python 爬取搞笑视频_Python爬取知乎上搞笑视频,一顿爆笑送给大家
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:Huangwei AI
来源:Python与机器学习之路
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
最近小编经常刷知乎上的一个问题“你见过哪些是「以为是个王者,结果是个青铜」的视频或图片?”。从这个问题我们就已经可以看出来里面的幽默成分了,点进去看果然是笑到停不下来。于是,我想一个个点进去看,还不如把这些视频都下载下来,享受一顿爆笑。
获取url
我们使用Google浏览器的“开发者工具”获取网页的url,然后用requests.get函数获得json文件,再使用json.loads函数转换成Python对象:
1 url = "https://www.zhihu.com/api/v4/questions/312311412/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=20&offset="+str(i*20)+"&platform=desktop&sort_by=default"
2 r = requests.get(url,headers =kv)3 dicurl = json.loads(r.text)
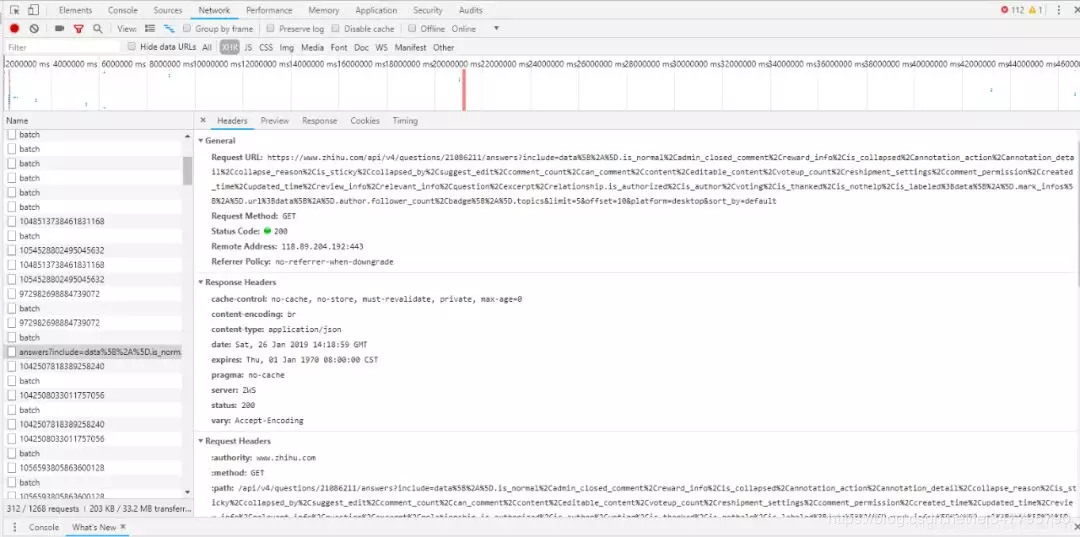
获取content
我们使用谷歌浏览器的一个开发者工具JSONview,可以看到打开的url中有一个content,这里面就是我们要找的回答内容,视频url也在里面。将返回的json转化成python对象后,获取其中content里面的内容。也就是说,我们获得了每一个回答的内容,包括了视频的地址。
1 for k in range(20):#每条dicurl里可以解析出20条content数据
2 name = dicurl["data"][k]["author"]["name"]3 ID = dicurl["data"][k]["id"]4 question = dicurl["data"][k]["question"]["title"]5 content = dicurl["data"][k]["content"]6 data_lens = re.findall(r'data-lens-id="(.*?)"',content)
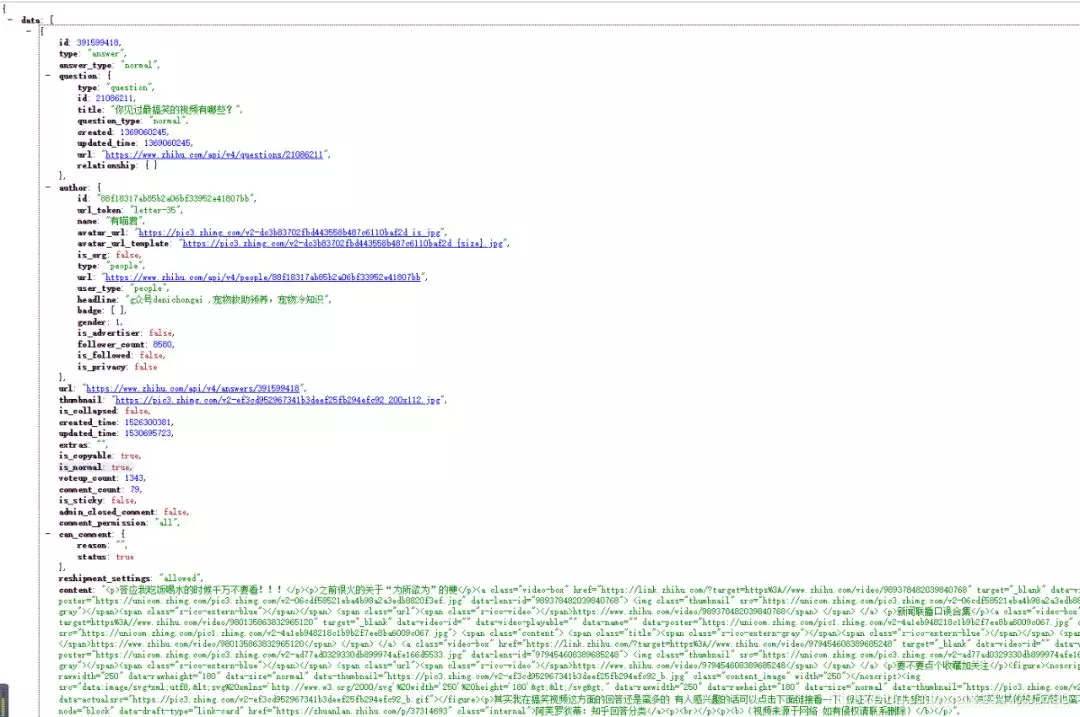
获得视频地址
打开获取的content,找到href后面的url,打开看一下打开后视频正是我们要的内容,但是发现url不是我们获取的真实地址。仔细观察后发现,这个url发生了跳转。想要知道如何跳转来的,我们再次F12,打开开发者工具,发现请求了一个新的URL。观察发现,其实后面一串数字就是之前的data-lens-id。

对这个地址进行构造:
1 videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])2 R = requests.get(videoUrl,headers =kv)3 Dicurl =json.loads(R.text)4 playurl = Dicurl["playlist"]["LD"]["play_url"]5 #print(playurl)#跳转后的视频url
6 videoread = request.urlopen(playurl).read()
完成之后,我们就可以下载视频了。
完整版代码:
1 from urllib importrequest2 from bs4 importBeautifulSoup3 importrequests4 importre5 importjson6 importmath7 defgetVideo():8 m = 0#计数字串个数
