如何应对海量数据时代的挑战
如何应对海量数据时代的挑战?
大数据的浪潮有多迅猛?IDC在2006年估计全世界产生的数据量是0.18ZB(1ZB=100万PB),而今年这个数字已经提升了一个数量级,达到1.8ZB,差不多对应全世界每个人一块100多GB的硬盘。这种增长还在加速,预计2015年将达到近8ZB。目前IT系统的存储能力远远不足,就更不用说深入地挖掘和分析了。
在本文中,百度首席科学家威廉•张、Teradata首席客户官周俊凌、Yahoo!北京全球软件研发中心架构师韩轶平、SAP中国区企业信息管理咨询资深顾问杜韬等四位业内专家,将分享他们在应对海量数据挑战方面的见解和经验。

|

|

|

|
| Teradata首席客户官周俊凌 | 百度首席科学家威廉•张 | Yahoo!北京全球软件研发中心架构师韩轶平 | SAP中国区企业信息管理咨询资深顾问杜韬 |
您所在企业的数据量现在达到了什么规模?
威廉•张:这个问题比较容易回答。百度不是一个产品,不仅有搜索引擎,还包括很多社区产品和媒体产品,所以这个数字大概是数百个PB,每天处理的数据大约有几十个PB。我是差不多四年半前加入百度的,所以我比较清楚地记得那时候的规模。与那时相比,现在的数据规模成长比较惊人,大概是那时的500~1000倍。
数据量大并不可怕,问题是要实时处理数据,因为任何的时延都会使服务失去一些优势,从而导致商业经济的下降。我们所做的策略都是针对实时性的,而且今天互联网用户的需求更加实时化,比如说微博、团购、秒杀。
周俊凌:从IDC的数据统计报告来看,数据增长是非常快的。相对于具体的数据量,Teradata更关注数据发展的趋势,并大量投入研究这种发展趋势,包括BI方面的变化和增长模式,这个模式对于我们非常有价值,通过研究这种模式,包括每分钟、每秒钟交易量有多大等这些数据的发掘和建模,数据科学家进行研究和探讨,把这些技术应用到生产系统里面,对企业发挥作用。
韩轶平:Yahoo!的主要云计算平台Hadoop现在有34个集群,总数超过3万台机器,最大的集群是4000台左右,总存储容量超过100PB。这个数量级可以说并不大,主要原因在于我们最近将很多精力放在处理用户隐私性和数据安全性上,因为按照欧盟的规定,Yahoo!不能存储超过一年的数据,所以我们的应对措施就是:不保存原始数据,但做很深入的数据挖掘,挖掘出真正蕴含的有价值的信息,把这些信息保存下来。
杜韬:SAP作为企业级应用提供商,更关注客户的数据量,而我们的客户有许多数据密集型企业,比如电信、金融、政府、零售等,数据量级从几个TB到数百TB。SAP在德国总部的数据中心有3万台服务器,数据量大概是15PB,主要为客户提供服务。我们正在帮助客户将内部应用迁移到我们的数据中心服务平台,这也意味着越来越多的客户数据会存在我们这儿。
面对大数据,您是怎样进行处理分析的?
杜韬:一方面在数据中心,我们使用了标准的虚拟化以及分布式存储;另一方面,我们推出了内存计算技术,用以应对数据应用和分析的挑战。传统的架构存在很大的瓶颈,磁盘读取是以毫秒,而内存读取则是纳秒。因此,我们将以前需要在应用层做的计算分析,比如预测分析或者大量运算,都放到内存里操作,从而实现性能提升,帮助用户充分利用数据。
韩轶平:对Yahoo!的情况,我想分三个部分来说明:数据采集、数据存储和数据处理。
在数据采集方面,我们建立了一个遍布Yahoo!几个数据中心、几十万台机器的实时搜集数据系统,该系统特点是一个主干道负责把数据经过过滤、清理以后,进行整合,并且在高可靠性的情况下,把它放到Hadoop平台。虽然相对来说精度很高、效果很好,但速度会慢一些。为了满足威廉•张所说实时性的需求,还有一个旁路系统,旁路系统在秒级能够把数据汇到主干道上,这是数据采集的部分。
在数据存储方面,基本上以HDFS为核心。在数据处理方面,主要技术是Hadoop、MapReduce以及我们自己开发的Pig。目前,我们有超过一半数据处理引擎是用Pig完成的。
周俊凌:Teradata一直在持续创新传统的企业级数据仓库产品线,在对接大数据时代的同时,继续传统的BI领域,包括提高数据处理的能力,从而更容易适应大数据管理。例如,通过数据访问频率高低确认数据温度,进行数据压缩,适应大数据的分析要求,使数据管理更容易。
我们有适应超高规模数据容量要求的硬件平台产品Teradata 1000,可以压缩35PB的数据。特别适用一些结构性数据和非结构性数据的分析,同时开发了很多能够进行数据统计和分析的软件包,包括将Hadoop等架构整合到Teradata数据仓库之中,可以基于目前的Teradata企业级数据仓库接口使用。
