苏宁海量服务器自动化配置运维实践
运维的演进
人力运维阶段
在IT产业的早期,服务器运维是通过各种Ad Hoc命令或者Shell脚本来完成基础设施的自动化工作,这种方式对于简单,一次性的工作很方便,但是对于复杂和长期的项目,后期的脚本维护非常麻烦。

自动化工具阶段
现时的大型互联网公司都已经有了成千上万台服务器,对于这么庞大体量的服务器规模,以往那种原始的人工运维方式显然已经过时,大规模服务器的自动化快速运维就成为了不得不探讨的课题。
目前Salt,Chef,Puppet和Ansible等配置管理工具是运维界非常流行的工具,它们定义了各自的语法规则来管理服务器,这些工具定义的代码和Ad Hoc脚本语言非常相似,但是它们强制要求代码具有结构化,一致性,和清晰的参数命名,它们能够远程管理大量的服务器,并且兼容早期的Ad hoc 脚本。
DevOps阶段
随着自动化维护的相关工具层出不穷,有些大公司已经把它上升到了战略层面,并引入了各种各样的自动化工具与自己的业务系统进行组装。

自动化运维平台ACM平台的建设
从传统业务转型互联网的苏宁随着业务量的上升,服务器本身的标准化扫描,内核批量升级,在备战双11大促时,运维会接入大量系统扩容,配置,全局变量设定等等操作也逐渐变得常态化,动辄上千台的主机运维的工作已经不是通过堡垒机系统就可以轻松完成了。
并且随着不断有PAAS业务系统提出需要各种可定制化,标准化的服务器配置管理部署接口。开发一个可以批量化配置管理服务器的通用平台就变得迫切起来。
底层工具的选取
目前市场上最主流的开源工具有
Puppet/Chef/Ansible/Saltstack四种,选型时在github的热度排名如下:

而在实际开发的选取时优先会考虑以下两点:
- 第一、语言的选择(Puppet/Chef vs Ansible/Saltstack)
Puppet、Chef基于Ruby开发,Ansible、Saltstack基于Python(后期可做二次开发),所以抛弃较为老旧并且兼容性较差的Puppet和Chef - 第二、速度的选择 (Ansible vs Saltstack)
运维的配置管理讲究的是更快更稳,Ansible基于SSH协议传输数据,Saltstack使用消息队列zeroMQ传输数据。
在Ansible、Saltstack的选择中,有一些公司放弃Saltstack的主要原因是Saltstack需要安装客户端,在服务器有一定数量的情况下比较麻烦,而Ansible不需要安装客户端。但是目前的Ansible还存在以下难以解决的问题:
- 众口难调:和业务特点相关的需求十分离散(有的重效率,有的看重流程的完备性,有的对易用性要求高)再加上需求方越来越多,没有合适的通用开放性接口提供 restful API,功能交付的排队会积压严重。
- 性能差:当需要执行一个服务器数量级达到 K 级操作,Ansible的响应长达数十分钟,并且还有比较高的错误率。
反观SaltStack,它结合轻量级消息队列(ZeroMQ)与Python第三方模块构建。具备了配置管理、远程执行、监控等功能,具有以下明显的优势:
- 速度极快
- 兼容性好
- 文档详细,并且开源社区跟Ansible一样持续活跃
速度测试
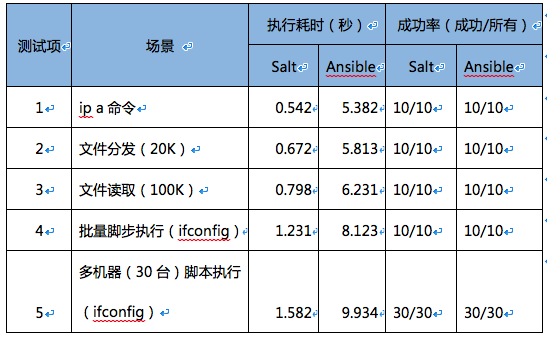
从表格中可以看出Ansible和SaltStack性能测试中,测试了Ansible和SaltStack在执行命令、分发文件、读取文件和批量脚本执行等自动化运维场景下的性能,由耗时数据可以看出Ansible的响应速度比SaltStack要慢10倍左右。
经过的综合论证考量,最终选择了在大规模集群下,适用性最强的SaltStack作为苏宁所有服务器的基础管理工具。
使用稳定性的维护
由于早期版本的Saltstack的稳定性不高,各种版本之间也有兼容性问题,为了保证版本升级时保持可以向下兼容,团队进行大量的验证和测试后会把发现的bug向社区报告,经过不断的沟通与协商,最终得到社区的认可并接受我们提出的修改建议,目前团队也积极的参与新版本Salt的检证测试与维护,有力的保障底层平台的稳定性。
通用外部接口及WEB平台的建设
由于Saltstack社区并没有提供WEB管理界面,所有的操作都只能通过命令行操作,而API的调用也会暴露出用户名密码给外部系统,Master的安全性得不到保障。并且脚本的维护升级都十分的麻烦。
所以在选定底层管理工具后还需要开发一套ACM上层平台,包装出通用的接口对外提供服务,并且提供可视化的操作界面提供给主机运维团队。
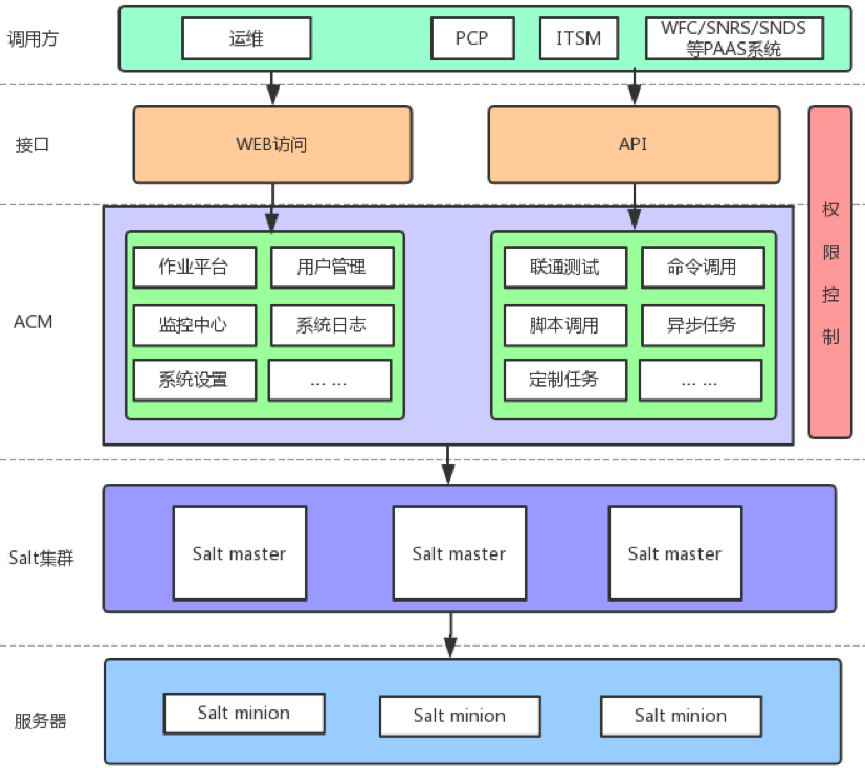
ACM提供了一套WEB系统供运维管理人员进行可视化的运维管理。实现了页面化的脚本工具定义, 作业编排,作业执行,命令执行,报表分析等功能。
外部系统则可以通过ACM开放的API接口实现对底层Salt的调用,从而实现对安装有Salt Minion Agent的机器进行配置管理。
并且在安全的设计上,平台提供审计,命令黑名单,通道管理,Agent配置、用户角色权限管理,并且仅允许授权过的外部系统接入ACM。
系统架构的演进
架构1.0
