利用已有的大数据技术,如何构建机器学习平台
机器如何学习?
\\
人脑具备不断积累经验的能力,依赖经验我们便具备了分析处理的能力,比如我们要去菜场挑一个西瓜,别人或者自己的经验告诉我们色泽青绿、根蒂蜷缩、纹路清晰、敲声浑响的西瓜比较好吃。
\\
我们具备这样的能力,那么机器呢?机器不是只接收指令,处理指令吗?和人脑类似,可以喂给机器历史数据,机器依赖建模算法生成模型,根据模型便可以处新的数据得到未知属性。以下便是机器学习与人脑归纳经验的类别图:
\\
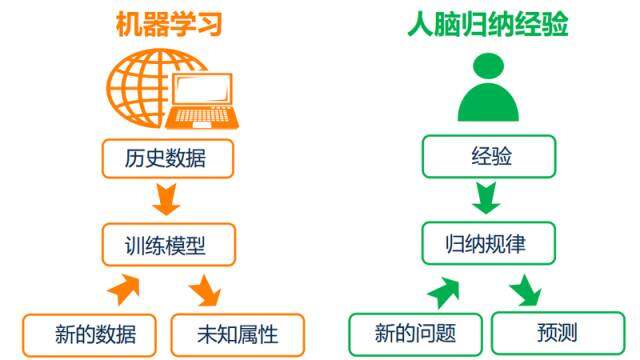
\\
平台设想
\\
在同程内部,我们对应用机器学习的一些团队做了了解,发现他们普遍的处理步骤如下:
\\

\\
这个过程中存在一些痛点:
\\
- 线上数据到线下搬运耗时\\t
- 训练数据量难均衡,如果训练数据量较大,用 R 或者 Python 做单机训练将会非常耗时。如果训练数据量较小,训练出来的模型容易过拟合。\\t
- 对分析和挖掘人员的编码能力有一定的要求。\
因此我们觉得可以构建一套平台化的产品直接对线上数据进行建模实验,节省机器学习的开发成本,降低机器学习的应用门槛。
\\
平台构建
\\
设计目标
\\
- 支持大数据量的建模实验,通过并行计算缩短耗时\\t
- 抽象出最小执行单元,配置简单。通过拖拽以及连线的形式构建建模流程\\t
- 支持常用的机器学习学习算法处理回归、分类、聚类等问题支持常用的特征工程组件,如标准化、归一化、缺失值处理等\\t
- 支持算法评估结果可视化\
算法库
\\
在算法库方面,我们选择了 Spark,相比于 R 或者 Python,Spark 具备分布式计算的能力,更高效。
\\
ml 和 mllib 都是 Spark 中的机器学习库,目前常用的机器学习功能两个个库都能满足需求。ml 主要操作的是 DataFrame,相比于 mllib 在 RDD 提供的基础操作,ml 在 DataFrame 上的抽象级别更高,数据和操作耦合度更低。
\\
ml 提供 pipeline,和 Python 的 sklearn 一样,可以把很多操作 (算法 / 特征提取 / 特征转换) 以管道的形式串起来,对于任务组合非常便利,如 StringToIndexer、IndexerToString、VectorAssembler 等。
