV任务
原图展示
# 待预测图片
test_img_path = ["./test.jpg"]
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img = mpimg.imread(test_img_path[0])
# 展示待预测图片
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis(‘off’)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
![]()
人像扣图
#安装预训练模型
!hub install deeplabv3p_xception65_humanseg==1.1.0
- 1
- 2
Downloading deeplabv3p_xception65_humanseg
[==================================================] 100.00%
Uncompress /home/aistudio/.paddlehub/tmp/tmpybp717db/deeplabv3p_xception65_humanseg
[==================================================] 100.00%
Successfully installed deeplabv3p_xception65_humanseg-1.1.0
- 1
- 2
- 3
- 4
- 5
import paddlehub as hub
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
module = hub.Module(name=“deeplabv3p_xception65_humanseg”)
res = module.segmentation(paths = ["./test.jpg"], visualization=True, output_dir=‘humanseg_output’)
res_img_path = ‘humanseg_output/test.png’
img = mpimg.imread(res_img_path)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis(‘off’)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
![]()
人体部位分割
#安装预训练模型
!hub install ace2p==1.1.0
- 1
- 2
Downloading ace2p
[==================================================] 100.00%
Uncompress /home/aistudio/.paddlehub/tmp/tmpses1557l/ace2p
[==================================================] 100.00%
Successfully installed ace2p-1.1.0
- 1
- 2
- 3
- 4
- 5
import paddlehub as hub
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
module = hub.Module(name=“ace2p”)
res = module.segmentation(paths = ["./test.jpg"], visualization=True, output_dir=‘ace2p_output’)
res_img_path = ‘./ace2p_output/test.png’
img = mpimg.imread(res_img_path)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis(‘off’)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
![]()
人脸检测
#安装预训练模型
! hub install ultra_light_fast_generic_face_detector_1mb_640==1.1.2
- 1
- 2
Downloading ultra_light_fast_generic_face_detector_1mb_640
[==================================================] 100.00%
