分解和合并:Java 也擅长轻松的并行编程!
多核处理器现在已广泛应用于服务器、台式机和便携机硬件。它们还扩展到到更小的设备,如智能电话和平板电脑。由于进程的线程可以在多个内核上并行执行,因此多核处理器为并发编程打开了一扇扇新的大门。为实现应用程序的最大性能,一项重要的技术就是将密集型任务拆分成可以并行执行的若干小块,以便最大程度利用计算能力。
传统上,处理并发(并行)编程一直很困难,因为您不得不处理线程同步和共享数据的问题。Groovy (GPar)、Scala 和 Clojure 社区的努力已经证明,人们对 Java 平台上并发编程的语言级支持的兴趣十分强烈。这些社区都尝试提供全面的编程模型和高效的实现,以屏蔽与多线程和分布式应用程序相关的难点。但不应认为 Java 语言本身在这方面逊色。Java Platform, Standard Edition (Java SE) 5 及后来的 Java SE 6 引入了一组程序包,可以提供强大的并发构建块。Java SE 7 通过添加并行支持进一步增强了这些构建块。
下文首先简单回顾了 Java 并发编程,从早期版本以来已经存在的低级机制开始。然后在介绍 Java SE 7 中由分解/合并框架提供的新增基本功能分解/合并任务之前,先介绍 java.util.concurrent 程序包添加的丰富基元。文中给出了这些新 API 的示例用法。最后,在结束之前对方法进行了讨论。
下面,我们假定读者拥有 Java SE 5 或 Java SE 6 编程背景。在此过程中,我们还将介绍 Java SE 7 一些实用的语言发展。
Java 并发编程
传统线程
过去,Java 并发编程包括通过 java.lang.Thread 类和 java.lang.Runnable 接口编写线程,然后确保其代码以正确、一致的方式对共享可变对象进行操作并避免错误的读/写操作,同时不会产生由于锁争用条件所导致的死锁。以下是基本线程操作的示例:
Thread thread = new Thread() { @Override public void run() {System.out.println(">>> I am running in a separate thread!");}};thread.start();thread.join();本示例中的代码所做的只是创建一个线程,该线程将一个字符串打印到标准输出流。主线程通过调用 join() 等待所创建的(子)线程完成。
这样直接操作线程对于简单示例来说是不错,但对于并发编程,这种代码很快就容易产生错误,尤其是当多个线程需要合作执行一个大型任务时。在这样的情况下,需要协调其控制流。
例如,某个线程执行的完成可能依赖于其他线程执行完成。通常人们熟知的示例是生产者/使用者的例子,如果使用者的队列已满则生产者应等待使用者,当队列为空时使用者应等待生产者。这一要求可通过共享状态和条件队列得到满足,但您仍需要通过对共享状态对象使用java.lang.Object.notify() 和 java.lang.Object.wait() 来使用同步,这很容易出错。
最后,一个常见的问题是对大段代码甚至是整个方法使用同步和提供互斥。尽管此方法可产生线程安全的代码,但由于排除实际上过长所引起的有限并行度,该方法通常导致性能变差。
正如计算中经常发生的那样,操作低级基元以实现复杂操作会打开错误之门,因此开发人员应想办法将复杂性封装在高效的高级库中。Java SE 5 正好为我们提供了这种能力。
java.util.concurrent 程序包的丰富基元
Java SE 5 引入了一个名为 java.util.concurrent 的程序包系列,Java SE 6 对其进行了进一步的增强。该程序包系列提供了以下并发编程基元、集合和特性:
执行器是对传统线程的增强,因为它们是从线程池管理抽象而来的。它们执行与传递到线程的任务类似的任务(实际上,可封装实现java.lang.Runnable 的实例)。有些实现提供了线程池和调度策略。而且,可以通过同步和异步方式获取执行结果。
线程安全队列允许在并发任务之间传递数据。底层数据结构和并发行为有着丰富的实现,底层数据结构的实现包括数组列表、链接列表或双端队列等,并发行为的实现包括阻塞、支持优先级或延迟等。
细粒度的超时延迟规范,因为 java.util.concurrent 程序包中的大部分类均支持超时延迟。例如,如果任务在规定时间范围内无法完成,执行器将中断任务执行。
丰富的同步模式,不仅仅是 Java 中低级同步块所提供的互斥。这些模式包括信号或同步障碍等常用语法。
高效、并发的数据集合(映射、列表和集),通过使用写时复制和细粒度锁通常可在多线程上下文中产生出色的性能。
原子变量,可以使开发人员免于亲自执行同步访问。这些变量封装了常用的基元类型,如整型或布尔值,以及对其他对象的引用。
超出固有锁所提供的锁定/通知功能范围的多种锁,例如,支持重新进入、读/写锁定、超时或基于轮询的锁定尝试。
例如,考虑以下程序:
注意:由于 Java SE 7 引入的新的整数文本,可以在任意位置插入下划线以提高可读性(例如,1_000_000)。
import java.util.*;
import java.util.concurrent.*;
