(图文)HBASE的知识点以及工作原理的详细解释--架构
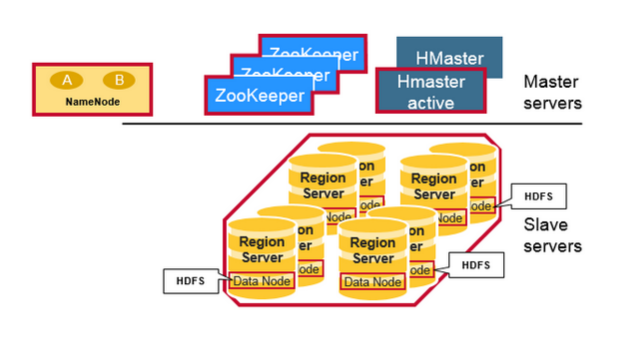
HBase架构组件
从物理结构上讲,HBase由三种类型的服务器构成主从式架构。Region Servers为数据的读取和写入提供服务。当访问数据时,客户端直接和Region Servers通信。Region的分配,DDL (create, delete tables)操作有HBase Master进程处理。Zookeeper是HDFS的一部分,维护着一个活动的集群。
Hadoop DataNode 存储着Region Server所管理的数据。所有的HBase数据存储在HDFS的文件中。Region Server和HDfs DataNode并置在一起,这使得RegionServers所服务的数据具有数据局部性(使数据接近需要的位置)。HBase数据在写入时是本地数据,但是当Region移动时,在压实之前它不是本地数据。
NameNode维护构成文件的所有物理数据块的元数据信息。
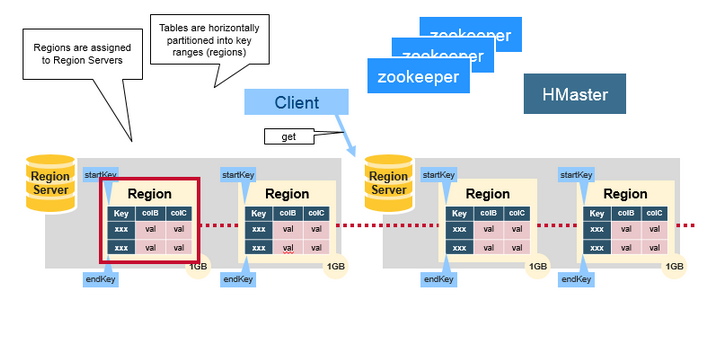
Regions
HBase表是按照rowkey范围水平划分为“Regions”.Region包含表中start key和end key之间的所有行。Region Server将Regions分配到集群的节点中,并对数据的读取和写入提供服务。单个Redion Server可服务大约1000个region。
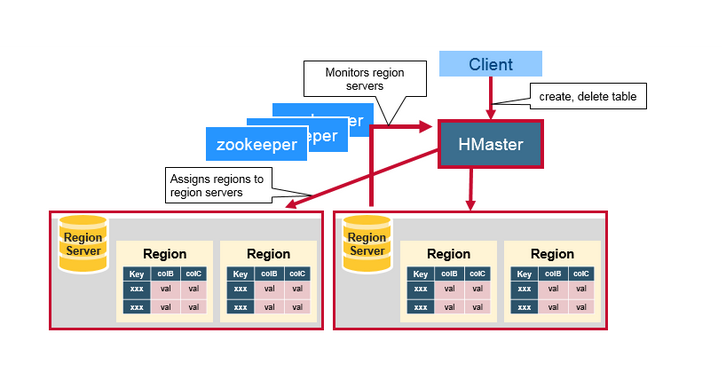
HBase HMaster
Region分配,DDL(create, delete tables)操作由HBase Master处理。
Mater的主要职责:
协调Region Servers
启动时分配Region,还原时重新分配Region或者负载均衡
监控集群中所有RegionServer实例(监听Zookeeper的消息)
管理员方法
提供创建,删除,更新表的接口。
ZooKeeper: The Coordinator
