云计算管理三利器:Nagios、Ganglia和Splunk
概述
我们在搭建趋势云计算平台时,遇到了很多的问题和挑战。开始搭建时,第一次来了那么多性能强劲的机器,我们在感到兴奋的同时,也不免有些顾虑。大家坐在一起讨论,问题就列了满满一白板。
出了问题怎么办,有没有预警机制?有没有可视化的管理界面?管理平台需要自己开发吗?开发难度有多大?有没有开源的管理工具?那么多日志分布在各个机器上,有没有更有效的方法管理?能否生成好的报表?机器宕机,管理员能否收到短信通知?如何做性能调优?扩容升级时,能否给出依据?
带着这些问题,我们开始了自己的云计算平台管理和运营之旅,一路走来,收获颇丰。现在基本上形成了如图1所示的一整套云计算平台监控体系。
图1云计算平台监控架构

在这个系统中,我们综合利用了Nagios、Ganglia和Splunk,搭建起云计算平台监控体系,使其具备错误报警、性能调优、问题追踪和自动生成运维报表的功能。有了这套系统,我们终于能够轻松管理Hadoop/HBase云计算平台了。接下来将简单介绍它们的特点和功能。
Nagios:云计算平台的智能报警器
总不能天天盯着机器看吧,因此我们首先关心的是机器的监控与报警。最理想的境界是:如果机器出故障了,我能第一时间处理;如果机器没有问题(最好永远没有问题),我能去喝茶、钓鱼和睡大觉。
发现机器有没有问题,对我们而言不是什么难事。写个脚本,Ping一下IP,Telnet每台机器的Service端口,如果增加了新机器就改改配置即可。但这样也太原始了吧,可视化效果差,不好维护,没有层次,不好管理,出不来报表,总不能老是用Excel人工写报表吧。有没有更好的方法呢?
有,你可以用Nagios。
Nagios是一个可运行在Linux/Unix平台之上的开源监视系统,可以用来监视系统运行状态和网络信息。Nagios可以监视所指定的本地或远程主机以及服务,同时提供异常通知功能。
Nagios可以提供以下几种监控功能。
监控网络服务(SMTP、POP3、HTTP、NNTP、Ping等)。监控主机资源(处理器负荷、磁盘利用率等)。简单的插件设计使得用户可以方便地扩展自己服务的检测方法。并行服务检查机制。具备定义网络分层结构的能力,并使用“parent”主机定义来表达网络主机间的关系,这种关系可被用来发现和明晰主机宕机或不可达状态。当服务或主机问题产生与解决时将告警发送给联系人(通过电子邮件、短信、用户定义方式)。具备定义事件处理功能,可以在主机或服务的事件发生时获取更多问题定位。自动的日志回滚。可以支持并实现对主机的冗余监控。可选的Web界面用于查看当前的网络状态、通知和故障历史、日志文件等。
Nagios最好用的地方就是它将这些每天管理员做的工作自动化,你只需设定好要监听的端口即可,它会默默地工作,帮忙定时地去检测服务端口的状态,一旦发现问题,会及时发出报警。报警可以是电子邮件也可以是手机,从而使得管理员第一时间就能收到系统的状况。
Nagios的报表功能也很强大。管理员可以很容易地得到每天、每周和每月的Service运行状况。

图2SPN后台运行的所有Service的当前状态
如图2所示,红色部分清楚地标注有问题的机器,点开链接,就可以得到有问题机器的情况。虽然在HBase中,几台RegionServer宕机不会对整体服务产生大的影响,但多少会影响到系统的Performance。而且,如果某几台RegionServer频繁宕机,对整个系统的稳定性也会产生不好的影响。有了Nagios,我们可以快速定位有问题的机器,及时地将一些机器移除出HBase系统,待调整好了再上线运行,以保证系统的稳定性。
现在,Nagios已经成为了很多公司必备的监控工具。只需要简单地配置,就可以实现强大的功能,将管理员从日常烦琐的工作中解放出来。
有了Nagios,哪怕就是管理上千台机器,也不会手忙脚乱,而是有一种统领千军、运筹帷幄的感觉。
Ganglia:看到云计算平台的方方面面
Nagios的确不错,但你是不是真的可以喝茶、钓鱼、睡大觉呢?显然还不行。有了Nagios,你基本上可以做个优秀的救火队员,能在事发第一时间到达现场、处理事故。但如何防患于未然,真正做到运筹帷幄、游刃有余呢?