9 num = 0#回答者个数
10 path = u'/home/zhihuvideo1'
11 #path = u'/home/zhihuimage'
12 kv = {'user-agent':'Mozillar/5.0'}13 for i in range(math.ceil(900/20)):14 try:15 url = "https://www.zhihu.com/api/v4/questions/312311412/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=20&offset="+str(i*20)+"&platform=desktop&sort_by=default"
16 r = requests.get(url,headers =kv)17 dicurl =json.loads(r.text)18 for k in range(20):#每条dicurl里可以解析出20条content数据
19 name = dicurl["data"][k]["author"]["name"]20 ID = dicurl["data"][k]["id"]21 question = dicurl["data"][k]["question"]["title"]22 content = dicurl["data"][k]["content"]23 data_lens = re.findall(r'data-lens-id="(.*?)"',content)24 print("正在处理第" + str(num+1) + "个回答--回答者昵称:" + name + "--回答者ID:" + str(ID) + "--" + "问题:" +question)25 num = num + 1 #每次碰到一个content就增加1,代表回答者人数
26 for j inrange(len(data_lens)):27 try:28 videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])29 R = requests.get(videoUrl,headers =kv)30 Dicurl =json.loads(R.text)31 playurl = Dicurl["playlist"]["LD"]["play_url"]32 #print(playurl)#跳转后的视频url
33 videoread =request.urlopen(playurl).read()34
35 fileName = path +"/" + str(m+1) + '.mp4'
36 print ('===============================================')37 print(">>>>>>>>>>>>>>>>>第---" + str(m+1) + "---个视频下载完成<<<<<<<<<<<<<<<<<")38 videoname = open(fileName,'wb')39
40 videoname.write(videoread)41 m = m+1
42 except:43 print("此URL为外站视频,不符合爬取规则")44 except:45 print("构造第"+str(i+1)+"条json数据失败")46 47 if __name__ == "__main__":48 getVideo()
跑这个程序需要注意的是需要按照代码存储视频的路径建立一个文件夹:

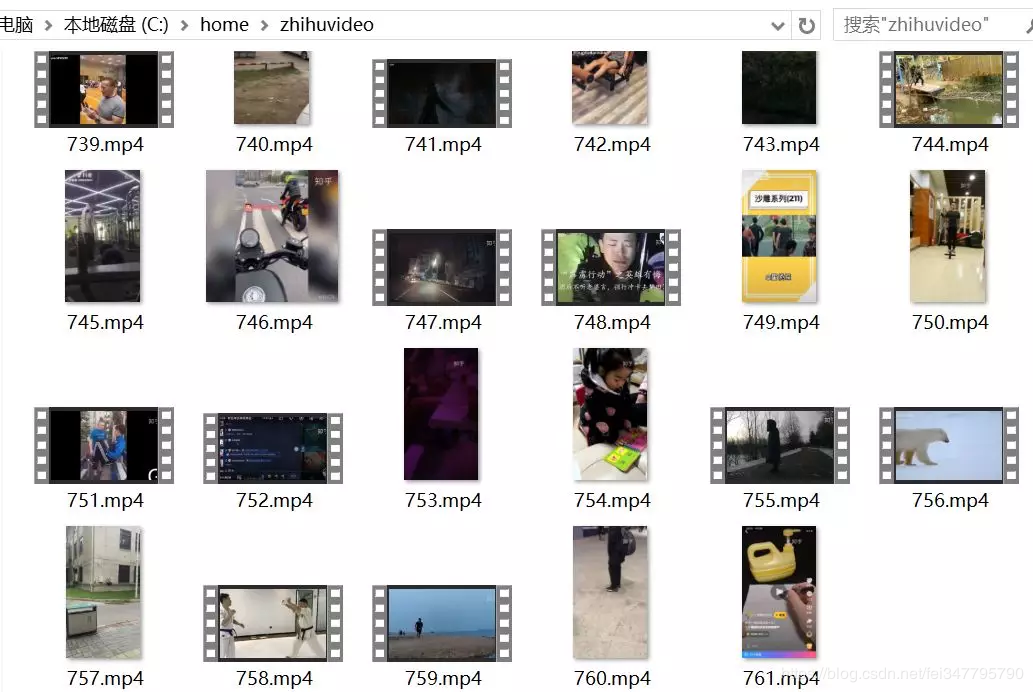
结果
经过一段时间爬虫,我们最终获得了七百多条视频:
.