HBase使用Zookeeper做为分布式协调服务来维护及群众server的状态。Zookeeper维护处于活状态并可使用的Severs,并提供Server故障通知。Zookeeper使用共识来保证共同共享的状态。请注意,应该有三到五台机器达成共识。
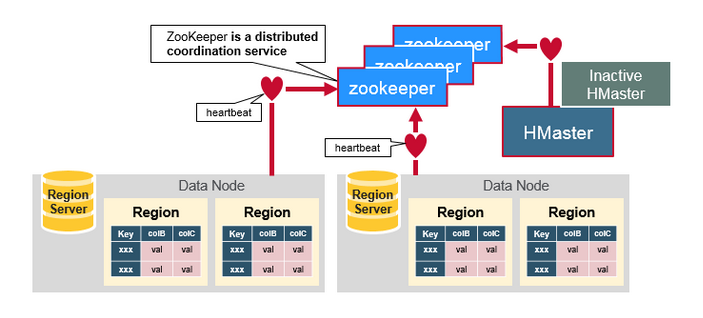
How the Components Work Together(组建如何协调工作)
Zookeeper用于协调分布式系统成员的共享状态信息。Region Server和active HMaster通过会话链接到Zookeeper.ZooKeeper通过心跳维护会话活动的临时节点。
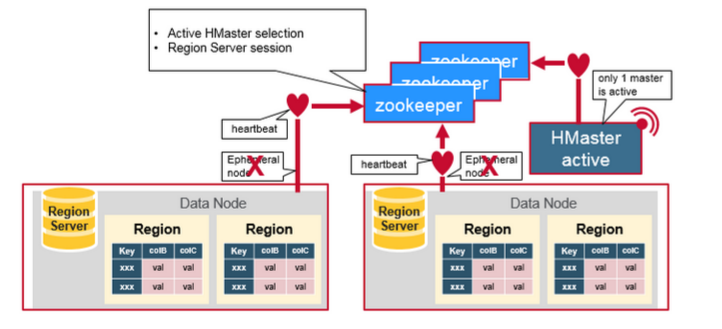
每个Region Server创建一个临时节点。HMaster监控这些节点以发现可用的region servers,并监控这些节点的服务器故障。
HMaster监控这些节点以发现可用的区域服务器,并监控这些节点的服务器故障。HMasters争夺创造一个短暂的节点。Zookeeper确定第一个并使用它来确保只有一个主站处于活动状态。 活动HMaster将心跳发送到Zookeeper,非活动HMaster将监听活动HMaster故障的通知。如果region server或者actice HMaster未能发送心跳信号,则会话过期并删除相应的临时节点。Listeners的更新在收到节点删除的通知后。Active HMaster监听region servers,并在region servers出现故障时进行恢复。Inactive HMaster监听active HMaster故障,并且如果active HMaster故障时,inactive HMaster编程active状态。
Base First Read or Write
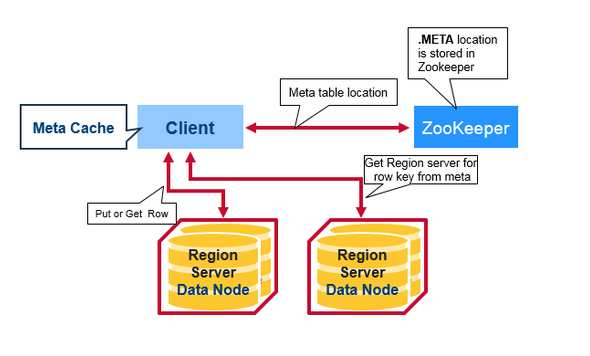
HBase有一个叫做META的特殊的目录表,用于保存集群中regions的位置信息。Zookeeper存储着META表的位置。
以下是客户端第一次读取和写入HBase时发生的情况:
1.客户端从zookeeper中META Table的位置.
