使用并行计算大幅提升递归算法效率
前言:
无论什么样的并行计算方式,其终极目的都是为了有效利用多机多核的计算能力,并能灵活满足各种需求。相对于传统基于单机编写的运行程序,如果使用该方式改写为多机并行程序,能够充分利用多机多核cpu的资源,使得运行效率得到大幅度提升,那么这是一个好的靠谱的并行计算方式,反之,又难使用又难直接看出并行计算优势,还要耗费大量学习成本,那就不是一个好的方式。
由于并行计算在互联网应用的业务场景都比较复杂,如海量数据商品搜索、广告点击算法、用户行为挖掘,关联推荐模型等等,如果以真实场景举例,初学者很容易被业务本身的复杂度绕晕了头。因此,我们需要一个通俗易懂的例子来直接看到并行计算的优势。
数字排列组合是个经典的算法问题,它很通俗易懂,适合不懂业务的人学习,我们通过它来发现和运用并行计算的优势,可以得到一个很直观的体会,并留下深刻的印象。问题如下:
请写一个程序,输入M,然后打印出M个数字的所有排列组合(每个数字为1,2,3,4中的一个)。比如:M=3,输出:
1,1,1
1,1,2
……
4,4,4
共64个
注意:这里是使用计算机遍历出所有排列组合,而不是求总数,如果只求总数,可以直接利用数学公式进行计算了。
一、单机解决方案:
通常,我们在一台电脑上写这样的排列组合算法,一般用递归或者迭代来做,我们先分别看看这两种方案。
1) 单机递归
可以将n(1<=n<=4)看做深度,输入的m看做广度,得到以下递归函数(完整代码见附件CombTest.java)
public void comb(String str){for(int i=1;i<n+1;i++){if(str.length()==m-1){System.out.println(str+i);total++;}elsecomb(str+i);}
}但是当m数字很大时,会超出单台机器的计算局限导致缓慢,太大数字的排列组合在一台计算机上几乎很难运行出,不光是排列组合问题,其他类似遍历求解的递归或回溯等算法也都存在这个问题,如何突破单机计算性能的问题一直困扰着我们。
2) 单机迭代
我们观察到,求的m个数字的排列组合,实际上都可以在m-1的结果基础上得到。
比如m=1,得到排列为1,2,3,4,记录该结果为r(1)
m=2, 可以由(1,2,3,4)* r(1) = 11,12,13,14,21,22,…,43,44得到, 记录该结果为r(2)
由此,r(m) =(1,2,3,4)*r(m-1)
如果我们从1开始计算,每轮结果保存到一个中间变量中,反复迭代这个中间变量,直到算出m的结果为止,这样看上去也可行,仿佛还更简单。
但是如果我们估计一下这个中间变量的大小,估计会吓一跳,因为当m=14的时候,结果已经上亿了,一亿个数字,每个数字有14位长,并且为了得到m=15 的结果,我们需要将m=14的结果存储在内存变量中用于迭代计算,无论以什么格式存,几乎都会遭遇到单台机器的内存局限,如果排列组合数字继续增大下去,结果便会内存溢出了。
二、分布式并行计算解决方案:
我们看看如何利用多台计算机来解决该问题,同样以递归和迭代的方式进行分析。
1) 多机递归
做分布式并行计算的核心是需要改变传统的编程设计观念,将算法重新设计按多机进行拆分和合并,有效利用多机并行计算优势去完成结果。
我们观察到,将一个n深度m广度的递归结果记录为 r(n,m),那么它可以由(1,2,…n)*r(n,m-1)得到:
r(n,m)=1*r(n,m-1)+2*r(n,m-1)+…+n*r(n,m-1)
假设我们有n台计算机,每台计算机的编号依次为1到n,那么每台计算机实际上只要计算r(n,m-1)的结果就够了,这里实际上将递归降了一级, 并且让多机并行计算。
如果我们有更多的计算机,假设有n*n台计算机,那么:
r(n,m)=11*r(n,m-2)+12*r(n,m-2)+…+nn*r(n,m-2)
拆分到n*n台计算机上就将递归降了两级了
可以推断,只要我们的机器足够多,能够线性扩充下去,我们的递归复杂度会逐渐降级,并且并行计算的能力会逐渐增强。
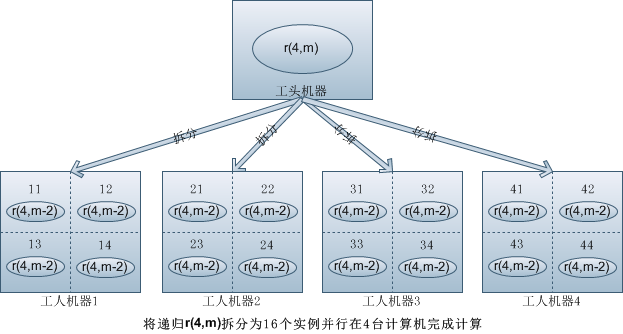
这里是进行拆分设计的分析是假设每台计算机只跑1个实例,实际上每台计算机可以跑多个实例(如上图),我们下面的例子可以看到,这种并行计算的方式相对传统单机递归有大幅度的效率提升。
