rnns_告别rnns欢迎tcns
rnns
Disclaimer: this article assumes that readers possess preliminary knowledge behind the model intuition and architecture of LSTM neural networks.
免责声明:本文假设读者具有LSTM神经网络的模型直觉和体系结构背后的初步知识。
总览 (Overview)
Background of Deep Learning in FTS
FTS深度学习的背景
Noteworthy Data Preprocessing Practices for FTS
FTS值得注意的数据预处理实践
Temporal Convolutional Network Architecture
时间卷积网络架构
Example Application of Temporal Convolutional Networks in FTS
时间卷积网络在FTS中的示例应用
Knowledge-Driven Stock Trend Prediction and Explanation via TCN
通过TCN进行知识驱动的股票趋势预测和解释
1.背景 (1. Background)
Financial Time Series (FTS) modelling is a practice with a long history which first revolutionised algorithmic trading in the early 1970s. The analysis of FTS was divided into two categories: fundamental analysis and technical analysis. Both these practices were put into question by the Efficient Market Hypothesis (EMH). The EMH, highly disputed since its initial publication in 1970, hypothesizes that stock prices are ultimately unpredictable. This has not constrained research attempting to model FTS through the use of linear, non-linear and ML-based models, as mentioned hereafter.
金融时间序列(FTS)建模是一种历史悠久的实践,在1970年代初首次对算法交易进行了革新。 FTS的分析分为两类:基础分析和技术分析。 有效市场假说(EMH)对这两种做法都提出了质疑。 自从1970年首次发布以来,EMH一直备受争议,它假设股价最终是不可预测的。 如下所述,这并未限制尝试通过使用线性,非线性和基于ML的模型对FTS建模的研究。
Due to the nonstationary, nonlinear, high-noise characteristics of financial time series, traditional statistical models have difficulty predicting them with high precision. Hence, increased attempts in recent years are being made to apply deep learning to stock market forecasts, though far from perfection. To list a mere few:
由于金融时间序列具有非平稳,非线性,高噪声的特点,因此传统的统计模型很难准确预测它们。 因此,尽管远非完美,但近年来人们越来越多地尝试将深度学习应用于股票市场预测。 仅列出几个:
2013
2013年
Lin et al. proposed a method to predict stocks using a support vector machine to establish a two-part feature selection and prediction model and proved that the method has better generalization than conventional methods.
Lin 等。 提出了一种使用支持向量机建立两部分特征选择和预测模型的股票预测方法,证明了该方法具有比常规方法更好的泛化能力。
2014
2014年
Wanjawa et al. proposed an artificial neural network using a feed-forward multilayer perceptron with error backpropagation to predict stock prices. The results show that the model can predict a typical stock market.
Wanjawa 等 。 提出了一种人工神经网络,该网络使用具有误差反向传播的前馈多层感知器来预测股票价格。 结果表明,该模型可以预测典型的股票市场。
2017
2017年
Enter LSTM — a surge in studies concerning application of LSTM neural networks to the time series data.
输入 LSTM -在涉及应用LSTM神经网络的时间序列数据研究的激增。
Zhao et al., a time-weighted function was added to an LSTM neural network, and the results surpassed those of other models.
赵等。 ,将时间加权函数添加到LSTM神经网络,结果超过了其他模型。
2018
2018年
Zhang et al. later combined convolutional neural network (CNN) and recurrent neural network (RNN) to propose a new architecture, the deep and wide area neural network (DWNN). The results show that the DWNN model can reduce the predicted mean square error by 30% compared to the general RNN model.
张等。 后来结合了卷积神经网络(CNN)和递归神经网络(RNN)提出了一种新的体系结构,即广域神经网络(DWNN)。 结果表明,与常规RNN模型相比,DWNN模型可以将预测的均方误差降低30%。
Ha et al., CNN was used to develop a quantitative stock selection strategy to determine stock trends and then predict stock prices using LSTM to promote a hybrid neural network model for quantitative timing strategies to increase profits.
Ha 等 。 ,CNN被用于开发定量股票选择策略,以确定股票趋势,然后使用LSTM预测股票价格,以推广用于定量计时策略的混合神经网络模型,以增加利润。
Jiang et al. used an LSTM neural network and RNN to construct models and found that LSTM could be better applied to stock forecasting.
江等 。 使用LSTM神经网络和RNN构建模型,发现LSTM可以更好地应用于库存预测。
2019
2019年
Jin et al. added investor sentiment tendency in model analysis and introduced empirical modal decomposition (EMD) combined with LSTM to obtain more accurate stock forecasts. The LSTM model based on the attention mechanism is common in speech and image recognition but is rarely used in finance.
Jin 等 。 在模型分析中增加了投资者的情绪趋势,并引入经验模态分解(EMD)与LSTM相结合,以获得更准确的股票预测。 基于注意力机制的LSTM模型在语音和图像识别中很常见,但在金融领域却很少使用。
Radford et al. Precursor to the now hot-stock, GPT-3, GPT-2’s goal is to design a multitask learner, and it utilizes a combination of pretraining and supervised finetuning to achieve more flexible forms of transfer. Therefore it has 1542M parameters, much bigger than other comparative models.
Radford 等。 目前热门的GPT-3的前身, GPT-2的目标是设计一个多任务学习器,它将预训练和监督式微调相结合,以实现更灵活的传输形式。 因此,它具有1542M参数,比其他比较模型大得多。
Shumin et al. A knowledge-driven approach using Temporal Convolutional Network (KDTCN) for stock trend prediction and explanation. They first extracted structured events from financial news and utilize knowledge graphs to obtain event embeddings. Then, combine event embeddings and price values together to forecast stock trend. Experiments demonstrate that this can (i) react to abrupt changes much faster and outperform state-of-the-art methods on stock datasets. (This will be the focal point of this article.)
Shumin 等 。 一种使用时间卷积网络( KDTCN)进行知识趋势预测和解释的知识驱动方法。 他们首先从财经新闻中提取结构化事件,然后利用知识图获得事件嵌入。 然后,将事件嵌入和价格值结合在一起以预测库存趋势。 实验表明,该方法可以(i)更快地应对突然的变化,并且可以胜过股票数据集上的最新方法。 (这将是本文的重点。)
2020
2020年
Jiayu et al. and Thomas et al. proposed hybrid attention networks to predict stock trend based on the sequence of recent news. LSTMs with attention mechanisms outperforms conventional LSTMS as it prevents long-term dependencies due to its unique storage unit structure.
贾玉等 。 和托马斯等。 提出了一种基于最近新闻序列的混合注意力网络来预测股票趋势。 具有注意机制的LSTM优于传统LSTM,因为它具有独特的存储单元结构,可防止长期依赖。
Hongyan et al. proposed an exploratory architecture referred to Temporal Convolutional Attention-based Network (TCAN) which combines temporal convolutional network and attention mechanism. TCAN includes two parts, one is Temporal Attention (TA) which captures relevant features inside the sequence, the other is Enhanced Residual (ER) which extracts the shallow layer’s important information and transfers to deep layers.