2.客户端查询.META。服务器获取客户端想要访问的并且是rowkey所相对应Region Server的信息。客户端会将META缓存带本地。
3.从相应的Region Server获取行
在未来的读取操作过程中,客户端使用Meta Cache来检索META Table的位置和之前读取的Row Keys。随着时间的推移,不再需要查询META table了,除非应为一个region转移而错过,那么它将重新查询并更新Meta Cache。
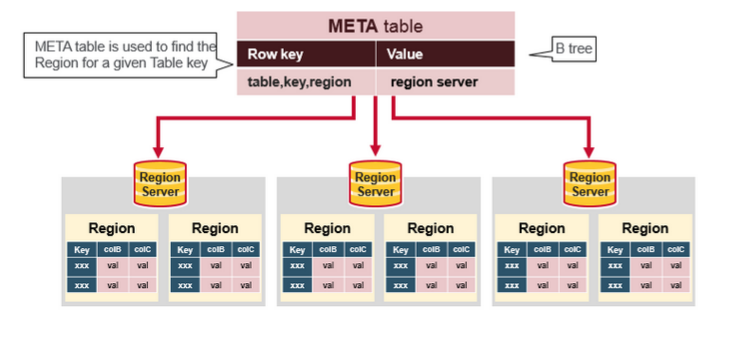
HBase Meta Table
1.META表是一个保存的了系统中所有region列表的HBase表。
2.META表就像一颗B—tree
3.METa的结构如下:
Key: region start key,region id
Values: RegionServer
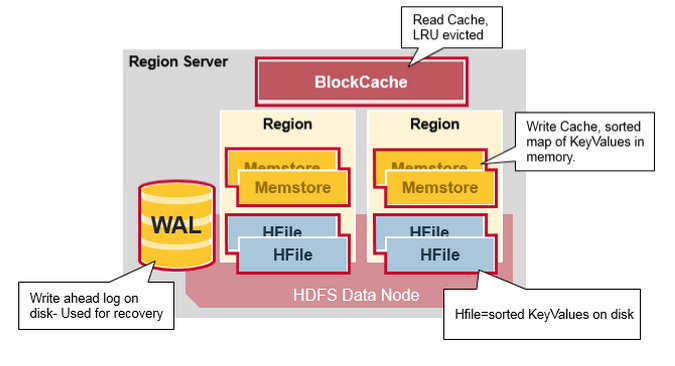
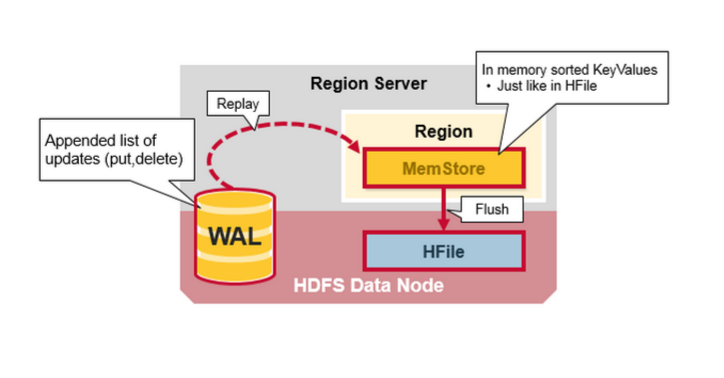
Region Server Components
Region Server运行在HDFS的DataNode,并且具备以下组件:
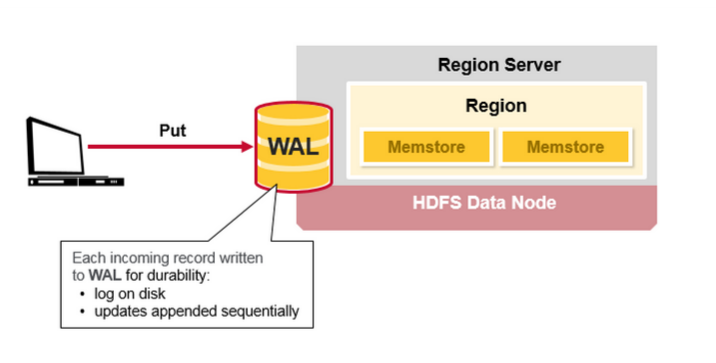
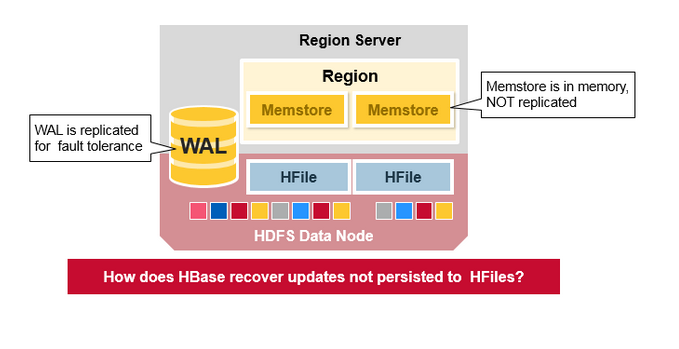
1.WAL:预写日志是分布式文件系统上的文件。WAL用于存储尚未被永久保存的新数据,用于故障情况下的恢复。
2.BlockCache: 是读取缓存。在内存中存储频繁读取的数据,近期最少使用的数据在满时被删除。
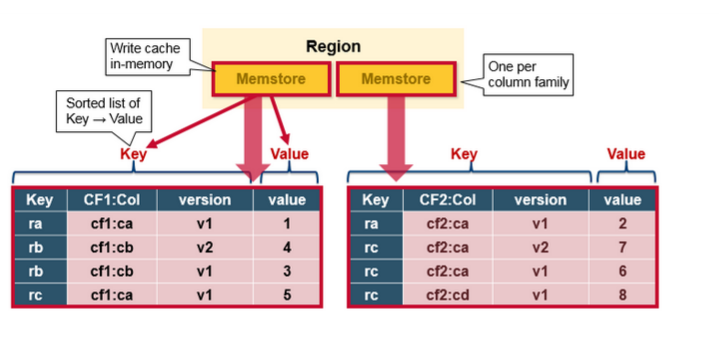
3.MemStore:是写入缓存。存储尚未写入磁盘的数据。在写入磁盘之前进行排序,每个region的每个column family有一个MemStore。
4.在磁盘上,Hfiles将行存储为已排序的KeyValues。
HBase Write Steps (1)
当客户端发起Put请求时,第一步是将数据写入于写日志,WAL:
1.发布的内容将被添加到存储在磁盘上的WAL文件末尾。
2.WAL用于在服务器崩溃的情况下恢复尚未保存的数据。
HBase Write Steps (2)
一旦数据写入WAL,将会被写入MemStore中,然后放入Put请求确认信息返回给客户端。