我们提供基于云的架构,能够使用Amazon EC2,为客户提供安全的存储产品,用来存储公司防火墙以外的、存储在云端的数据。我们刚刚收购了Aster Data公司,它有一些非常好的工具,适用于Hadoop、MapReduce的一些应用。
威廉•张:各互联网企业在云计算技术方面的应用都差不多,比如说百度也用了Hadoop,我提几个比较有特点的地方。
第一个是大搜索,即不仅是把网页抓过来,建立极其庞大的索引,而且为了使数据做到准实时或者更快速的更新,进行一些优化,比如根据地域分布和重要性分布,放在南方或者北方的机房里,主要还是根据数据应用制订的策略。另外就是采用数据流技术。
第二个是机器学习算法。在科技领域里,机器学习以前更多的是对一台服务器内存里的数据进行高复杂的计算,可能要跑很长时间。而在百度,机器学习应用于所有地方,比如判断用户需求,从用户行为反馈中得到我们应该推荐什么样的内容、匹配什么样的广告等,时效性非常高。可以称得上是增量型、大规模的机器学习方法。
此外,互联网应用要继续发展,最关键还是找到更有价值的数据,即不管数据来自何方,都要按照价值来决定如何处理它。
您怎样看待层出不穷的NoSQL技术?
杜韬:我一直认为,存在的就是合理的,NoSQL的产生和演进也是因为我们现有的应用需求所导致。当前在大并发量、海量数据的高效读写等方面,对关系型数据库提出了更高的要求,而NoSQL在这方面有独特的价值和优势。
当然,这并不是说NoSQL的出现就代表着关系型数据库的世界末日,因为对于一些应用,特别是企业级应用,对于事务的一致性以及读写的实时性等各方面有很高的要求,而关系型数据库在这些年的发展中积累了自己的优势。
因此,我很认同NoSQL是“Not Only SQL”的说法,相信在未来关系型数据库和NoSQL会并存甚至是相互融合。
韩轶平:NoSQL是一个很宽泛的概念。在Yahoo!,虽然NoSQL说得不多,但用的NoSQL工具非常多,我们的Key-Value数据库等各种各样的系统,都属于NoSQL框架。至于说NoSQL和SQL之间的关系,因为很多场合需要ACID,也就需要NoSQL的东西,而NoSQL之所以会出现,就像我经常说的“上帝是公平的”,当有一个需求出现时必须放弃另一个东西。我们的很多需求,比如大数据量、高分布性,当有了这些需求以后另一个需求可能成为新的瓶颈。事实上,对我们来说,互联网行业在很多应用中并不需要一致性。当把需求放宽时,自然能够满足另一些需求。
怎样挖掘数据中的价值?
威廉•张:我举一个直观的匹配广告的例子,它包括两类数据:一类是广告库,即广告内容信息和广告客户信息,这类信息很适合于传统数据库;另一类信息是用户看到广告之后的一切行为,经历了日积月累,可能会有几百万亿的用户行为。这两种数据可以相结合,经过机器学习算法就能产生价值。显然,第二种信息更重要,因为它能给用户提供想要的信息,比如搜索一个词,可以利用所有用户在他之前、在他之后的群体智能、群体行为,判定哪一类的信息最重要、最优质,哪一类信息可能是作弊信息,然后经过反馈机制,把最好的内容提供给用户,甚至推荐相关的一些搜索、查询信息。总而言之,对任何企业来说,数据是命根子;对云计算来说,数据处理就是云数据中心或者云计算存在的理由。
韩轶平:我们工作之余经常开玩笑说:从数据中能挖出的东西,不一定是钱,更重要的是用户体验,对互联网公司来说,数据就是一切。
Yahoo!不仅仅是搜索引擎,也有很多在美国各领域中排名第一的网站。我们做的很多工作,比如新闻网站信息,都是根据新闻的相关性和大家的兴趣推荐的,我们希望根据每一个用户自己的兴趣,甚至每一个用户此时此刻的兴趣,进行推荐。Yahoo!新闻的推荐系统,是把Yahoo!所有的数据搜集起来,用户在Yahoo!搜索上的所有行为都搜集到一起,做深度挖掘和个性化,对每一个用户都进行分析和推荐,没有这些数据我们不可能为客户提供体验,数据对我们来说就是一切。
杜韬:既然各位是从互联网的角度来看数据的价值,那么我就从企业的角度来分享一下。
智能电网现在欧洲已经做到了终端,也就是所谓的智能电表。在德国,为了鼓励利用太阳能,会在家庭安装太阳能,除了卖电给你,当你的太阳能有多余电的时候还可以买回来。通过电网收集每隔五分钟或十分钟收集一次数据,收集来的这些数据可以用来预测客户的用电习惯等,从而推断出在未来2~3个月时间里,整个电网大概需要多少电。有了这个预测后,就可以向发电或者供电企业购买一定数量的电。因为电有点像期货一样,如果提前买就会比较便宜,买现货就比较贵。通过这个预测后,可以降低采购成本。
另一个例子更偏我个人的兴趣。丹•布朗的《失落的秘符》一书讲到,如果把很多人的精神集中在一个点,能够移动物体。当然这个我们无从考证,但我们在网上搜索关键词、敏感词时,就可以判断出某件事情的公众态度。有一些新的业务模式,比如做一个网络广告投放评估公司,利用这样的技术评估网络广告的效果,我觉得也许是未来的业务价值产生点。