import static java.util.Arrays.asList;public class Sums {static class Sum implements Callable<Long> {private final long from;private final long to;Sum(long from, long to) {this.from = from;this.to = to;}@Overridepublic Long call() {long acc = 0;for (long i = from; i <= to; i++) {acc = acc + i;}return acc;} }public static void main(String[] args) throws Exception {ExecutorService executor = Executors.newFixedThreadPool(2);List <Future<Long>> results = executor.invokeAll(asList(new Sum(0, 10), new Sum(100, 1_000), new Sum(10_000, 1_000_000)));executor.shutdown();for (Future<Long> result : results) {System.out.println(result.get());} }
}该示例程序利用执行器来计算多个长整型的和。内部 Sum 类实现了执行器用于计算结果的 Callable 接口,并发工作在 call() 方法内执行。java.util.concurrent.Executors 类提供了多种实用方法,如提供预配置执行器或将传统 java.lang.Runnable 对象封装到 Callable 实例中。与 Runnable 相比,使用 Callable 的优势在于 Callable 能够显式返回一个值。
本示例使用一个执行器将工作分派给两个线程。ExecutorService.invokeAll() 方法接受 Callable 实例的集合,并在返回之前等待所有这些实例完成。它会返回 Future 对象的列表,这些对象全都表示计算的“未来”结果。如果我们以异步方式工作,就可以测试每个 Future 对象来检查其对应的 Callable 是否已完成工作,并检查其是否引发了异常,甚至可以取消其工作。相反,当使用普通传统线程时,必须通过共享的可变布尔值对取消逻辑进行编码,并由于定期检查此布尔值而减缓代码的执行。因为 invokeAll() 容易产生阻塞,我们可以直接对 Future 实例进行遍历并读取其计算和。
还需注意,必须关闭执行器服务。如果未关闭,则在主方法退出时 Java 虚拟机将不会退出,因为环境中还有活动线程。
分解/合并任务
概述
与传统线程相比,执行器是一大进步,因为可以简化并发任务的管理。有些类型的算法要求任务创建子任务并与其他任务互相通信以完成任务。这些是“分而治之”的算法,也称为“映射归约”,类似函数语言中的齐名函数。其思路是将算法要处理的数据空间拆分成较小的独立块。这是“映射”阶段。一旦块集处理完毕之后,就可以将部分结果收集起来形成最终结果。这是“归约”阶段。
一个简单的示例是您希望计算一个大型整数数组的总和(参见图 1)。假定加法是可交换的,可以将数组划分为较小的部分,并发线程对这些部分计算部分和。然后将部分和相加,计算总和。因为对于此算法,线程可以在数组的不同区域上独立运行,所以与对数组中每个整数循环执行的单线程算法相比,此算法在多核架构上可以看到明显的性能提升。
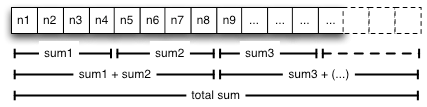
图 1:整数数组的部分和
使用执行器解决以上问题很简单:将数组分为 n 个可用物理处理单元,创建 Callable 实例以计算每个部分和,将部分和提交给管理 n 个线程的线程池的执行器,然后收集结果以计算最终和。
但对于其他类型的算法和数据结构,执行计划通常不会如此简单。尤其是,标识“足够小”可通过高效方式独立处理的数据块的“映射”阶段预先不知道数据空间拓扑结构。对基于图形和基于树的数据结构来说尤为如此。在这些情况下,算法应创建“各部分”的层次结构,在返回部分结果之前等待子任务完成。尽管类似图 1 中的数组并非最优,但可以使用多级并发部分和计算(例如,在双核处理器上将数组分为 4 个子任务)。
用于实现分而治之算法的执行器的问题与创建子任务无关,因为 Callable 可自由向其执行器提交新的子任务,然后以同步或异步方式等待其结果。问题出在并行上:当 Callable 等待另一个 Callable 的结果时,它被置于等待状态,因此浪费了处理排队等待执行的另一个Callable 的机会。
通过 Doug Lea 的努力,在 Java SE 7 中添加到 java.util.concurrent 程序包的分解/合并框架填补了这一空白。Java SE 5 和 Java SE 6 版本的 java.util.concurrent 帮助处理并发,Java SE 7 中另外增加了一些功能帮助处理并行。
用于支持并行的新增功能
