机器学习常用性能度量中的Accuracy、Precision、Recall、ROC、F score等都是些什么东西?...
一篇文章就搞懂啦,这个必须收藏!
我们以图片分类来举例,当然换成文本、语音等也是一样的。
Positive
正样本。比如你要识别一组图片是不是猫,那么你预测某张图片是猫,这张图片就被预测成了正样本。Negative
负样本。比如你要识别一组图片是不是猫,那么你预测某张图片不是猫,这张图片就被预测成了负样本。TP
一组预测为正样本的图片中,真的是正样本的图片数。TN:
一组预测为负样本的图片中,真的是负样本的图片数。FP:
一组预测为正样本的图片中,其实是负样本的图片数。又称“误检”FN:
一组预测为负样本的图片中,其实是正样本的图片数。又称“漏检”。精度(accuracy)
分类正确的样本数占总样本数的比例。
acc = (TP+TN)/ 总样本数查准率/准确率 precision
一组预测为正样本的图片中,真的是正样本的图片所占的比例。

为什么有了Accuracy还要提出Precision的概念呢?因为前者在测试样本集的正负样本数不均衡的时候,比如正样本数为1,负样本数为99时,模型只要每次都将给定的样本预测成负样本,那么Accuracy = (0+99)/100 = 0.99,精度依然可以很高,但这毫无意义。但是同样的样本集,同样的方法运用到查准率公式上,就不可能得到一个很高的值了。
查全率/召回率 recall
所有真的是正样本的图片中,被成功预测出来的图片所占的比例。

查准率和查全率的关系
一般来说,想查的准,那么往往查不全(想想宁缺毋滥);想查的全,又往往会不准(想想宁抓错不放过)。所以P和R是两个矛盾的量。P-R曲线 (查准率-查全率曲线)
该曲线是通过取不同的阈值下的P和R,绘制出来。这里的阈值就是指模型预测样本为正样本的概率。比如阈值取0.6,则所有被预测出的概率大于该阈值的样本,都认为是被预测成了正样本,这些被预测成正样本的样本中,实际是由TP(真的是正样本)和FP(并不是正样本)组成的。所以取一个阈值,就能计算出一组P-R,那么取多个阈值后,P-R曲线就绘制出来了。

从上图中可以看到,P-R曲线是采用平衡点(P=R的点)来判断哪个学习器更好(图中有A、B、C三个学习器),A好于B好于C。
- F1分数和Fβ分数
然而,上面的度量方法只能通过看图来理解,但是我们希望能更直接的通过一个分数来判定模型的好坏。所以更常用来度量的方法是取相同阈值下各模型的F1分数或Fβ分数(以下截图来自周志华老师的西瓜书[1]):

F1分数的公式是怎么来的呢?看下图:2.10的公式,其实是由下面的调和平均公式推导出来的。

所谓调和平均数就是:所有数字的倒数求算术平均后,再取倒数。该值平均考虑了P和R的表现。
为什么β>1时查全率有更大影响,而β<1时查准率有更大影响呢?看下图:2.11的公式,其实是由下面的加权调和平均公式推导出来的。

β的平方相当于1/R的权重,当β大于1,相当于提高1/R的重要度,当β小于1,相当于降低了1/R的重要度,而R正是查全率。
所以,当我们更倾向于查准率R的表现(即想查的更全,宁抓错不放过)时,可以将β设置为一个大于1的数字,具体设置多少,就要看倾向程度了,然后进行Fβ分数的比较。
- ROC曲线
ROC的全称是Receiver operating characteristic,翻译为受试者工作特征。先不用管这个名字有多难理解。我们先弄清楚ROC曲线是什么。ROC曲线如下图[2]:

纵坐标是真正率(其实就是召回率/查全率)=TP/(TP+FN),横坐标是假正率(误检率FPR)=FP/(FP+TN)。
该曲线是模型在不同阈值(与PR曲线中提到的阈值意思一样)下的查全率和误检率的表现。当阈值设为0时,相当于所有样本预测为正,查全率达到1,误检率当然也达到1;当阈值设为1时,相当于所有样本预测为负,查全率达到0(太严格了),误检率当然也达到0(因为严格嘛)。
因为我们希望召回率高,误检率低,所以曲线上越接近左上角(0,1)的点表现越好。所以ROC曲线是干嘛的?就是通过查全率和误检率的综合表现来评价模型的好坏用的。
你可以尝试大量增加测试样本的正样本或负样本的数量,让数据集变的不均衡,然后会发现ROC曲线可以几乎稳定不变,而PR曲线会发生巨大的变化。如下图:[5]。

