KNN算法原理与简单实现
KNN算法原理与简单实现
K最近邻(k-Nearest Neighbor,KNN)分类算法,是最简单的机器学习算法之一,涉及高等数学知识近乎为0,虽然它简单,但效果很好,是入门机器学习的首选算法。但很多教程只是一笔带过,在这里通过该算法,我们可以学习到在机器学习中所涉及的其他知识点和需要注意的地方。
- 在之前的鸢尾花数据集中,我们只将2种花的150个样本的前2个特征在二维特征空间中表示,如下图
![]()
- 那么当来了一个新的数据(如下图中绿色的点),我们如何判断它最可能属于哪种花呢
![]()
KNN算法原理
- 我们先取一个k值(即KNN中的"K"),在这里我们先根据经验假设取得了最优值k=3。K近邻算法做的事情就是对于每个新的点,我们计算出距离它最近的前k个点,然后这k个点进行投票,在这里k=3,如下图所示
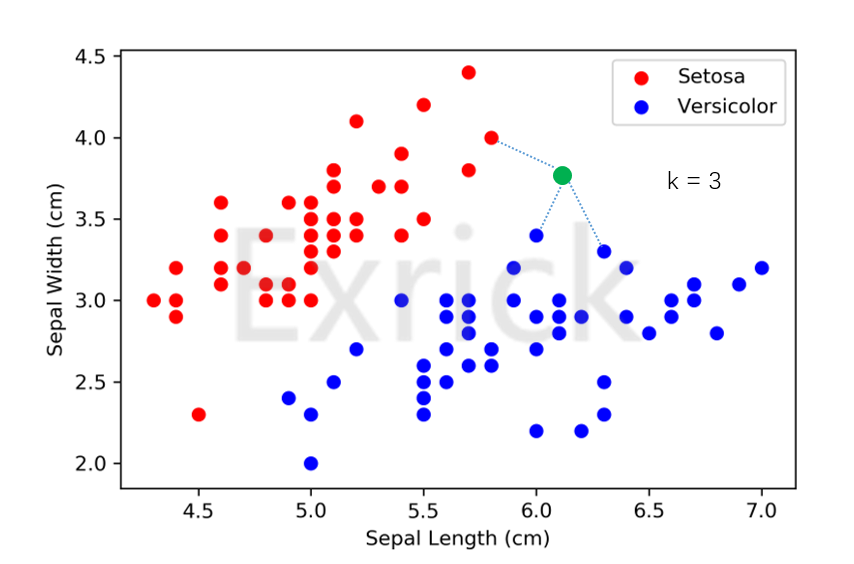
- 这个例子中,蓝色:红色为2:1
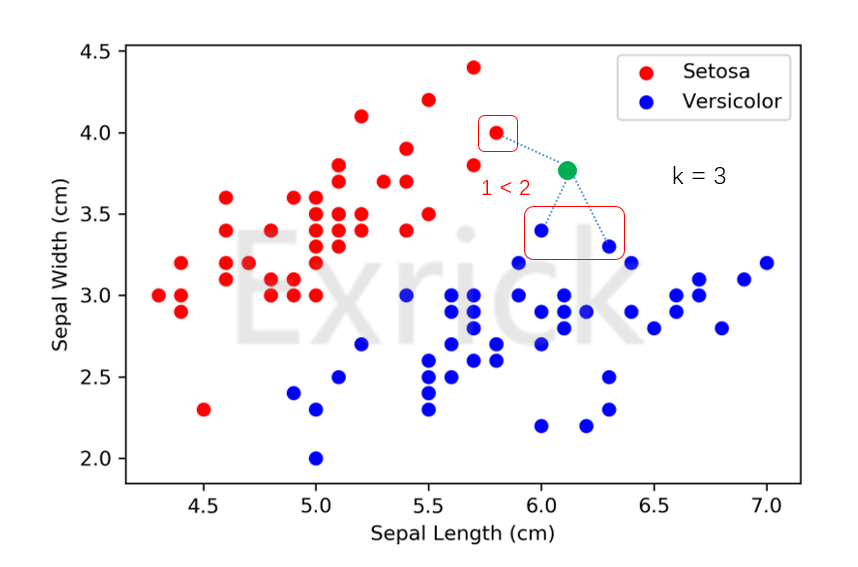
- 因此该新的绿色数据点更有可能属于蓝色类别的花
即KNN算法就是通过各样本之间的相似程度(样本空间中的距离)作出判断,因此只考虑1个样本是不具有说服力的,通常我们考虑k为多个
这里K近邻解决的就是前面讲到的分类问题,它也可以解决回归问题
KNN算法的简单实现
经过上面的分析我们可以得出该算法大致思路,即判断新来的数据点与其他所有数据的距离,距离最近的点的类别即可能为该新点的类别
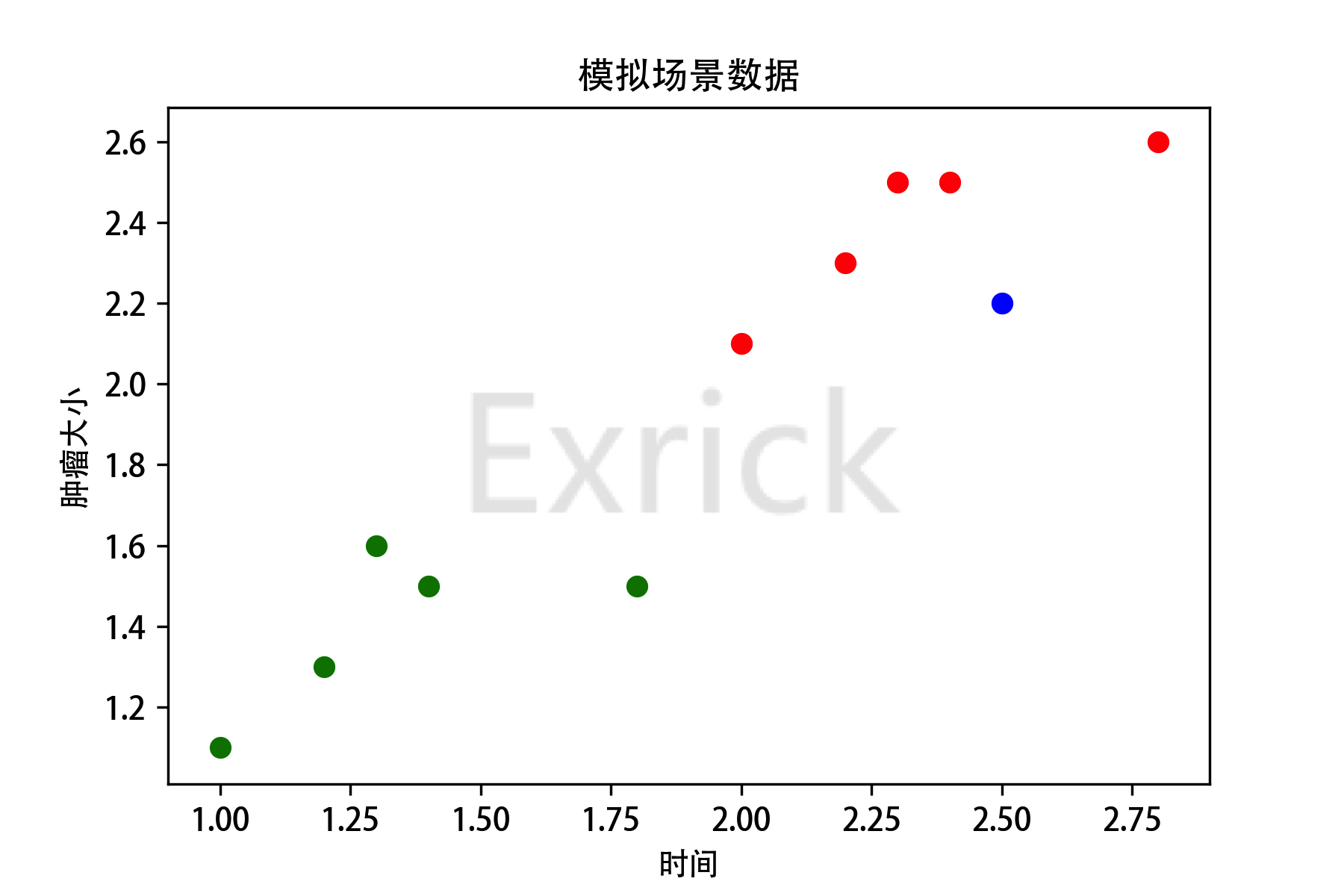
这里模拟了十组数据,每组数据横坐标代表已患肿瘤天数,纵坐标代表对应肿瘤大小,依次对应标记数据:0代表良性肿瘤用绿点表示,1代表恶性肿瘤红点表示

这里所用到的数学公式是大家初高中就学习的求两点(x1, y1)与(x2, y2)间距离公式,
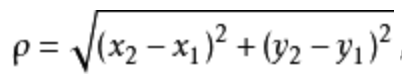 ,即欧氏距离公式
,即欧氏距离公式

- 假设现在来了一个新的病人数据(2.5, 2.2)对应图中蓝色点,绘制散点图后我们可以很容易发现其属于红色即恶性肿瘤一类,那么接下来让我们用代码实现吧
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #正常显示中文
plt.rcParams['axes.unicode_minus'] = False #正常显示负号from math import sqrt
from collections import Counter'''
k:kNN中的k,判断多少个最近的数据
xTrain:待训练的特征数据
yTrain:待训练的Label标记数据
x:新的待预测判断的数据
'''
#模拟10组数据 python列表格式 rawDataX:原始数据特征集 rawDataY:原始标记(所属标记)