python 爬取搞笑视频_Python爬取知乎上搞笑视频,一顿爆笑送给大家相关推荐
- 爬取知乎上搞笑视频,一顿爆笑送给大家
作者:Huangwei AI 来源:Python与机器学习之路 最近小编经常刷知乎上的一个问题"你见过哪些是「以为是个王者,结果是个青铜」的视频或图片?".从这 ...
- Python爬虫:爬取知乎上的视频,并把下载链接保存到md文件中
Python爬虫:爬取知乎上的视频,并把下载链接保存到md文件中 1.需要的Python模块 主要是requests模块,用于得到的网页的数据 安装命令为:pip install requests 2 ...
- python爬抖音短视频_python爬取抖音小视频
import os,json,requests #伪装头 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) App ...
- python 爬取直播弹幕视频_Python爬取b站任意up主所有视频弹幕
爬取b站弹幕并不困难.要得到up主所有视频弹幕,我们首先进入up主视频页面,即https://space.bilibili.com/id号/video这个页面.按F12打开开发者菜单,刷新一下,在ne ...
- python抓取微博评论_Python爬取新浪微博评论数据,你有空了解一下?
开发工具 Python版本:3.6.4 相关模块: argparse模块: requests模块: jieba模块: wordcloud模块: 以及一些Python自带的模块. 环境搭建 安装Pyth ...
- python爬取手机微信_Python爬取微信好友
前言 今天看到一篇好玩的文章,可以实现微信的内容爬取和聊天机器人的制作,所以尝试着实现一遍,本文记录了实现过程和一些探索的内容 itchat安装 对微信的控制可以使用itchat来实现,我们找到itc ...
- python开源代码百度盘_python爬取百度云网盘资源-源码
今天测试用了一下python爬取百度云网盘资源. 代码片段import urllib import urllib.request import webbrowser import re def yun ...
- python爬取动态网页_python爬取动态网页数据,详解
原理:动态网页,即用js代码实现动态加载数据,就是可以根据用户的行为,自动访问服务器请求数据,重点就是:请求数据,那么怎么用python获取这个数据了? 浏览器请求数据方式:浏览器向服务器的api(例 ...
- python爬关键词百度指数_Python 抓取指定关键词的百度指数
百度指数很多时候在我们做项目的时候会很有帮助,从搜索引擎的流量端给到我们一些帮助,比如:家具行业的销量跟"装修","新房","二手房"等关键 ...
最新文章
- 植物根系微生物组的调控入选中科院科技创新亮点成果筛选
- python编程爱心-使用Python画出小人发射爱心的代码
- 线程知识-ThreadLocal使用详解
- “让Keras更酷一些!”:分层的学习率和自由的梯度
- JavaEE PO VO BO DTO POJO DAO 整理总结
- 宁愿月薪1万招新人,却不愿给月薪5千的老员工涨薪
- admin is not in the sudoers file. This incident will be reported
- AngularJS 控制器 ng-controller
- 2019,我们被“黑”科技薅过的羊毛?
- oracle 保留池,oracle的内存结构之--查看内存信息+保留池和循环池(摘自文平书)...
- ICE 3.7.4 实现客户服务端hello world
- mysql relay log_mysql binlog和relay log日志如何清除
- 单片机模拟输出PPM信号
- charles的使用
- 三极管的检测及其管脚的判别
- 抖音企业号获客系统技术操作手册
- 提高钢材品质应用 高精度在线测径仪
- 详解IP地址后面斜杠加具体数字
- 水晶报表 发布 部署
- php职业发展路径是什么意思,如何找准职业发展路径