快排Quick Sort到底有多快?
所以,想让基于比较的排序更快,等价于让每次比较的信息熵达到最大。所以,让每次比较的结果概率相等(使得每次比较的信息熵接近1bit),这是算法改进的核心思想。
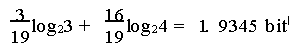
当主元随机选择的时候:我们不妨令轴元素为pivot,第一次比较结果是a1<pivot,那么可以证明第二次比较a2也小于pivot的可能性是2/3!这容易证明:如果a2>pivot的话,那么a1,a2,pivot这三个元素之间的关系就完全确定了——a1<pivot<a2,剩下来的元素排列的可能性我们不妨记为P(不需要具体算出来)。而如果a2<pivot呢?那么a1和a2的关系就仍然是不确定的,也就是说,这个分支里面含有两种情况:a1<a2<pivot,以及a2<a1<pivot。对于其中任一种情况,剩下的元素排列的可能性都是P,于是这个分支里面剩下的排列可能性就是2P。所以当a2<pivot的时候,还剩下2/3的可能性需要排查。
再进一步,如果第二步比较果真发现a2<pivot的话,第三步比较就更不妙了,模仿上面的推理,a3<pivot的概率将会是3/4!
这就是快排也不那么快的原因,它不能保证每次比较结果的概率都是相同的(1/2 :1/2),因此,每次比较的信息熵不是都=1bit。
如果你想改进快排,那么可以试试把精力放在提高每次比较的信息熵。
from: http://blog.csdn.net/cyh_24/article/details/8120045
快排Quick Sort到底有多快?相关推荐
- SEO快排是什么?怎样实现快排?
转自:http://www.weidianyuedu.com SEO快排是什么?顾名思义SEO快排就是快速排名,也就是让指定关键词指定内容快速在搜索引擎获得排名.SEO优化是一个长期的过程,而SEO快 ...
- js排序(快排与sort)
快排 <!DOCTYPE html> <html lang="en"><head><meta charset="UTF-8&qu ...
- 非递归的方法写快排java_快排的最差情况以及快排平均复杂度的计算
最近突然讨论了这两个问题,有点忘记了,记录了一下网上的比较好的说法,参见Reference 快排的相关知识请参考排序总结 快排的最差情况以及如何避免 首先,快排的最差情况什么时候发生? 1. 已排序 ...
- seo模拟点击软件_关键词快排是什么?SEO快排、刷点击和快排发包原理分析
如今大多数SEO快排都宣称自己是安全的SEO发包技术,但这种可能的发包技术原理更能解释为什么百度指数比百度表现更好. 如今,带来的是"用户行为影响排名.刷点击和快排分配原则".但愿 ...
- 23行代码_动图展示——快排详解(排序最快的经典算法)
快排 1.快排的实现逻辑: 先从数列中取出一个数作为基准数(通常取第一个数). 遍历序列,将比它小的数与比它大的数分别记录下来,分为两类,最后该数放在这两类数中间(它左边的所有数都比它小,右边的所有数 ...
- 天下武功,唯快不破 - SAP HANA 到底有多快?
天下武功,无坚不破,唯快不破,以势赢者势颓则败,以力胜者力尽则亡. 但是武功在高,也怕"羊刀"啊一神器,(又名:邪恶镰刀,名字是不是很霸气,其实就是其能将敌方单位变为小动物的能力- ...
- 快排Java代码实现(Quick Sort)
1. 快排算法思路 基本思想:通过一趟快速排序将待排数组分割成独立的两份部分; 其中一部分数组的值均比另一部分数组的值小,则可分别对着两部分数组继续进行排序,以达到整个序列有序. 快排的平均时间复杂 ...
- 排序算法--快排的优化
排序算法–快排的优化 下面是我写的一种快排: #include <iostream> #include <stdlib.h>using namespace std;void P ...
- C++数据结构和算法2 栈 双端/队列 冒泡选择插入归并快排 二三分查找 二叉树 二叉搜索树 贪婪 分治 动态规划
C++数据结构和算法2 栈 双端/队列 冒泡选择插入归并快排 二三分查找 二叉树 二叉搜索树 贪婪 分治 动态规划 博文末尾支持二维码赞赏哦 _ github 章3 Stack栈 和 队列Queue= ...
最新文章
- 干货:如何在前端统计用户访问来源?
- [团队开发]总结下Server 2008 + TeamFoundation Server 2008安装过程
- 单循环链表中设置尾指针比设置头指针更好的原因
- DevExpress控件库----AlertControl提示控件
- 博士生的deadline血泪史,这是一份来自Nature的避坑指南
- Java 网络实例一(获取指定主机的IP地址、查看端口是否已使用、获取本机ip地址及主机名、获取远程文件大小)
- Java线程之CompletionService批处理任务
- idea 批量导入包
- 《可解释的机器学习》校对活动正式启动 | ApacheCN
- 2022年美赛成绩什么时候出,2022美赛思路与注意事项。
- 超简单版Python打包exe文件,并修改图标,这将是你见过最容易上手的教程~
- CentOS7中安装PostgreSQL客户端
- 无线系统笔记(1)--梯度、散度、旋度(麦克斯韦先导)
- js 实现当有省略号时,显示title,无省略号不显示title
- mysql 取月份天数_mysql 之 获取指定月份天数和指定月份上月天数
- java jar包转成exe运行
- 计算机网络与互联网的区别,计算机网络与互联网的主要区别是什么?
- 肿瘤NGS的常规检测流程
- 成都开发者看过来!百度资深研发工程师将出席超级账本成都见面会
- Qt 模型视图编程之表头设置
热门文章
- 主成分分析(PCA)——以2维图像为例
- android 蓝牙耳机 判断,Android实现蓝牙耳机连接
- Tomcat - Tomcat 8.5.55 启动过程源码分析阶段三_start阶段
- MySQL-日志二进制日志binlog初探
- python中key的意思_有朋友问Python 中实例对象为啥能按照key赋值。
- expdp oracle 并行_关于Expdp/Impdp 并行导入导出详细测试结果和并行参数的正确理解!!...
- 项目实战解决 java.sql.SQLException: Unable to load authentication plugin ‘caching_sha2_password‘.
- Go语言垃圾回收(GC)
- php函数dirname范例,PHP dirname( )用法及代碼示例
- php网站添加cnzz,cnzz代码添加元素到页面