hadoop大数据生态概述
Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构
Hadoop通常是指一个更广泛的概念——Hadoop生态圈
Hadoop 三大发行版本: Apache、 Cloudera、 Hortonworks (被收购)
注意:Hadoop1.x、 2.x、 3.x的区别(计算和资源调度)
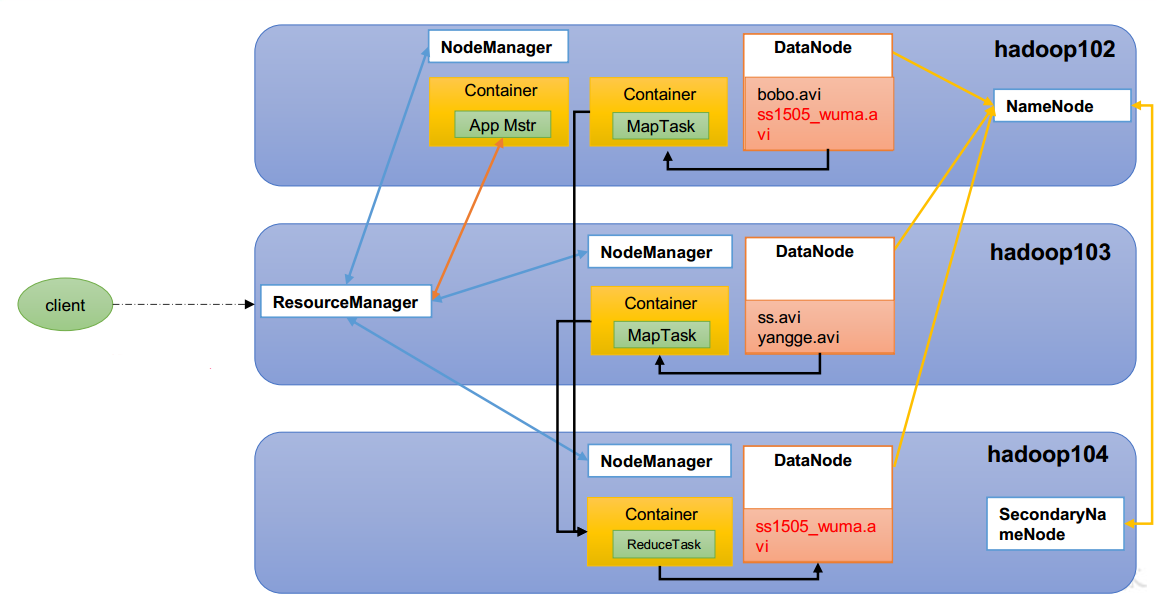
HDFS架构
- NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、 副本数、文件权限),以及每个文件的块列表和块所在的DataNode等
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和
- Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份
YARN架构
- ResourceManager(RM):整个集群资源(内存、 CPU等)
- NodeManager(NM):单个节点服务器资源
- ApplicationMaster(AM):单个任务运行资源
- Container:封装了任务运行所需要的资源,如内存、 CPU、磁盘、网络等
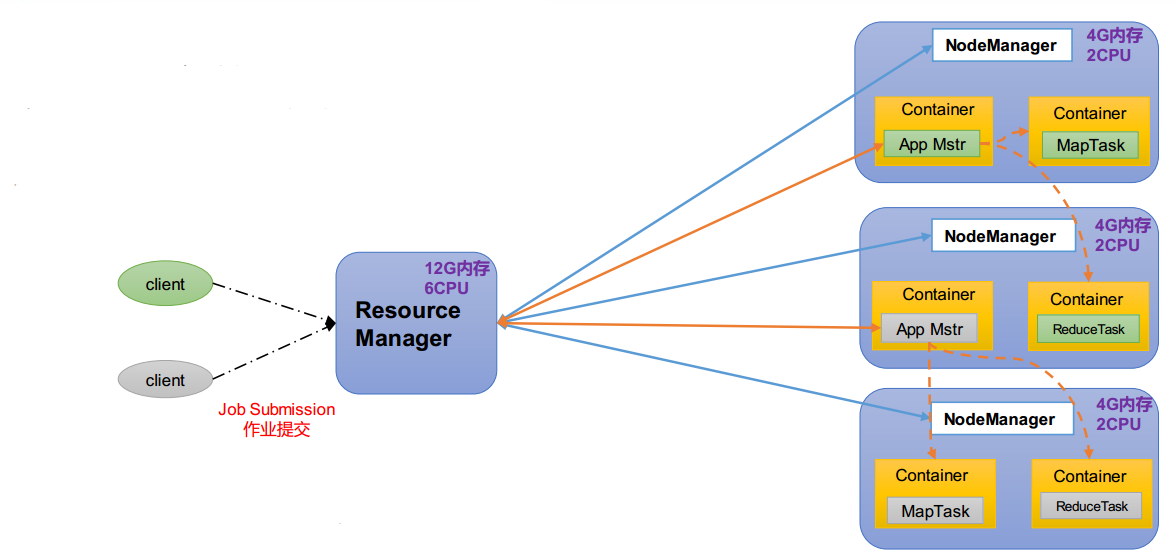
MapReduce架构
- Map 阶段并行处理输入数据
- Reduce 阶段对 Map 结果进行汇总
HDFS、 YARN、 MapReduce 关系
大数据生态体系概述
![]()
- Sqoop: Sqoop 是一款开源的工具,主要用于在 Hadoop、 Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL, Oracle 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
- Flume: Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
- Kafka: Kafka 是一种高吞吐量的分布式发布订阅消息系统
- Spark: Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数据进行计算。
- Flink: Flink 是当前最流行的开源大数据内存计算框架。 用于实时计算的场景较多。
- Oozie: Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
- Hbase: HBase 是一个分布式的、面向列的开源数据库。 HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
- Hive: Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
- ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
hadoop大数据生态概述相关推荐
- Hadoop 大数据生态框架--总述
1. 前言:什么是大数据?什么是分布式? 官方概念就不在这里赘述了,以笔者的理解,所谓大数据,不是指绝对数据量很大,经常有人说 PB,TB级大数据处理技术等等.试想如果未来的硬件性能有跨越式发展,常规 ...