\\
组件化设计
\\
从架构设计上来说,不管是算法单元、特征工程单元、评估单元或者其他工具单元,我们认为都可以以组件的形式来设计。借助通用的接口行为以及不同的实现可以达到松耦合、易扩展的目的。
\\
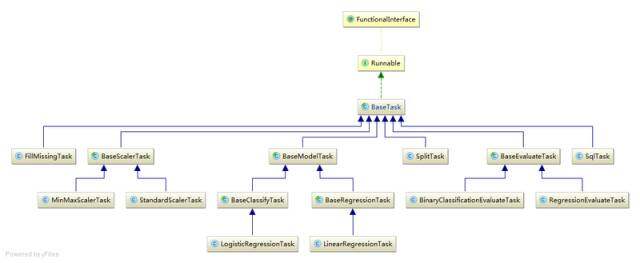
\\
上图是整个设计类图的一部分,实际上我们做了较多层次的抽象以及公用代码。下面看看核心类 BaseTask:
\\

\\
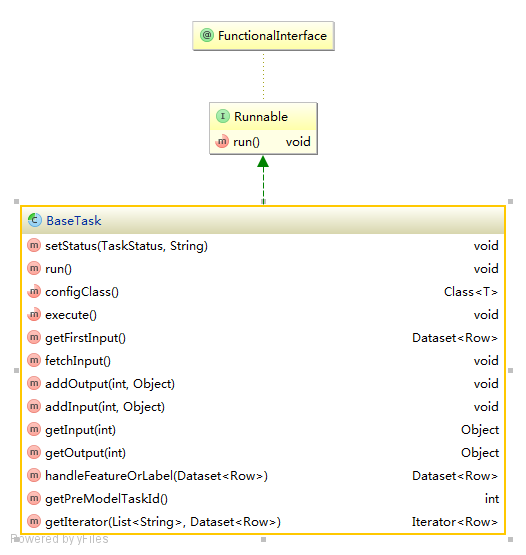
\\
run 方法的实现是一套模板,步骤如下:
\\

\\
每个组件只要实现自己的核心逻辑 execute 方法就可以了。
\\
平台迭代
\\
v1.0(平台核心架构)
\\
基于上述的设计目标,机器学习平台第一个版本的架构如下:
\\
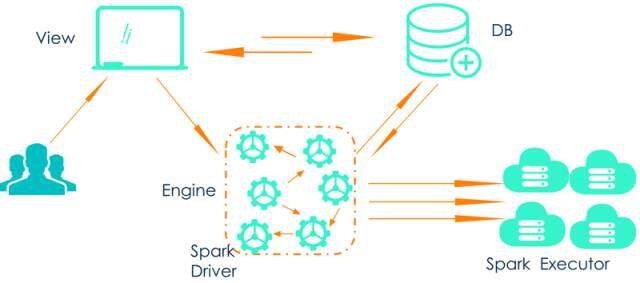
\\
- 用户通过界面拖拽组件构建建模流程,并将组件配置以及依赖关系保存到 DB 中\\t
- 用户可以在界面上触发建模试验的运行,实际上通过 spark-submit 提交一个 spark 任务\\t
- Ml Engine 负责这个任务的执行,在 Driver 端会从 DB 中获取当前试验的依赖组件以及流程关系。这些组件将依次运行,涉及 RDD 相关的操作时会提交到 Spark Executor 进行并行计算\
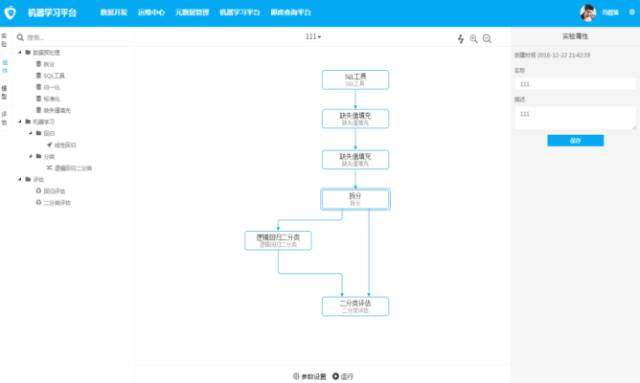
流程 \u0026amp; 评估视图
\\
\\
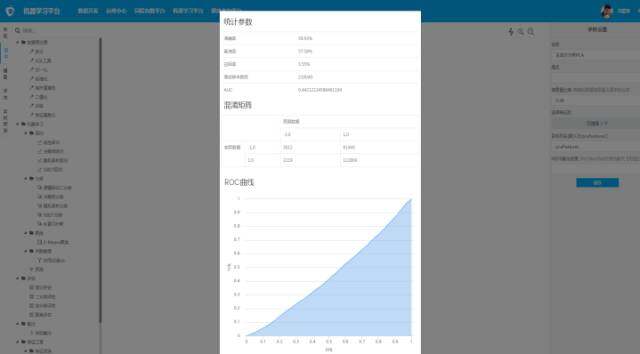
\\
第一个版本我们并没有提供太多的算法组件,只有线性回归和逻辑回归,但是基于组件化的思想,我们非常有信心在后期快速迭代。
\\
除了算法较少外,结合业务反馈与自身思考。我们觉得机器学习平台可以做更多的事:
\\
- 平台定位不仅仅是实验控制台,增加预测结果落地的功能(离线计算)\\t
- 训练模型随着历史数据的不断扩充在大部分情况下都应该是个周期性的事情。我们希望在平台层面能够帮助用户托管这个过程。\