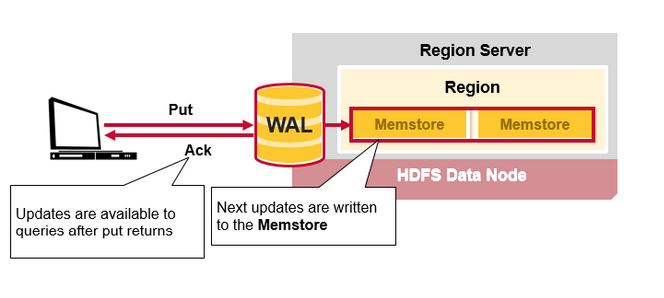
HBase MemStore
MemStore 将更新的内容排序并以KeyValues的形式存储到内存中,与将其存储在HFile中相同。每个列族只有一个MenStorre,更新内容按照列族排序。
HBase Region Flush
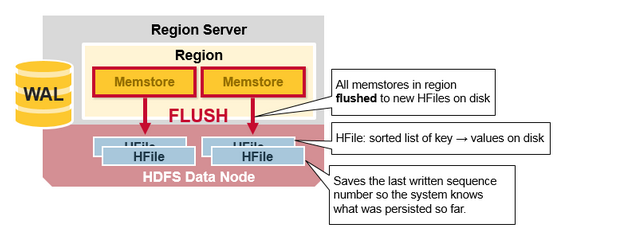
当MemStrore积聚了足够的数据,整个有序集合被写入到HDFS的HFile中。HBase每个列族使用多个HFile,其中包含真正的Cell或者KeyValue实例。随着时间的推移,在MenStore中跟据KeyValue排序,最终刷新到磁盘HFile文件中。
注意这也是HBase为什么限制列族数量的一个原因。每个列族只有一个MemStore;当一个MemStore数据满了,会刷新到磁盘文件中。它还保存了最近写入的序列号,以便让系统知道到目前为止持久化的情况。
高位序列号作为元字段存储在每个HFile中,以反映持久化结束位置以及继续执行的位置。在region启动时,序列号被读取后,然后最高位做为新编辑内容的序列号。
HBase HFile
数据存储在HFile中,其中包含排序的Key/Value。当MemStore累积足够的数据时,整个已排序的KeyValue集将被写入HDFS中的新HFile。这是一个顺序写入。它速度非常快,因为它避免了移动磁盘驱动器磁头。
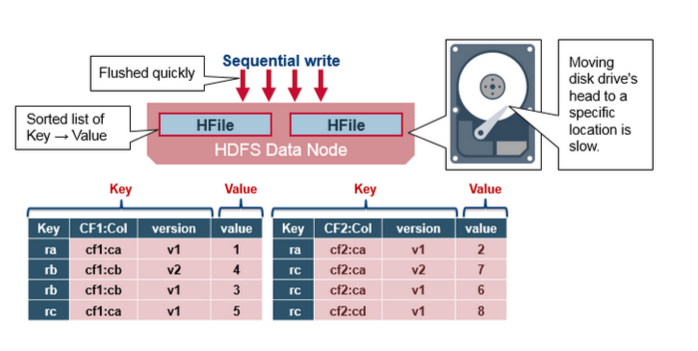
HBase HFile Structure
HBase包含一个多层索引,是HBase不必读取整个文件的情况下查找定位数据。多级索引就像一颗b+tree:
1.键值对按照升序存储
2.索引通过RowKey指向内容为key/value的64kb大小的block中。
3.每个block都有自己叶子索引
4.每个block的最后的key放进intermediate index(中间索引)
5.根索引指向中间索引
trailer指向元数据块,它写在文件中持久化数据的末尾。trailer也包含布隆过滤器和时间范围信息。布隆过滤器有助于跳过不包含某个row key的文件。如果时间范围信息不在读取的时间范围内,则时间范围信息对于跳过该文件非常有用。
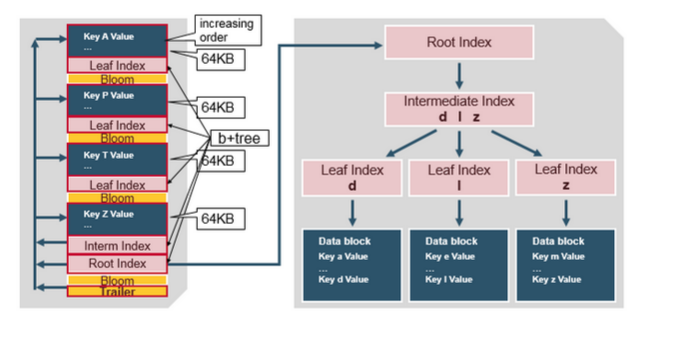
HFile Index
我们刚才讨论的索引是在HFile打开并保存在内存中时加载的。这允许查找通过单个磁盘寻道来执行。
