mc2180 刷机方法_MC控制和时差方法
mc2180 刷机方法
深层加固学习介绍— 14 (DEEP REINFORCEMENT LEARNING EXPLAINED — 14)
In this new post of the “Deep Reinforcement Learning Explained” series, we will improve the Monte Carlo Control Methods to estimate the optimal policy presented in the previous post. In the previous algorithm for Monte Carlo control, we collect a large number of episodes to build the Q-table. Then, after the values in the Q-table have converged, we use the table to come up with an improved policy.
在“ 深度强化学习解释 ”系列的这一新文章中,我们将改进蒙特卡洛控制方法,以估计前一文章中提出的最佳策略。 在以前的蒙特卡洛控制算法中,我们收集了大量事件以构建Q表。 然后,在Q表中的值收敛之后,我们使用该表提出一种改进的策略。
However, Monte Carlo prediction methods can be implemented incrementally, on an episode-by-episode basis and this is what we will do in this post. Even though the policy is updated before the values in the Q-table accurately approximate the action-value function, this lower-quality estimate nevertheless still has enough information to help propose successively better policies.
但是, 可以在逐集的基础上逐步实现 Monte Carlo预测方法,这是我们在本文中将要做的。 即使在Q表中的值准确地逼近行动值函数之前就更新了策略,但此较低质量的估算仍然有足够的信息来帮助提出相继更好的策略。
Furthermore, the Q-table can be updated at every time step instead of waiting until the end of the episode using Temporal-Difference Methods. We will review them also in this post.
此外,可以使用时间差异方法在每个时间步 更新 Q表,而不必等到情节结束 。 我们还将在这篇文章中对其进行审查。
蒙特卡洛控制的改进 (Improvements to Monte Carlo Control)
In the previous post we have introduced how the Monte Carlo control algorithm collects a large number of episodes to build the Q-table ( policy evaluation step). Then, once the Q-table closely approximates the action-value function qπ, the algorithm uses the table to come up with an improved policy π′ that is ϵ-greedy with respect to the Q-table (indicated as ϵ-greedy(Q) ), which will yield a policy that is better than the original policy π (policy improvement step).
在上一篇文章中,我们介绍了蒙特卡洛控制算法如何收集大量情节以构建Q表( 策略评估步骤)。 然后,一旦Q表紧密接近动作值函数qπ ,该算法就会使用该表提出一个改进的策略π' ,相对于Q表为ϵ -greedy(表示为ϵ-greedy( Q) ),这将产生比原始策略π ( 策略改进步骤)更好的策略。
Maybe would it be more efficient to update the Q-table after every episode? Yes, we could amend the policy evaluation step to update the Q-table after every episode of interaction. Then, the updated Q-table could be used to improve the policy. That new policy could then be used to generate the next episode, and so on:
也许在每个情节之后更新Q表会更有效吗? 是的,我们可以修改策略评估步骤,以在每次互动之后更新Q表。 然后,可以使用更新后的Q表来改进策略。 然后可以使用该新策略来生成下一集,依此类推:

The most popular variation of the MC control algorithm that updates the policy after every episode (instead of waiting to update the policy until after the values of the Q-table have fully converged from many episodes) is the Constant-alpha MC Control.
在每个情节之后更新策略(而不是等到Q表的值已从许多情节完全收敛之后才更新策略)的MC控制算法中,最流行的变体是Constant-alpha MC Control。
恒定alpha MC控制 (Constant-alpha MC Control)
In this variation of MC control, during the policy evaluation step, the Agent collects an episode
在MC控制的这种变化中,在策略评估步骤中,代理收集事件

using the most recent policy π. After the episode finishes in time-step T, for each time-step t, the corresponding state-action pair (St, At) is modified using the following update equation:
使用最新策略π 。 在时间步长T中完成情节结束之后,对于每个时间步长t ,使用以下更新方程式修改相应的状态-动作对(St,At) :
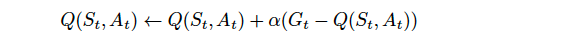
where Gt is the return at time-step t, and Q(St,At) is the entry in the Q-table corresponding to state St and action At.
