MaxCompute - ODPS重装上阵 第五弹 - SELECT TRANSFORM
MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务。 MaxCompute除了持续优化性能外,也致力于提升SQL语言的用户体验和表达能力,提高广大ODPS开发者的生产力。
MaxCompute基于ODPS2.0新一代的SQL引擎,显著提升了SQL语言编译过程的易用性与语言的表达能力。我们在此推出MaxCompute(ODPS2.0)重装上阵系列文章
第一弹 - 善用MaxCompute编译器的错误和警告
第二弹 - 新的基本数据类型与内建函数
第三弹 - 复杂类型
第四弹 - CTE,VALUES,SEMIJOIN
上次向您介绍了CTE,VALUES,SEMIJOIN,本篇向您介绍MaxCompute对其他脚本语言的支持 - SELECT TRANSFORM。
场景1
我的系统要迁移到MaxCompute平台上,系统中原来有很多功能是使用脚本来完成的,包括python,shell,ruby等脚本。 要迁移到MaxCompute上,我需要把这些脚本全部都改造成UDF/UDAF/UDTF。改造过程不仅需要耗费时间人力,还需要做一遍又一遍的测试,从而保证改造成的udf和原来的脚本在逻辑上是等价的。我希望能有更简单的迁移方式。场景2
SQL比较擅长的是集合操作,而我需要做的事情要对一条数据做更多的精细的计算,现有的内置函数不能方便的实现我想要的功能,而UDF的框架不够灵活,并且Java/Python我都不太熟悉。相比之下我更擅长写脚本。我就希望能够写一个脚本,数据全都输入到我的脚本里来,我自己来做各种计算,然后把结果输出。而MaxCompute平台就负责帮我把数据做好切分,让我的脚本能够分布式执行,负责数据的输入表和输出表的管理,负责JOIN,UNION等关系操作就好了。
上述功能可以使用SELECT TRANSFORM来实现
SELECT TRANSFORM 介绍
此文中采用MaxCompute Studio作展示,首先,安装MaxCompute Studio,导入测试MaxCompute项目,创建工程,建立一个新的MaxCompute脚本文件, 如下
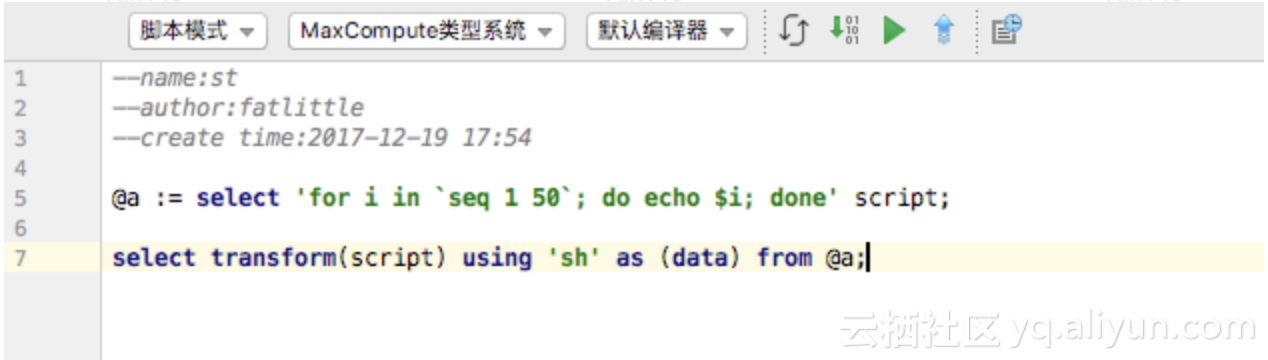
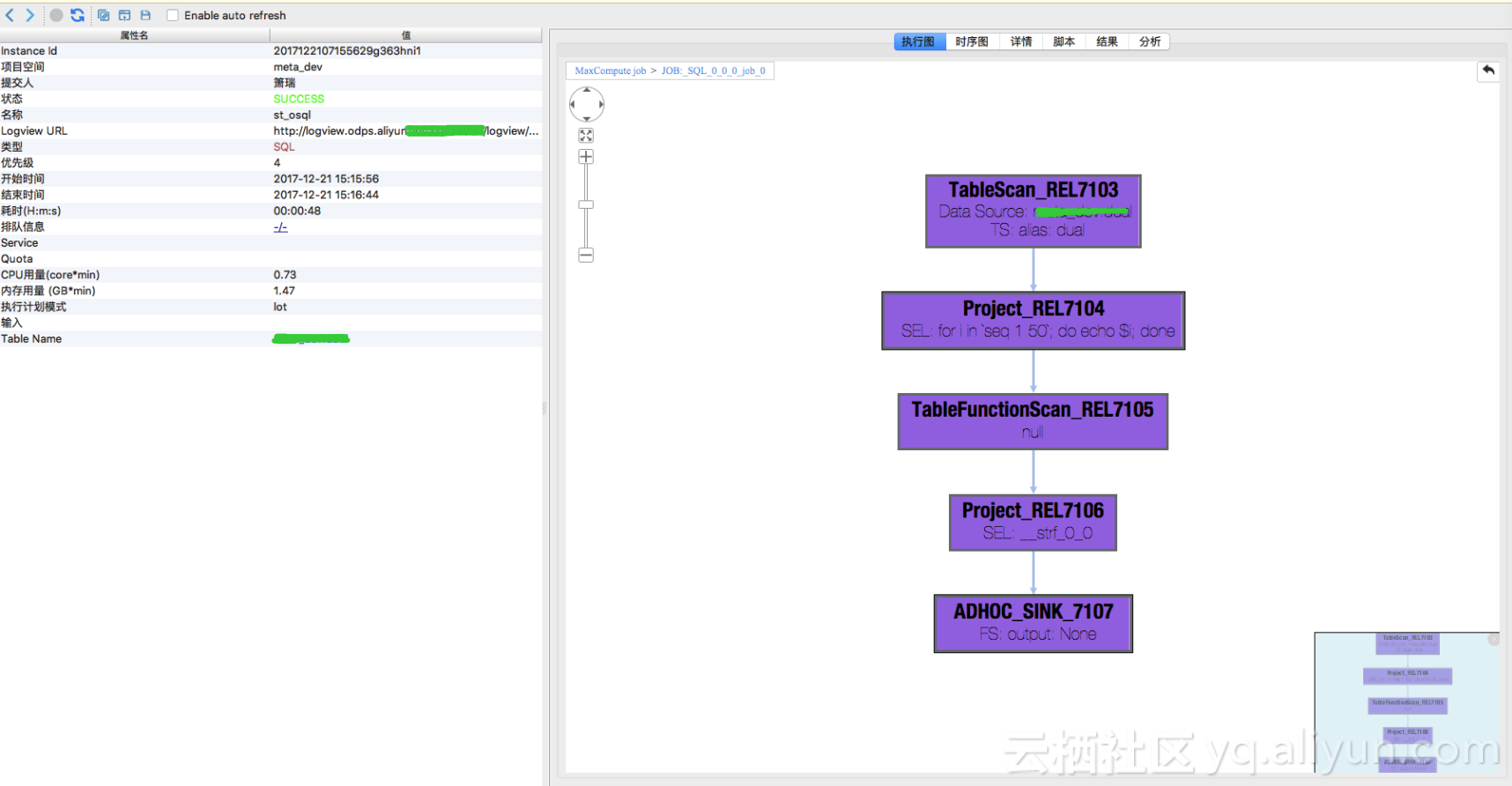
提交作业可以看到执行计划(全部展开后的视图):
Select transform允许sql用户指定在服务器上执行一句shell命令,将上游数据各字段用tab分隔,每条记录一行,逐行输入shell命令的stdin,并从stdout读取数据作为输出,送到下游。Shell命令的本质是调用Unix的一些utility,因此可以启动其他的脚本解释器。包括python,java,php,awk,ruby等。
该命令兼容Hive的Transform功能,可以参考Hive的文档。一些需要注意的点如下:
1. Using 子句指定的是要执行的命令,而非资源列表,这一点和大多数的MaxCompute SQL语法不一样,这么做是为了和hive的语法保持兼容。
2. 输入从stdin传入,输出从stdout传出;
3. 可以配置分隔符,默认使用 \t 分隔列,用换行分隔行;
4. 可以自定义reader/writer,但用内置的reader/writer会快很多