早期采用Order Master + Syndic+Minion的三层架构模式,当时全苏宁的OS虚机+物理服务器总数大概在1万左右,Salt的原生架构还能勉强支撑。
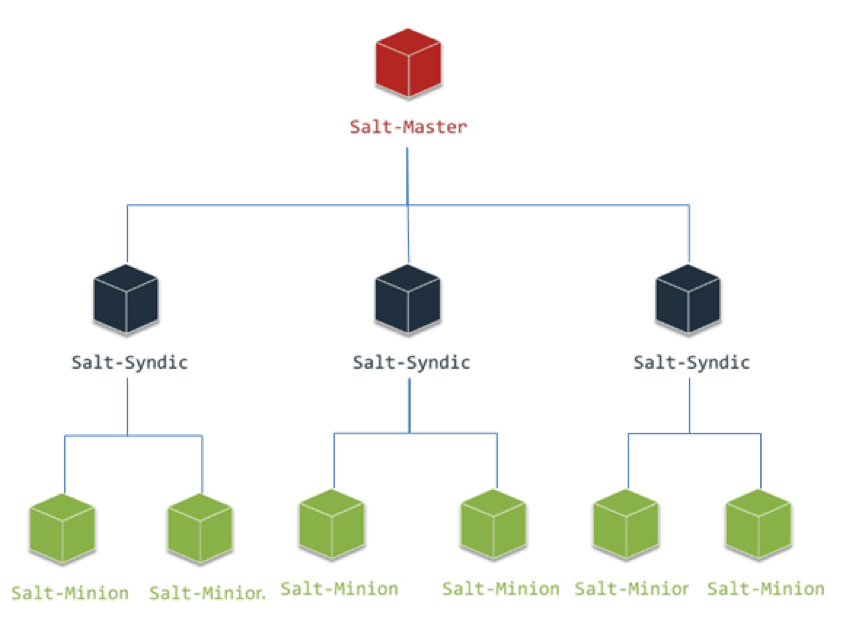
但随着集团转型的持续进行,线上业务量的急速上升,大促前上线的服务器数量也以近乎每天一千台的速度上升,接入ACM的系统也从仅有的两三个,每天几百个总请求量,快速上升到几十个系统,一天有近万个配置任务;此时系统的问题也逐步暴露出来,比如任务返回慢,一个同步任务执行需要5秒以上的调用时间;原生架构下Order Master在并发任务量大时,系统压力过高,任务失败率也超过10%
团队每天都花费大量时间应对客户苦不堪言,业务方也是经常提出抱怨,由于业务量提升的倒逼,Salt-Minion又是集团默认的唯一基础运维Agent,除了我们没有人可以承担下自动化配置管理的工作。于是乎ACM进行了整个系统的重新设计。
架构2.0-两层化拆分
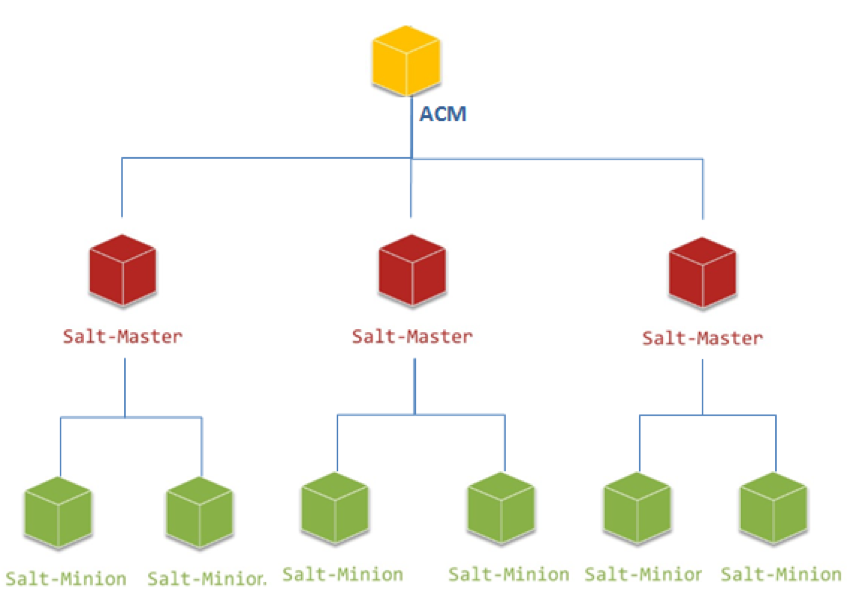
经过反复研究跟论证,ACM可以改造成直接充当Order Master的角色,对服务器发起配置任务时,ACM可以通过安装记录直接查询到Minion挂载在哪台Master上,直接对需要的Master发起调用,任务如果是多台机器,后期也通过ACM进行结果的聚合。
由于ACM本身就是JBoss集群,这样做不仅解决了单台Order Maser负担太重的问题,还大大加快了请求的响应时间,从原来的五秒+响应提升到了毫秒级响应,解决了原生架构中官方必须开销的Syndic等待时间。
架构2.1-Salt Master的高可用化
在实际生产环境中如果发生了某一台Salt Master宕机的情况,就会有约2K的机器失去控制,人工的进行Master恢复长达几十分钟,对于一些业务的调用是不可以接受的。
所以Master迫切的需要进行高可用化的改造,而改造的过程中又需要解决以下几个问题:
- Minion如何探测到Master宕机,并进行快速切换。
- 当Minion探测到主Master宕机后如何切换到备Master。
- 如何解决主备Master之间Salt-key复制的问题,尤其是当主Master关联新的Minion,新Minion的Salt-key如何同步给备Master。
方案1
采用Saltstack原生的高可用方案,Mutil-Master+Failover-Minion。
Mutil-Master: Saltstack从0.16.0版本开始支持,提供Minion可以连接多Master的功能特性.