Uncompress /home/aistudio/.paddlehub/tmp/tmpstkqzi19/ultra_light_fast_generic_face_detector_1mb_640
[==================================================] 100.00%
Successfully installed ultra_light_fast_generic_face_detector_1mb_640-1.1.2
- 1
- 2
- 3
- 4
- 5
import paddlehub as hub
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
module = hub.Module(name=“ultra_light_fast_generic_face_detector_1mb_640”)
res = module.face_detection(paths = ["./test.jpg"], visualization=True, output_dir=‘face_detection_output’)
res_img_path = ‘./face_detection_output/test.jpg’
img = mpimg.imread(res_img_path)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis(‘off’)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
![]()
关键点检测
#安装预训练模型
!hub install human_pose_estimation_resnet50_mpii==1.1.0
- 1
- 2
File human_pose_estimation_resnet50_mpii_1.1.0.tar.gz already existed
Wait to check the MD5 value
MD5 check failed!
Delete invalid file.
Downloading human_pose_estimation_resnet50_mpii_1.1.0.tar.gz
[==================================================] 100.00%
- 1
- 2
- 3
- 4
- 5
- 6
import paddlehub as hub
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
module = hub.Module(name=“human_pose_estimation_resnet50_mpii”)
res = module.keypoint_detection(paths = ["./test.jpg"], visualization=True, output_dir=‘keypoint_output’)
res_img_path = ‘./keypoint_output/test.jpg’
img = mpimg.imread(res_img_path)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis(‘off’)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
![]()
2.1.2 NLP 任务
对于自然语言处理任务,下面以中文分词和情感分类的任务为例,待处理的数据以函数参数的形式传入。
#安装预训练模型
!hub install lac==2.1.1
- 1
- 2
Downloading lac
[==================================================] 100.00%
Uncompress /home/aistudio/.paddlehub/tmp/tmpt0t3qlhr/lac
[==================================================] 100.00%
Successfully installed lac-2.1.1
- 1
- 2
- 3
- 4
- 5
import paddlehub as hub
lac = hub.Module(name=“lac”)
test_text = [“1996年,曾经是微软员工的加布·纽维尔和麦克·哈灵顿一同创建了Valve软件公司。他们在1996年下半年从id software取得了雷神之锤引擎的使用许可,用来开发半条命系列。”]
res = lac.lexical_analysis(texts = test_text)