这里使用fourinone框架设计分布式并行计算,第一次使用可以参考分布式计算上手demo指南, 开发包下载地址:http://www.skycn.com/soft/68321.html
ParkServerDemo:负责工人注册和分布式协调
CombCtor:是一个包工头实现,它负责接收用户输入的m,并将m保存到变量comb,和线上工人总数wknum一起传给各个工人,下达计算命令,并在计算完成后累加每个工人的结果数量得到一个结果总数。
CombWorker:是一个工人实现,它接收到工头发的comb和wknum参数用于递归条件,并且通过获取自己在集群的位置index,做为递归初始条件用于降级,它找到一个排列组合会直接在本机输出,但是计数保存到total,然后将本机的total发给包工头统计总体数量。
运行步骤:
为了方便演示,我们在一台计算机上运行:
1、启动ParkServerDemo:它的IP端口已经在配置文件的PARK部分的SERVERS指定。
2、启动4个CombWorker实例:传入2个参数,依次是ip或者域名、端口(如果在同一台机器可以ip相同,但是端口不同),这里启动4个工人是由于1<=n<=4,每个工人实例刚好可以通过集群位置 index进行任务拆分。
3、运行CombCtor查看计算时间和结果
下面是在一台普通4cpu双核2.4Ghz内存4g开发机上和单机递归CombTest的测试对比
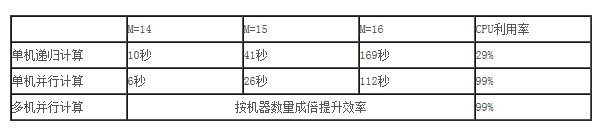
通过测试结果我们可以看到:
1、可以推断,由于单机的性能限制,无法完成m值很大的计算。
2、同是单机环境下,并行计算相对于传统递归提升了将近1.6倍的效率,随着m的值越大,节省的时间越多。
3、单机递归的CPU利用率不高,平均20-30%,在多核时代没有充分利用机器资源,造成cpu闲置浪费,而并行计算则能打满cpu,充分利用机器资源。
4、如果是多机分布式并行计算,在4台机器上,采用4*4的16个实例完成计算,效率还会成倍提升,而且机器数量越多,计算越快。
5、单机递归实现和运行简单,使用c或者java写个main函数完成即可,而分布式并行程序,则需要利用并行框架,以包工头+多个工人的全新并行计算思想去完成。
2) 多机迭代
我们最后看看如何构思多机分布式迭代方式实现。
思路一:
根据单机迭代的特点,我们可以将n台计算机编号为1到n
第一轮统计各工人发送编号给工头,工头合并得到第一轮结果{1,2,3,…,n}
第二轮,工头将第一轮结果发给各工人做为计算输入条件,各工人根据自己编号累加,返回结果给工头合并,得到第二轮结果:{11,12,13,1n,…,n1,n2,n3,nn}
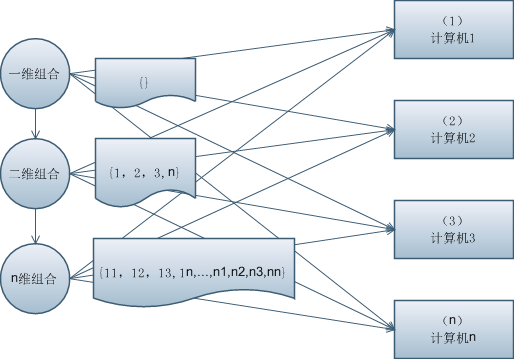
这样迭代下去,直到m轮结束,如上图所示。
但很快就会发现,工头合并每轮结果是个很大的瓶颈,很容易内存不够导致计算崩溃。
思路二:
如果对思路一改进,各工人不发中间结果给工头合并,而采取工人之间互相合并方式,将中间结果按编号分类,通过receive方式(工人互相合并及receive使用可参见sayhello demo),将属于其他工人编号的数据发给对方。这样一定程度避免了工头成为瓶颈,但是经过实践发现,随着迭代变大,中间结果数据越来越大,工人合并耗用网络也越来越大,如果中间结果保存在各工人内存中,随着m变的更大,仍然存在内存溢出危险。
思路三:
继续改进思路二,将中间结果变量不保存内存中,而每次写入文件(详见Fourinone2.0对分布式文件的简化操作),这样能避免内存问题,但是增加了大量的文件io消耗。虽然能运行出结果,但是并不高效。
总结:
或许分布式迭代在这里并不是最好的做法,上面的多机递归更合适。由于迭代计算的特点,需要将中间结果进行保存,做为下一轮计算的条件,如果为了利用多机并行计算优势,又需要反复合并产生中间结果,所以导致对内存、带宽、文件io的耗用很大,处理不当容易造成性能低下。
我们早已经进入多cpu多核时代,但是我们的传统程序设计和算法还停留在过去单机应用,因此合理利用并行计算的优势来改进传统软件设计思想,能为我们带来更大效率的提升。
以下是分布式并行递归的demo源码:
001
|
// CombTest
|
002
|
import java.util.Date;
|
003
|
public class CombTest
|
004
|
{
|
005
|
int m=0,n=0,total=0;
|
006
|
CombTest(int n, int m){
|
007
|
this.m=m;
|
008
|
this.n=n;
|
009
|
}
|
010
|
public void comb(String str)
|
011
|
{
|
012
|
for(int i=1;i<n+1;i++){
|
013
|
if(str.length()==m-1){
|
014
|
//System.out.println(str+i);//打印出组合序列
|
015
|
total++;
|
016
|
}
|
017
|
else
|
018
|
comb(str+i);
|
019
|
}
|
020
|
}
|
021
|
|
022
|
public static void main(String[] args)
|
023
|
{
|
024
|
CombTest ct = new CombTest(Integer.parseInt(args[0]), Integer.parseInt(args[1]));
|
025
|
long begin = (new Date()).getTime();
|
026
|
ct.comb("");
|
027
|
System.out.println("total:"+ct.total);
|
028
|
long end = (new Date()).getTime();
|
029
|
System.out.println("time:"+(end-begin)/1000+"s");
|
030
|
}
|
031
|
}
|
032
|
033
|
// ParkServerDemo
|
034
|
import com.fourinone.BeanContext;
|
035
|
public class ParkServerDemo{
|
036
|
public static void main(String[] args){
|
037
|
BeanContext.startPark();
|
038
|
}
|
039
|
}
|
040
|
041
|
// CombCtor
|
042
|
import com.fourinone.Contractor;
|
043
|
import com.fourinone.WareHouse;
|
044
|
import com.fourinone.WorkerLocal;
|
045
|
import java.util.Date;
|
046
|
public class CombCtor extends Contractor
|
047
|
{
|
048
|
public WareHouse giveTask(WareHouse wh)
|
049
|
{
|
050
|
WorkerLocal[] wks = getWaitingWorkers("CombWorker");
|
051
|
System.out.println("wks.length:"+wks.length+";"+wh);
|
052
|
wh.setObj("wknum",wks.length);
|
053
|
WareHouse[] hmarr = doTaskBatch(wks, wh);//批量执行任务,所有工人完成才返回
|
054
|
int total=0;
|
055
|
for(WareHouse hm:hmarr)
|
056
|
total+=(Integer)hm.getObj("total");
|
057
|
System.out.println("total:"+total);
|
058
|
return wh;
|
059
|
}
|
060
|
|
061
|
public static void main(String[] args)
|
062
|
{
|
063
|