5. 使用自定义的资源(脚本文件,数据文件等),可以使用 set odps.sql.session.resources=foo.sh,bar.txt; 来指定。可以指定多个resource文件,用逗号隔开(因此不允许resource名字中包含逗号和分号)。此外我们还提供了resources子句,可以在using 子句后面指定 resources 'foo.sh', 'bar.txt' 来指定资源,两种方式是等价的(参考“用odps跑测试”的例子);
6. 资源文件会被下载到执行指定命令的工作目录,可以使用文件接口打开./bar.txt文件。
目前odps select transform完全兼容了hive的语法、功能和行为,包括 input/output row format 以及 reader/writer。Hive上的脚本,大部分可以直接拿来运行,部分脚本只需要经过少许改动即可运行。另外我们很多功能都用比hive更高执行效率的语言 (C++) 重构,用以优化性能。
应用场景举例
理论上select transform能实现的功能udtf都能实现,但是select transform比udtf要灵活得多。且select transform不仅支持java和python,还支持shell,perl等其它脚本和工具。 且编写的过程要简单,特别适合adhoc功能的实现。举几个例子:
1. 无中生有造数据
<span style="color:#24292e"><span style="color:#f8f8f2"><code class="language- language-undefined">select transform(script) using 'sh' as (data) from
(select 'for i in `seq 1 50`; do echo $i; done' as script
) t;
</code></span></span>或者使用python
<span style="color:#24292e"><span style="color:#f8f8f2"><code class="language- language-undefined">select transform('for i in xrange(1, 51): print i;') using 'python' as (data);
</code></span></span>上面的语句造出一份有50行的数据表,值是从1到50; 测试时候的数据就可以方便造出来了。功能看似简单,但以前是odps的一个痛点,没有方便的办法造数据,就不方便测试以及初学者的学习和探索。当然这也可以通过udtf来实现,但是需要复杂的流程:进入ide->写udtf->打包->add jar/python->create function->执行->drop function->drop resource。
2. awk 用户会很喜欢这个功能
<span style="color:#24292e"><span style="color:#f8f8f2"><code class="language- language-undefined">select transform(*) using "awk '//{print $2}'" as (data) from src;
</code></span></span>上面的语句仅仅是把value原样输出,但是熟悉awk的用户,从此过上了写awk脚本不写sql的日子
3. 用odps跑测试