海量数据时代对企业和技术人员带来了哪些挑战?
韩轶平:以前我们都说自己是软件工程师,我们这个行业也经常被叫做软件行业,但我认为我们是真正的Information Technology行业。对大多数人来说,现在最重要的一点是转变观念,从Code/Program观念转变成Data观念,在做任何设计和开发时,要把Data放在第一位。
杜韬:海量数据一直在增长,但是我们应该想办法控制下来,未来的趋势应该放在怎样缩小海量数据上,而不是任凭它扩张。此外,海量数据时代对中国来说是一次引领世界IT业的机会。
周俊凌:在云计算时代,业务数据与云紧密结合在一起,提供业务开发的能力,我们从中学到了很多新的东西,有一些东西不再是自己去存储和开发,而是都放在云里面存储。技术产品推向市场的方式与以往相比,发生了很大变化。云的这样一种环境也给数据库提供商带来很多技术上的挑战,例如如何保证存储的安全性,包括身份识别的健全。这关系到数据的存储地方,例如现在发货的数据都是放在全球任何一个地方,不是放在某一个国家里面,这就带来关于数据主权的问题,可能有一些国家和政府不允许把数据放在国家某些地方,这都是一些挑战,需要从技术上解决安全等问题。
威廉•张:这里我浅谈一下两点感受。
首先,数据管理是DBA的一项重要本领,而高校的计算机专业教育里没有特别重视数据程序员,并没有数据管理员;其次,MapReduce并不是一个新概念,早在30~40年前当计算机能力还超小的时候,函数式编程语言就出现了,但至今大学里还没有开设MapReduce或者类似数据处理的课程,也基本上没有人听过这些东西。
未来将所有人的生活经验数据放在云里,这个大概可以实现,但如果解决不好数据安全性问题的话,那么距离最终的实现就会很远。我期待云计算变成云知识、云智能,而不仅仅是计算的工具。建立数据整合分享是云计算成功的必要和充分条件。
前言
本博客内曾经整理过有关海量数据处理的10道面试题(十道海量数据处理面试题与十个方法大总结),此次除了重复了之前的10道面试题之后,重新多整理了7道。仅作各位参考,不作它用。
同时,程序员编程艺术系列将重新开始创作,第十一章以后的部分题目来源将取自下文中的17道海量数据处理的面试题。因为,我们觉得,下文的每一道面试题都值得重新思考,重新深究与学习。再者,编程艺术系列的前十章也是这么来的。若您有任何问题或建议,欢迎不吝指正。谢谢。
第一部分、十五道海量数据处理面试题
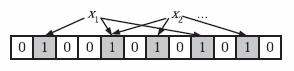
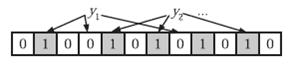
1. 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
方案1:可以估计每个文件安的大小为50G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
- 遍历文件a,对每个url求取
 ,然后根据所取得的值将url分别存储到1000个小文件(记为)中。这样每个小文件的大约为300M。
,然后根据所取得的值将url分别存储到1000个小文件(记为)中。这样每个小文件的大约为300M。 - 遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为)。这样处理后,所有可能相同的url都在对应的小文件()中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
- 求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
读者反馈@crowgns:
- hash后要判断每个文件大小,如果hash分的不均衡有文件较大,还应继续hash分文件,换个hash算法第二次再分较大的文件,一直分到没有较大的文件为止。这样文件标号可以用A1-2表示(第一次hash编号为1,文件较大所以参加第二次hash,编号为2)
- 由于1存在,第一次hash如果有大文件,不能用直接set的方法。建议对每个文件都先用字符串自然顺序排序,然后具有相同hash编号的(如都是1-3,而不能a编号是1,b编号是1-1和1-2),可以直接从头到尾比较一遍。对于层级不一致的,如a1,b有1-1,1-2-1,1-2-2,层级浅的要和层级深的每个文件都比较一次,才能确认每个相同的uri。
2. 有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