CombCtor a = new CombCtor();
|
064
|
WareHouse wh = new WareHouse("comb", Integer.parseInt(args[0]));
|
065
|
long begin = (new Date()).getTime();
|
066
|
a.doProject(wh);
|
067
|
long end = (new Date()).getTime();
|
068
|
System.out.println("time:"+(end-begin)/1000+"s");
|
069
|
a.exit();
|
070
|
}
|
071
|
}
|
072
|
073
|
//CombWorker
|
074
|
import com.fourinone.MigrantWorker;
|
075
|
import com.fourinone.WareHouse;
|
076
|
public class CombWorker extends MigrantWorker
|
077
|
{
|
078
|
private int m=0,n=0,total=0,index=-1;
|
079
|
080
|
public WareHouse doTask(WareHouse wh)
|
081
|
{
|
082
|
total=0;
|
083
|
n = (Integer)wh.getObj("wknum");
|
084
|
m = (Integer)wh.getObj("comb");
|
085
|
index = getSelfIndex()+1;
|
086
|
System.out.println("index:"+index);
|
087
|
comb(index+"");
|
088
|
System.out.println("total:"+total);
|
089
|
return new WareHouse("total",total);
|
090
|
}
|
091
|
|
092
|
public void comb(String str)
|
093
|
{
|
094
|
for(int i=1;i<n+1;i++){
|
095
|
if(str.length()==m-1){
|
096
|
//System.out.println(str+i);//打印出组合序列
|
097
|
total++;
|
098
|
}
|
099
|
else
|
100
|
comb(str+i);
|
101
|
}
|
102
|
}
|
103
|
|
104
|
public static void main(String[] args)
|
105
|
{
|
106
|
CombWorker mw = new CombWorker();
|
107
|
mw.waitWorking(args[0],Integer.parseInt(args[1]),"CombWorker");
|
108
|
}
|
109
|
}
|
转载于:https://www.cnblogs.com/dushu/archive/2012/12/20/2826062.html
使用并行计算大幅提升递归算法效率相关推荐
- 华为云发布全新DevOps实践,大幅提升交付效率
日前,在QCon全球软件开发大会上,华为云DevCloud发布DevCloud on DevCloud DevOps实践.借助该方案,DevCloud得以达成每天10次的高频发布目标. 华为云DevC ...
- 64位linux并行计算大气模型效率优化研究,64位Linux并行计算大气模型效率优化研究...
第26卷第6期 2009年6月 计算机应用研究 ApplicationResearchofComputers V01.26No.6 Jun.2009 64位Linux并行计算大气模型 效率优化研究术 ...
- 回溯法解决01背包-非递归算法-效率低
http://acm.zua.edu.cn/problem.php?cid=1025&pid=24 解题思路: 物体的个数为Num,背包的体积限制为Volum 物品的体积是v[1].v[2]. ...
