分布式系统架构的基本原则和实践
采用分布式系统架构是由于业务需求决定的,若系统要求具备如下特性,便可考虑采用分布式架构来实现:
1.数据存储的分区容错,冗余
2.应用的大访问、高性能要求
3.应用的高可用要求,故障转移
分布式系统遵循几个基本原则
1.CAP原理
分布式系统架构的实践
1.分布式存储架构
分布式存储架构现阶段有3种模式
1.1一种是物理存储采用集中式,存储节点采用多实例的方式,如NFS挂载SAN、NAS等等
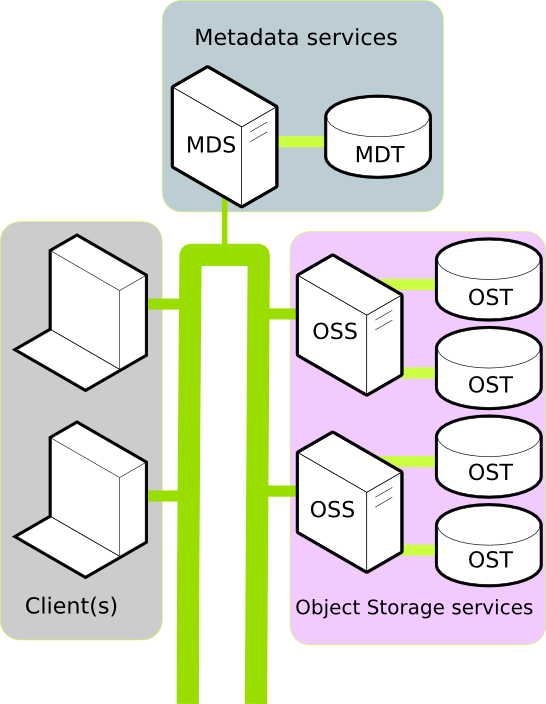
2.分布式数据库
分布式系统架构的基本原则和实践相关推荐
- 《架构设计2.0大型分布式系统架构方法论与实践》三高笔记
目录 前言 高并发 高并发读 动静分离与CDN加速 缓存 并发读与Pipeline 重写轻读 读写分离 批量 高并发写 数据分片 任务分片 异步化 批量 高可靠 七板斧 高可用 高可用架构几个核心问题 ...
- 左耳朵耗子:聊聊分布式系统架构
点击关注 InfoQ,置顶公众号 程序员的 8 点技术早餐 作者|陈皓 编辑|杨爽 学习任何技术,善于提纲挈领总是事半功倍.学习分布式系统架构也是如此,只要找到这张网的纲,就能更有效率地做好架构和工程 ...
- 美团即时物流的分布式系统架构设计
背景 美团外卖已经发展了五年,即时物流探索也经历了3年多的时间,业务从零孵化到初具规模,在整个过程中积累了一些分布式高并发系统的建设经验.最主要的收获包括两点: 即时物流业务对故障和高延迟的容忍度极低 ...
- 美团外卖分布式系统架构设计
背景 美团外卖已经发展了五年,即时物流探索也经历了3年多的时间,业务从零孵化到初具规模,在整个过程中积累了一些分布式高并发系统的建设经验.最主要的收获包括两点: 即时物流业务对故障和高延迟的容忍度极低 ...
- 分布式系统架构与云原生—阿里云《云原生架构白皮书》导读
-点击领取<云原生架构白皮书>- 导语: 有幸作为阿里云MVP提前获得了阿里云云原生团队编写的<云原生架构白皮书>,希望通过自己对于云原生的理解为开发者提供一篇观后感或者是能够 ...
- 大规模 Node.js 网关架构设计与工程实践
作者:王伟嘉,腾讯云 CloudBase 前端负责人. 本文是王伟嘉在 GMTC 2021 全球大前端技术大会(深圳站)上的演讲内容:<十亿级 Node.js 网关的架构设计与工程实践>. ...
- 《大规模分布式系统架构与设计实战》
<大规模分布式系统架构与设计实战> 基本信息 作者: 彭渊 丛书名: 大数据技术丛书 出版社:机械工业出版社 ISBN:9787111455035 上架时间:2014-2-21 出版日期: ...
- #分布式系统架构之# 事件驱动模式以及与之匹配的长时间处理过程讨论
为什么80%的码农都做不了架构师?>>> 在分布式系统下,可以很多种架构从事设计,或者分布式系统对技术架构本身没有做严格的限制.但是结合自己的实践以及基于<领域驱动设计& ...
- 腾讯云十亿级 Node.js 网关的架构设计与工程实践
作者|王伟嘉 编辑|孙瑞瑞 本文由 InfoQ 整理自腾讯云 CloudBase 前端负责人王伟嘉在 GMTC 全球大前端技术大会(深圳站)2021 上的演讲<十亿级 Node.js 网关的架构 ...
最新文章
- [分享] 数学学术资源站点
- RabbitMQ之惰性队列(Lazy Queue)
- spring boot 单元测试_spring-boot-plus1.2.0-RELEASE发布-快速打包-极速部署-在线演示
- Java基础笔记 – Annotation注解的介绍和使用 自定义注解
- .NET简谈组件程序设计之(渗入序列化过程)
- ubuntu 设置定时任务
- 数据结构第三章栈和队列(一)
- phpstorm配置ftp,自动更新代码
- nios IIcommand shell 烧录
- 如何在Word中画横线?
- Matlab syms 矩阵变量,matlab syms.m
- 自动化爬取网贷黑名单
- pgsql 日期转换
- 确定权重方法之一:主成分分析
- 图片文字转换为文本怎么做?图片转文本的简单方法介绍
- IDEA工具避坑指南(七):git@github.com: Permission denied|You must supply a key in OpenSSH public key format详解
- B. Dubious Cyrpto
- Element-Ui组件 Radio 单选框 修改点击激活时的文本颜色,填充色和边框色
- VB / VBA 自制二维码小工具
- Android的鼠标事件流向