Failover-Minion: Minion定期检测Master的可用性,当发现Master不可用时,则在一定时间切换到备用Master上。
主要的配置项如下:
# multi-MasterMaster: - 10.27.135.188 - 10.27.135.189# 设置为failover Minion Master_type: failover # 探测Master的间隔,单位为秒Master_alive_interval: \u0026lt;seconds\u0026gt; 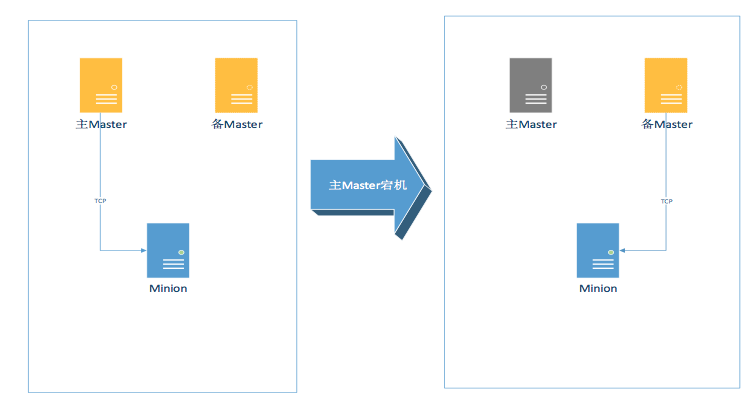
该方案的优点是基于SaltStack原生的高可用支持,不需别的组合方案进行支撑,理论上可以实现Master的高可用,但是经过实际的验证和测试,存在一些明显的不足:
- Minon在启动的时候会随机连接一台Master,假如此时连接的Master恰好宕机,Minion不会再随机选择另外一台Master,从而导致连接失败的情况。
- Minion 检测间隔,根据Master_alive_interval的设置时间,Minion会主动对现有的Master进行TCP连接一次检查,查看Master是否响应。如果探测间隔设置过长,则可能影响到切换的时效;如果探测间隔设置过短,在大规模服务器场景下,则在短时间内产生过多的网络请求,对Master主机以及网络带宽产生巨大冲击,相当于一次DDOS攻击。
- 假如需要更换Master的IP或者追加新的Master的IP,则需要对该Master下的所有的Minon进行配置变更,更恐怖的是Minion需要重启才能生效。
- Salt-key同步没有提供解决方案。
方案2
经过不停实验,发现Master可以通过由Keepalived维护的VIP对外提供Salt服务,平时VIP绑定在主Master,当主Master宕机时VIP漂移至备Master,主备Master通过lsyncd共享Salt-key文件。
**注:Keepalived软件主要是通过VRRP协议实现高可用功能的。VRRP是Virtual Router RedundancyProtocol(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行。
所以,Keepalived 一方面具有配置管理LVS的功能,同时还具有对LVS下面节点进行健康检查的功能,另一方面也可实现系统网络服务的高可用功能。**