我们需要更加精确的数据,能够看到云计算平台的方方面面,能根据这些数据,做出性能调整、升级、扩容等的决策,从而保证Service能够满足不断增长的业务需求。
这时候,你需要Ganglia。
Ganglia是UCBerkeley发起的一个开源实时监视项目,用于测量数以千计的节点,为云计算系统提供系统静态数据以及重要的性能度量数据。Ganglia系统基本包含以下三大部分。
Gmond:Gmond运行在每台计算机上,它主要监控每台机器上收集和发送度量数据(如处理器速度、内存使用量等)。
Gmetad:Gmetad运行在Cluster的一台主机上,作为WebServer,或者用于与WebServer进行沟通。
GangliaWeb前端:Web前端用于显示Ganglia的Metrics图表。
Hadoop和HBase本身对于Ganglia的支持非常好。通过简单的配置,我们可以将Hadoop和HBase的一些关键参数以图表的形式展现在Ganglia的WebConsole上。这些对于我们洞悉Hadoop和HBase的内部系统状态有很大的帮助。
在Hadoop的conf文件夹下面,找到hadoop-metrics.properties,配置好Ganglia的Server即可。这里要注意,Ganglia3.0和Ganglia3.1的区别,它们使用了不同的class。
dfs.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
dfs.period=10
dfs.servers={Ganglia_Server}:8649
有了这些图表,Hadoop和HBase就不再是一个黑盒。无论是Hadoop的Namenode、Datanode,还是HBase的MasterServer、RegionServer任何时刻的情况,都会一目了然。由于图标的跨度可以是小时、天、月甚至是年,这样,就可以非常方便地定期生成周报、月报和年报。同时,根据图中Metrics的状况,我们可以通过调整参数、增加内存和硬盘、增加机器等的方法调整单个机器或者整个Service的性能。
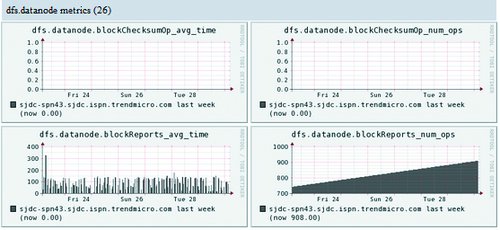
图3Hadoop其中一个DataNode的Metrics
Nagios最大的问题在于不能洞悉到Service内部的状况。像Hadoop、HBase这样的分布式系统,一个节点的故障并不等于整个Service的故障,影响的只是Service的性能。所以,在测定Service的SLA时,我们不能以某一台机器的故障作为Service故障的评判标准。比如在我们的HBaseSLA的设定上,我们定义了HBaseService完全不能工作的评判标准如下。
MasterServer联系不上。所有RegionServer都无法联系上。-ROOT-表无法访问。.META.表无法访问。

图4Ganglia对Hadoop/HBase使用情况的监测
那么,我们就可以根据这个规则定义SLA,通过定期调用HBaseAdmin相应API,将测试的结果发给Ganglia。采用同样的方法,我们还可以自定义一些规则,监视HBaseMaster、Zookeeper等的情况。
通过这些方法,我们完全能够针对Hadoop/HBase使用的实际情况,做出Service级别而不是机器级别的监控系统并生成报表。
此外,Ganglia还可以通过Server反馈回来的Load信息,给出各个机器的Load情况,给我们做升级和扩容提供依据。
如图5所示,Ganglia分别会用不同颜色,标注出当前时刻的机器Load分布情况。如果Load过重,就应该检查机器的具体使用情况。

图5HBaseClusterLoadMetrics
Ganglia的安装配置,可以参考:http://www.spnguru.com/?p=604。
Splunk:像查Google一样查日志
有了Nagios和Ganglia,算是成功了一大半。作为一名优秀的管理员,我们需要具备一定的Troubleshooting能力,对一些常见的问题能给出解决方案。那么,对日志的分析就必不可少。
但Hadoop/HBase的日志分布在各个机器上面,而日志之间关联性强。Client端的错误有可能是RegionServer引起,而RegionServer的错误有可能是Zookeeper导致。有没有一个统一的日志管理平台呢?