- hadoop大数据生态集群
大数据 又称为巨量资料,指的是传统数据处理应用软件不足以处理它们的大或复杂的数据集的术语.大数据也可以定义为来自各种来源的大量非结构化或结构化数据. 大数据无处不在,例如我们在淘宝搜索输入一个手机后, ...
- Hadoop大数据生态组件环境安装
首先安装Centos系统修改网络配置: 我的三台机器: master 192.168.179.10 slave1 192.168.179.11 slava2 192.168.179.12 各组件端口号 ...
- 二、大数据技术之Hadoop --从Hadoop框架讨论大数据生态
目录 1.从Hadoop框架讨论大数据生态 1.1 Hadoop是什么 1.2 Hadoop发展历史 1.3 Hadoop三大发行版本 1.3.1 Apache Hadoop 1.3.2 Cloude ...
- 从Hadoop框架讨论大数据生态
文章目录 从Hadoop框架讨论大数据生态 Hadoop 是什么(一是) Hadoop发展史(二知) Hadoop三大版本(三版) Hadoop的优势(4高) Hadoop的组成(关于吾的自身) Ha ...
- hadoop大数据开发基础_Java大数据开发(三)Hadoop(2)经典的Hadoop
点击蓝字关注我 1 什么是大数据 1.Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2.主要解决,海量数据的存储和海量数据的分析计算问题. 3.广义上来说,HADOOP通常是指一个 ...
- 1.初始Hadoop大数据技术
1.1 大数据技术概要 1.1.1 大数据产生的背景 2001年后,互联网迅速发展,数据量成倍递增.进入2012年,大数据(big data)一词越来越多地被提及,人们用它来描述和定义信息爆炸时代产生 ...
- Hadoop大数据零基础高端实战培训系列配文本挖掘项目
<Hadoop大数据零基础高端实战培训系列配文本挖掘项目(七大亮点.十大目标)> 课程讲师:迪伦 课程分类:大数据 适合人群:初级 课时数量:230课时 用到技术:部署Hadoop集群 涉 ...
- 融合趋势下基于 Flink Kylin Hudi 湖仓一体的大数据生态体系
简介:本文由 T3 出行大数据平台负责人杨华和资深大数据平台开发工程师王祥虎介绍 Flink.Kylin 和 Hudi 湖仓一体的大数据生态体系以及在 T3 的相关应用场景. 本文由 T3 出行大数据 ...
- 大数据生态及其技术栈
大数据生态及其技术栈 原文:大数据生态及其技术栈 如何用形象的比喻描述大数据的技术生态?Hadoop.Hive.Spark 之间是什么关系?对于大部分人来说都是傻傻分不清楚. 今年来大数据.人工智能获 ...
最新文章
- 过滤内容字段_巧用参数组件和过滤组件,教你快速定位目标数据
- keepalived介绍
- get传递中文产生乱码的解决方式汇总
- JAVA记录-Servlet RequestDispatcher请求转发
- SVN主干与分支的合并
- 异步/scrapy想关
- 没有信号无服务器,没有信号不用怕“音离”你身边的便携式基站
- php 判断 跳转url参数,怎么通过链接获取跳转后的url参数
- vue 一个组件内多个弹窗_使用vue实现各类弹出框组件
- [转]HTTP协议之状态码详解
- ADS(Advanced Design system)原理图结合板层结构仿真(MSub)及版图仿真(EM Simulation)
- 免费手机WAP网站大全
- uniapp之安卓文件操作插件
- 关于安装VC++运行库遇到各种小问题
- kubeadm工作原理-kubeadm init原理分析-kubeadm join原理分析
- Python爬虫:博客被抄袭了还不知道?快来查查
- 巧用 Linux 定时任务
- 人们从诗人的字句里选取自己心爱的意义但诗句的最终意义是指向你
- linux 防火墙的配置
- C语言 正序分解整数