其中Gt是在时间步t处的返回值 ,而Q(St,At)是Q表中与状态St和动作At相对应的条目。
Generally speaking, the basic idea behind this update equation is that the Q(St,At) element of Q-table contains the Agent’s estimate for the expected return if the Environment is in state St and the Agent selects action At. Then, If the return Gt is not equal to the expected return contained in Q(St,At), we “push” the value of Q(St,At) to make it agree slightly more with the return Gt. The magnitude of the change that we make to Q(St,At) is controlled by the hyperparameter α that acts as a step-size for the update step.
一般而言,此更新方程背后的基本思想是,如果环境处于状态St且Agent选择动作At ,则Q表的Q ( St , At )元素包含Agent对预期回报的估计。 然后,如果返回亿吨不等于预期收益包含在Q(街,在),我们的“推” Q(ST,在)的值,使之与回报亿吨略微同意。 我们对Q(St,At)所做的更改的大小由用作更新步长的超参数α控制。
We always should set the value for α to a number greater than zero and less than (or equal to) one. In the outermost cases:
我们始终应将α的值设置为大于零且小于(或等于)一的数字。 在最外层情况下:
If α=0, then the action-value function estimate is never updated by the Agent.
如果α = 0,则行动价值函数估算值永远不会由代理更新。
If α=1, then the final value estimate for each state-action pair is always equal to the last return that was experienced by the Agent.
如果α = 1,则每个状态-动作对的最终值估计始终等于代理所经历的最后一次收益。
厄普西隆贪婪政策 (Epsilon-greedy policy)
In the previous post we advanced that random behavior is better at the beginning of the training when our Q-table approximation is bad, as it gives us more uniformly distributed information about the Environment states. However, as our training progresses, random behavior becomes inefficient, and we want to use our Q-table approximation to decide how to act. We introduced Epsilon-Greedy policies in the previous post for this purpose, a method that performs such a mix of two extreme behaviors which just is switching between random and Q policy using the probability hyperparameter ϵ. By varying ϵ , we can select the ratio of random actions.
在上一篇文章中,我们提出,当我们的Q表近似值不好时,在训练开始时随机行为会更好,因为它为我们提供了有关环境状态的更均匀分布的信息。 但是,随着训练的进行,随机行为变得效率低下,我们希望使用Q表近似值来决定如何采取行动。 为此,我们在上一篇文章中介绍了Epsilon-Greedy策略,该方法执行两种极端行为的混合,仅使用概率超参数ϵ在随机策略和Q策略之间切换。 通过改变ε,我们可以选择随机行动的比率。
We will define that a policy is ϵ-greedy with respect to an action-value function estimate Q if for every state,
我们将定义一个策略 ,对于每个状态而言,对于行动值函数估计值Q 都是ϵ-贪婪 ,
with probability 1−ϵ, the Agent selects the greedy action, and
以概率1-ε,代理选择贪婪的动作,和
with probability ϵ, the Agent selects an action uniformly at random from the set of available (non-greedy and greedy) actions.
以概率ε,代理均匀地随机从所述一组可用(非贪婪和贪婪)动作中选择的动作。
So the larger ϵ is, the more likely you are to pick one of the non-greedy actions.
因此,较大的ε,越有可能你是要挑非贪婪行动之一。
To construct a policy π that is ϵ-greedy with respect to the current action-value function estimate Q, mathematically we will set the policy as
为了构建一个策略π是ε-greedy相对于当前的行动值函数估计Q,数学上,我们将设置政策

if action a maximizes Q(s,a). Else
如果动作a使Q ( s , a )最大化。 其他

for each s∈S and a∈A(s).
对于每个s∈S 和 ∈A( 多个 )。
In this equation, it is included an extra term ϵ/∣A(s)∣ for the optimal action (∣A(s)∣ is the number of possible actions) because the sum of all the probabilities needs to be 1. Note that if we sum over the probabilities of performing all non-optimal actions, we will get (∣A(s)∣−1)×ϵ/∣A(s)∣, and adding this to 1−ϵ+ϵ/∣A(s)∣ , the probability of the optimal action, the sum gives one.