<span style="color:#24292e"><span style="color:#f8f8f2"><code class="language- language-undefined">select transform(key, value) using 'java -cp a.jar org.junit.runner.JUnitCore MyTestClass' resources 'a.jar'
from testdata;
</code></span></span>或者
<span style="color:#24292e"><span style="color:#f8f8f2"><code class="language- language-undefined">set odps.sql.session.resources=a.jar;
select transform(key, value) using 'java -cp a.jar org.junit.runner.JUnitCore MyTestClass'
from testdata;
</code></span></span>这个例子是为了说明,很多java的utility可以直接拿来运行。java和python虽然有现成的udtf框架,但是用select transform编写更简单,并且不需要额外依赖,也没有格式要求,甚至可以实现离线脚本拿来直接就用。
4. 支持其他脚本语言
<span style="color:#24292e"><span style="color:#f8f8f2"><code class="language- language-undefined">select transform (key, value) using "perl -e 'while($input = <STDIN>){print $input;}'" from src;
</code></span></span>上面用的是perl。这其实不仅仅是语言支持的扩展,一些简单的功能,awk, python, perl, shell 都支持直接在命令里面写脚本,不需要写脚本文件,上传资源等过程,开发过程更简单。另外,由于目前我们计算集群上没有php和ruby,所以这两种脚本不支持。
5. 可以串联着用,使用 distribute by和 sort by对输入数据做预处理
<span style="color:#24292e"><span style="color:#f8f8f2"><code class="language- language-undefined">select transform(key, value) using 'cmd2' from
(select transform(*) using 'cmd1' from (select * from data distribute by col2 sort by col1) t distribute by key sort by value
) t2;
</code></span></span>或者用map,reduce的关键字会让逻辑显得清楚一些
<span style="color:#24292e"><span style="color:#f8f8f2"><code class="language- language-undefined">@a := select * from data distribute by col2 sort by col1;
@b := map * using 'cmd1' distribute by col1 sort by col2 from @a;
reduce * using 'cmd2' from @b;