红岩等。 提出了一种基于时间卷积注意力的网络(TCAN)的探索性架构,该架构结合了时间卷积网络和注意力机制。 TCAN包括两个部分,一个是时间注意(TA) ,它捕获序列中的相关特征,另一个是增强残差(ER) ,其提取浅层的重要信息并传输到深层。
The timeline above is merely meant to provide a glimpse into the historical context of FTS in deep learning but not downplay on the significant work contributed to by the rest of the sequence model academia during similar time periods.
上面的时间线仅是为了提供对FTS在深度学习中的历史背景的一瞥,而不是对其余时间序列学术界在相似时间段内所做的重要工作轻描淡写。
However, a word of caution is worth mentioning here. It might be the case that academic publications in the field of FTS forecasting are often misleading. Many FTS forecasting papers tend to inflate their performance for recognition and overfit their models due to the heavy use of simulators. Many of the performances claimed in these papers are difficult to replicate as they fail to generalise for future changes in the particular FTS being forecast.
但是,在此值得一提。 FTS预测领域的学术出版物可能经常会产生误导。 由于大量使用模拟器,许多FTS预测论文往往会夸大其性能以供识别和过拟合其模型。 这些论文中声称的许多性能难以复制,因为它们无法概括所预测的特定FTS的未来变化。
2. FTS值得注意的数据预处理实践 (2. Noteworthy Data Preprocessing Practices for FTS)
2.1去噪 (2.1 Denoising)
Financial time series data — especially stock prices, constantly fluctuate with seasonality, noise and autocorrection. Traditional methods of forecasting use moving averages and differencing to reduce the noise for forecasting. However, FTS is conventionally non-stationary and exhibits the overlapping of useful signals and noise, which makes traditional denoising ineffective.
金融时间序列数据(尤其是股票价格)会随着季节,噪声和自动更正而不断波动。 传统的预测方法使用移动平均值和微分来减少预测的噪声。 然而,FTS传统上是不稳定的,并且表现出有用信号和噪声的重叠,这使得传统的去噪无效。
Wavelet analysis has led to remarkable achievements in areas such as image and signal processing. With its ability to compensate for the shortcomings of Fourier analysis, it has gradually been introduced in the economic and financial fields. The wavelet transform has unique advantages in solving traditional time series analysis problems as it can decompose and reconstruct financial time series data from a different time and frequency domain scales.
小波分析在图像和信号处理等领域取得了令人瞩目的成就。 由于它具有弥补傅里叶分析缺点的能力,因此已逐渐引入经济和金融领域。 小波变换在解决传统时间序列分析问题方面具有独特的优势,因为它可以分解和重建来自不同时域和频域尺度的金融时间序列数据 。
Wavelet transform essentially uses multi-scale characteristics to denoise the dataset, effectively separating the useful signal from the noise. In a paper by Jiayu Qiu, Bin Wang, Changjun Zhou, they used the coif3 wavelet function with three decomposition layers, and evaluate the effect of the wavelet transform by its signal-to-noise ratio (SNR) and root mean square error (RMSE). The higher the SNR and the smaller the RMSE, the better the denoising effect of the wavelet transform:
小波变换本质上使用多尺度特征对数据集进行降噪,从而有效地将有用信号与噪声分离。 邱佳瑜,王斌,周长军的论文中,他们将coif3小波函数用于三个分解层,并通过其信噪比(SNR)和均方根误差(RMSE)来评估小波变换的效果。 )。 SNR越高,RMSE越小,小波变换的去噪效果越好 :

2.2数据混排 (2.2 Data Shuffling)
In FTS, the choice of which piece of data to use as the validation set is not trivial. Indeed, there exist a myriad of ways of doing this which must be carefully considered for stock indices of varying volatility.
在FTS中,选择哪个数据用作验证集并非易事。 确实,存在无数种执行此操作的方法,对于变化不定的股票指数,必须仔细考虑。
The fixed origin method is the most naive and common method used. Given a certain split size, the start of the data is the training set and the end is the validation set. However, this is a particularly rudimentary method to choose, especially for a high-growth stock like Amazon. The reason why this is the case is that Amazon’s stock price starts off with low volatility and, as the stock grows, experiences increasingly volatile behaviour.
固定原点方法是最幼稚和最常用的方法。 给定一定的拆分大小,数据的开始是训练集,而结束是验证集。 但是,这是一种特别基本的选择方法,对于像亚马逊这样的高增长股票而言尤其如此。 出现这种情况的原因是,亚马逊的股价始于低波动性,并且随着股票的增长,其行为也越来越不稳定。
We would therefore be training a model on low volatility dynamics and expect it to deal with unseen high volatility dynamics for its predictions. This has indeed shown itself to be difficult and come at a cost in performance for these types of stocks. Therefore our benchmark for validation loss and performance may be misleading if we only consider this. However, for stocks like Intel that are more constant in their volatility (pre-COVID crisis), this method is reasonable.
因此,我们将针对低波动率动态模型进行训练,并期望该模型能够处理其预测中看不见的高波动率动态模型。 对于这些类型的股票,这确实表明了自己的难度,并且以性能为代价。 因此,仅考虑这一点,我们的验证损失和性能基准可能会产生误导。 但是,对于像英特尔这样的波动性较为恒定的股票(COVID危机前),这种方法是合理的。
The rolling origin recalibration method is slightly less vulnerable than fixed origin as it allows the validation loss to be computed by taking the average of various different splits of the data to avoid running into unrepresentative issues with high volatility timeframes.
滚动原点重新校准方法比固定原点的脆弱性稍差一些,因为它允许通过对数据的各种不同拆分取平均值来计算验证损失,从而避免陷入高波动时间框架的不具代表性的问题。
Finally, the rolling window method is usually one of the most useful methods as it is particularly used for FTS algorithms being run for long timeframes. Indeed, this model outputs the average validation error of multiple rolling windows of data. This means the final values we get are more representative of recent model performance, as we are less biased by strong or poor performance in the distant past.
最后, 滚动窗口方法通常是最有用的方法之一,因为它特别适用于长时间运行的FTS算法。 实际上,该模型输出多个滚动数据窗口的平均验证误差。 这意味着我们获得的最终值更能代表近期的模型性能,因为我们在远古时代对强或弱性能的偏见较少。
A study done by Thomas Hollis, Antoine Viscardi, Seung Eun Yi indicated that both rolling window (RW) and rolling origin recalibration (ROR) describe very slightly better performances (58% and 60%) than that of the simple fixed origin method. This suggests that for volatile stocks like Amazon, using these shuffling methods would be inevitable.