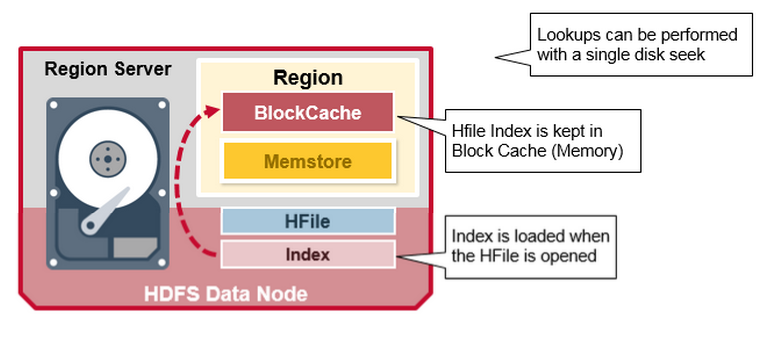
HBase Read Merge
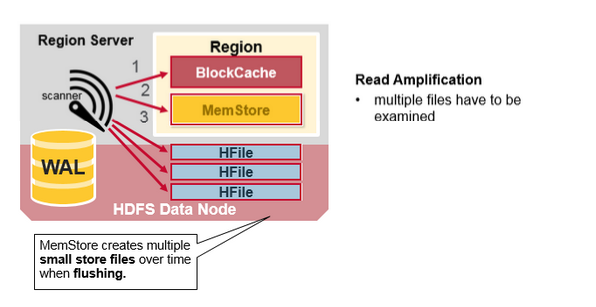
我们已经看到,row对应的KeyValue cell可以在多个位置,row cell已经持久化到Hfile中,最近更新的cell在MemStore中,最近读取的cell在Block Cache中。因此,当读取一行数据时,系统是如何获得相应的cell并返回的?读取操作按照以下步骤从BlockCache,MemStore和HFile合并关键值:
首先,扫描器在BlockCache(读取缓存)中,查找Row Cells。最近读取的Key Values被缓存在这里,并且当需要内存时,最近最少使用的被清除。
其次,扫描器在MemStore中查找,内存写入缓存包含最近的写入。
如果扫描器在MenStore和BlockCache中没有找到Row cells,然后HBase使用BLock Cache的HFile索引和布隆过滤器把可能存在目标Row cells的HFile加载到内存中。
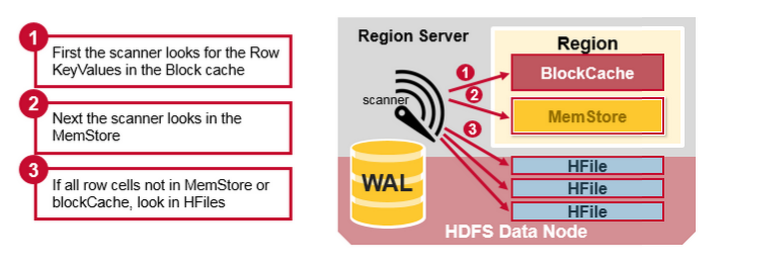
HBase Read Merge
正如前面所讨论的,每个MemStore可能有许多HFile,这意味着读取时可能需要检查多个HFile文件,这可能会影响性能。这被称为读取放大。
HBase Minor Compaction
HBase会自动选择一些较小的HFile,并将它们重写成更少且更大的Hfiles。这个过程称为Minor Compaction。Minor Compaction通过将较小的文件重写为较少但较大的文件来减少存储文件的数量,执行合并排序。
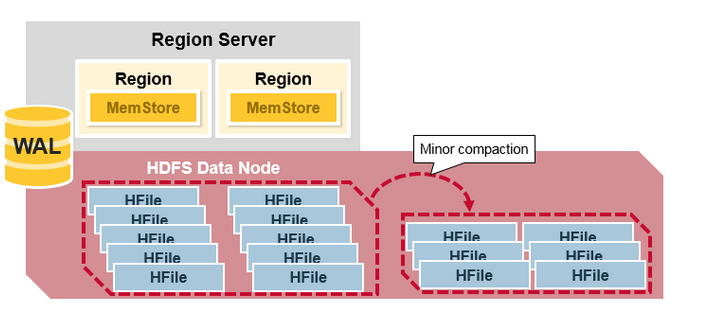
HBase Major Compaction
Major compaction将region所有的HFile合并并重写到一个HFile中,每个列族对应这样的一个HFile。并在此过程中,删除已删除或过期的Cell。这样提升了读取性能,由于Major compaction重写了所有HFile文件,因此在此过程中可能会发生大量磁盘I/O和网络流量。这被称为写入放大。
Major compaction执行计划可以自动运行。由于写入放大,通常计划在周末或晚上进行Major compaction。由于服务器故障或负载平衡,Major compaction还会使任何远程数据文件成为本地服务器的本地数据文件。