print(“中文词法分析结果:”, res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
[2020-05-25 10:40:44,605] [ INFO] - Installing lac module
[2020-05-25 10:40:44,610] [ INFO] - Module lac already installed in /home/aistudio/.paddlehub/modules/lac
中文词法分析结果: [{'word': ['1996年', ',', '曾经', '是', '微软', '员工', '的', '加布·纽维尔', '和', '麦克·哈灵顿', '一同', '创建', '了', 'Valve软件公司', '。', '他们', '在', '1996年下半年', '从', 'id', ' ', 'software', '取得', '了', '雷神之锤', '引擎', '的', '使用', '许可', ',', '用来', '开发', '半条命', '系列', '。'], 'tag': ['TIME', 'w', 'd', 'v', 'ORG', 'n', 'u', 'PER', 'c', 'PER', 'd', 'v', 'u', 'ORG', 'w', 'r', 'p', 'TIME', 'p', 'nz', 'w', 'n', 'v', 'u', 'n', 'n', 'u', 'vn', 'vn', 'w', 'v', 'v', 'n', 'n', 'w']}]
- 1
- 2
- 3
#安装预训练模型
! hub install senta_bilstm==1.1.0
- 1
- 2
Downloading senta_bilstm
[==================================================] 100.00%
Uncompress /home/aistudio/.paddlehub/tmp/tmpjh2vgjcx/senta_bilstm
[==================================================] 100.00%
Successfully installed senta_bilstm-1.1.0
- 1
- 2
- 3
- 4
- 5
import paddlehub as hub
senta = hub.Module(name=“senta_bilstm”)
test_text = [“味道不错,确实不算太辣,适合不能吃辣的人。就在长江边上,抬头就能看到长江的风景。鸭肠、黄鳝都比较新鲜。”]
res = senta.sentiment_classify(texts = test_text)
print(“中文词法分析结果:”, res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
[2020-05-25 10:43:00,885] [ INFO] - Installing senta_bilstm module
[2020-05-25 10:43:00,949] [ INFO] - Module senta_bilstm already installed in /home/aistudio/.paddlehub/modules/senta_bilstm
[2020-05-25 10:43:02,875] [ INFO] - Installing lac module
[2020-05-25 10:43:02,877] [ INFO] - Module lac already installed in /home/aistudio/.paddlehub/modules/lac
中文词法分析结果: [{'text': '味道不错,确实不算太辣,适合不能吃辣的人。就在长江边上,抬头就能看到长江的风景。鸭肠、黄鳝都比较新鲜。', 'sentiment_label': 1, 'sentiment_key': 'positive', 'positive_probs': 0.9775, 'negative_probs': 0.0225}]
- 1
- 2
- 3
- 4
- 5
2.2 通过命令行调用方式 使用PaddleHub
PaddleHub在设计时,为模型的管理和使用提供了命令行工具,也提供了通过命令行调用PaddleHub模型完成预测的方式。比如,上面人像分割和文本分词的任务也可以通过命令行调用的方式实现。
#通过命令行方式实现人像分割任务
! hub run deeplabv3p_xception65_humanseg --input_path test.jpg
- 1
- 2