由托马斯·霍利斯 ( Thomas Hollis),安托万·维斯卡迪(Antoine Viscardi)和成恩义(Seung Eun Yi)进行的一项研究表明,滚动窗口(RW)和滚动起点重新校准(ROR)都比简单固定起点方法的性能要好得多(58%和60%)。 这表明对于像亚马逊这样的动荡股票,使用这些洗牌方法将是不可避免的。

3.时间卷积网络 (3. Temporal Convolutional Network)
Temporal Convolutional Networks, or simply TCN, is a variation of Convolutional Neural Networks for sequence modelling tasks, by combining aspects of RNN and CNN architectures. Preliminary empirical evaluations of TCNs have shown that a simple convolutional architecture outperforms canonical recurrent networks such as LSTMs across a diverse range of tasks and datasets while demonstrating longer effective memory.
时间卷积网络 (简称TCN)是卷积神经网络的一种变体,它通过结合RNN和CNN架构的方面来进行序列建模任务。 对TCN的初步经验评估表明,简单的卷积体系结构在各种任务和数据集上均表现出优于LSTM的规范化递归网络,同时展示了更长的有效内存。
The distinguishing characteristics of TCNs are:
TCN的区别特征是:
The convolutions in the architecture are causal, meaning that there is no information “leakage” from future to past.
体系结构中的卷积是因果关系的,这意味着从将来到过去都不会发生信息“泄漏”。
The architecture can take a sequence of any length and map it to an output sequence of the same length, just as with an RNN. TCNs possess very long effective history sizes (i.e., the ability for the networks to look very far into the past to make a prediction) using a combination of very deep networks (augmented with residual layers) and dilated convolutions.
与RNN一样,该体系结构可以采用任意长度的序列并将其映射到相同长度的输出序列。 TCN具有非常长的有效历史记录大小(即,网络可以使用非常深的过去进行预测的能力),可以结合使用非常深的网络(带有残差层)和膨胀卷积。
3.1模型架构概述 (3.1 Model Architecture Overview)
3.1.1 Causal Convolutions
3.1.1因果卷积
As mentioned above, the TCN is based upon two principles: the fact that the network produces an output of the same length as the input, and the fact that there can be no leakage from the future into the past. To accomplish the first point, the TCN uses a 1D fully-convolutional network (FCN) architecture, where each hidden layer is the same length as the input layer, and zero padding of length (kernel size − 1) is added to keep subsequent layers the same length as previous ones. To achieve the second point, the TCN uses causal convolutions, convolutions where output at time t is convolved only with elements from time t and earlier in the previous layer.
如上所述,TCN基于两个原则:网络产生与输入长度相同的输出,以及从将来到过去都不会泄漏的事实。 为了完成第一点,TCN使用一维全卷积网络(FCN)架构,其中每个隐藏层的长度与输入层的长度相同,并且添加了零填充长度(内核大小− 1)以保留后续层与以前的长度相同 。 为了达到第二点,TCN使用因果卷积 ,即在卷积中时间t的输出仅与时间t或更早的上一层中的元素卷积。
To put it simply: TCN = 1D FCN + causal convolutions.
简单地说: TCN = 1D FCN +因果卷积。
3.1.2 Dilated Convolutions
3.1.2膨胀卷积
A simple causal convolution is only able to look back at a history with size linear in the depth of the network. This makes it challenging to apply the aforementioned causal convolution on sequence tasks, especially those requiring a longer history. The solution implemented by Bai, Kolter and Koltun (2020), was to employ dilated convolutions that enable an exponentially large receptive field. More formally, for a 1-D sequence input x ∈ Rⁿ and a filter f:{0,…,k−1}→R, the dilated convolution operation F on element s of the sequence is defined as:
一个简单的因果卷积只能回顾网络深度为线性的历史。 这使得将上述因果卷积应用于序列任务,特别是那些需要较长历史记录的任务具有挑战性。 Bai,Kolter和Koltun(2020 )实施的解决方案是采用膨胀卷积,以实现指数级大的接收场。 更正式地,对于一维序列输入x∈Rⁿ和滤波器f:{0,…,k-1}→R,对该序列元素s的扩张卷积运算F定义为:
where d is the dilation factor, k is the filter size, and s − d · i accounts for the direction of the past. Dilation is thus equivalent to introducing a fixed step between every two adjacent filter taps. When d = 1, a dilated convolution reduces to a regular convolution. Using larger dilation enables an output at the top level to represent a wider range of inputs, thus effectively expanding the receptive field of a ConvNet.
其中d是扩张因子, k是滤波器大小, s - d · i代表过去的方向。 因此,膨胀等效于在每两个相邻的滤波器抽头之间引入一个固定的阶跃。 当d = 1时,膨胀卷积减小为规则卷积。 使用较大的膨胀可使顶层的输出代表更大范围的输入,从而有效地扩展了ConvNet的接收范围。

3.1.3 Residual Connections
3.1.3残余连接
Residual blocks effectively allow layers to learn modifications to the identity mapping rather than the entire transformation, which has repeatedly been shown to benefit very deep networks.
残留块有效地允许层学习对身份映射的修改,而不是整个转换,这已反复证明对非常深的网络有利。
Since a TCN’s receptive field depends on the network depth n as well as filter size k and dilation factor d, stabilization of deeper and larger TCNs becomes important.
由于TCN的接收场取决于网络深度n以及滤波器大小k和扩散因子d ,因此更深和更大的TCN的稳定化变得很重要。
3.2利弊 (3.2 Pros & Cons)
Several advantages of using TCNs for sequence modelling:
使用TCN进行序列建模的几个优点:
Parallelism. Unlike in RNNs where the predictions for later timesteps must wait for their predecessors to complete, convolutions can be done in parallel since the same filter is used in each layer. Therefore, in both training and evaluation, a long input sequence can be processed as a whole in TCN, instead of sequentially as in RNN.
并行性 。 与RNN中的后继时间步长的预测必须等待其前任完成之前的RNN不同,卷积可以并行完成,因为每一层都使用相同的滤波器。 因此,在训练和评估中,可以在TCN中整体上处理一个长输入序列,而不是像RNN中那样顺序处理。
Flexible receptive field size. A TCN can change its receptive field size in multiple ways. For instance, stacking more dilated (causal) convolutional layers, using larger dilation factors, or increasing the filter size are all viable options. TCNs thus afford better control of the model’s memory size and are easy to adapt to different domains.
灵活的接收场大小。 TCN可以多种方式更改其接收字段的大小。 例如,使用更大的膨胀因子堆叠更多的膨胀(因果)卷积层或增加过滤器尺寸都是可行的选择。 因此,TCN可以更好地控制模型的内存大小,并且易于适应不同的域。
Stable gradients. Unlike recurrent architectures, TCN has a backpropagation path different from the temporal direction of the sequence. TCN thus avoids the problem of exploding/vanishing gradients, which is a major issue for RNNs (and which led to the development of LSTM and GRU).