核心新增功能是专用于运行实现 ForkJoinTask 实例的新的 ForkJoinPool 执行器。ForkJoinTask 对象支持创建子任务并等待子任务完成。通过这些明确的语义,执行器能够通过在任务等待另一任务完成并且有待处理任务要运行时“窃取”作业,从而在其内部线程池中分派任务。
ForkJoinTask 对象有两种特定方法:
fork() 方法允许计划 ForkJoinTask 异步执行。这允许从现有 ForkJoinTask 启动新的 ForkJoinTask。
- 而 join() 方法允许 ForkJoinTask 等待另一个 ForkJoinTask 完成。
任务之间的合作通过 fork() 和 join() 来实现,如图 2 所示。请注意,fork() 和 join() 方法名不应与其 POSIX 对应项(进程可通过它复制自身)混淆。其中,fork() 仅在 ForkJoinPool 中调度一个新任务,但不创建子 Java 虚拟机。

图 2:Fork 和 Join 任务之间的合作
有两种类型的 ForkJoinTask 实现:
RecursiveAction 的实例表示不产生返回值的执行。
- 相反,RecursiveTask 的实例会产生返回值。
通常,优先选择 RecursiveTask,因为大多数的分而治之算法返回数据集的计算值。对于任务的执行,提供了不同的同步和异步选项,从而有可能实现细致的模式。
示例:计算某个单词在文档中出现的次数
为了说明新的分解/合并框架的用法,我们举一个简单示例:计算某个单词在一组文档中出现的次数。首先,分解/合并任务应作为“纯”内存中算法运行,其中不涉及 I/O 操作。同时,应尽可能避免任务之间通过共享状态的通信,因为这意味着可能必须执行锁定。理想情况下,仅当一个任务分出另一个任务或一个任务并入另一个任务时,任务之间才进行通信。
我们的应用程序运行在文件目录结构上,将每个文件的内容加载到内存中。因此,需要以下类来表示该模型。文档表示为一系列行:
class Document {private final List<String> lines;Document(List<String> lines) {this.lines = lines;}List<String> getLines() {return this.lines;}static Document fromFile(File file) throws IOException {List<String> lines = new LinkedList<>();try(BufferedReader reader = new BufferedReader(new FileReader(file))) {String line = reader.readLine();while (line != null) {lines.add(line);line = reader.readLine();}}return new Document(lines);}
}注意:如果您是初次接触 Java SE7,fromFile() 方法有两点会使您感到惊讶:
LinkedList 使用尖括号语法 (<>) 告知编译器推断通用类型参数。由于行是 List<String>,LinkedList<> 扩展为LinkedList<String>。使用尖括号运算符,对于那些能在编译时轻松推断的类型就不必再重复,从而使得通用类型的处理更轻松。
try 块使用新的自动资源管理语言特性。在 try 块的开头可以使用实现 java.lang.AutoCloseable 的任何类。无论是否引发异常,当执行离开 try 块时,在此声明的任何资源都将正常关闭。在 Java SE 7 之前,正常关闭多个资源很快会变成一场嵌套if/try/catch/finally 块的梦魇,这种嵌套块通常很难正确编写。
于是文件夹成为一个简单的基于树的结构:
class Folder {private final List<Folder> subFolders;private final List<Document> documents;Folder(List<Folder> subFolders, List<Document> documents) {this.subFolders = subFolders;this.documents = documents;}List<Folder> getSubFolders() {return this.subFolders;}List<Document> getDocuments() {return this.documents;}static Folder fromDirectory(File dir) throws IOException {List<Document> documents = new LinkedList<>();List<Folder> subFolders = new LinkedList<>();for (File entry : dir.listFiles()) {if (entry.isDirectory()) {subFolders.add(Folder.fromDirectory(entry));} else {documents.add(Document.fromFile(entry));}}return new Folder(subFolders, documents);}