v2.0(扩充组件 \u0026amp; 离线计算 \u0026amp; 周期性调度)
\\
第二个版本中,我们首先基于原有的设计框架扩充完善了相关实用组件:
\\

\\

\\
同时在第二个版本中,我们在细节上又做了一些完善:
\\
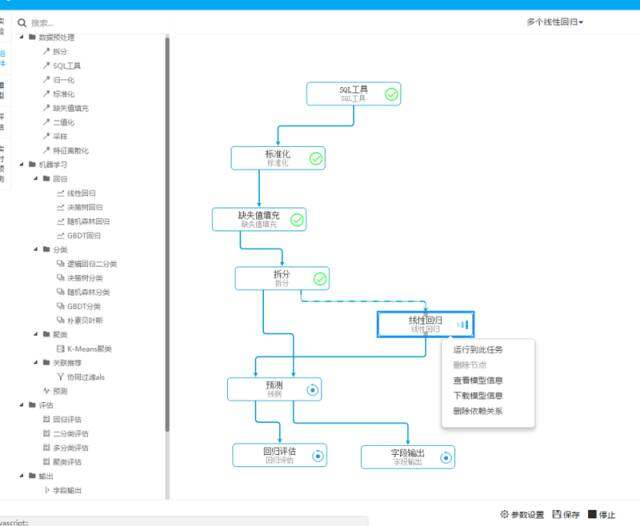
\\
- 建模实验运行状态流程展示,用户可以观察到每个组件的运行时间,状态,日志等\\t
- 依赖完整的组件可以进行局部运行,在一个较复杂的建模实验中,完全可以先进行局部验证以及参数调整\\t
- 建模实验支持克隆\
离线计算
\\
我们提供了‘字段落地’的工具组件,可以将预测结果以 csv 的格式落入 hdfs 中:
\\
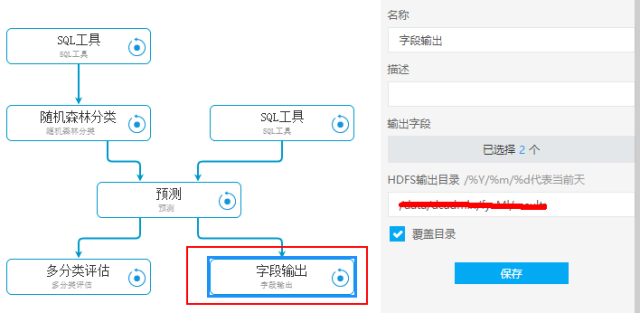
\\
周期性调度 \u0026amp; 宏变量支持
\\
我们的另一款产品:大数据开发套件(BDK),函盖周期性调度的功能,机器学习平台的建模实验可以以子任务的形式嵌入其中,结合宏变量(某种规则的语法替换,例如’/%Y/%m/%d’可以表示为当前天等等)用户可以在我们的平台中托管他们的建模试验,从而达到周期性离线计算的目的。
\\
架构
\\
综上,丰富组件及完善功能、离线计算结果落地、结合 BDK 进行周期性离线计算是我们平台第二个版本主要关注的,具体架构有了以下演进:
\\
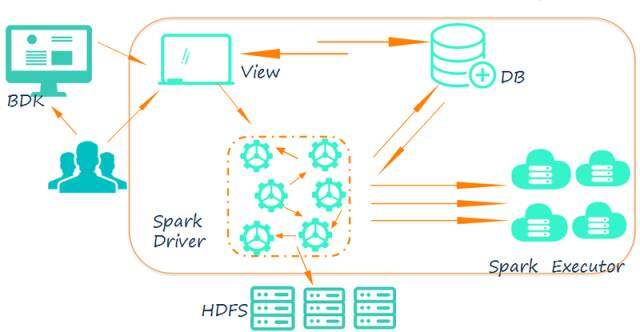
\\
v3.0(实时预测 \u0026amp; 交叉验证)
\\
实时预测
\\
在我们的平台中可以通过建模实验训练模型,模型可以通过 PMML 这样的标准导出,同样也可以通过我们的模型导出功能将模型以 parquet 格式保存在 Hdfs 相应的目录上。用户可以得到这些模型标准,自己去实现一些功能。但是我们觉得实时预测的功能在我们平台上也可以抽象出来。于是 3.0 的架构中我们开发了提供实时预测服务的 tcscoring 系统:
\\
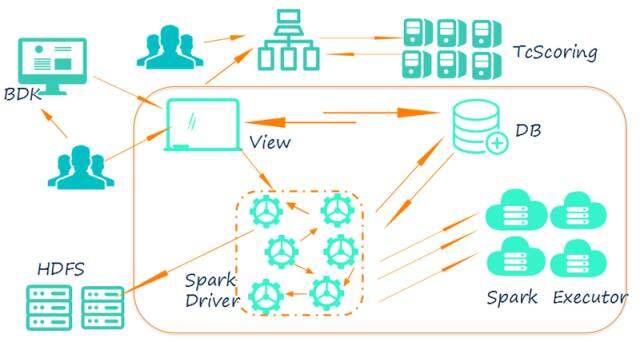
\\