- CUDA并行计算 | CUDA算法效率提升关键点概述
文章目录 前言 存取效率 计算效率 性能优化要点 展现足够的并行性 优化内存访问 优化指令执行 前言 CUDA算法的效率总的来说,由存取效率和计算效率两类决定,一个好的CUDA算法必定会让两类效率 ...
- 镭速传输攻克视频素材传输顽疾,大幅提升业务效率
云语科技旗下的镭速传输,为IT.影视.生物基因.制造业等众多行业实现高性能.稳定安全的数据传输服务.目前有2W+企业使用镭速传输提供的大数据传输方案解决企业面临的数据交互问题. 本次与云语团队对接的是 ...
- 飞步科技 x 焱融 YRCloudFile:大幅提升训练效率,开启智驾新纪元
随着冬奥会的完美闭幕和残奥会的开幕,北京成为了奥运史上首个成功举办奥运会和冬奥会的"双奥之城".在本届冬奥会赛场上,大家除了对赛场内奥运健儿们的表现印象深刻以外,在赛场外,中国的科 ...
- 大幅提升冲浪效率,搜狗高速浏览器3.0
随着近年IE6.0市场占有率的逐步下滑,各大浏览器厂商之间可谓硝烟四起.在以Firefox.Chrome为代表的国外老牌劲旅不断以功能更为强劲的新版本吸引用户的同时,国内浏览器厂商也不甘示弱,多个门户 ...
- 工作党必备的5款办公软件,大幅提升工作效率,用过的都说好用
对于工作党来说,能够找到一款好用的办公软件实在是太重要啦!很多工作如果单纯靠手动的话,那真的是会浪费很多的时间,也不是因为懒得动手,主要是想提升工作效率. 1.文件对比--Diffchecker Di ...
- 《大规模分布式系统架构与设计实战》
<大规模分布式系统架构与设计实战> 基本信息 作者: 彭渊 丛书名: 大数据技术丛书 出版社:机械工业出版社 ISBN:9787111455035 上架时间:2014-2-21 出版日期: ...
- EDA云实证Vol.10:Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?
这是我们EDA云实证的第四期. 本期实证的主角是--Virtuoso. 半导体行业中使用范围最广的EDA应用之一. 1991年Virtuoso技术正式发布,最初作为掩模设计师的版图工具,是Opus平台 ...
最新文章
- 羡慕嫉妒!看了腾讯月收入 8 万 的支出账单不恨了 | 每日趣闻
- Qt 独立运行时伴随CMD命令窗口
- ios13 无法传参_iOS13个人热点功能频遭投诉
- 用Asp.Net创建基于Ajax的聊天室程序
- mysql join 排序_MySQL查询优化:连接查询排序limit(join、order by、limit语句)
- 易语言卷帘菜单与json_易语言卷帘式菜单组件使用教程
- 已知函数ex可以展开为幂级数。现给定一个实数x,要求利用此幂级数部分和求ex的近似值,求和一直继续到最后一项的绝对值小于0.00001。
- kettle连接oracle汉字乱码
- 计算机抖音链接,抖音怎么开始电脑直播
- 计算机网卡不连接网络连接怎么办,台式机无线网卡连接不上网络怎么办
- 计算日期间隔,以XX年XX月XX日格式显示
- c#未能加载程序集oracle.dataaccess,未能加载文件或程序集“Oracle.DataAccess, Version=2.112.1.0...
- win7无法连接虚拟磁盘服务器,win7系统电脑打开磁盘管理出现“无法连接虚拟磁盘服务”的解决方法...
- 发光二极管之—工作原理图解分析
- python 换页符_python分页字符串
- python jit_Pypy Python的JIT实现
- Activity详解2
- 星际穿越+降临+明日边缘?星际拓荒重新定义星际探索题材游戏
- MacOS 平台使用CLion工具进行ndk开发示例
- 写一篇基于SPEA2算法的高维多目标救灾物资分配的论文