在此等式中,由于最佳概率的总和必须为1,因此为最佳动作包含了额外项ϵ / ∣A( s )∣(∣A( s )∣是可能动作的数量)。如果我们总结执行所有非最佳动作的概率,我们将得到(getA(s)∣-1)×ϵ / ∣A(s)∣,并将其加到1− ϵ + ϵ / ∣A( s )∣,最佳行动的概率,总和为1。
设置Epsilon的值 (Setting the Value of Epsilon)
Remember that in order to guarantee that MC control converges to the optimal policy π∗, we need to ensure the conditions Greedy in the Limit with Infinite Exploration (presented in the previous post) that ensure the Agent continues to explore for all time steps, and the Agent gradually exploits more and explores less. We presented that one way to satisfy these conditions is to modify the value of ϵ , making it gradually decay, when specifying an ϵ-greedy policy.
请记住,为了确保MC控制收敛到最佳策略π ∗,我们需要确保无限探索中的贪婪条件(如上一篇文章所述),以确保Agent继续探索所有时间步长,而Agent会逐渐开发更多资源,而更少探索。 我们提出,要满足这些条件的一种方法是修改ε值,使得它逐渐衰减,指定ε-greedy策略时。
The usual practice is to start with ϵ = 1.0 (100% random actions) and slowly decrease it to some small value ϵ > 0 (in our example we will use ϵ = 0.05) . In general, this can be obtained by introducing a factor ϵ-decay with a value near 1 that multiply the ϵ in each iteration.
通常的做法是,以开始与ε= 1.0(100%随机动作)然后缓慢下降到一些小值ε> 0(在我们的例子中,我们将使用ε= 0.05)。 通常,这可以通过引入因子ϵ衰减来实现,该因子的衰变值接近1,并在每次迭代中将multiply相乘。
伪码 (Pseudocode)
We can summarize all the previous explanations with this pseudocode for the constant-α MC Control algorithm that will guide our implementation of the algorithm:
我们可以概括所有与此伪代码恒αMC控制算法,将引导我们实现算法的前面的解释:

一个简单的MC控制实现 (A simple MC Control implementation)
In this section, we will write an implementation of constant-
mc2180 刷机方法_MC控制和时差方法相关推荐
- 瑞芯微RK3128盒子刷机提示测试设备失败的解决方法:MASKROM模式
设备:MSIDIGTAL-RM701 平台:瑞芯微RK3128 工具:AndroidTool_Release_v2.33 在刷入过第三方固件后再刷机,就遇到了测试设备失败的问题: 苦苦寻找了很多方法都 ...
- 玩机搞机---脱离电脑 用手机给手机刷机 解锁bl 获取root的方法教程
友友们有时候手机出问题需要刷机而手头缺没有电脑的情况下该如何解决呢,今天的话题就聊聊 这方面的常识.其实类似手机给手机刷机的方法有很多,但原理都是一样的,有时候可以起到应急解决方法, 一 需要的工具与 ...
- 手机运行慢可以刷机吗_小米手机内存小速度慢?刷机不行另有三个方法
搭载Android系统或是基于Android系统深度定制ROM的智能手机,相信许多人都有这样一种感受:用到一定时候会出现运行速度慢.偶尔碰见软件闪退等现象.即便是以人性化操作为主打亮点的MIUI系统, ...
- NVIDIA Jetson Xavier NX 刷机记录(使用SDK Manager方法)
本文章仅适用于使用 SDK Manager 对 NVIDIA Jetson 系列产品进行刷机. 文章目录 准备工作 开始刷机 第一步:配置开发环境 第二步:检查组件并接受许可 第三步:安装 第四步:完 ...
- 刷机-升级到3.90M33-2的方法
3.90M33-2图文升级教程 适用机种 PSP-100X & PSP-200X 适用版本 3.52M33-3以上(核心设为3.XX 点击查看升级教程) 文件下载 CG本地下載 ; CG高速3 ...