稳定的渐变 。 与循环架构不同,TCN的反向传播路径与序列的时间方向不同。 因此,TCN避免了爆炸/消失梯度的问题,这是RNN的主要问题(并导致了LSTM和GRU的发展)。
Low memory requirement for training. Especially in the case of a long input sequence, LSTMs and GRUs can easily use up a lot of memory to store the partial results for their multiple cell gates. However, in a TCN the filters are shared across a layer, with the backpropagation path depending only on network depth. Therefore in practice, it was found that gated RNNs are likely to use up to a multiplicative factor more memory than TCNs.
训练的记忆力低 。 尤其是在输入序列较长的情况下,LSTM和GRU可以轻松地消耗大量内存来存储其多个单元门的部分结果。 但是,在TCN中,过滤器是跨层共享的,反向传播路径仅取决于网络深度。 因此,在实践中发现,门控RNN可能比TCN占用最多乘数的内存。
Variable length inputs. Just like RNNs, which model inputs with variable lengths in a recurrent way, TCNs can also take in inputs of arbitrary lengths by sliding the 1D convolutional kernels. This means that TCNs can be adopted as drop-in replacements for RNNs for sequential data of arbitrary length.
可变长度输入 。 就像RNN以循环方式对可变长度的输入进行建模一样,TCN也可以通过滑动一维卷积内核来接受任意长度的输入。 这意味着,对于任意长度的顺序数据,可以将TCN用作RNN的直接替代。
Two notable disadvantages to using TCNs:
使用TCN的两个明显的缺点:
Data storage during evaluation. TCNs need to take in the raw sequence up to the effective history length, thus possibly requiring more memory during evaluation.
评估期间的数据存储 。 TCN需要采用原始序列,直到有效的历史记录长度,因此在评估期间可能需要更多的存储空间。
Potential parameter change for a transfer of domain. Different domains can have different requirements on the amount of history the model needs in order to predict. Therefore, when transferring a model from a domain where only little memory is needed (i.e., small k and d) to a domain where much longer memory is required (i.e., much larger k and d), TCN may perform poorly for not having a sufficiently large receptive field.
域转移的潜在参数更改。 不同领域对模型进行预测所需的历史记录数量可能有不同的要求。 因此,当将模型从仅需要很少内存(即,较小的k和d )的域转移至需要更长内存(即,较大的k和d )的域时,TCN可能会因为没有足够大的接收场。
3.3基准 (3.3 Benchmark)
Executive summary:
执行摘要:
The results strongly suggest that the generic TCN architecture with minimal tuning outperforms canonical recurrent architectures across a broad variety of sequence modelling tasks that are commonly used to benchmark the performance of recurrent architectures themselves.
结果强烈表明,在各种序列建模任务(通常用于对循环体系结构本身的性能进行基准测试)中, 具有最少调整的通用TCN体系结构的性能优于规范的循环体系结构。
4.通过TCN进行知识驱动的股票趋势预测和解释 (4. Knowledge-Driven Stock Trend Prediction and Explanation via TCN)
4.1背景 (4.1 Background)
Most of the deep neural networks in stock trend prediction have two common drawbacks: (i) current methods are not sensitive enough to abrupt changes of stock trend, and (ii) forecasting results are not interpretable for humans. To address these two problems, Deng et al., 2019 proposed a novel Knowledge-Driven Temporal Convolutional Network (KDTCN) for stock trend prediction and explanation, by incorporating background knowledge, news events and price data into deep prediction models, to tackle the problem of stock trend prediction and explanation with abrupt changes.
股票趋势预测中的大多数深度神经网络都有两个共同的缺点:(i) 当前的方法对股票趋势的突然变化不够敏感 ,(ii) 人类无法预测预测结果 。 为了解决这两个问题, Deng等人(2019)提出了一种新颖的知识驱动的时间卷积网络(KDTCN) ,通过将背景知识,新闻事件和价格数据整合到深度预测模型中来进行股票趋势预测和解释,以解决该问题。变化趋势的股票趋势预测和解释。
To address the problem of prediction with abrupt changes, events from financial news are extracted and structurized into event tuples, e.g., “Britain exiting from EU ” is represented as (Britain, exiting from, EU ). Then entities and relations in event tuples are linked to KGs, such as Freebase and Wikidata. Secondly, structured knowledge, textual news, as well as price values are vectorized respectively, and then concatenated together. Finally, feed these embeddings into a TCN-based model.
为了解决与急剧变化预测的问题,从金融新闻事件被提取和结构化到事件的元组,例如,“从英国退出欧盟的”被表示为( 英国 从 欧盟 退出 )。 然后,将事件元组中的实体和关系链接到KG,例如Freebase和Wikidata。 其次,将结构化知识,文本新闻以及价格值分别矢量化,然后连接在一起。 最后,将这些嵌入内容放入基于TCN的模型中。
Experiments demonstrate that KDTCN can (i) react to abrupt changes much faster and outperform state-of-the-art methods on stock datasets, as well as (ii) facilitate the explanation of prediction particularly with abrupt changes.
实验表明,KDTCN可以(i)更快地对突然变化做出React,并且在股票数据集上的表现优于最新技术,以及(ii)有助于特别是对于突然变化的预测解释。
Furthermore, based on prediction results with abrupt changes, to address the problem of making explanations, the effect of events are visualized by presenting the linkage among events with the use of Knowledge Graphs (KG). By doing so, we can make explanations of (i) how knowledge-driven events influence the stock market fluctuation in different levels, and (ii) how knowledge helps to associate events with abrupt changes in stock trend prediction.
此外,基于具有突然变化的预测结果,以解决做出解释的问题,通过使用知识图谱(KG)呈现事件之间的链接,可以可视化事件的效果。 通过这样做,我们可以做出以下解释:(i)知识驱动的事件如何在不同程度上影响股市波动;(ii)知识如何帮助将事件与股票趋势预测的突然变化相关联。
Note the section below merely summarizes into a broad overview of the paper Shumin et al., if you could refer to the paper if you seek further technical details.
请注意 ,如果您需要进一步的技术细节,请参考本文, 以下部分只是对 Shumin等人 的论文进行了概述 。
4.2模型架构概述 (4.2 Model Architecture Overview)
The fundamental TCN model architecture mentioned here is derived from Section 3 above —a generic TCN architecture consisting of causal convolutions, residual connections and dilated convolutions.