</code></span></span>理论上OpenMR的模型都可以映射到上面的计算过程。注意,使用map,reduce,select transform这几个语法其实语义是一样的,用哪个关键字,哪种写法,不影响直接过程和结果。
性能
性能上,SELECT TRANSFORM 与UDTF 各有千秋。经过多种场景对比测试,数据量较小时,大多数场景下select transform有优势,而数据量大时UDTF有优势。由于transform的开发更加简便,所以select transform非常适合做adhoc的数据分析。
UDTF的优势:
- UDTF是有类型,而Transform的子进程基于stdin/stdout传输数据,所有数据都当做string处理,因此transform多了一步类型转换;
- Transform数据传输依赖于操作系统的管道,而目前管道的buffer仅有4KB,且不能设置, transform读/写 空/满 的pipe会导致进程被挂起;
- UDTF的常量参数可以不用传输,而Transform没办法利用这个优化。
SELECT TRANSFORM 的优势:
- 子进程和父进程是两个进程,而UDTF是单线程的,如果计算占比比较高,数据吞吐量比较小,可以利用服务器的多核特性
- 数据的传输通过更底层的系统调用来读写,效率比java高
- SELECT TRANSFORM支持的某些工具,如awk,是natvie代码实现的,和java相比理论上可能会有性能优势。
小结
MaxCompute基于ODPS2.0的SQL引擎,提供了SELECT TRANSFORM功能,可以明显简化对脚本代码的引用,与此同时,也提高了性能!我们推荐您尽量使用SELECT TRANSFORM。
标注
- 注一,USING 后面的字符串,在后台是直接起的子进程来调起命令,没有起shell,所以shell的某些语法,如输入输出重定向,管道等是不支持的。如果用户需要可以以 shell 作为命令,真正的命令作为数据输入,参考“无中生有造数据”的例子;
- 注二,JAVA 和 PYTHON 的实际路径,可以从JAVA_HOME 和 PYTHON_HOME 环境变量中得到作业;
原文链接
本文为云栖社区原创内容,未经允许不得转载。
MaxCompute - ODPS重装上阵 第五弹 - SELECT TRANSFORM相关推荐
- MaxCompute - ODPS重装上阵 第一弹 - 善用MaxCompute编译器的错误和警告
摘要: MaxCompute (ODPS) ( 注1 )是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务. ODPS2.0除了持续优化性 ...
- MaxCompute - ODPS重装上阵 第二弹 - 新的基本数据类型与内建函数
MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务. MaxCompute除了持续优化性能外,也致力于提 ...
- MaxCompute - ODPS重装上阵 第四弹 - CTE,VALUES,SEMIJOIN
摘要: MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务. MaxCompute除了持续优化性能外,也 ...
- MaxCompute - ODPS重装上阵 第三弹 - 复杂类型
摘要: MaxCompute(原ODPS)是阿里云自主研发的具有业界领先水平的分布式大数据处理平台, 尤其在集团内部得到广泛应用,支撑了多个BU的核心业务. MaxCompute除了持续优化性能外,也 ...