}现在我们可以开始实现主类:
import java.io.*;
import java.util.*;
import java.util.concurrent.*;public class WordCounter {String[] wordsIn(String line) {return line.trim().split("(\\s|\\p{Punct})+");}Long occurrencesCount(Document document, String searchedWord) {long count = 0;for (String line : document.getLines()) {for (String word : wordsIn(line)) {if (searchedWord.equals(word)) {count = count + 1;}}}return count;}
}occurrencesCount 方法利用 wordsIn 方法返回某个单词在文档中出现的次数,wordsIn 方法在一行中生成该单词的数组。为此,该方法基于空格和标点字符对行进行拆分。
我们将实现两种类型的分解/合并任务。直观地说,一个文件夹中某个单词出现的次数是该单词在每个子文件夹和文档中出现的次数的总和。因此,我们将有一个任务用于计算文档中出现的次数,还有一个任务用于计算文件夹中出现的次数。后一类型分出子任务,然后将子任务合并以收集这些子任务的结果。
任务相关性易于掌握,因为它直接映射底层文档或文件夹树结构,如图 3 中所示。分解/合并框架通过确保可以在文件夹任务等待 join()操作时执行一个待处理文档或文件夹的字数计算任务来使并行最大化。

图 3:分解/合并字数计算任务
首先介绍 DocumentSearchTask,它计算某个单词在文档中出现的次数:
class DocumentSearchTask extends RecursiveTask<Long> {private final Document document;private final String searchedWord;DocumentSearchTask(Document document, String searchedWord) {super();this.document = document;this.searchedWord = searchedWord;}@Overrideprotected Long compute() {return occurrencesCount(document, searchedWord);}
}因为我们的任务产生值,这些任务扩展了 RecursiveTask 并接受 Long 作为通用类型,因为出现的次数将由一个 long 型整数表示。compute() 方法是所有 RecursiveTask 的核心。此处,它只是委托上述 occurrencesCount() 方法。现在我们可以处理FolderSearchTask 的实现,该任务运行在树结构的文件夹元素上:
class FolderSearchTask extends RecursiveTask<Long> {private final Folder folder;private final String searchedWord;FolderSearchTask(Folder folder, String searchedWord) {super();this.folder = folder;this.searchedWord = searchedWord;}@Overrideprotected Long compute() {long count = 0L;List<RecursiveTask<Long>> forks = new LinkedList<>();for (Folder subFolder : folder.getSubFolders()) {FolderSearchTask task = new FolderSearchTask(subFolder, searchedWord);forks.add(task);task.fork();}for (Document document : folder.getDocuments()) {DocumentSearchTask task = new DocumentSearchTask(document, searchedWord);forks.add(task);task.fork();}for (RecursiveTask<Long> task : forks) {count = count + task.join();}return count;}
}
在该任务中,compute() 方法的实现只是为已通过其构造函数传递的每个文件夹元素分解文档和文件夹任务。然后将合并所有这些任务以计算其部分和并返回该部分和。
现在我们只差一种方法来启动分解/合并框架上的字数计算操作,以及一个分解/合并池执行器:
private final ForkJoinPool forkJoinPool = new ForkJoinPool();Long countOccurrencesInParallel(Folder folder, String searchedWord) {return forkJoinPool.invoke(new FolderSearchTask(folder, searchedWord));
}
初始 FolderSearchTask 将启动所有这些操作。ForkJoinPool 的 invoke() 方法允许等待计算完成。在上面的例子中,
ForkJoinPool 是通过其空构造函数来使用的。并行度将与可用的硬件处理单元的数目相匹配(例如,在具有双核处理器的计算机上并行度将为 2)。
现在我们可以编写一个 main() 方法,该方法从命令行参数接受要在其上运行的文件夹以及要搜索的字:
public static void main(String[] args) throws IOException {WordCounter wordCounter = new WordCounter();Folder folder = Folder.fromDirectory(new File(args[0]));System.out.println(wordCounter.countOccurrencesOnSingleThread(folder, args[1]));
}
该示例的完整源代码还包括此算法更传统的基于递归的实现,该实现工作在单线程上:
Long countOccurrencesOnSingleThread(Folder folder, String searchedWord) {long count = 0;for (Folder subFolder : folder.getSubFolders()) {count = count + countOccurrencesOnSingleThread(subFolder, searchedWord);}for (Document document : folder.getDocuments()) {count = count + occurrencesCount(document, searchedWord);}return count;
}
讨论
在 Oracle 的 Sun Fire T2000 服务器上进行了一次非正式测试,其中可以指定 Java 虚拟机可用的内核数。同时运行了上例的分解/合并和单线程形式以找出 import 在 JDK 源代码文件中出现的次数。
多次运行了这些变化形式以确保 Java 虚拟机热点优化有足够的时间完成部署。收集了 2 个、4 个、8 个和 12 个内核的最佳执行时间,然后计算了加速(即单线程上的时间/分解-合并上的时间之比)。结果反映在图 4 和表 1 中。
正如您看到的,只需极少的努力即可在内核数上获得近乎线性的加速,因为分解/合并框架会负责最大化并行度。
表 1:非正式测试执行时间和加速
|
内核数 |
单线程执行时间 (ms) |
分解/合并执行时间 (ms) |
加速 |
|
2 |
18798 |
11026 |
1.704879376 |
|
4 |
19473 |
8329 |
2.337975747 |
|
8 |
18911 |
4208 |
4.494058935 |
|
12 |
19410 |
2876 |
6.748956885 |
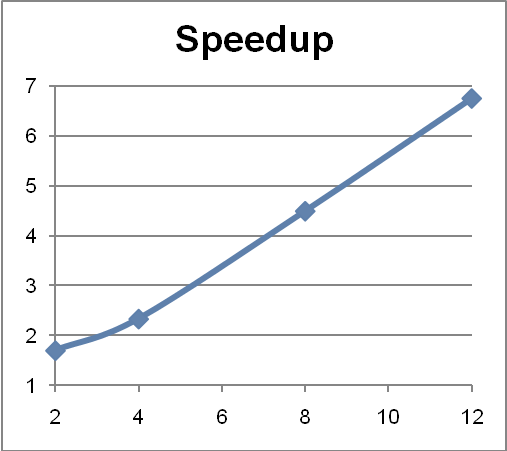
图 4:加速(纵轴)与内核数(横轴)有关
我们还可以对计算进行优化,分解任务使其在行级而不是在文档级运行。这将使并发任务有可能在同一文档的不同行上运行。但这有点牵强。实际上,分解/合并任务应执行“足够”数量的计算以克服分解/合并线程池和任务管理的开销。在行级工作将过于琐碎,从而影响该方法的效率。
所包含的源代码还提供基于对整数数组执行合并-排序算法的另一个分解/合并示例。这很有趣,因为它使用 RecursiveAction 来实现,该分解/合并任务对 join() 方法的调用不会产生值。相反,任务将共享可变状态:要排序的数组。同样,实验显示内核数目上存在近乎线性的加速。
总结
本文讨论了 Java 并发编程,重点强调 Java SE 7 为简化并行程序编写而提供的新的分解/合并任务。本文显示,可以使用和组合丰富的基元来编写可利用多核处理器的高性能程序,而完全无需处理线程和共享状态同步的低级操作。本文在某单词出现次数计算示例中阐释了这些新 API 的使用,既引人注目又易于掌握。在非正式测试中,在内核数目上取得了近乎线性的加速。这些结果显示分解/合并框架非常有用;因为我们既不必更改代码,也不必调整代码或 Java 虚拟机,即可最大程度利用硬件内核。
您还可以将此技术应用于自己的问题和数据模型。只要您按无需 I/O 工作和锁定的“分而治之”的方式重新编写算法,即可看到显著的加速。
分解和合并:Java 也擅长轻松的并行编程!相关推荐
- 分解和合并:Java 也擅长轻松的并行编程! 作者:Julien Ponge
文中的程序我也测试过了, 注意下面的红字部分,在测试的时候我们需要保护测试环境尽可能等价,要么 分成2次测试 一次输出串行的时间 一次输出并行的时间,如果想在一个方法中比较,那么两者的先后顺序就 ...