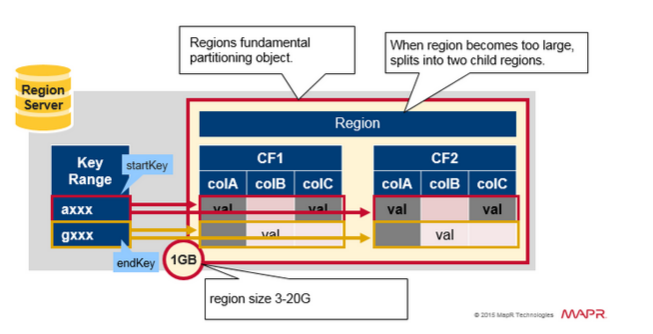
Region = Contiguous Keys
快速回顾一下region:
表格可以水平划分为一个或者多个region。早start key和end key之间包含连续的,排序的行范围。
每个region小为1GB(默认)
表的region通过RegionServer为客户端提供服务。
RegionServer可以提供大约1,000个region(可能属于同一个表或不同的表)
Region Split
最初每个表格有一个区域。当一个region变得太大时,它会分裂成两个子region。代表原region的一半的两个子region,在相同的RegionServer上并行打开,然后将分区报告给HMaster。由于负载平衡的原因,HMaster可以安排将新region移动到其他服务器。
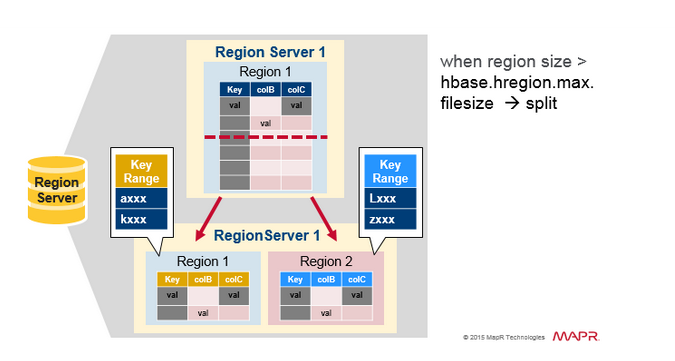
Read Load Balancing
分裂最初发生在同一个RegionServer上,由于负载平衡的原因,HMaster可以安排将新region移动到其他服务器。这导致新RegionServer提供服务的数据来自远程HDFS节点,直到Major compaction将数据文件移动到RegionServer的本地节点。HBase数据在写入时是本地数据,但当某个区域被移动时(为了负载平衡或恢复),在Major compaction之前它不是本地数据。
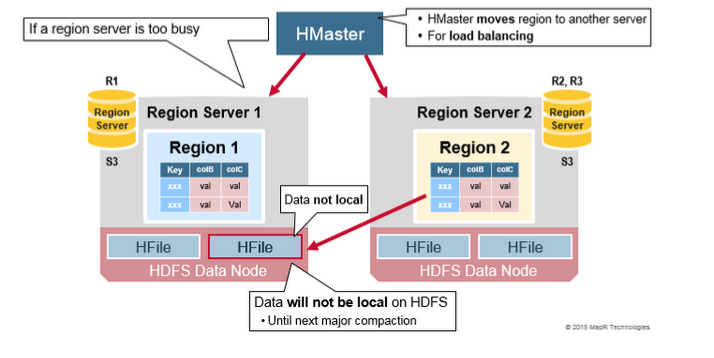
HDFS Data Replication
所有的写入和读取都来自主节点。HDFS复制WAL和HFile块。HFile块复制自动发生。HBase依靠HDFS在存储文件时提供的数据安全性。在HDFS中写入数据时,本地写入一个副本,然后将其复制到第二个节点,并将第三个副本写入第三个节点。
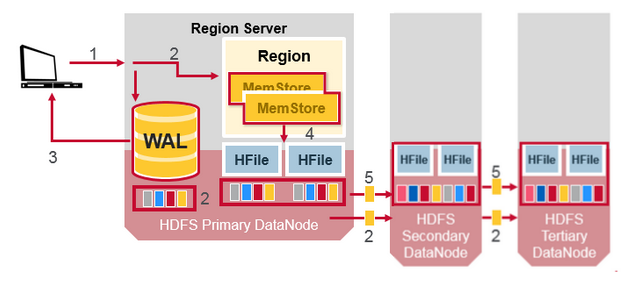
HDFS Data Replication (2)
WAL文件和HFiles文件被持久化到磁盘并复制,那么HBase如何恢复没有报持久化到HFile的MemStore更新呢?请参阅下一节寻找答案。
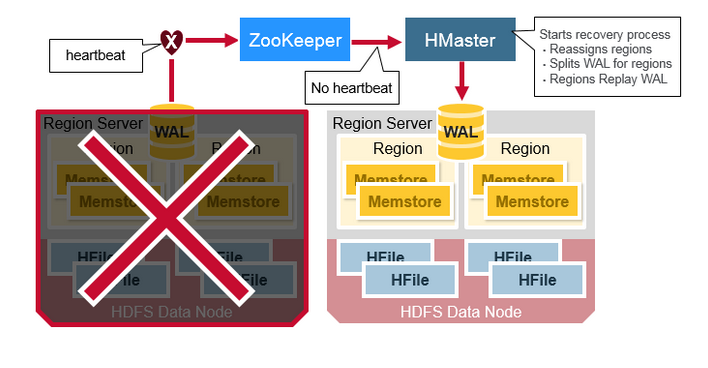