方案1:
- 顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
- 找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为)。
- 对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:
与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
3. 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
方案1:顺序读文件中,对于每个词x,取 ![]() ,然后按照该值存到5000个小文件(记为
,然后按照该值存到5000个小文件(记为 ![]() )中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,知道分解得到的小文件的大小都不超过1M。对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,知道分解得到的小文件的大小都不超过1M。对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
4. 海量日志数据,提取出某日访问百度次数最多的那个IP。
方案1:首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
5. 在2.5亿个整数中找出不重复的整数,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32*2bit=1GB 内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用上题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
6. 海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
方案1:
- 在每台电脑上求出TOP10,可以采用包含10个元素的堆完成(TOP10小,用最大堆,TOP10大,用最小堆)。比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。最后堆中的元素就是TOP10大。
- 求出每台电脑上的TOP10后,然后把这100台电脑上的TOP10组合起来,共1000个数据,再利用上面类似的方法求出TOP10就可以了。
(更多可以参考: 第三章、寻找最小的k个数,以及 第三章续、Top K算法问题的实现)
7. 怎么在海量数据中找出重复次数最多的一个?
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
8. 上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
方案1:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用第6题提到的堆机制完成。
9. 1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
方案1:这题用trie树比较合适,hash_map也应该能行。
10. 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一个。
11. 一个文本文件,找出前10个经常出现的词,但这次文件比较长,说是上亿行或十亿行,总之无法一次读入内存,问最优解。
方案1:首先根据用hash并求模,将文件分解为多个小文件,对于单个文件利用上题的方法求出每个文件件中10个最常出现的词。然后再进行归并处理,找出最终的10个最常出现的词。
12. 100w个数中找出最大的100个数。
- 方案1:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100w*lg100)。
- 方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
- 方案3:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
13. 寻找热门查询:
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,这些查询串的重复读比较高,虽然总数是1千万,但是如果去除重复和,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就越热门。请你统计最热门的10个查询串,要求使用的内存不能超过1G。
(1) 请描述你解决这个问题的思路;
(2) 请给出主要的处理流程,算法,以及算法的复杂度。
方案1:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
14. 一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N^2个数中的中数?
方案1:先大体估计一下这些数的范围,比如这里假设这些数都是32位无符号整数(共有2^32个)。我们把0到2^32-1的整数划分为N个范围段,每个段包含(2^32)/N个整数。比如,第一个段位0到2^32/N-1,第二段为(2^32)/N到(2^32)/N-1,…,第N个段为(2^32)(N-1)/N到2^32-1。然后,扫描每个机器上的N个数,把属于第一个区段的数放到第一个机器上,属于第二个区段的数放到第二个机器上,…,属于第N个区段的数放到第N个机器上。注意这个过程每个机器上存储的数应该是O(N)的。下面我们依次统计每个机器上数的个数,一次累加,直到找到第k个机器,在该机器上累加的数大于或等于(N^2)/2,而在第k-1个机器上的累加数小于(N^2)/2,并把这个数记为x。那么我们要找的中位数在第k个机器中,排在第(N^2)/2-x位。然后我们对第k个机器的数排序,并找出第(N^2)/2-x个数,即为所求的中位数的复杂度是O(N^2)的。
方案2:先对每台机器上的数进行排序。排好序后,我们采用归并排序的思想,将这N个机器上的数归并起来得到最终的排序。找到第(N^2)/2个便是所求。复杂度是O(N^2*lgN^2)的。
15. 最大间隙问题
给定n个实数 ![]() ,求着n个实数在实轴上向量2个数之间的最大差值,要求线性的时间算法。
,求着n个实数在实轴上向量2个数之间的最大差值,要求线性的时间算法。
方案1:最先想到的方法就是先对这n个数据进行排序,然后一遍扫描即可确定相邻的最大间隙。但该方法不能满足线性时间的要求。故采取如下方法:
- 找到n个数据中最大和最小数据max和min。
- 用n-2个点等分区间[min, max],即将[min, max]等分为n-1个区间(前闭后开区间),将这些区间看作桶,编号为,且桶i 的上界和桶i+1的下届相同,即每个桶的大小相同。每个桶的大小为:。实际上,这些桶的边界构成了一个等差数列(首项为min,公差为),且认为将min放入第一个桶,将max放入第n-1个桶。
- 将n个数放入n-1个桶中:将每个元素x 分配到某个桶(编号为index),其中,并求出分到每个桶的最大最小数据。
- 最大间隙:除最大最小数据max和min以外的n-2个数据放入n-1个桶中,由抽屉原理可知至少有一个桶是空的,又因为每个桶的大小相同,所以最大间隙不会在同一桶中出现,一定是某个桶的上界和气候某个桶的下界之间隙,且该量筒之间的桶(即便好在该连个便好之间的桶)一定是空桶。也就是说,最大间隙在桶i的上界和桶j的下界之间产生j>=i+1。一遍扫描即可完成。
16. 将多个集合合并成没有交集的集合
给定一个字符串的集合,格式如:![]() 。要求将其中交集不为空的集合合并,要求合并完成的集合之间无交集,例如上例应输出
。要求将其中交集不为空的集合合并,要求合并完成的集合之间无交集,例如上例应输出![]() 。
。
(1) 请描述你解决这个问题的思路;
(2) 给出主要的处理流程,算法,以及算法的复杂度;
(3) 请描述可能的改进。
方案1:采用并查集。首先所有的字符串都在单独的并查集中。然后依扫描每个集合,顺序合并将两个相邻元素合并。例如,对于 ![]() ,首先查看aaa和bbb是否在同一个并查集中,如果不在,那么把它们所在的并查集合并,然后再看bbb和ccc是否在同一个并查集中,如果不在,那么也把它们所在的并查集合并。接下来再扫描其他的集合,当所有的集合都扫描完了,并查集代表的集合便是所求。复杂度应该是O(NlgN)的。改进的话,首先可以记录每个节点的根结点,改进查询。合并的时候,可以把大的和小的进行合,这样也减少复杂度。
,首先查看aaa和bbb是否在同一个并查集中,如果不在,那么把它们所在的并查集合并,然后再看bbb和ccc是否在同一个并查集中,如果不在,那么也把它们所在的并查集合并。接下来再扫描其他的集合,当所有的集合都扫描完了,并查集代表的集合便是所求。复杂度应该是O(NlgN)的。改进的话,首先可以记录每个节点的根结点,改进查询。合并的时候,可以把大的和小的进行合,这样也减少复杂度。