rawDataX = [[1.0,1.1],[1.2,1.3],[1.4,1.5],[1.3,1.6],[1.8,1.5],[2.0,2.1],[2.2,2.3],[2.4,2.5],[2.8,2.6],[2.3,2.5],
]
rawDataY = [0,0,0,0,0,1,1,1,1,1]
x = [2.5,2.2]#将上面所有数据作为训练集 创建为numpy数组格式
#xTrain变为二维数组 yTrain变为一维向量
xTrain = np.array(rawDataX)
yTrain = np.array(rawDataY)# print(xTrain)
print(yTrain)#1计算距离
distance = []
for xt in xTrain:d = sqrt(np.sum((xt-x)**2)) #相减的平方再开根号 欧式距离distance.append(d)
print(distance)
# distance = [(sqrt(np.sum((xt-x)**2)) for i in X] #2排序
#复习:argsort从小到大排序后直接返回索引
nearest = np.argsort(distance)
print(nearest)#3找出最近的k个点对应标记值
#当k=6时 即上方已排好序的前6个索引值对应的点即为前6个最近的
#索引值对应的yTrain里面看类别为 0 或 1
k=6
topKY = [yTrain[i] for i in nearest[:k]]
print(topKY)#统计类别个数 进行投票输出最终结果
votes = Counter(topKY)
print(votes.most_common(1))predictY = votes.most_common(1)[0][0]
print(predictY)
![]()
![]()
- 通过预测结果得出:由于该点所属类别很可能为1。
注:跟着大佬梳理的流程走下来的,在这里注明一下出处:
https://github.com/Exrick/Machine-Learning
注:大佬的更直观详细
更多详细讲解可见B站视频:https://www.bilibili.com/video/BV1th411B7Kx
KNN算法原理与简单实现相关推荐
- KNN算法原理及简单改进
KNN算法 1. 什么是KNN算法 简单来说,就是根据周围几个邻居的类别来判断自己的类别 1.1 KNN概念 KNN算法全称K Nearest Neighbor 定义:如果一个样本在特征空间中的k个最 ...
- 机器学习之KNN算法原理
机器学习之KNN算法原理 1 KNN算法简介 2 算法思想 3 多种距离度量公式 ① 欧氏距离(Euclidean distance) ② 曼哈顿距离(Manhattan distance) ③ 闵式 ...
- KNN算法原理及python实现
文章目录 1 KNN算法原理 1.1 基本概念 1.2 KNN算法原理 1.3 实现步骤 1.3 KNN算法优缺点 2 python手工实现KNN算法 2.1 KNN算法预测单个数据 2.2 KNN算 ...
- 详细的KNN算法原理步骤