可以根据PR曲线中P(precision)的公式,R(recall)的公式,根据ROC曲线中R(recall)的公式,误检率(FPR)的公式来理解,这里不细说了。
- AUC
area under curve。定义为ROC曲线下的面积。然因为这个面积的计算比较麻烦。所以大牛们总结出了下面的等价的计算方法。
假设一组数据集中,实际有M个正样本,N个负样本。那么正负样本对就有M*N种。
AUC的值等同于在这M*N种组合中,正样本预测概率大于负样本预测概率的组合数所占的比例。

其中I函数定义如下:
P正>P负,输出1;
P正=P负,输出0.5;
P正<P负,输出0。
上面的计算方法已经比计算面积要愉快多了,但是还有相对更好的计算思路:
按照预测概率从小到大排序,得到排好序的M*N个组合,其中正样本的序号就表示比当前正样本概率小的样本个数,再从这些样本中减去正样本的个数,就得到了当前正样本概率大于负样本概率的组合数。
为了计算方便,我们先把排好序的M*N个组合中所有正样本的序号累加,然后减去正样本的个数的累加,就得到了所有正样本概率大于负样本概率的组合数,然后除以M*N,就得到了在这M*N种组合中,正样本预测概率大于负样本预测概率的组合数所占的比例,这个比例等同于AUC。下面我们来看看具体的计算公式[4] :
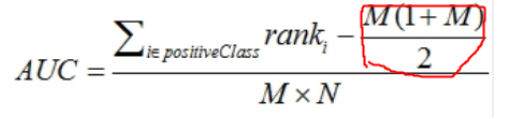
看上去挺复杂的,稍微解释一下你就明白了。
分子左边的部分就是排好序的M*N个组合中所有正样本的序号累加,
分子右边的部分其实就是正样本的个数的累加的公式,这个稍微解释一下:比如我们有5个正样本,那么正样本的个数累加就是1+2+3+4+5=15,带入公式就是5*(1+5)/2=15,而这个公式就是“高斯等差数列求和公式”: (首项+末项)x项数÷2。
分母部分比较好理解了,就是所有的正负样本的组合数。
如果在排序的时候遇到了概率值相同的情况,其实谁前谁后是没有关系的,只是在累加正样本的序号的时候,如果有正样本的概率值和其他样本(包括正和负)的概率值一样,那么序号是通过这些相同概率值的样本的序号的算术平均数来计算的。举例如下[3]:
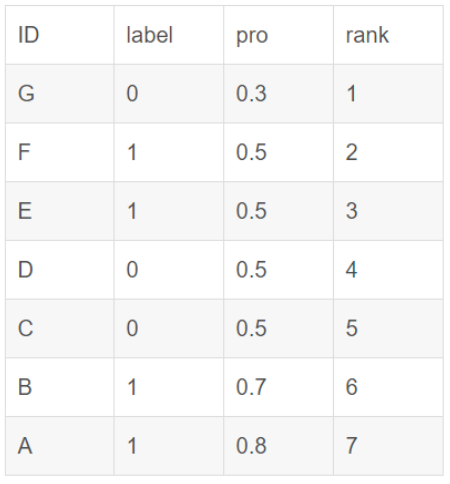
在累加正样本的序号的时候,正样本的rank(序号)值:
对于正样本A,其rank值为7
对于正样本B,其rank值为6
对于正样本E,其rank值为(5+4+3+2)/4
对于正样本F,其rank值为(5+4+3+2)/4
最后正样本的序号累加计算就是:

求出了各个模型的ROC曲线下的面积,也就是AUC,就可以比较模型之间的好坏啦。
注意
以上度量指标一般都是用于二元分类,如果是在多分类的场景下,可以拆成多个二分类问题来度量。而如果除了分类还有其他预测的任务,就需要针对性的度量指标来评估模型的好坏了。比如像目标检测,除了目标分类,还要预测目标的边界框位置,所以用的是mAP指标,具体可以参考下一篇文章《目标检测中为什么常提到IoU和mAP,它们究竟是什么?》
参考文献
[1]《西瓜书》周志华 著
[2]《机器学习实战》Peter Harrington 著
[3] https://blog.csdn.net/qq_22238533/article/details/78666436
[4] https://blog.csdn.net/pzy20062141/article/details/48711355
[5] https://www.cnblogs.com/dlml/p/4403482.html
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O,88~
推荐阅读:
还再@微信官方要国旗?这才是正确的打开方式~
转载于:https://www.cnblogs.com/anai/p/11576831.html
机器学习常用性能度量中的Accuracy、Precision、Recall、ROC、F score等都是些什么东西?...相关推荐
- 机器学习常用的评测指标Rank-n、Precision Recall、F-score、Map 、CMC、ROC Single shot 和Muti shot
机器学习中常用的评测指标为:Rank-n.Precision & Recall.F-score.Map .CMC.ROC Single shot 和Muti shot,下面一个个进行介绍. 写 ...
- 机器学习模型常用评价指标(Accuracy, Precision, Recall、F1-score、MSE、RMSE、MAE、R方)
前言 众所周知,机器学习分类模型常用评价指标有Accuracy, Precision, Recall和F1-score,而回归模型最常用指标有MAE和RMSE.但是我们真正了解这些评价指标的意义吗? ...
- 机器学习:性能度量篇-Python利用鸢尾花数据绘制ROC和AUC曲线
文章目录 前言 一.ROC与AUC 1.ROC 2.AUC 二.代码实现 总结 前言 内容接上一篇机器学习:性能度量篇-Python利用鸢尾花数据绘制P-R曲线_fanstuck的博客-CSDN博客_ ...
- 多分类模型Accuracy, Precision, Recall和F1-score的超级无敌深入探讨
https://zhuanlan.zhihu.com/p/147663370?from_voters_page=true 众所周知,机器学习分类模型常用评价指标有Accuracy, Precision ...
- Accuracy, Precision, Recall和F1-score解释
本文解释分类问题常用评价指标Accuracy, Precision, Recall和F1-score 主要参考以下文章 多分类模型Accuracy, Precision, Recall和F1-scor ...
- 机器学习之性能度量指标
机器学习的模型性能度量指标 在机器学习中,衡量,评估和选择一个模型好坏是通过一些常见指标实现的,称之为性能指标(Metrics). 对于一个二分类问题,我们首先给出如下基本指标基于这些指标可以推导出其 ...
- 机器学习性能度量(1):P-R曲线与ROC曲线,python sklearn实现
最近做实验要用到性能度量的东西,之前学习过现在重新学习并且实现一下. 衡量模型泛化能力的评价标准,这就是性能度量.性能度量反应了任务需求,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判 ...
- 机器学习之性能度量指标——决定系数R^2、PR曲线、ROC曲线、AUC值、以及准确率、查全率、召回率、f1_score
一.线性回归的决定系数(也称为判定系数,拟合优度) 相关系数是R哈~~~就是决定系数的开方! 正如题所说决定系数是来衡量回归的好坏,换句话说就是回归拟合的曲线它的拟合优度!也就是得分啦~~ 决定系数它 ...
- 【机器学习】距离度量中常见的距离计算公式
机器学习:距离度量 欧式距离(Euclidean Distance) 曼哈顿距离(Manhattan Distance) 切比雪夫距离 (Chebyshev Distance) 闵可夫斯基距离(Min ...
最新文章
- Android 动画 ViewPropertyAnimator 的使用
- 一天一个设计模式(3)——单例模式
- 中国大学MOOC 人工智能导论第三章测试
- codeforces:CF1604 总结
- RabbitMQ 关键词解释
- 格式化显示(日期\货币)
- 算子,滤波器,卷积模板,卷积核的概念比较
- win7和win8双系统的问题
- iOS开发内存泄露修复
- postgresql 时区与时间函数
- 计算机二级c语言必看,计算机二级C语言考试必看技巧
- nvidia 卸载驱动
- 浏览器首页被雨林木风篡改( /hao.ylmf.com/u7654.html)
- 在非关联情况下的欧姆定律的使用
- HTML设置图片为页面背景
- c语言计算标准体重作业,c语言/* 已知成人标准体重粗算公式:
- Java基础 -> 线程池的底层⼯作原理
- 如何通过 onstat 命令监控GBase8s数据库
- 关于用python爬取自如网信息的价格问题(已解决)
- uni-app如何设置整个项目的统一背景色