[{'data': array([[-226.66667, -226.66667, -226.66667, ..., -226.66667, -226.66667,-226.66667],[-226.66667, -226.66667, -226.66667, ..., -226.66667, -226.66667,-226.66667],[-226.66667, -226.66667, -226.66667, ..., -226.66667, -226.66667,-226.66667],...,[-226.66667, -226.66667, -226.66667, ..., -226.66667, -226.66667,-226.66667],[-226.66667, -226.66667, -226.66667, ..., -226.66667, -226.66667,-226.66667],[-226.66667, -226.66667, -226.66667, ..., -226.66667, -226.66667,-226.66667]], dtype=float32)}]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
#通过命令行方式实现文本分词任务
!hub run lac --input_text "今天是个好日子"
- 1
- 2
[{'word': ['今天', '是', '个', '好日子'], 'tag': ['TIME', 'v', 'q', 'n']}]
- 1
上面的命令中包含四个部分,分别是:
hub表示PaddleHub的命令。run调用run执行模型的预测。deeplabv3p_xception65_humanseg、lac表示要调用的算法模型。--input_path/--input_text表示模型的输入数据,图像和文本的输入方式不同。
PaddleHub的命令行工具在开发时借鉴了Anaconda和PIP等软件包管理的理念,可以方便快捷的完成模型的搜索、下载、安装、升级、预测等功能。
可点击Github的网址了解详情。
目前,PaddleHub的命令行工具支持以下12个命令:
- install:用于将
Module安装到本地,默认安装在{HUB_HOME}/.paddlehub/modules目录下; - uninstall:卸载本地
Module; - show:用于查看本地已安装
Module的属性或者指定目录下确定的Module的属性,包括其名字、版本、描述、作者等信息; - download:用于下载百度提供的
Module; - search:通过关键字在服务端检索匹配的
Module,当想要查找某个特定模型的Module时,使用search命令可以快速得到结果,例如hub search ssd命令,会查找所有包含了ssd字样的Module,命令支持正则表达式,例如hub search ^s.\*搜索所有以s开头的资源; - list:列出本地已经安装的
Module; - run:用于执行
Module的预测; - version:显示
PaddleHub版本信息; - help:显示帮助信息;
- clear:
PaddleHub在使用过程中会产生一些缓存数据,这部分数据默认存放在${HUB_HOME}/.paddlehub/cache目录下,用户可以通过clear命令来清空缓存; - autofinetune:用于自动调整
Fine-tune任务的超参数,具体使用详情参考PaddleHub AutoDL Finetuner使用教程; - config:用于查看和设置
Paddlehub相关设置,包括对server地址、日志级别的设置; - serving:用于一键部署
Module预测服务,详细用法见PaddleHub Serving一键服务部署。
PaddleHub的产品理念是模型即软件,通过Python API或命令行实现模型调用,可快速体验或集成飞桨特色预训练模型。
此外,当用户想用少量数据来优化预训练模型时,PaddleHub也支持迁移学习,通过Fine-tune API,内置多种优化策略,只需少量代码即可完成预训练模型的Fine-tuning。
3. PaddleHub提供的预训练模型
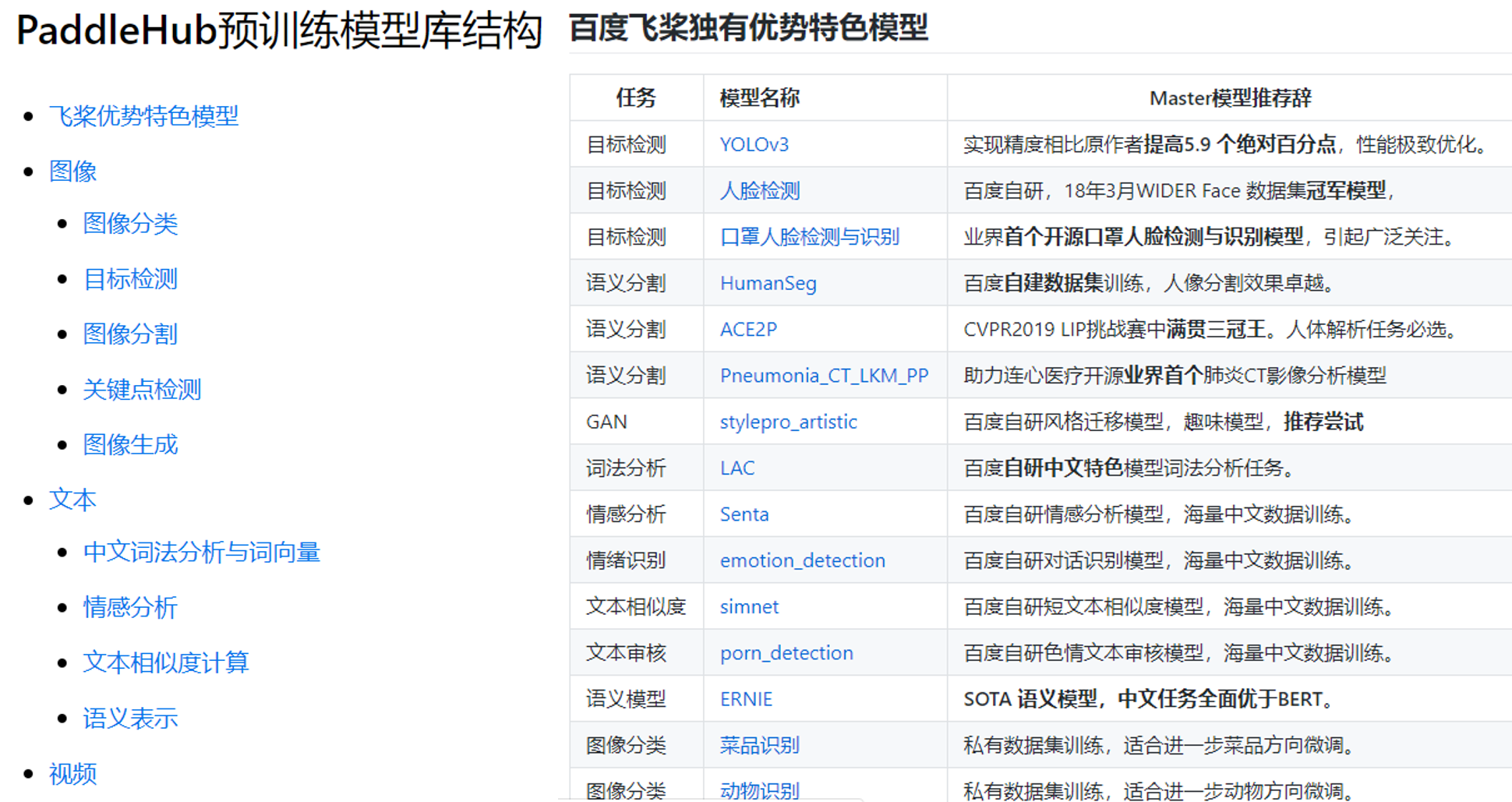
为了更好的应用PaddleHub的各种能力,我们需要知道PaddleHub集成了哪些模型。PaddleHub提供的预训练模型涵盖了图像分类、目标检测、视频分类、图像生成、图像分割、关键点检测、词法分析、语义模型、情感分析、文本审核等主流模型。PaddleHub的资源已有100多个分布在各领域的预训练模型,其中各领域均有百度独有数据训练或独有技术积累的模型,即只能在PaddleHub中找到的强大预训练模型,如 图4 所示。