这里提到的基本TCN模型体系结构是从上面的第3节派生而来的-一种通用的TCN体系结构,由因果卷积,残差连接和膨胀卷积组成。
The overview of KDTCN architecture is shown below:
KDTCN体系结构概述如下所示:
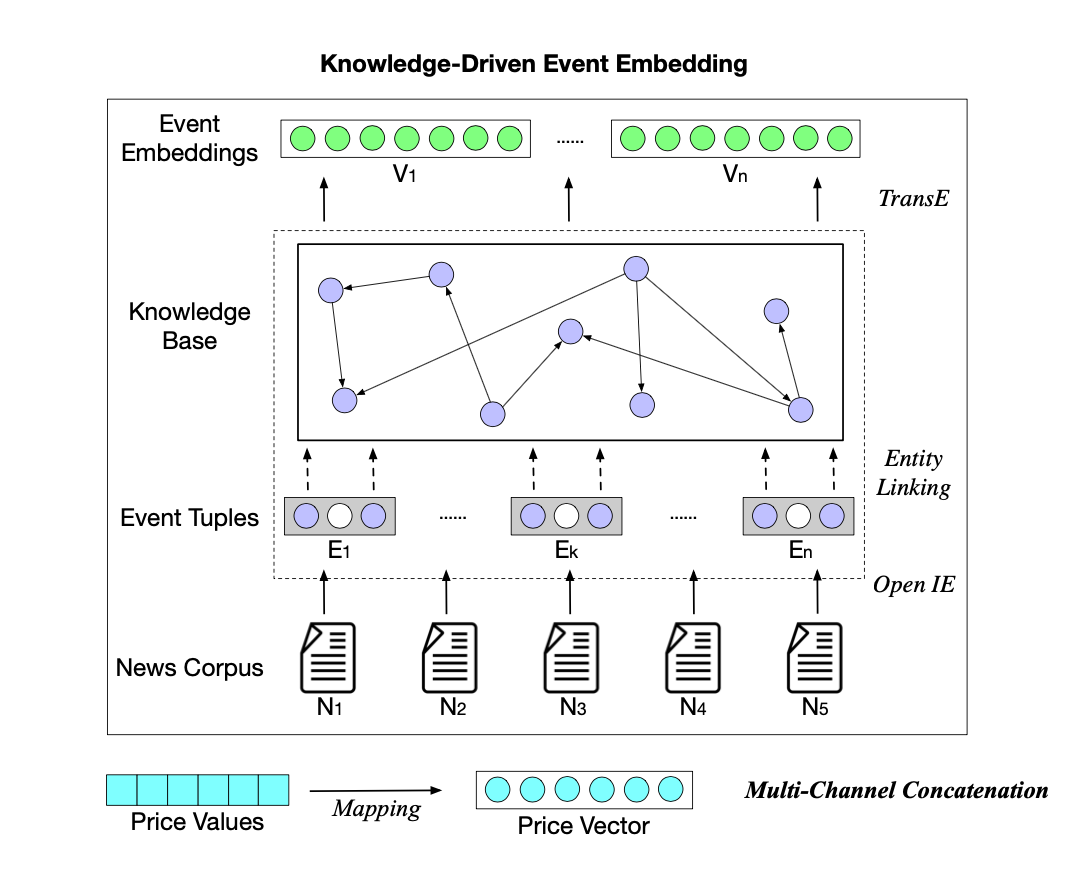
Original model inputs are price values X, news corpus N , and knowledge graph G. The price values are normalized and mapped into the price vector, denoted by
原始模型输入是价格值X , 新闻语料库N和知识图G。 价格值已标准化并映射到价格向量中,表示为
where each vector pt represents a real-time price vector on a stock trading day t, and T is the time span.
其中每个向量p t代表股票交易日t上的实时价格向量,而T是时间跨度。
As for news corpus, pieces of news are represented as event sets, ε; then, structured into event tuple e = (s, p, o), where p is the action/predicate, s is the actor/subject and o is the object on which the action is performed; then, each item in the event tuples is linked to KG, correspond to entities and relations in KG; lastly, event embeddings V are obtained by training both event tuples and KG triples. A more detailed of this process is documented in Shumin et al.
对于新闻语料库,新闻片段表示为事件集ε ; 然后,构造成事件元组e =(s,p,o) ,其中p是动作/谓词, s是角色/主体, o是在其上执行动作的对象; 然后,将事件元组中的每个项目链接到KG,对应于KG中的实体和关系。 最后,通过训练事件元组和KG三元组获得事件嵌入V。 Shumin 等人在文档中详细介绍了此过程。
Finally, event embeddings, combined with price vectors are input into a TCN-based model.
最后,将事件嵌入与价格向量相结合,输入基于TCN的模型。
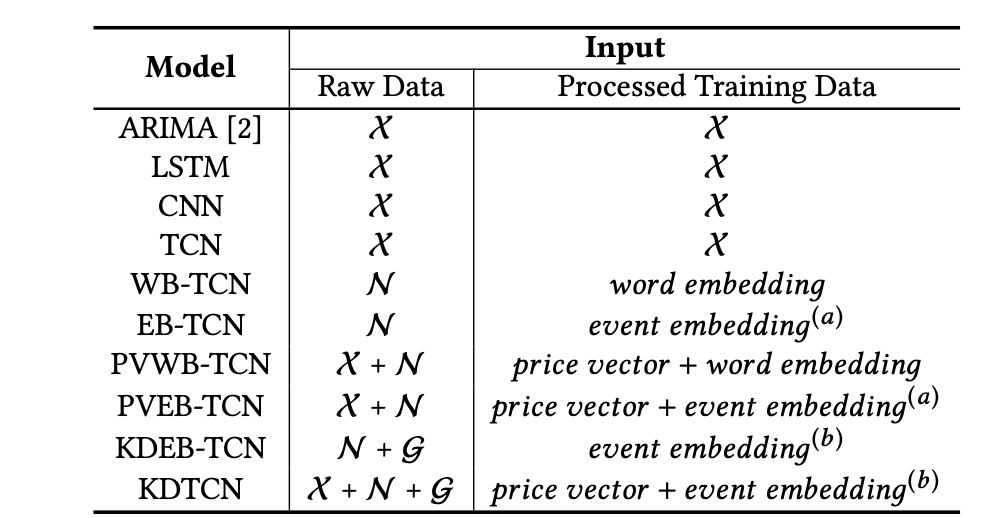
4.2.1数据集和基准 (4.2.1 Datasets & Baselines)
Datasets:
数据集:
Time-series Price Data X: The price dataset of daily value records of DJIA index
时间序列价格数据X : DJIA指数每日价值记录的价格数据集
Textual News Data N: News dataset composed of historical news headlines from Reddit WorldNews Channel (top 25 posts based on votes).
文字新闻数据N:由Reddit WorldNews频道的历史新闻头条组成的新闻数据集(根据投票数排名前25位)。
Structured Knowledge Data G: A sub-graph constructed from the structured data of two commonly used open knowledge graphs for research — Freebase and the Wikidata.