HBase Crash Recovery
当RegionServer失败时,崩溃的region将不可用,直到检测和恢复步骤发生。 Zookeeper会在失去与RegionServer心跳信号时确定节点故障。 HMaster将会被通知Region Server失败。HMaster将会被通知Region Server失败。
当HMaster确定RegionServer宕机时,HMaster重新分配宕机服务器的Region到活动的服务器。为了恢复宕机服务器未刷新到磁盘的memstore数据,HMaster将属于宕机RegionServer的WAL拆分成单独的文件并将这些文件存储在新RegionServer的数据节点中。每个Region Server然后进行重播WAL,从相应的WAL拆分文件,为region重建MemStore。
WAL的文件包含编辑列表,其中一个编辑表示单个放置或删除。一个编辑表示一个放置或删除。编辑按时间顺序编写,因此,对于持久化,添加内容将附加到存储在磁盘上的WAL文件的末尾。
如果数据仍在内存中并且未保存到HFile时发生故障会发生什么?WAL重播,重播WAL的过程是通过读取WAL,添加或者排序已知的编辑到当前MemStore。最后,Memtore将变化刷新到HFile。
Data Recovery
Apache HBase Architecture Benefits
HBase 优点:
1.强一致性模型
当写入返回时,所有读者将看到相同的值
2.自动扩展
数据增长过大时分割region
使用HDFS传播和复制数据
3.内置恢复机制
使用预写日志 (与文件系统上的日记类似)
4.集成Hadoop
MHBase上的MapReduce很简单
Apache HBase Has Problems Too…
Business continuity reliability:
1.WAL 重播缓慢
2.意外恢复缓慢
3.Major Compaction I/O 风暴
文章来源:http://www.uml.org.cn/bigdata/201804131.asp
(图文)HBASE的知识点以及工作原理的详细解释--架构相关推荐
- MapReduce的工作原理,详细解释WordCount程序
本篇文章主要说两部分:简单介绍MapReduce的工作原理:详细解释WordCount程序. MapReduce的工作原理 在<Hadoop in action>一书中,对MapReduc ...