tcscoring 系统的依赖介质就是模型的 PMML 文件,用户可以在机器学习平台上直接部署训练完成了的模型对应的 PMML 文件,或者通过其他路径生成的 PMML 文件。部署成功后会返回用于预测的 rest 接口供业务使用:
\\
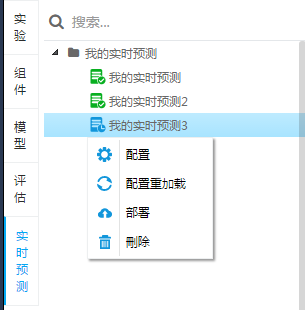
\\
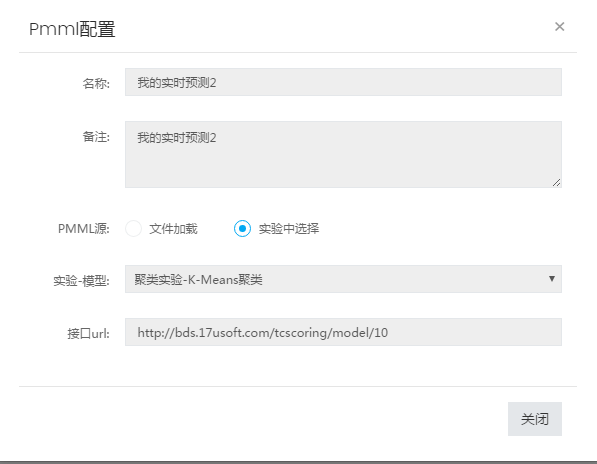
\\
当然,PMML 的部署也可以结合 BDK 设置成周期性调度,这些结合模型的周期性训练,整个训练 + 预测的过程都可以交给机器学习平台 +BDK 实现托管。
\\
交叉验证
\\
在机器学习平台的第三个版本中,我们还有个关注点就是交叉验证,之前的版本中用户一次只能实验一组超参数,有了交叉验证,用户便可以在一次实验中配置多组超参数,在训练集中在按比例进行循环拆分,一部分训练,一部分验证,从而得到最优模型:
\\
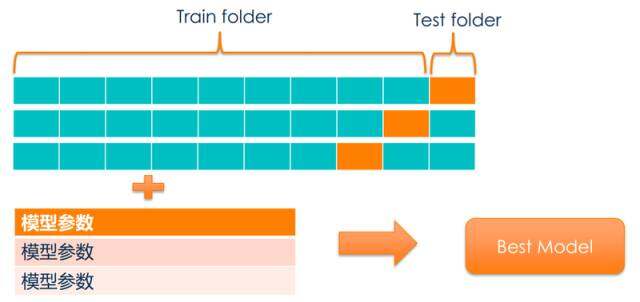
\\
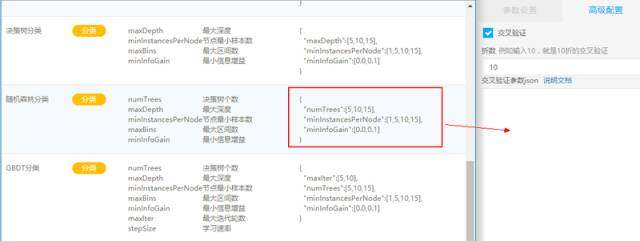
\\
平台展望
\\
个性化
\\
迭代完 3 个版本后,机器学习平台抽象出了很多通用的东西,但是还有一些个性化的东西没有办法很好地变现。我们的想法是对于用户来说,最好的个性化途径就是让用户自己写代码,我们会尝试开放接口自定义插件,同时利用动态编译技术加载这些个性化的组件,融合进建模流程中。
\\
融合其他算法包
\\
我们目前也在尝试融合 spark ml 之外的算法包,如使用度较广的 xgboost 等。另一方面目前的算法还是基于传统的机器学习算法,对于深度学习,不管是嵌入 tensorflow 还是使用一些第三方的深度学习库,如 Deeplearning4j 等。我们接下来会尝试融合这些 spark ml 之外的算法包。
\\
作者
\\
同程机器学习平台负责人,冯煜策
利用已有的大数据技术,如何构建机器学习平台相关推荐
- 基于大数据技术的综合数据分析平台
对于企业来说,利用大数据技术建立综合数据分析平台有利于企业内的管理人员更好地掌握企业的实际情况,有效控制企业的经营成本,提高企业的经济效益,同时全面提高企业的管理水平,对企业的发展有非常积极的促进作用 ...