在实际运行时,Minion会主动向Master(VIP)发起注册,每5分钟检测一次跟Master的TCP连接,如果连接被冲断则重新发起TCP握手,建立TCP长连接;当主Master发生宕机,Keepalived检测到后将VIP漂移至备用Master,Minion最多在5分钟后将向备用Master的VIP发起TCP连接请求,并重新挂起长连接,等待Master发起任务。
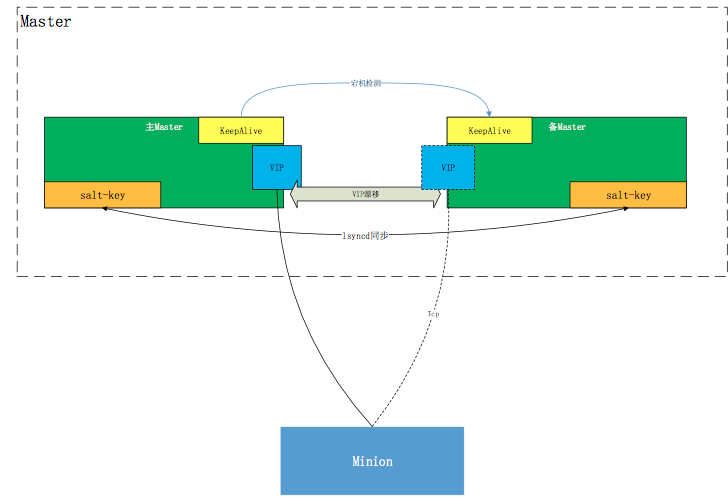
该方案的需要安装额外的软件对高可用进行支撑,由Keepalived对Master进行宕机检测,由lsyncd保证Salt-key的实时同步。这样做的好处是可以避免的方案1的诸多不足。首先,Minion端识别到的是虚拟的Master的IP地址,所以Master底层的IP地址的变化对Minion端是无感知的,Minion既不需要更改配置也不需要重启;其次,Keepalived的检活机制是对本网段内的D类地址进行检测,并设置了唯一的虚拟路由ID,检测间隔控制在5秒以内,所以不会对集团网络造成冲击;最后由lsyncd对Salt-key进行同步,既保证了安全性,又避免了多个Master之间Salt-key同步的问题。
至此,通过以上的混合解决方案,成功的实现的Salt Master宕机自检测自动迁移的高可用方案,目前新港环境下的服务器已经全部由采用高可用架构的Salt集群接管。

总结
现在的ACM已经基本满足集团在日常以及大促的批量规模调用。
- 目前ACM已经最大支持K级服务器的同步调用。
- ACM同步简单任务的调用平均开销时间约200ms。
- 平台日均调用量已经接近50万次。
- 请求成功率99.99%。
展望
随着系统可靠性得到保障,接入系统和调用量将会越来越高,以后怎么应对日均百万,千万级的任务调用也提上日程。
未来的AIOps对ACM这种基础配置服务平台也会提出的更高要求,因为当指挥监测系统在采集决策所需的数据,做出分析、决策后,ACM则需要担当起执行动作的工具,利用自动化脚本/命令去执行AI大脑的决策。
目前Saltstack已经管理了十五万+的服务器,当Salt调用失败时, 可能是因为机器本身宕机、防火墙限制,七层网络不通、系统负载过高、磁盘满了等等各种,这些原因会造成Salt调用失败,我们希望提前对Salt故障问题作出预警,并能够智能的定位问题和解决问题。
而目Salt在批量执行时也有一定的概率产生任务结果的丢失,因为所有任务的返回结果时都需要客户端主动推回服务器,在批量任务大时,少数机器的返回结果会丢失。
这些课题我们后续也将继续研究,探索!