图4:PaddleHub特色预训练模型
PaddleHub中集成的模型列表如下(持续扩充中):
- NLP模型列表
- 语义模型:word2vec_skipgram、simnet_bow、rbtl3、rbt3、Ernie_v2_eng_large、ernie_v2_eng_base、ernie_tiny、ERNIE、chinese-roberta-wwm-ext-large、chinese-roberta-wwm-ext、chinese-electra-small、chinese-electra-base、chinese-bert-wwm-ext、chinese-bert-wwm
- 文本审核: porn_detection_lstm、 porn_detection_gru、 porn_detection_cnn
- 词法分析:lac
- 情感分析:senta_lstm、senta_gru、senta_cnn、senta_bow、senta_bilstm、emotion_detection_textcnn
- CV模型列表
- 图像分类:vgg、xception、shufflenetv2、se_resnet、resnet、resnet_vd、resnet_v2、pnasnet、mobilenet、inception_v4、Googlenet、efficientent、dpn、densent、darknet、alexnet
- 关键点检测:pose_resnet50_mpii、face_landmark_localization
- 目标检测:yolov3、ssd、Pyramidbox、faster_rcnn
- 图像生成: StyleProNNet、stgan、cyclegan、attgan
- 图像分割:deeplabv3、ace2p
- 视频分类:TSN、TSM、stnet、nonlocal
4. 使用自己的数据Fine-tune PaddleHub预训练模型
果农需要根据水果的不同大小和质量进行产品的定价,所以每年收获的季节有大量的人工对水果分类的需求。基于人工智能模型的方案,收获的大堆水果会被机械放到传送带上,模型会根据摄像头拍到的图片,控制仪器实现水果的自动分拣,节省了果农大量的人力。
图5:水果在工厂传送带上自动分类

下面我们就看看如果采集到少量的桃子数据,如何基于PaddleHub对ImageNet数据集上预训练模型进行Fine-tune,得到一个更有效的模型。桃子分类数据集取自AI Studio公开数据集桃脸识别,该桃脸识别数据集中已经将所有桃子的图片分为2个文件夹,一个是训练集一个是测试集;每个文件夹中有4个分类,分别是B1、M2、R0、S3。
图6:自动分类结果示意

使用PaddleHub中的模型进行迁移学习的步骤如 图7 所示:

图7:PaddleHub模型迁移学习步骤
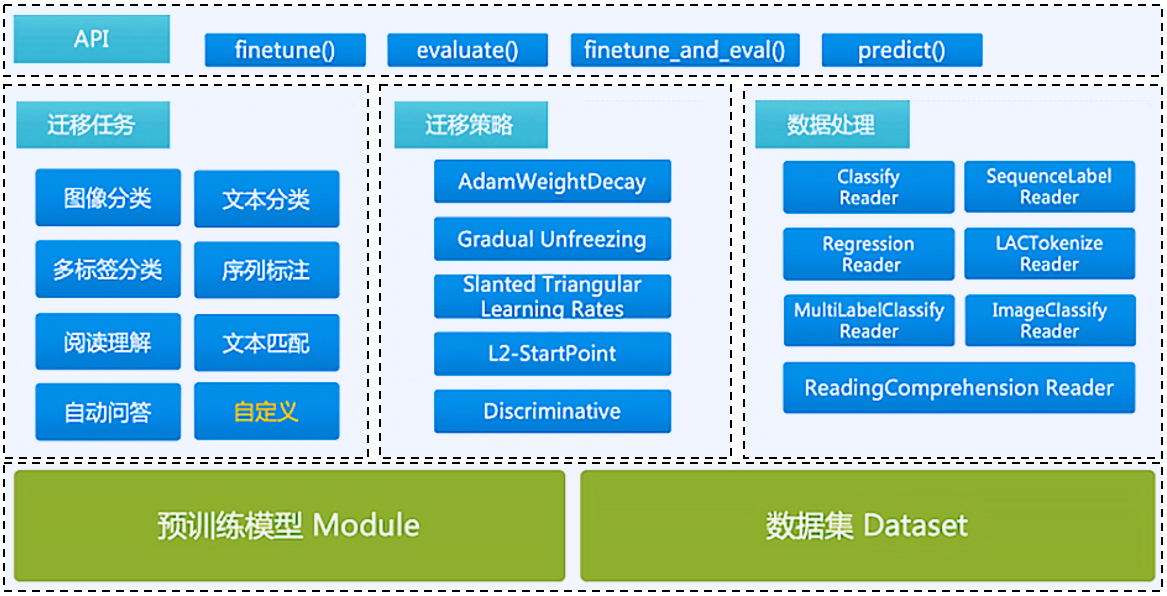
实现迁移学习,包括如下步骤:
- 安装PaddleHub
- 数据准备
- 模型准备
- 训练准备
- 组建Fine-tune Task
- 启动Fine-tune
在迁移学习的过程中,除了指定迁移学习的问题类型之外(通过选择模型的方式),还可以选择迁移学习的策略,以及对新收集样本做出数据增强的方法。
4.1 安装PaddleHub
paddlehub安装可以使用pip完成安装,如下:
# 安装并升级PaddleHub,使用清华源更稳定、更迅速
pip install paddlehub==1.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
- 2
- 3
4.2 数据准备
在本次教程提供的数据文件中,已经提供了分割好的训练集、验证集、测试集的索引和标注文件。如果用户利用PaddleHub迁移CV类任务使用自定义数据,则需要自行切分数据集,将数据集切分为训练集、验证集和测试集。需要三个文本文件来记录对应的图片路径和标签,此外还需要一个标签文件用于记录标签的名称。相关方法可参考用户自定义PaddleHub的数据格式。
├─data: 数据目录 ├─train_list.txt:训练集数据列表 ├─test_list.txt:测试集数据列表 ├─validate_list.txt:验证集数据列表 ├─label_list.txt:标签列表 └─……
- 1
- 2
- 3
- 4
- 5
- 6
训练集、验证集和测试集的数据列表文件的格式如下,列与列之间以空格键分隔。
图片1路径 图片1标签
图片2路径 图片2标签
...
- 1
- 2
- 3
label_list.txt的格式如下:
分类1名称
分类2名称
...