结构化知识数据G:从两个常用的开放式知识图(Freebase和Wikidata)的结构化数据构建的子图。
Baselines:
基线:
4.4预测评估 (4.4 Prediction Evaluation)
Performance of KDTCN was benchmarked in three progressive aspects: (i) evaluation of basic TCN architecture, (ii) influence of different model inputs with TCN, and (iii) TCN-based model performance for abrupt changes.
KDTCN的性能在三个方面进行了基准测试:(i)基本TCN体系结构的评估,(ii)不同模型输入对TCN的影响,以及(iii)基于TCN的模型对于突然变化的性能。
Basic TCN Architecture:
TCN基本架构:
Note that all experiments reported in this part are only input with price values.
请注意,此部分报告的所有实验仅输入价格值 。
TCN greatly outperforms baseline models on the stock trend prediction task. TCN achieves much better performance than either traditional ML models (ARIMA), or deep neural networks (such as LSTM and CNN), indicating that TCN has more obvious advantages in sequence modeling and classification problems.
在股票趋势预测任务上,TCN大大优于基线模型。 与传统的ML模型(ARIMA)或深度神经网络(例如LSTM和CNN)相比,TCN的性能要好得多,这表明TCN在序列建模和分类问题上具有更明显的优势。
Different Model Inputs with TCN:
使用TCN的不同模型输入:
As seen, WB-TCN and EB-TCN both get better performance than TCN, indicating textual information helps to improve forecasting.
如图所示,WB-TCN和EB-TCN均比TCN获得更好的性能,表明文本信息有助于改善预测。
KDTCN gets both the highest accuracy and F1 scores, and such a result demonstrates the validity of model input integration with structured knowledge, financial news, and price values.
KDTCN获得最高的准确性和F1得分,并且这样的结果证明了模型输入与结构化知识,财务新闻和价格值的集成的有效性。
Model Performance for Abrupt Changes:
突发变化的模型性能:
It was observed that models with knowledge-driven event embedding input, such as KDEB-TCN and KDTCN, can greatly outperform numerical-data-based and textual-data-based models. These comparison results indicate that knowledge-driven models have advantages in reacting to abrupt changes in the stock market swiftly.
据观察,具有知识驱动的事件嵌入输入的模型(例如KDEB-TCN和KDTCN)可以大大胜过基于数字数据和基于文本数据的模型。 这些比较结果表明,知识驱动的模型在Swift应对股市的突然变化方面具有优势。
Additional note on how the degree of stock fluctuation is quantified below.
有关如何量化库存波动程度的其他说明,请参见下文。
First, get time intervals of abrupt changes by figuring out the difference of stock fluctuation degree D(fluctuation) between two adjacent stock trading days
首先,通过计算两个相邻股票交易日之间的股票波动程度D( 波动)的差,得出突变的时间间隔
where x at time t denotes the stock price value on the stock trading day t. Then the difference of fluctuation degree C is defined by:
其中,时间t处的x表示股票交易日t的股票价格值。 然后,将波动程度C的差定义为:
If |Ci | exceeds a certain threshold, it can be considered that the stock price abruptly changes at the ith day.
如果| Ci | 超过某个阈值,可以认为股价在第i天突然变化。
4.1.4预测说明 (4.1.4 Explanation for Predictions)
Explanations for why knowledge-driven events are common sources of abrupt changes to human without ML expertise are accomplished in two aspects: (i) visualizing effects of knowledge-driven events on prediction results with abrupt changes, and (ii) retrieving background facts of knowledge-driven events by linking the events to external KG.
为何在没有ML专业知识的情况下知识驱动事件是导致人类突然改变的常见原因的解释从两个方面完成:(i) 可视化知识驱动事件对具有突然改变的预测结果的影响,以及(ii) 检索知识的背景事实通过将事件链接到外部KG来驱动事件 。
Effect Visualization of Events:
事件的效果可视化:
The prediction result in the figure below is that trend of DJIA index will drop. Note that the bars of the same colour have the same event effect, the height of bars reflects the degree of effects, and the event popularity declines from left to right. Intuitively, events with higher popularity should have greater effects on stock trend prediction with abrupt changes, but not always.
下图的预测结果是DJIA指数的趋势将下降。 请注意,相同颜色的条具有相同的事件效果,条的高度反映了效果的程度,事件受欢迎程度从左到右下降。 从直觉上讲,具有较高知名度的事件应在突然变化的情况下对股票趋势预测产生更大的影响,但并不总是如此。
Nearly all other events with negative effect are related to these two events, e.g., (British Pound, drops, nearly 5%) and (Northern Ireland, calls for poll on United Ireland).
几乎所有其他具有负面影响的事件都与这两个事件有关, 例如 ,( 英镑,跌幅接近5% )和( 北爱尔兰,要求对联合爱尔兰进行民意调查 )。
Although there are also some events have positive effects of predicting stock trend to rise, and have high popularity, i.e., (Rich, Getting, Richer), the total effect is negative. Therefore, abrupt changes of the stock index fluctuation can be viewed as the combined result of effects and popularity of events.
虽然也有一些事件有预测股票走势上涨的积极影响,并有很高的人气, 即 ,( 富,获取更丰富 ),总的影响是消极的。 因此,可以将股指波动的突然变化视为事件的影响和流行的综合结果。
Visualization of Event Tuples Linked to KG:
链接到KG的事件元组的可视化:
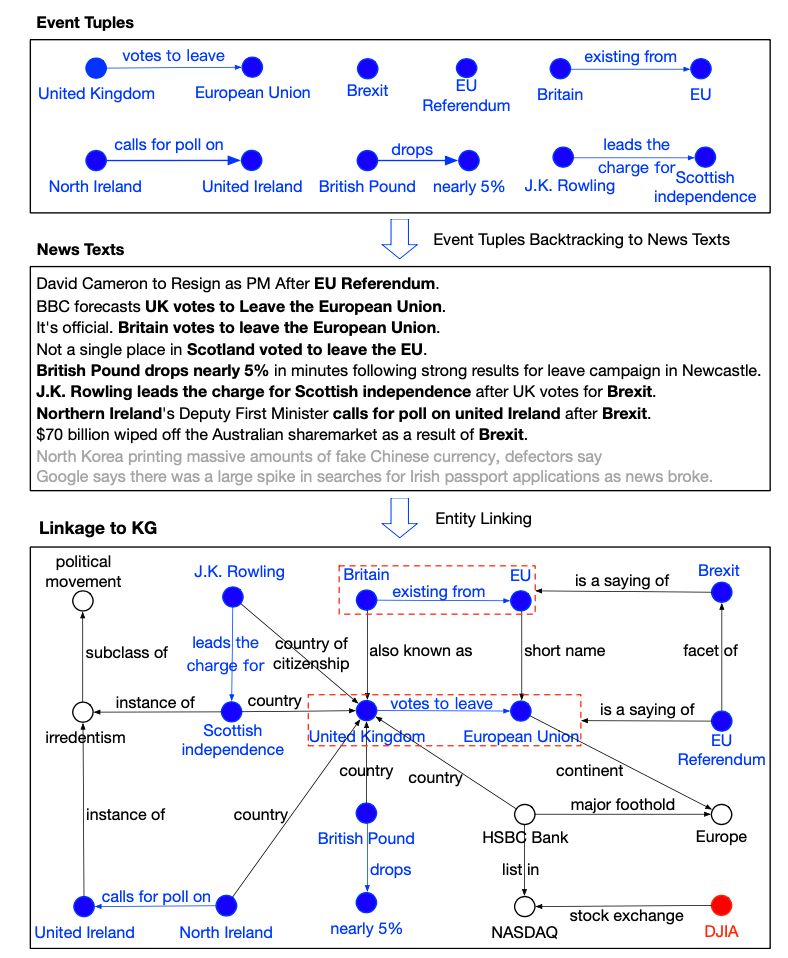
First, the event tuples with great effects or high popularity in stock trend movements were searched. Then, backtrack to the news texts containing these events. Finally, retrieve associated KG triples linked to event tuples by entity linking. In the above figure, each event tuple is marked in blue, and entities in it are linked to KG.