17. 最大子序列与最大子矩阵问题
数组的最大子序列问题:给定一个数组,其中元素有正,也有负,找出其中一个连续子序列,使和最大。
方案1:这个问题可以动态规划的思想解决。设b 表示以第i个元素a结尾的最大子序列,那么显然![]() 。基于这一点可以很快用代码实现。
。基于这一点可以很快用代码实现。
最大子矩阵问题:给定一个矩阵(二维数组),其中数据有大有小,请找一个子矩阵,使得子矩阵的和最大,并输出这个和。
方案2:可以采用与最大子序列类似的思想来解决。如果我们确定了选择第i列和第j列之间的元素,那么在这个范围内,其实就是一个最大子序列问题。如何确定第i列和第j列可以词用暴搜的方法进行。
第二部分、海量数据处理之Bti-map详解
什么是Bit-map
所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
如果说了这么多还没明白什么是Bit-map,那么我们来看一个具体的例子,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0(如下图:)
然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作 p+(i/8)|(0×01<<(i%8)) 当然了这里的操作涉及到Big-ending和Little-ending的情况,这里默认为Big-ending),因为是从零开始的,所以要把第五位置为一(如下图):
然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。下面的代码给出了一个BitMap的用法:排序。
view plain
- //定义每个Byte中有8个Bit位 #include <memory.h> #define BYTESIZE 8 void SetBit(char *p, int posi) { for(int i=0; i < (posi/BYTESIZE); i++) { p++; } *p = *p|(0x01<<(posi%BYTESIZE));//将该Bit位赋值1 return; } void BitMapSortDemo() { //为了简单起见,我们不考虑负数 int num[] = {3,5,2,10,6,12,8,14,9}; //BufferLen这个值是根据待排序的数据中最大值确定的 //待排序中的最大值是14,因此只需要2个Bytes(16个Bit) //就可以了。 const int BufferLen = 2; char *pBuffer = new char[BufferLen]; //要将所有的Bit位置为0,否则结果不可预知。 memset(pBuffer,0,BufferLen); for(int i=0;i<9;i++) { //首先将相应Bit位上置为1 SetBit(pBuffer,num); } //输出排序结果 for(int i=0;i<BufferLen;i++)//每次处理一个字节(Byte) { for(int j=0;j<BYTESIZE;j++)//处理该字节中的每个Bit位 { //判断该位上是否是1,进行输出,这里的判断比较笨。 //首先得到该第j位的掩码(0x01<<j),将内存区中的 //位和此掩码作与操作。最后判断掩码是否和处理后的 //结果相同 if((*pBuffer&(0x01<<j)) == (0x01<<j)) { printf("%d ",i*BYTESIZE + j); } } pBuffer++; } } int _tmain(int argc, _TCHAR* argv[]) { BitMapSortDemo(); return 0; }
可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点
使用bit数组来表示某些元素是否存在,比如8位电话号码
扩展
Bloom filter可以看做是对bit-map的扩展(关于Bloom filter,请参见:海量数据处理之Bloom filter详解)。
问题实例
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
整理自:
- http://www.cnblogs.com/youwang/archive/2010/07/20/1781431.html
- http://blog.redfox66.com/post/2010/09/26/mass-data-4-bitmap.aspx
|
||||