- 1
- 2
- 3
- 4
准备好数据后即可使用PaddleHub完成数据读取器的构建,实现方法如下所示:构建数据读取Python类,并继承BaseCVDataset这个类完成数据读取器构建。只要按照PaddleHub要求的数据格式放置数据,均可以用这个数据读取器完成数据读取工作。
!unzip -q -o ./data/data34445/peach.zip -d ./work
- 1
import paddlehub as hub
from paddlehub.dataset.base_cv_dataset import BaseCVDataset #加载图像类自定义数据集,仅需要继承基类BaseCVDatast,修改数据集存放地址即可
class DemoDataset(BaseCVDataset):
def init(self):
# 数据集存放位置
self.dataset_dir = “./work/peach-classification” #dataset_dir为数据集实际路径,需要填写全路径
super(DemoDataset, self).init(
base_path=self.dataset_dir,
train_list_file=“train_list.txt”,
validate_list_file=“validate_list.txt”,
test_list_file=“test_list.txt”,
#predict_file=“predict_list.txt”, #如果还有预测数据(没有文本类别),可以将预测数据存放在predict_list.txt文件
label_list_file=“label_list.txt”,
# label_list=[“数据集所有类别”] #如果数据集类别较少,可以不用定义label_list.txt,可以选择定义label_list=[“数据集所有类别”]
)
dataset = DemoDataset()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
4.3 模型准备
我们要在PaddleHub中选择合适的预训练模型来Fine-tune,由于桃子分类是一个图像分类任务,这里采用Resnet50模型,并且是采用ImageNet数据集Fine-tune过的版本。这个预训练模型是在图像任务中的一个“万金油”模型,Resnet是目前较为有效的处理图像的网络结构,50层是一个精度和性能兼顾的选择,而ImageNet又是计算机视觉领域公开的最大的分类数据集。所以,在不清楚选择什么模型好的时候,可以优先以这个模型作为baseline。
使用PaddleHub,不需要重新手写Resnet50网络,可以通过一行代码实现模型的调用。
#安装预训练模型
! hub install resnet_v2_50_imagenet
- 1
- 2
Downloading resnet_v2_50_imagenet
[==================================================] 100.00%
Uncompress /home/aistudio/.paddlehub/tmp/tmpn1e1enxo/resnet_v2_50_imagenet
[==================================================] 100.00%
Successfully installed resnet_v2_50_imagenet-1.0.1
- 1
- 2
- 3
- 4
- 5
import paddlehub as hub
module = hub.Module(name=“resnet_v2_50_imagenet”) #加载Hub提供的图像分类的预训练模型resnet_v2_50_imagenet
- 1
- 2
- 3
[2020-05-25 10:45:16,692] [ INFO] - Installing resnet_v2_50_imagenet module
[2020-05-25 10:45:16,710] [ INFO] - Module resnet_v2_50_imagenet already installed in /home/aistudio/.paddlehub/modules/resnet_v2_50_imagenet
- 1
- 2
将训练数据输入模型之前,我们通常还需要对原始数据做一些数据处理的工作,比如数据格式的规范化处理,或增加一些数据增强策略。
构建图像分类模型的数据读取器(Reader),负责将桃子dataset的数据进行预处理,以特定格式组织并输入给模型进行训练。
如下数据处理策略,只做了两种操作:
- 指定输入图片的尺寸,并将所有样本数据统一处理成该尺寸。
- 对所有输入图片数据进行归一化处理。其中,需要通过参数指定上一步的
dataset来链接到具体数据集,相当于在第一步的数据读取器上又包了一层处理策略。
data_reader = hub.reader.ImageClassificationReader(image_width=module.get_expected_image_width(), #预期桃子图片经过reader处理后的图像宽度image_height=module.get_expected_image_height(), #预期桃子图片经过reader处理后的图像高度images_mean=module.get_pretrained_images_mean(), #进行桃子图片标准化处理时所减均值。默认为Noneimages_std=module.get_pretrained_images_std(), #进行桃子图片标准化处理时所除标准差。默认为Nonedataset=dataset)
- 1
- 2
- 3
- 4
- 5
- 6
[2020-05-25 10:45:19,933] [ INFO] - Dataset label map = {'R0': 0, 'B1': 1, 'M2': 2, 'S3': 3}
- 1
4.4 训练准备
定义好模型,也设定好数据读取器后,我们就可以开始设置训练的策略。训练的配置使用hub.RunConfig函数完成,包括配置Fine-tune的轮数、Batchsize、评估的间隔等等,实现如下:
# Setup runing config for PaddleHub Finetune API
config = hub.RunConfig(use_cuda=True, #是否使用GPU训练,默认为False;num_epoch=1, #Fine-tune的轮数;checkpoint_dir="cv_finetune_turtorial_demo", #模型checkpoint保存路径, 若用户没有指定,程序会自动生成;batch_size=32, #训练的批大小,如果使用GPU,请根据实际情况调整batch_size;eval_interval=50, #模型评估的间隔,默认每100个step评估一次验证集;strategy=hub.finetune.strategy.DefaultFinetuneStrategy()) #Fine-tune优化策略;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[2020-05-25 10:45:22,634] [ INFO] - Checkpoint dir: cv_finetune_turtorial_demo
- 1
4.5 组建Fine-tune Task
有了合适的预训练模型,并准备好要迁移的数据集后,我们开始组建一个Task。在PaddleHub中,Task代表了一个Fine-tune的任务。任务中包含了执行该任务相关的Program、数据读取器Reader、运行配置等内容。PaddleHub预置了常见任务的Task,每种Task都有特定的应用场景并提供了对应的度量指标,满足用户的不同需求。在这里可以找到图像分类任务的对应说明ImageClassifierTask。
由于桃子分类是一个四分类的任务,而我们下载的分类module是在ImageNet数据集上训练的1000分类模型。所以需要对模型进行简单的微调,即将最后一层1000分类全连接层改成4分类的全连接层,并重新训练整个网络。实现方案如下:
- 获取
module(PaddleHub的预训练模型)的上下文环境,包括输入和输出的变量,以及Paddle Program(可执行的模型格式)。 - 从预训练模型的输出变量中找到特征图提取层
feature_map,在feature_map后面接入一个全连接层,如下代码中通过hub.ImageClassifierTask的feature_map参数指定。 - 网络的输入层保持不变,依然从图像输入层开始,如下代码中通过
hub.ImageClassifierTask的参数feed_list变量指定。
hub.ImageClassifierTask就是通过这两个参数明确我们的截取骨干网络的要求,按照这样的配置,我们截取的网络是从输入层“image”一直到特征提取的最后一层“feature_map”。
input_dict, output_dict, program = module.context(trainable=True) #获取module的上下文信息包括输入、输出变量以及paddle program
img = input_dict[“image”] #待传入图片格式
feature_map = output_dict[“feature_map”] #从预训练模型的输出变量中找到最后一层特征图,提取最后一层的feature_map
feed_list = [img.name] #待传入的变量名字列表
task = hub.ImageClassifierTask(
data_reader=data_reader, #提供数据的Reader
feed_list=feed_list, #待feed变量的名字列表
feature=feature_map, #输入的特征矩阵
num_classes=dataset.num_labels, #分类任务的类别数量
config=config) #运行配置
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
[2020-05-25 10:45:26,755] [ INFO] - 267 pretrained paramaters loaded by PaddleHub
- 1
4.6 启动Fine-tune
最后,使用Finetune_and_eval函数可以同时完成训练和评估。在Fine-tune的过程中,控制台会周期性打印模型评估的效果,以便我们了解整个训练过程的精度变化。
run_states = task.finetune_and_eval() #通过众多finetune API中的finetune_and_eval接口,可以边训练,边打印结果
- 1
[2020-05-25 10:45:34,892] [ INFO] - Strategy with slanted triangle learning rate, L2 regularization,
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/executor.py:804: UserWarning: There are no operators in the program to be executed. If you pass Program manually, please use fluid.program_guard to ensure the current Program is being used.warnings.warn(error_info)
[2020-05-25 10:45:37,003] [ INFO] - Try loading checkpoint from cv_finetune_turtorial_demo/ckpt.meta
[2020-05-25 10:45:37,952] [ INFO] - PaddleHub model checkpoint loaded. current_epoch=2, global_step=188, best_score=0.99760
[2020-05-25 10:45:37,953] [ INFO] - PaddleHub finetune start
[2020-05-25 10:45:37,954] [ INFO] - PaddleHub finetune finished.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
当Fine-tune完成后,我们使用模型来进行预测,实现如下:
import numpy as np
data = ["./work/peach-classification/test/M2/0.png"] #传入一张测试M2类别的桃子照片
task.predict(data=data,return_result=True) #使用PaddleHub提供的API实现一键结果预测,return_result默认结果是False
- 1
- 2
- 3
- 4
[2020-05-25 10:45:40,748] [ INFO] - PaddleHub predict start
[2020-05-25 10:45:40,749] [ INFO] - Load the best model from cv_finetune_turtorial_demo/best_model
[2020-05-25 10:45:42,838] [ INFO] - PaddleHub predict finished.