首先,搜索在股票趋势运动中具有巨大影响或很高知名度的事件元组。 然后,回溯到包含这些事件的新闻文本。 最后,通过实体链接检索关联到事件元组的关联的KG三元组。 在上图中,每个事件元组都标记为蓝色,并且其中的实体链接到KG。
These listed event tuples, such as (Britain, exiting from, EU ), (United Kingdom, votes to leave, European Union), (British Pound, drops, nearly 5%), (J. K. Rowling, leads the charge for, Scottish independence), and (Northern Ireland, calls for poll on United Ireland), are not strongly relevant literally. However, with the linkage to KG, they can establish an association with each other, and strongly related to events of Brexit and EU Referendum. By incorporating explanations of event effects, it could be justified that knowledge-driven events are common sources of abrupt changes.
这些列出的事件元组,例如( 英国,从欧盟退出 ),( 英国,离开欧盟的票数 ),( 英镑,跌幅近5% ),( JK Rowling负责苏格兰独立) )和( 北爱尔兰,要求对联合爱尔兰进行民意测验)在字面上并不是很重要。 但是,通过与KG的联系,他们可以彼此建立联系,并且与英国退欧和欧盟公投事件密切相关。 通过结合事件影响的解释,可以证明知识驱动的事件是突变的常见来源。
5.结论 (5. Conclusion)
The preeminence enjoyed by recurrent networks in sequence modelling may be largely a vestige of history. Until recently, before the introduction of architectural elements such as dilated convolutions and residual connections, convolutional architectures were indeed weaker. The recent academic research has indicated that with these elements, a simple convolutional architecture is more effective across diverse sequence modelling tasks than recurrent architectures such as LSTMs. Due to the comparable clarity and simplicity of TCNs, it was proposed in Bai, S., Kolter, J. and Koltun, V., 2020, that convolutional networks should be regarded as a natural starting point and a powerful toolkit for sequence modelling.
循环网络在序列建模中享有的优势可能在很大程度上是历史的遗迹。 直到最近,在引入诸如卷积卷积和残差连接之类的体系结构元素之前,卷积体系结构确实还比较弱。 最近的学术研究表明,利用这些元素,简单的卷积架构在各种序列建模任务中比LSTM等递归架构更有效。 由于TCN具有相当的清晰度和简单性, Bai,S.,Kolter,J.和Koltun,V.,2020年提出 , 卷积网络应该被视为自然的起点和强大的序列建模工具。
Furthermore, as seen in the application of TCNs in stock trend prediction above, by incorporating news event and knowledge graphs, TCNs could significantly outperform canonical RNNs.
此外,从上述TCN在股票趋势预测中的应用可以看出,通过合并新闻事件和知识图,TCN可以大大胜过规范RNN。
引用与参考 (Citations and References)
[1] Hollis, T., Viscardi, A. and Yi, S. (2020). “A Comparison Of Lstms And Attention Mechanisms For Forecasting Financial Time Series”.
[1] Hollis,T.,Viscardi,A.和Yi,S.(2020)。 “ 用于预测财务时间序列的Lstms和注意机制的比较” 。
[2] Qiu J, Wang B, Zhou C. (2020). “Forecasting stock prices with long-short term memory neural network based on attention mechanism”.
[2] 邱健,王冰,周丙(2020)。 “ 基于注意力机制的长短期记忆神经网络预测股票价格”。
[3] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. (2020). “Neural Machine Translation By Jointly Learning To Align And Translate”.
[3] Bahdanau,Dzmitry,Kyunghyun Cho和Yoshua Bengio。 (2020)。 “通过共同学习对齐和翻译来进行神经机器翻译” 。
[4] Bai, S., Kolter, J. and Koltun, V., 2020. “An Empirical Evaluation Of Generic Convolutional And Recurrent Networks For Sequence Modeling”.
[4] Bai,S.,Kolter,J.和Koltun,V.,2020年。“ 基于通用卷积和递归网络进行序列建模的实证评估” 。
[6] Deng, S., Zhang, N., Zhang, W., Chen, J., Pan, J. and Chen, H., 2019. “Knowledge-Driven Stock Trend Prediction and Explanation via Temporal Convolutional Network”.
[6] 邓S.,张N.,张W.,Chen,J.,Pan,J.和Chen,H.,2019。“ 通过时间卷积网络的知识驱动型股票趋势预测和解释” 。
[5] Hao, H., Wang, Y., Xia, Y., Zhao, J. and Shen, F., 2020. “Temporal Convolutional Attention-Based Network For Sequence Modeling”.
[5] Hao,H.,Wang,Y.,Xia,Y.,Zhao,J.和Shen,F.,2020。“ 基于时序卷积注意力的序列建模网络” 。
翻译自: https://towardsdatascience.com/farewell-rnns-welcome-tcns-dd76674707c8
rnns
相关文章:
- KNIME Explorer用户指南
- 发那科机器人示教盒复位键是哪个_发那科示教器专业维修 二手FANUC示教器销售...
- 汇总css布局模型和常见代码缩写与长度单位
- 告别RNN,迎来TCN!将深度学习应用于股市预测
- Devops 开发运维基础篇之使用Maven编译和打包项目
- 矩阵分析与应用-1.9-Moore-Penrose逆矩阵-Section3
- 基于LSTM、RNN及滑动窗口CNN模型的股票价格预测
- 用Calibre 转mobi 到 DOC (WORD) 的方法
- 我是如何走上运维岗位的?