- C语言编程中的8位、16位、32位整数的分解与合并
在单片机的编程中对于8位.16位.32位整数的分解与合并用的比较多,今天做了简要学习,后面还需要加以总结. 练习在VC++6.0编程环境中进行,源程序: #include <stdio.h> ...
- Fork and Join: Java也可以轻松地编写并发程序 原文地址 作者:Julien Ponge 译者:iDestiny 资源下载: Java SE 7 Sample Code(Zi
Fork and Join: Java也可以轻松地编写并发程序 原文地址 作者:Julien Ponge 译者:iDestiny 资源下载: Java SE 7 Sample Code(Zip) ...
- 华为笔试题 -- 多个数组按顺序合并(Java代码实现)
华为笔试题 – 多个数组按顺序合并(Java代码实现) 题目描述: 现在有多组整数数组,需要将他们合并成一个新的数组.合并规则,从每个数组里按顺序取出固定长度的内容合并到新的数组中,取完的内容会删除掉 ...
- java 并行_Java 并行编程!
多核处理器现在已广泛应用于服务器.台式机和便携机硬件.它们还扩展到到更小的设备,如智能电话和平板电脑.由于进程的线程可以在多个内核上并行执行,因此多核处理器为并发编程打开了一扇扇新的大门.为实现应用程 ...
- java 多线程和并行编程_Java 8中的并行和异步编程
java 多线程和并行编程 并行代码是在多个线程上运行的代码,曾经是许多经验丰富的开发人员的噩梦,但是Java 8带来了许多更改,这些更改应该使这种提高性能的窍门更加易于管理. 并行流 在Java 8 ...
- 浅谈并行编程中的任务分解模式
并行编程使用线程来使得多个操作能够同时运行.并行编程主要包括应用程序中线程设计,开发和部署以及线程间相互协调和各自的操作. 在下文中我们将讨论怎样分割适合线程化大小的编程任务来多任务化一个应用程 ...
- 轻松掌握FFmpeg编程:从架构到实践
轻松掌握FFmpeg编程:从架构到实践 (Master FFmpeg Programming with Ease: From Architecture to Practice 引言 (Introduc ...
- 终于有人说出来了——Java不适合于作为主要编程教学语言
CSDN首页推荐了一篇文章,说两位退休的美国大学教授上书反对将Java作为编程教学语言,对此我表示高度认同.对于Java,我并不反感,而且相信它在工业应用中的地位不可取代,但是,我一直反对将Java作 ...
最新文章
- 23种设计模式C++源码与UML实现--责任链模式
- Linux shell if判断=左右必须要有空格
- ikvm java转换成dll_利用IKVM.NET将Java jar包转换成可供C#调用的dll文件
- windows apache html5,Windows服务器下的IIS和Apache性能比较
- android中虚拟程序停止,为什么我的在虚拟机运行后出现应用程序停止运行
- gensim读取已训练模型LDA模型的模型与dictionary
- C++得到当前进程所占用的内存
- 运行 lighttrack 遇到错误和解决方法
- neo4j jdbc中文乱码
- 网站安全之设置HttpOnly的方法
- 【Android -- 性能优化】启动速度分析工具 — TraceView
- linux某用户 计划任务,Linux计划任务管理
- oracle单表空间预估,使用ARIMA和腾讯的Metis时序数据异常检测来预测系统空间容量变化趋势...
- #!/bin/bash和#!/bin/sh是什么意思以及区别
- 沈航C语言上机实验题答案,2017年沈阳航空航天大学航空航天工程学部823C语言程序设计考研题库...
- wpf展开树节点_WPF中展开一个TreeView控件的所有树节点
- oracle中那个日期怎么相减_oracle日期时间加减规则
- 超级3合1U盘维护系统
- 聚簇索引和非聚簇索引到底有什么区别?
- 微服务容器部署与持续集成(Jenkins)