|
||||



|
||||














|
||||
|
||||






|
||||
|
||||

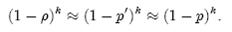
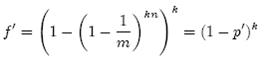
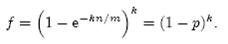
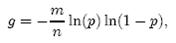
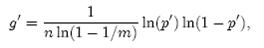
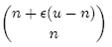
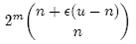
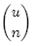
|
||||
|
||||
|
||||




| usidc5 | 2012-05-29 15:27 |
|
美国国家超级计算应用中心(National Center for Supercomputing Applications)正计划推出一个包含380PB磁带存储容量和由17000个SATA驱动器组成的25PB在线磁盘存储的存储基础设施。 这个大规模存储基础设施将用于支持世界上最大的超级计算机之一,被称为Blue Waters。由美国国家科学基金会(NFS)委托制造的Blue Waters预计峰值性能将达到11.5 petaflops,虽然NFS对其的要求是提供1 petaflop的应用程序持续计算能力。 美国伊利诺伊大学运行的NCSA已经与Cray公司签署了一份合同来建设这个超级计算机,该系统将运行一个Lustre并行文件系统,到其后端存储的吞吐量将超过1TB每秒。 Blue Waters项目将创造一个1 petaflop超级计算机来处理现实世界科学和工程应用。其中,这台超级计算机将帮助人类理解宇宙大爆炸后宇宙是如何演化的,帮助预测飓风和龙卷风的形成,并在新材料的设计中在原子水平上发挥重要作用。 这台超级计算机将包含超过235个使用380000个AMD Opteron 6200系列X82处理器的Cray XE6机柜,和超过30个最新推出的Cray XK6超级计算机(拥有3000个NVIDIA CPU)未来版本的机柜。该系统将包含来自19万个内存DIMM的1.5PB聚合内存。 为了支持所有这些计算能力,NCSA使用Cray Sonexion存储系统部署了25PB磁盘存储。Sonexion原本被称为Zyratex存储阵列,该系统通过40Gbps以太网从Extreme Networks提供高达1TBps聚合带宽。 “我们一直努力与网络供应商合作,以确保他们准备好迎接40千兆以太网,”NCSA负责存储和网络工程的高级技术项目经理Michelle Butler表示,“我们并不是第一个使用40Gbps以太网的,但是现在使用这个以太网的人并不多。” Butler表示,使用40Gbit以太网网络的关键是将管道分成多个10Gbps以太网通道的能力,使NCSA将架构分散到多个端口。该以太网将被用于连接75台主机。 Butler表示,NCSA还选择了DataDirect Network的SFA 12K存储阵列提供100GBps存储性能来卸载数据到“近线”磁带库系统。该磁带子系统可扩展到500PB容量。 她表示:“该子系统能够卸载每秒万亿字节的文件系统,所以我们需要一个非常大的磁带基础设施来进行卸载。”  正在建设中的Blue Waters超级计算机 在主存储后面是四个Spectra Logic 17-frame T-Finity磁带库,磁带库将拥有366个240MB/sec 的IBM TS1140企业级磁带驱动器。该磁带库将提供高达每小时2.2PB的聚合读/写率。 Butler表示:“我们实际上评估了LTO-5或LTO-6和TS1140,我们并没有指定何种磁带驱动器、何种库或者其他任何东西。我们希望让供应商自由地向我们提供多种解决方案。” Butler表示,NCSA选择IBM磁带驱动器,而没有选择更流行的中级LTO驱动器,因为它们提供优越的性能。TS1140提供240MB每秒的吞吐量,LTO驱动器提供140MB每秒。 在意见请求书中,Butler的团队给存储供应商列出了10到15个要求。除此之外,它们还规定磁带库必须要符合一定面积,不能超过一定电力和冷却要求,并且应该满足某种可靠性和性能目标。 Butler表示,磁带库聚合吞吐量的目标是100GB/sec,目前,大约为89.5GB/sec。 Cray超级计算机通过Mellanox IS5000 InfiniBand交换机和ConnectX InfiniBand适配器连接到磁带库。交换机使用InfiniBand QDR协议,提供高达每个lane 8Gbps吞吐量和高达12个I/O lane。Butler表示,她想要使用更高带宽版本的InfiniBand, FDR,但是Cray的系统不支持。 InfiniBand FDR提供每个lane 13.6 Gbps吞吐量和高达12个I/O lane。 虽然NCSA可以从很多企业级磁盘存储供应商中选择产品用于超级计算机中,Butler及其团队感觉如果所有产品都来自于Cray的话,他们将会得到更好的支持。 “Lustre,如你所知,并不好维护,所以我们想要与特定供应商合作,使用其软件硬件,并有一个设备来进行故障转换等,自2003年以来,我们就一直运行Lustre,”Butler表示,“所以我理解Cray公司试图为我们简化我们的系统。” |
|
在过去几年,一种新兴的大型数据存储机制正吞噬大数据存储市场。这种存储解决方案与传统的RDBMS有显著的区别,它们被称之为NoSQL。
在NoSQL世界中有以下关键的成员,包括
●Google BigTable、HBase、Hypertable
●Amazon Dynamo、Voldemort、Cassendra、Riak
●Redis
●CouchDB、MongoDB
而这些解决方案又有一些共同的特点
●基于键-值存储
●系统运行在海量的普通机器上
●数据在经过分区和复制后分布在集群中
●放宽对数据一致性的要求(因为CAP定理)。
选择NoSQL的重要标准就是要看CAP(Consistency、Availability和Partition Tolerance),也就是我们所说的一致性、可用性和分区容忍性。但CAP原则要求在分布式系统只能选择一致性、可用性和分区容忍性其中的两项。
本文旨在提取这些解决方案背后的共同的技术,以便更深入的了解应用程序设计的意义。本文并不会对这些解决方案作比较,也不会建议使用某一款产品。
API模型
底层的数据模型可以被看作为一个大的Hashtable(键/值存储)
API访问基本形式:
get(key):提取给定键的对应值
put(key,value) :新建或更新给定键的对应值
delete(key):删除键及其关联值
在服务器环境利用更高级的API执行用户自定义的函数
execute(key, operation, parameters) :调用操作给定键对应的值,值具有特殊数据(例如List、Set、Map等)
mapreduce(keyList, mapFunc, reduceFunc) :对范围内的键调用MapReduce
机器布局

