Detail-revealing Deep Video Super-resolution 论文笔记
视频超分辨 Detail-revealing Deep Video Super-resolution 论文笔记
简介
- 视频超分辨关注的主要问题有两个:一是如何充分利用多帧关联信息,而是如何有效地融合图像细节到高分辨率图像中。
- 动作补偿方面,深度学习方法用的是backward warping到参考帧,但这个方法其实并不是最优的。多帧融合方面,虽然很多CNN方法可以产生丰富的细节,但不能确定图像细节是来自内部的帧,还是外部的数据。在可缩放性方面,现有的方法对多尺度超分辨都不太灵活,包括ESPCN、VSRnet、VESPCN。
- 基于现状,作者提出一个sub-pixel motion compensation(SPMC)层,用来有效处理动作补偿和特征图缩放。另外,用一个基于LSTM的框架来处理多帧输入。
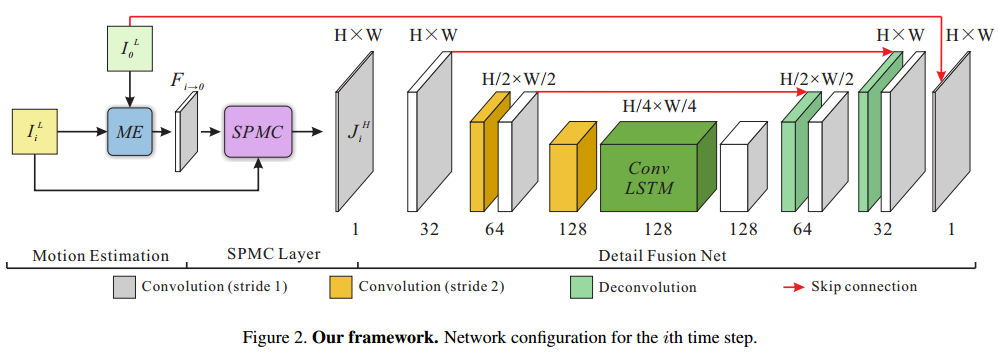
方法
- 作者提出的框架如图2所示。这个网络主要分成三个部分:motion estimation, motion compensation和detail fusion。
Motion Estimation
- motion estimation已经相对比较成熟了,方法有Flownet-S和VESPCN中的motion compensation transformer(MCT)。最后作者计划使用MCT。

Motion Compensation
- motion compensation用的就是SPMC层。首先记LR、HR图像分别为JLJ^L和JHJ^H。用公式可以表示为:

- 之前的模块已经得到帧之间的光流估计F=(u,v)F=(u,v),所以可以用Sampling Grid Generator生成格子(如下公式)。其中有一个α\alpha参数,说明在这一步分辨率就已经提高了(为什么要特地提高分辨率?)。

- 接着,用同样的方法重建出输出图像JHqJ^H_q:

- 在本文中,作者选择M(x)=max(0,1−|x|)M(x)=max(0,1-|x|),代表双线性插值核。
- 这个网络的好处是,没有额外的参数,并且可微,能够反向传播。
detail fusion net
- 经过SPMC层后,输出{JHi}\{J^H_i\}已经变成HR的尺寸了,但比较稀疏(大约有15/16的值都是0)。作者把detail fusion net设计成编码-解码风格。前面的卷积层降低了分辨率,也使得特征图不那么稀疏,多帧图片也分别进入了LSTM模块,处理帧内关联信息,之后再通过deconvolution。结构可以这么表示:

- 看最后输出的符号,这个是多入多出的网络?
训练方法
- 一口气进行端到端训练会在动作估计部分出现zero flow的问题,导致最后结果和单图像SR差不多,所以做了一个三步训练:
- 只训练motion estimation的参数。鉴于没有label,所以用无监督的warping loss。

- 固定ME的参数,训练后面的网络。

- 联合训练。

- 只训练motion estimation的参数。鉴于没有label,所以用无监督的warping loss。
实验
- 作者自己收集了一个数据集,有975个1080p HD视频序列,每个序列有31帧。HR的尺寸为540*960,LR的尺寸为270*480,180*320,135*240。训练集945个,测试集和验证集30个。下面只贴结果