- 微信支付 APP端 后端 第四-五弹 退款定时任务 账单下载
目录 第四弹 退款定时任务 成果展示: 1.设计思路 2.代码实现 2.1数据库查询订单 2.2定时任务 检查退款订单 2.3调用微信支付 get请求 统一配置(如果是看了前几篇的友友 前面有一样的 ...
- MaxCompute(ODPS)实现笛卡尔积
笛卡尔积会产生大量的重复记录,是引起主键重复的主要原因,但是对有些业务或者数据的处理笛卡尔积又是必不可少的技巧.如何在MaxCompute(ODPS)对表实现笛卡尔积,几种方案记录如下: 方法1:条件 ...
- MaxCompute(ODPS)上处理非结构化数据的Best Practice
2019独角兽企业重金招聘Python工程师标准>>> 摘要: 随着MaxCompute(ODPS)2.0的上线,新增的非结构化数据处理框架也推出一系列的介绍文章,包括 MaxCom ...
- 每日三道前端面试题--vue 第五弹
每日三道前端面试题--vue 第五弹 DOM 渲染在哪个周期中就已经完成? 说明Vue父组件向子组件传值的方法(代码或文字描述均可)? 请列举axios的配置项及含义(五条)? DOM 渲染在哪个周期 ...
- 计算机网络第五弹——运输层
计算机网络第五弹--运输层 彩蛋 计算机网络谢希仁第七版原版ppt获取方式:公众号后台回复"N3"即可获取. 由于公众号不支持显示LaTeX公式且公众号排版混乱,建议大家关注微信公 ...
最新文章
- MIT公布“著名黑客之死”调查报告
- Silverlight 5 深入理解 - TechEd2011葡萄城讲师课程
- Java 基本功之(三)Java 核心技术
- opengl加载显示3D模型PLY类型文件
- __asm__ __volatile__(: : :memory);
- php get请求 json返回,[1.23]-请求和响应:GET和POST两者皆可得及超越JSON格式返回 | PhalApi(π框架) - PHP轻量级开源接口框架 - 接口,从简单开始!...
- feign直接走熔断_SpringCloud微服务面试必问:Hystrix 服务降级、熔断
- Hadoop为什么没有采用RAID?
- c #include如何找到文件_使用 MATLAB Function 模块集成 C 代码
- Django知识总结
- 斜率、梯度(完全不一样的理解)
- Android设置输入法
- 苹果电脑如何快速清理废纸篓?
- 怎么强力卸载360天擎_如何手动卸载天擎
- 各种手段终于将土豆视频url请求找到了
- 怎么进入修复计算机界面,开机进入启动修复界面不能启动win7电脑的修复办法...
- 李宏毅学习笔记42.More about Domain Adaptation. Part I. Domain Adaptation
- wps在线编辑梳理(此处整理了对接过后容易出错的地方)
- 基于JSP的高校考试排座管理系统
- 以结算价交易TAS和以市价交易TAM
热门文章
- 运行catia_CATIA清除错误目录及防串链接
- python资源管理器选择文件_Python:在资源管理器中获取选定文件的列表(windows7)...
- Windows和linux提权方法,Windows与Linux本地用户提权体验(一)
- 我的世界java版做船_“不要在云了,船的合成用木铲?”我的世界:Java和基岩版的差异...
- react配合python_部署React前端和Django后端的3种方法
- 济南“凡尔赛”大姨:一儿一女俩博士,还算可以吧!网友:俺孩要这么棒,我一天发18遍朋友圈...
- 32个机械动图,揭秘生活中制造原理
- 性质极其恶劣!针对基因编辑婴儿,怀进鹏这样说…
- 中国空间站核心舱首次公开亮相:将于2022年前后完成在轨建造
- 游戏编程里面有哪些经典或者很酷的算法?