众里寻它千百度,蓦然回首,我们找到了Splunk——日志界的Google。
很遗憾,Splunk不是开源的,但它的免费版本提供每天500MB日志索引。如果数据量较小,通过定义好Log的级别,基本上也能满足需求。但对于数据量较大的公司,就有些捉襟见肘。
Splunk支持AdHoc的日志搜索,而且可以与Nagios配合使用。比如Nagios报警某台RegionServer端口不可达,我们收到Notification后,登录Splunk,直接搜索shutdown和host名称,找到RegionServer退出的日志。点击详细信息,分析日志,就能快速定位问题。如图6所示。
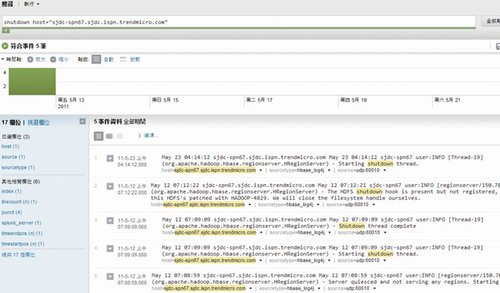
图6Splunk与Nagios配合使用进行日志搜索
对Hadoop和HBase有了进一步了解后,我们可以利用Splunk实时检测日志中的关键字,定义关键字规则,如监控“shutdown”、“quit”、“ERROR”、“ZookeeperSessionExpired”等,一旦出现,利用Splunk的Notification功能,发出邮件通知管理员,管理员通过Splunk定位问题,就可以在系统真正出现问题之前,对系统进行调整,防患于未然。
总结
搭建一套云计算平台,强大的监控管理系统是必不可少的。当然,任何工具都不是万能的,在实际维护过程中,我们也发现,Nagios和Splunk经常出现误报,如果规则定义得不好,大量的警报邮件如潮水一样涌来,反而掩盖了真正的问题。可以说,在云计算平台的运维管理上,没有一劳永逸的事情,随着规模的不断增大和应用的不断多样化,需要大家不断地实践和总结。
云计算管理三利器:Nagios、Ganglia和Splunk相关推荐
- 云计算平台管理的三大利器Nagios、Ganglia和Splunk
综合利用Nagios.Ganglia和Splunk搭建起的云计算平台监控体系,具备错误报警.性能调优.问题追踪和自动生成运维报表的功能.有了这套系统,就可轻松管理Hadoop/HBase云计算平台. ...
- Linux运维学习笔记之三十一:监控利器Nagios实战
第四十二章 监控利器Nagios实战 一.Nagios介绍 1.哪些内容需要监控呢? (1)本地资源 a.负载:uptime: b.CPU:top,sar,cpu温度: c.磁盘:df: d.内存:f ...
- IaaS, PaaS和SaaS是云计算的三种服务模式
原文链接:https://zhidao.baidu.com/question/584394281.html IaaS, PaaS和SaaS是云计算的三种服务模式. SaaS:Software-as-a ...
- 运维监控利器Nagios:概念、结构和功能
一.使用Nagios的必要性 1.大量的IT基础设施系统管理繁琐.复杂. 2.减少管理和维护成本 3.优化系统.合理利用服务资源 监控软件局限性: 1. 没有任何工具可以监视您所需的一切内容. 2 ...
- 云计算的三种服务模式:IaaS,PaaS,SaaS
1. 简介 IaaS, PaaS和SaaS是云计算的三种服务模式."云"其实是互联网的一个隐喻,"云计算"其实就是使用互联网来接入存储或者运行在远程服务器端的应 ...
- 仿OpenStack开发云计算管理软件”--熟悉开发环境
他山之石,可以成云 --咆哮金刚猪的云烹饪之路 第一周(7月13日-7月19日):熟悉开发环境 实验内容: 云平台功能模块分析 云平台架构设计 Flask开发环境搭建 Flask可运行的代码框架 实验 ...
- 维监控利器Nagios:概念、结构和功能
一.使用Nagios的必要性 1.大量的IT基础设施系统管理繁琐.复杂. 2.减少管理和维护成本 3.优化系统.合理利用服务资源 监控软件局限性: 1. 没有任何工具可以监视您所需的一切内容. 2. ...
- 喜报|聚焦信创——360云计算管理平台生态建设的又一里程碑!
女主宣言 近日,360云计算管理平台完成了基于海光芯片的中科曙光和中科可控的服务器兼容认证.麒麟和统信的操作系统兼容认证.人大金仓数据库管理系统KingbaseES及东方通Tongweb产品互兼容认证 ...
- 云计算机类型,云计算的三种云类型你了解多少?
随着云计算的快速发展,云计算最基础的产品云主机慢慢深入人心,也非常深受大众欢迎,其中分为公有云.私有云.混合云,云计算的不断创新与发展,也不再是一个新概念,将成为互联网发展的趋势,接下来蒙鸟云小编来谈 ...
最新文章
- Android单元测试全解
- keil5软件仿真出现unknown signal解决方法。
- 科大星云诗社动态20210414
- 歌谣对自己的“自勉“
- SIM800A上传数据到Onenet平台命令
- 一个便捷的在线取色器工具
- 计算机桌面设置上时间表,如何在电脑桌面设置显示星期
- 中国计算机科技成果,中国科技成就有哪些(盘点2020年中国八大黑科技)
- Windows定时关机小程序
- Stream流创建,常用方法
- python并发编程之semaphore(信号量)_python 之 并发编程(守护进程、互斥锁、IPC通信机制)...
- scala连接mysql数据库
- RuoYi-Vue部署服务器流程
- 蜂鸣器分类及声音控制说明
- nas 群晖 git 项目创建步骤
- 第七章-数据分析-数据透视表的应用
- 白醋泡大蒜,治疗灰指甲。以下为详细操作,供需要的人参考
- 计算机主机通常包不包括硬盘,计算机主机通常包括
- nativeQuery = true是什么意思?
- BZOJ 2246 [SDOI2011]迷宫探险 (记忆化搜索)