- 苹果服务器维护不能刷机,iphone刷机失败不开机报错维修方法分享
刷苹果和苹果产品时,苹果服务器需要检查和验证苹果和苹果设备的相关硬件或参数.如果苹果服务器在验证过程中检测到相关数据错误,它就不能刷电脑,itunes软件会弹出相应的错误代码. 常见故障代码,如:硬盘 ...
- android 刷机动画,Android开机动画修改方法
该楼层疑似违规已被系统折叠 隐藏此楼查看此楼 Android开机动画有两种修改方法,android 2.0及之后,使用bootanimation程序显示开机画面,如需修改开机画面,不用修改代码,只需按 ...
- 手机刷机的几种常用方法
目录 前言 什么是刷机 什么情况下要给手机刷机 手机刷机的分类 前言 有的时候手机无法正常开机,或者是一些功能不能使用.这都是手机系统出现了问题.只要通过给手机刷机,这些都可以解决.很多人刷机一般都是 ...
- Android fastboot 基本操作命令(Android 刷机)
Android fastboot 基本操作命令(Android 刷机) 1. 控制类: #查看设备信息 fastboot devices #重启设备 fastboot reboot #重启Bootlo ...
- 小米手机--刷机指南
刷机有风险,刷机需谨慎!!! 本教程适用于小米手机,其他手机方法也类似但不建议小白按该教程的方法操作其他品牌手机. 为什么要刷机? 好处: 解决手机无缘无故重启.卡机.无法启动.无法关机.卡顿等问题. ...
最新文章
- java.lang.IllegalArgumentException: columnNames.length = 3, columnValues.length = 4
- JVM:垃圾回收概述
- React.js 小书 Lesson14 - 实战分析:评论功能(一)
- TensorFlow-CIFAR10 CNN代码分析
- Mr. Kitayuta‘s Technology CodeForces - 505D(并查集+拓扑排序或dfs找环) 题解
- spingboot下shiro自定义过滤器roles
- Myeclipse 安装所有插件
- STL之accumulate
- 4月8日及以后火车票暂停发售!
- java报错空指针异常_分析使用Spring Boot进行单元测试时,报出空指针异常
- JSONString 与 JSONData 与字典或者数组互相转化
- 图:[PPT双屏技术-知识竞赛方案策划]华中师范大学-城市与环境科学学院-城环学院地理知识竞赛胜利闭幕.
- 物体检测算法:R-CNN,SSD,YOLO 动手学深度学习v2 pytorch
- android armv7 libmp3lame.so,lame支持armv6 armv7 i386 armv7s arm64
- 剑指Offer对答如流系列 - 剪绳子
- QQ 微信转链,如何实现淘宝京东苏宁唯品会拼多多,返利转链思路
- 苹果成美国历史上市值最大公司
- IT4IT 标准助力 IT 经理控制乱局
- Chrome浏览器未连接到互联网的解决办法
- 小米平板4刷入twrp
热门文章
- 小四轴之第二次飞行篇
- ajax.net 的使用方法--摘自网上
- word多个文档标签显示在一个窗口
- OpenCV人工智能图像处理学习笔记 第6章 计算机视觉加强之机器学习中 SVM和HOG特征
- 多个文件或pdf合并生成一个Pdf
- 黑马程序员传智播客 正则表达式学习笔记 匹配单个字符多个字符
- 《图解算法》第10章之 k最近邻算法
- Atitit 数据库抽象层jdbc pdo ado.net等比较与异常点 目录 1. 应该具有的功能 1 1.1. 元数据 API 1 1.2. 分布式事务 vs事务中使用 Savepoint 1
- Atitit 功能扩展法细则条例 目录 1. 界面ui扩展 2 1.1. 使用h5做界面 2 1.2. 自制h5 ide。。简化ui自定义配置 2 2. 业务逻辑扩展 2 2.1. Bpm流程引擎还
- Atitit 标签式tab 切换的实现 Softdev=declare+intercept 申明+解释 软件=代码+文档 软件=数据结构+算法 软件=程序+数据+文档 申明式 decla