- 【笨嘴拙舌WINDOWS】实践检验之剪切板查看器【Delphi】
- 【笨嘴拙舌WINDOWS】实践检验之按键精灵【Delphi】
- 【笨嘴拙舌WINDOWS】实践检验之屏幕取色
- 【笨嘴拙舌WINDOWS】实践检验之GDI缩放
- 【笨嘴拙舌WINDOWS】键盘消息,鼠标消息
- 【笨嘴拙舌WINDOWS】GDI(2)
- 【笨嘴拙舌WINDOWS】GDI(1)
- 【笨嘴拙舌WINDOWS】伟大的变革
- 【笨嘴拙舌WINDOWS】GDI映射方式
- 【笨嘴拙舌WINDOWS】GDI绘制区域
- 【笨嘴拙舌WINDOWS】计时器精度
- 【笨嘴拙舌WINDOWS】SetCapture和ReleaseCapture
- 【笨嘴拙舌WINDOWS】BMP图片浏览器
- 【笨嘴拙舌WINDOWS】编码历史
- 【笨嘴拙舌WINDOWS】窗体样式
- 【笨嘴拙舌WINDOWS】消息机制
- 【笨嘴拙舌WINDOWS】tagTEXTMETRIC结构
- 【笨嘴拙舌WINDOWS】剪切板
- 【笨嘴拙舌WINDOWS】API
- 有了蒲公英智能组网我对向日葵、TeamViewer等远程控制软件说拜拜
- 楼房墙角的蒲公英花
rnns_告别rnns欢迎tcns相关推荐
- 论文阅读 Skeleton-based abnormal gait recognition with spatio-temporal attention enhanced
Skeleton-based abnormal gait recognition with spatio-temporal attention enhanced gait-structural gra ...
- android 高通平台有前途吗,华为鸿蒙计划要适配高通平台了,可以告别安卓搭载鸿蒙OS了?...
鸿蒙走出这一步是可以想象到的,看来华为打造这个系统希望的结果是万物皆可盘呀,所以一开始就提出了开源,也就意味着这次是高通,下次就可以是联发科,甚至更多的手机品牌也完全就可以搭载!早期我们一直在说国产手 ...
- 北师大历史系65 级同学聚会宁夏【之七】——在中阿之轴、西夏王陵、董府、板桥道堂、鸿乐府及告别宴会...
北师大历史系65级同学在中阿之轴 庞心田.王庆云.李建宇.樊淑爱.何明书.郑文范.李建宇夫人.惠晓秋.边聪民.登高夫人.张登高.杨家兴.杨森翔 西夏王陵 北师大历史系65级同学在西夏王陵 北师大历史系 ...
- 告别CNN?一张图等于16x16个字,计算机视觉也用上Transformer了
编译 | 凯隐 出品 | AI科技大本营(ID:rgznai100) Transformer是由谷歌于2017年提出的具有里程碑意义的模型,同时也是语言AI革命的关键技术.在此之前的SOTA模型都是以 ...
- 12种主要的Dropout方法:用于DNNs,CNNs,RNNs中的数学和可视化解释
深入了解DNNs,CNNs以及RNNs中的Dropout来进行正则化,蒙特卡洛不确定性和模型压缩的方法. 动机 在深度机器学习中训练一个模型的主要挑战之一是协同适应.这意味着神经元是相互依赖的.他们对 ...
- 告别2019:属于深度学习的十年,那些我们必须知道的经典
选自leogao.dev 作者:Leo Gao,机器之心 参与:一鸣.泽南.蛋酱 2020 新年快乐! 当今天的太阳升起时,我们正式告别了上一个十年. 在这十年中,伴随着计算能力和大数据方面的发展,深 ...
- 仅靠合成数据就能实现真实人脸分析!微软这项新研究告别人工标注
点击上方"视学算法",选择加"星标"或"置顶" 重磅干货,第一时间送达 杨净 发自 凹非寺 量子位 报道 | 公众号 QbitAI 相信吗? ...
- 告别 CNN?一张图等于 16x16 个字,计算机视觉也用上 Transformer 了
编译 | 凯隐 出品 | AI科技大本营(ID:rgznai100) Transformer是由谷歌于2017年提出的具有里程碑意义的模型,同时也是语言AI革命的关键技术.在此之前的SOTA模型都是以 ...
- 介绍一款 API 敏捷开发工具,告别加班!
作者:棒锤 来源:xie.infoq.cn/article/b5c3a339267e1351c6151b42a_ 初衷 用尽可能简单的方式,完成尽可能多的需求.通过约定的方式 实现统一的标准.告别加班 ...
最新文章
- 和linux关系_Linux内核Page Cache和Buffer Cache关系及演化历史
- jquery DataTable默认显示指定页
- 【程序员面试宝典】强制类型转换之面试例题2
- pycharm+itk+vtk安装及测试程序运行
- c#.net2005 调用evc4.0生成的dll文件
- pip升级python版本_GEE学习笔记 六十八:【GEE之Python版教程二】配置Python开发环境...
- WARNING: Ignoring invalid distribution -ip
- 测试集没标签,可以拿来测模型吗?
- Codeforces 583 DIV2 Robot's Task 贪心
- 策略模式详解(用java语言实现策略模式)
- 装上WPS后导入Excel 的代码出错
- 《HTTP权威指南》思维导图一览全书
- 在计算机检索中 有哪些方法能缩小,使用“或OR”运算将同义词连接起来可以缩小检索。()...
- Linux修改文件编码格式的三种方式
- VUE2.X全教程--基础详解(二)
- java 重载与重写 【转】
- 《Java170道面试笔试题全面含答案》
- CentOS-7安装Cinnamon Desktop
- 计算机打开硬盘响应慢,电脑处理多任务卡顿,开机反应慢,换固态硬盘不能解决问题根本...
- VSCode配置格式化工具(Prettier/Vetur/ESLint)和jsconfig.json
热门文章
- 江苏自考计算机应用基础停考了吗,江苏自考停考35个自考专业!附详细专业目录...
- python商业数据分析报告范文_python案例分析之电商销售数据分析
- checksum命令 linux_数字签名及 Checksum 校验和
- 随机数字生成器(RNG)和Hash函数组合武器背后的黑暗秘密
- 人工智能是用计算机模拟人的智能特别是模拟,张钹院士:人工智能是让计算机模拟人的三种功能...
- 家用宽带公网ipv4/ipv6搭建服务(常见两种网络模式)超详细
- 计算机网络有哪三种体系结构,计算机网络体系结构有哪几种
- 解决一个偶现的503 bug,花了俺不少时间
- 正 文 声学漫谈之一:声音三要素
- 嘉立创SMT下单流程