- 计算机网络之交换机的工作原理---超详细解析,谁都看得懂!!
在了解交换机的工作原理之前,我们先要了解几个概念. 一.相关概念 1.OSI七层模型是哪七层? 自上而下分别是: 应用层 表示层 会话层 传输层 网络层 数据链路层 物理层 交换机工作在数据链路层, ...
- 路由器的工作原理,详细介绍
1.路由器的作用 路由器: router 作用:实现跨网段通信,不同的网络之间通信 交换机: switch 作用:组建局域网,就是将电脑通过网络连起来 交换机的原理参考文档:计算机 ...
- Zookeeper工作原理(详细)
1.Zookeeper的角色 领导者(leader),负责进行投票的发起和决议,更新系统状态 学习者(learner),包括跟随者(follower)和观察者(observer) follower用于 ...
- 增量式编码器工作原理超详细图解
旋转编码器是由光栅盘(又叫分度码盘)和光电检测装置(又叫接收器)组成.光栅盘是在一定直径的圆板上等分地开通若干个长方形孔.由于光栅盘与电机同轴,电机旋转时,光栅盘与电机同速旋转,发光二极管垂直照射光栅 ...
- k型热电偶材料_k型热电偶工作原理及详细参数
K型热电偶作为一种温度传感器,K型热电偶通常和显示仪表,记录仪表和电子调节器配套使用.K型热电偶可以直接测量各种生产中从0℃到1300℃范围的液体蒸汽和气体介质以及固体的表面温度. K型热电偶是目前用 ...
- sever串口wifi拓展板_串口Wifi模块的工作原理和详细功能介绍
在无线网络领域里面,无线wifi是最火的名词.对于串口wifi模块的工作原理是什么呢?串口wifi模块又有什么功能呢?wifi方案设计远嘉科技给大家讲解有关串口wifi模块的工作原理,以及详细功能介绍 ...
- 关于协议转换器的分类以及工作原理的详细介绍
现如今,随着互联网的广泛应用,我们国内的网民也是突破了8.29亿,相信,大家对于网络这块是非常的熟悉了,它是一种虚拟的东西,但是它几乎存在于我们生活的各个角落,在很大程度的让我们的日常生活变得便捷与丰 ...
- HTTP协议工作原理及详细介绍
HTTP协议简介: 什么是超文本? 包含有超链接(Link)和各种多媒体元素标记的文本.这些文本文件彼此链接,形成网状(Web),因此又被称为网页.这些链接使用URL表示.最常见的超文本格式是超文本标 ...
最新文章
- vfp中,函数subs(计算机管理信息系统,7)返回的结果是,VFP选择题库(可发学生).xls...
- java游戏下载ios_java浏览器下载
- HTC One 802w(联通双卡版本)刷机过程(只是记录大概的过程,网上已经有各步骤的详细过程)...
- C++中基于范围的for循环
- pdo 封装增删改查类
- Cocos2d-x3.1FileUtilsTest使用
- spring mvc学习(15)Referenced file contains errors
- 【NOIP 模拟赛】 道路
- 根据用户id查询菜单列表(菜单权限问题)
- Highcharts x轴为时间时,设置plotBands
- Android开发笔记(一百一十一)聊天室中的Socket通信
- 深入浅出MFC.pdf
- Linux中vim命令详解
- 解决使用Glide加载图片背景出现浅绿色
- 计算机蓝屏代码0xc0000020,Win10打开软件提示“损坏的映像 错误0xc0000020”的解决方法...
- 接口文档规范有哪些?
- android向DDR读写数据,透过数据看本质 - 被“吹爆”的LPDDR5内存究竟有多强大?...
- 微软对联服务器关闭了吗,不只对联,现在微软还能自动生成绝句
- ST-LINK/V2 烧录固件
- 给未来的你 — 李开复在2011级大学新生学习规划讲座上的演讲