Detail-revealing Deep Video Super-resolution 论文笔记相关推荐
- A Comprehensive Study of Deep Video Action Recognition 论文笔记
A Comprehensive Study of Deep Video Action Recognition 论文链接: https://arxiv.org/abs/2012.06567 一. Pro ...
- Collaborative Spatiotemporal Feature Learning for Video Action Recognition 论文笔记
论文笔记 1 引子 在本文中,我们提出了一种新颖的协作时空(CoST)特征学习操作,它与权重共享共同学习时空特征. 给定3D体积视频张量,我们通过从不同角度观看它们,将其展平为三组2D图像. ...
- 3D Bounding Box Estimation Using Deep Learning and Geometry 论文笔记
3D Bounding Box Estimation Using Deep Learning and Geometry 论文链接: https://arxiv.org/abs/1612.00496 一 ...
- [video super resolution] ESPCN论文笔记
ESPCN是twitter2017年提出来的实时视频超分辨率的方法.下面记录下对论文的一些理解. 上面这张图就是整个网络的架构.输入t帧的相邻图像,t-1和t+1,在具体的网络中,有输入连续3张,5张 ...
- CVPR 2017 《Deep Feature Flow for Video Recognition》论文笔记
本学弱喜欢在本子上记笔记,但字迹又丑. 望看不懂我的字的大佬不要喷我,看得懂的大佬批评指正.
- arXiv 2019 《DCA: Diversified Co-Attention towards Informative Live Video Commenting》论文笔记
目录 简介 动机 贡献 方法 实验 简介 北大电子工程与计算机科学学院.华科软件工程学院.北航软件学院合作的一篇文章,算是我看到的第二篇ALVC任务方面的论文,看这个版面和参考文献格式,感觉是投了IC ...
- A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification(论文笔记)(2019CVPR)
论文链接:<A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification> Abstra ...
- Towards High Performance Video Object Detection论文笔记
这篇文章可以说是很牛逼的又快有准的文章,对比之前的这个团队的deep feature fow(快)和Flow-guided feature aggregation(准),这篇文章可以说是又快又准.但是 ...
- 《TextBoxes: A Fast Text Detector with a Single Deep Neural Network》论文笔记
参考博文: 日常阅读论文,这是在谷歌学术上搜索其引用CRNN的相关文献中被引数量比较高的一篇OCR方向的文章,这里拿来读一读. 文章目录 make decision step1:读摘要 step2:读 ...
- X3D: Expanding Architectures for Efficient Video Recognition个人论文笔记
https://zhuanlan.zhihu.com/p/129279351 这篇X3D的解读写的比我早,写的挺好的,但有些细节没写上,所以由于强迫症写了这篇个人笔记 X3D为一系列的高效视频分类网络 ...
最新文章
- 打造数字原生引擎,易捷行云EasyStack发布新一代全栈信创云
- java线程入门篇(一)
- python怎么读write_Python如何读写文件?python写入文件读写操作详解
- MySQL 笔记3 -- SQL 语言
- PHP判断文章是否有图片,利用PHP判断文件是否为图片的方法总结
- 人与计算机的未来_身边的很多人都在学习计算机,学习计算机到底能带来哪些好处...
- 如何进行产品战略规划
- Ceph (1) - 安装Ceph集群方法 1:使用ceph-deploy安装Nautilus版Ceph集群
- 不要相信 errno 可靠
- Allegro给一个网络赋默认值,取消默认值
- Autodesk AutoCAD 2018 for Mac 汉化破解版安装教程
- 怎么把两个pdf合并成一个?
- 编译原理 NFA确定化与DFA最小化
- HWP转Word说明
- html如何实现统计访客功能,JS 实时网站访客(用户)统计
- Windows触控手势
- 看脸的时代,AI医美为什么没有成为风口?
- 【微信小程序】协同工作与发布
- MyBatis-第三章 动态SQL
- Java-JDK下载过慢的问题解决方案