作者简介
徐洋,十年高可用Linux集群、服务器虚拟化建设经验,现为苏宁易购IT总部技术经理。擅长Linux服务器故障诊断与排除,在数据同步、SHELL脚本、Linux系统安全等方面有深入研究,精通服务器集群配置管理的自动化、高可用化技术。
苏宁海量服务器自动化配置运维实践相关推荐
- 网易有数海量任务调度和智能运维实践(整理)
网易有数海量任务调度和智能运维实践 https://mp.weixin.qq.com/s/LJIS7xeHsiTpf12os3DtNw 根据依赖关系,智能推算出每个具体实例的完成时间. 实现:任务运维 ...
- DBA很忙—MySQL的性能优化及自动化运维实践
作者:王辰 来自:高效运维(ID:greatops) DBA的日常工作 首先,我们来看看DBA的具体工作,我觉得 DBA 真的很忙:备份和恢复.监控状态.集群搭建与扩容.数据迁移和高可用,这是我们 D ...
- 美团外卖自动化业务运维系统 - Alfred
1背景 美团外卖业务在互联网行业是非常独特的,不仅流程复杂--从用户下单.商家接单到配送员接单.交付,而且压力和流量在午.晚高峰时段非常集中.同时,外卖业务的增长非常迅猛,自2013年11月上线到最近 ...
- linux框架下搭建orl,DevOps和自动化运维实践/Linux\Unix技术丛书
导语 内容提要 随着云计算.Docker.Kubernetes技术的流行,相信大家经常会听到"容器云"这个专业词汇,容器技术的兴起,对于传统的运维知识体系而言也是一种冲击和挑战.& ...
- 有赞数据库自动化运维实践之路
「运维内推」有赞诚聘:应用运维工程师.系统运维工程师.运维开发工程师.DBA.请关注文末链接 一.前言 有赞作为"新零售"的软件服务供应商,随着业务的不断发展,从第一批几十家商户到 ...
- 阿里技术实战:数十万云服务器如何高效运维?
上云后需要运维吗?答案是:当然需要. 上云确实简化了一部分的运维工作,比如传统IT中服务器的日常运维等工作都交由云服务商来完成了.但随着云上产品种类的不断丰富和规模的不断扩大,云上资源如何高效运维正逐 ...
- 微信分享 | 大规模数据中心自动化运维实践
大规模数据中心的运维实践 大家好,我是青云QingCloud 运维工程师朱峻华,在海关某单位任职数年,后又混迹多家外企,曾在IBM/EMC出现. 刚才粗略看了一下群成员,有我好几个曾经的同事,还有不少 ...
- MySQL的性能优化及自动化运维实践与Mysql高并发优化
首先,我们来看看DBA的具体工作,我觉得 DBA 真的很忙:备份和恢复.监控状态.集群搭建与扩容.数据迁移和高可用,这是我们 DBA 的功能. 了解这些功能以后要对体系结构有更加深入的了解,你不知道怎 ...
- MySQL数据库性能优化及自动化运维实践教程!DBA日常工作
MySQL数据库性能优化及自动化运维实践教程!本文作者将站在更加全面的角度分享他在这一年多 DBA 工作中的经验,希望可以给大家带来启发和帮助. DBA 的日常工作 我觉得 DBA 真的很忙,我们来看 ...
最新文章
- 打牌软件可以控制吗_使用crm软件真的可以帮助企业省钱吗
- npc一定不能多项式时间内解决吗_P, NP, NPC 和 NPhard
- linux 安装go编译器,CentOS 7 安装 go 语言开发环境
- Android插件化原理解析——广播的管理
- 20150206--JS巩固与加强4-02
- [转载] JAVA数组实现学生成绩统计
- 导入csv未响应_IOS免费P12企业证书分享!支持导入Gbox和闪电签!Windows和Mac通用!...
- Fragment学习3--底部tab布局
- innodb--聚簇索引真实案列排序问题
- 百度新营销:不只是关键词了
- pandas之透视表
- 剪切蒙版与抠图的结合
- 小手的图标css,CSS中cursor属性给标签加上小手形状
- elasticSearch API
- ajax爬虫小案例(百度翻译)
- harbor离线包下载(百度网盘)
- 手机群控软件免root
- 【网络】VLAN 及其配置详解
- 生物信息学算法之Python实现|Rosalind刷题笔记:010 DNA一致性序列计算
- 人工智能(网络爬虫)