- 百分点大数据技术团队:舆情平台架构实践与演进
编者按 现代社会每天都有大量信息产生,抖音.小红书等自媒体的普及,不断丰富着人们表达看法.传播诉求.分享信息的渠道和形式.如何完成多源异构数据的收集和处理,挖掘海量信息中的价值,洞察事件背后的观点和情 ...
- 大数据技术在跨境电商中的应用
1.大数据技术与跨境电子商务综述 (1)大数据技术.大数据量,是指数据量极大,不能使用传统的数据采集方法.传统的数据库.传统的研究方法对数据集进行分析.传统的数据分析往往采用样本,采用推理的方法,用常 ...
- 水环境模型与大数据技术融合研究
点击上方蓝字关注我们 水环境模型与大数据技术融合研究 马金锋1, 饶凯锋1, 李若男1,2, 张京1, 郑华1,2 1 中国科学院生态环境研究中心城市与区域生态国家重点实验室,北京 100085 2 ...
- 你是否很好奇腾讯大厂的大数据是怎么构建的?(文末赠书3本)
文章目录 1 写在前面 2 有点东西 3 文末福利 1 写在前面 随着<数字中国建设整体布局规划>政策落地,数字中国建设将迎来新一轮的推进,大数据产业也将迎来全新的发展.数据之所以能够成为 ...
- 借力大数据技术 证券行业迎转型契机
互联网+时代,证券行业制定大数据战略迫切而适时.一方面,近年来大数据被提升到国家发展战略层面,政府提供资金及政策支持,鼓励企业在大数据方面的发展和转型,大数据技术体系发展逐渐成熟.基于开源和商业技术共 ...
- 数据科学与大数据技术专业有哪些就业方向?
数据科学和大数据技术专业的就业方向包括: 数据分析师/科学家: 分析和挖掘大型数据集, 为公司决策提供数据支持. 数据工程师: 负责数据的收集, 存储, 处理和建模. 数据产品经理: 负责设计和管理数 ...
- 大数据舆情监测与分析平台有何作用功能及相关软件排名如何详解
大数据时代,要想及时有效精准的捕捉到与己相关的舆情数据信息,就需要运用到大数据技术,也就是专业的大数据舆情监测与分析平台.通过运用大数据舆情监测与分析平台实现全网舆情舆论信息监测搜集.但问题是现在市面 ...
- 如何利用大数据技术构建用户画像
在大数据时代,我们经常谈论的概念之一是用户画像.准确营销的商业目的可以通过在互联网领域利用用户画像来实现,这就是为什么在这个流量至上的时代构建用户画像是如此重要.任何企业公司的产品要想做好精细化运营, ...
最新文章
- python装饰器函数-python 装饰器 函数被装饰+函数执行
- 优化Nginx服务的安全配置
- Linux 最常用的脚本,值得学习收藏!
- Ubuntu开启防火墙
- Object-c 中字符串与数组的处理
- ubuntu16.04下pycharm中无法使用中文输入法
- centos7.2编译php,CentOS7.2编译安装PHP7.2.3之史上最详细步骤。
- 巩固——Vue中如何使用less和scss?
- 设计大师Donald Norman和Bill Buxton签书会在南京举行
- Affinity Publisher for Mac排版设计工具
- 毕业设计 - 题目 :基于大数据的疫情数据分析及可视化系统
- 安装驱动省心办法:驱动总裁
- PHP将swf转为gif,swf转gif 在线转换
- 小波神经网络的基本原理,小波神经网络什么意思
- qpython3打开app_QPython3
- 隐私保护联邦学习之差分隐私原理
- 微信视频号直播数据哪里可以看?
- 从零搭建WebApi接口开发框架-接口规范
- 《MATLAB语音信号分析与合成(第二版)》:第7章 语音信号的减噪
- 如何处理文字中的emoji?