['M2']
- 1
- 2
- 3
- 4
以上为加载模型后实际预测结果(这里只测试了一张图片),返回的是预测的实际效果,可以看到我们传入待预测的是M2类别的桃子照片,经过Fine-tune之后的模型预测的效果也是M2,由此成功完成了桃子分类的迁移学习。
5. 相关参考链接
PaddleHub官网链接:https://www.paddlepaddle.org.cn/hubPaddleHub Github链接:https://github.com/PaddlePaddle/PaddleHubPaddleHub课程链接:https://aistudio.baidu.com/aistudio/course/introduce/1070
</div>
预训练模型应用工具 PaddleHub情感分析、对话情绪识别文本相似度相关推荐
- Paddle预训练模型应用工具PaddleHub
Paddle预训练模型应用工具PaddleHub • 本文主要介绍如何使用飞桨预训练模型管理工具PaddleHub,快速体验模型以及实现迁移学习.建议使用GPU环境运行相关程序,可以在启动环境时,如下 ...
- Hugging Face 中文预训练模型使用介绍及情感分析项目实战
Hugging Face 中文预训练模型使用介绍及情感分析项目实战 Hugging Face 一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上最先进(SOTA, ...
- PaddlePaddle模型资源之一:预训练模型应用工具 PaddleHub
文章目录 1. 预训练模型的应用背景 1.1 多任务学习与迁移学习 1.2 自监督学习 2. 快速使用PaddleHub 2.1 通过Python代码调用方式 使用PaddleHub 2.1.1 CV ...
- 模型资源之一:预训练模型应用工具 PaddleHub
目录 PaddleHub使用预训练模型和Finetune的工具 预训练模型的应用背景 多任务学习与迁移学习 自监督学习 快速使用PaddleHub 通过Python代码调用方式 使用PaddleHub ...
- 利用LSTM+CNN+glove词向量预训练模型进行微博评论情感分析(二分类)
先上代码和数据集 https://pan.baidu.com/s/1tpEKb0nCun2oxlBXGlPvxA 提取码:cryy 里面所需要的,都在文件里, 数据是微博评论(共12万,没记错的话,0 ...
- PaddleHub--飞桨预训练模型应用工具{风格迁移模型、词法分析情感分析、Fine-tune API微调}【一】
相关文章: 基础知识介绍: [一]ERNIE:飞桨开源开发套件,入门学习,看看行业顶尖持续学习语义理解框架,如何取得世界多个实战的SOTA效果?_汀.的博客-CSDN博客_ernie模型 百度飞桨:E ...
- [Python人工智能] 二十二.基于大连理工情感词典的情感分析和情绪计算
从本专栏开始,作者正式研究Python深度学习.神经网络及人工智能相关知识.前一篇文章分享了CNN实现中文文本分类的过程,并与贝叶斯.决策树.逻辑回归.随机森林.KNN.SVM等分类算法进行对比.这篇 ...
- BERT 预训练模型及文本分类(情感分类)
https://www.cnblogs.com/wwj99/p/12283799.html
- 【Spark NLP】第 12 章:情感分析和情绪检测
最新文章
- ROS话题通信中创建自定义数据类型的两种方式
- myeclipse.ini内存参数设置及其含义
- apache .htaccess 禁止访问某目录方法
- EM算法 大白话讲解
- SVM+HOG:利用训练好的XML进行行人检测(检测效果)
- java线程唤醒线程_Java中如何唤醒“指定的“某个线程
- set-matrix-zeroes当元素为0则设矩阵内行与列均为0
- 分类(category)是门学问
- Python入门4_之字典的使用
- RNN 循环神经网络系列 5: 自定义单元
- HDU - 6191 Query on A Tree
- 无代码编程时代下,程序员要失业了?
- php 调用高拍仪,html页面通过ActiveX控件调用摄像头实现拍照上传demo代码下载
- sklearn学习笔记之开始
- 用PHP实现手机对jar,jad文件的下载(转)
- 基于SSM高校教师教务信息管理系统
- android-sdk-windows 如何安装,android-sdk-windows 安装.doc
- Android studio 简易流式布局
- 基于java的CRM客户关系管理系统的设计和实现
- 关于 sso 博客大巴的神仙的一点思路