KNN算法原理详解 KNN算法 1.1 解决监督学习中分类问题的一般步骤 1.2 什么是消极(惰性)的学习方法 2 首先从一个实例讲起 3 KNN分类算法入门 3.1.1算法综述 3.1.2算法思想 ...
- KNN算法原理与python实现
文章目录 KNN算法原理 KNN算法介绍 KNN算法模型 距离度量 k值的选择 分类的决策规则 KNN算法python实现 手写数字识别 sklearn代码实现 参考文献 KNN算法原理 KNN算法介 ...
- KNN算法原理及实现
KNN算法原理及实现 1.KNN算法概述 kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.该方法在确定分类 ...
- 深入浅出KNN算法(一) KNN算法原理
一.KNN算法概述 KNN可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,注意KNN算法是有监督学习中的分类算法,它看起来和另一个机器学习算法Kmeans有点像(Kmeans是无监督学 ...
- 机器学习算法—KNN算法原理
机器学习算法-KNN算法原理 概述: KNN算法一般也会经常被称为K邻近算法,其核心思想是根据训练集中的样本分类计算测试集中样本与训练集中所有样本的距离,根据所设定的K值选取前K个测试样本与训练样本最 ...
- 浅谈KNN算法原理及python程序简单实现、KD树、球树
最近比较空闲,打算利用这一段时间理一下机器学习的一些常见的算法.第一个是KNN算法: KNN 1.原理: KNN,K-NearestNeighbor---K最近邻 K最近邻,就是K个最近的邻居的意思, ...
最新文章
- Maximum Subsequence Value CodeForces - 1365E(规律+暴力)
- 「前端工程化」该怎么理解?
- LeetCode 438. 找到字符串中所有字母异位词(滑动窗口)
- ifram嵌入网址 有跨域问题
- StorageEvent
- USACO Dual Palindrome
- Java笔记(十二) 文件基础技术
- 连线杂志:史上最强的恶意软件Stuxnet揭秘
- 微型计算机测试题答案,微机原理试题及答案(考试必备)
- 用什么材料作电磁屏蔽呢?
- X61的intel wireless 3945abg 不再掉线了
- itest考试切屏能检测出来吗_itest测试
- 判断一个数是否为4的倍数
- canvas全局合成画月牙_画房子一日营 | 园林设计写生系列课程
- 琼斯是计算体心立方弹性模量_固体物理 课后习题解答(黄昆版)第二章
- php yii2.0框架下载,yii2.0下载|yii2.0(php框架) v2.0.10官方版 附安装教程 - 121下载站...
- django3.0+ 使用 xadmin
- 最新WordPress漏洞,黑客可轻松控制您的网站
- java随机生成姓名、电话、邮箱、时间
- matlab中数字除以矩阵,Matlab中的矩阵除法有问题???