底层基础设施由大量(成百上千)廉价的、普通的、不可靠的机器通过网络组成。每台机器为一个单独的物理节点(PN)。在每个PN软件配置相同,但CPU、内存、硬盘等会有所不同。每个PN根据不同的硬件配置运行不同数目的虚拟节点。
数据分区

由于整个Hashtable分布在众多VN之中,我们需要一种能够将每个键映射到对应VN的方法。一种行之有效的方法是:partition = key mod (total_VNs)。这种方案的缺点是当我们改变VN的数量时,现有键的所有权将发生巨大的变化,这导致全部的数据需要重新再分配。所以多数大型存储使用被称为“consistent hashing”的技术将键所有权变更的影响最小化。
在“consistent hashing”方法中,键空间是有限的,且分布在一个环上。虚拟节点的ID也从相同的键空间中分配。对于任意键,如果从该键沿着环顺时针移动,遇到了第一个虚拟节点就是它的所属节点。当某一节点崩溃时,他所属的所有键都将顺时针的移动到相邻的节点。因此,重新分配键的情况只发生在崩溃节点的相邻节点中,而所有其他的节点仍保持原有的键值。
数据复制

为了从单个并不可靠的资源来提供更高的可靠性,迫使我们需要复制数据分区。
复制不仅提高了数据的可靠性,同时将工作负载分布到多个副本还有助于提升性能。
只读请求可以分发到任何副本,而更新的要求却具有挑战性。因为需要任职协调各个副本的更新。
成员变动

请注意,虚拟节点可以随时加入和离开而不影响环的运作网络。
当心节点加入到网络
1.新加入的节点将示意自身的存在,并将其ID通知其他重要的节点。
2.所有相邻(左边或右边)节点将调整键的所有权以及副本成员的信息,这将通过同步完成。
3.新加入的节点开始从其相邻的节点并行、异步的批量复制数据。
4.副本成员的变更异步传播到其他节点
当现有节点脱离网络时(例如崩溃)

1.崩溃的节点不再回应Gossip消息,因此相邻的节点也会得知此情况。
2.相邻节点更新成员信息,同时异步复制数据。
客户端的一致性
一旦我们拥有相同数据的多个副本,就必须考虑如何同步他们,这样在客户端看来数据才能使一致的。
1.严格的一致性:从语义上看相当只存在一个数据副本,任何更新看上去都是实时发生的。
2.读取已写内容的一致性:允许客户端立刻看到自身所做的更新,但无法看到其他客户端的更新
3.会话一致性:对于客户端在同一会话作用域发出的请求,提供读取已写内容一致性。
4.单调读一致性:保证时间的单调性,保证客户端在未来的请求中只读区比当前更新的数据。
5.最终一致性:提供最低限度的保证。在更新过程中客户端将看到不一致的视图。当并发访问同一数据几率非常小的时候,此模型效果可以得到保证。
同时取决采用何种一致性模型需要安排两种机制
●客户端请求如何让分发到副本
●副本如何传播以及应用更新
围绕着如何实现这两方面。出现了许多模型,各有不同的权衡取舍。
矢量时钟

矢量时钟是一种时间戳机制,透过矢量时钟我们可以推到更新之前的因果关系。首先,每个副本都持有矢量时钟。假设副本i的时钟是Vi。Vi是副本根据特定规则更新矢量时钟之后的逻辑时钟。
●当副本i执行了一则内部操作,副本i的时钟加1。
●当副本i向副本j发送一则消息,副本i首先把自己的时钟Vi加1,并将自己的矢量时钟Vi附加到消息中发送出去。
●当副本j收到来自副本i的消息,首先自增其时钟Vj[j],然后合并其时钟及消息所附的时钟Vm。即Vj[k] = max (Vj[k], Vm[k])。
于是可以定义偏序关系,Vi > Vj,当且仅当对于所有的k,Vi[k] >= Vj[k]。根据这样的偏序关系,我们就可以推导出更新之间的因果关系。其背后原理如下
●内部操作的效果可在同一节点上立即看到。
●接到消息之后,接收节点得知发送节点在消息发送之时的情况。情况不仅包括发送节点上发生的事情,还包括发送节点所知的所有其他节点上发生的事情。
●Vi反映了节点i上发生最后一次内部操作的时间。Vi[k] = 6意味着副本i已经知道副本k在他的逻辑时钟6时刻的情况。
MapReduce的执行过程

分布式存储架构同样适合分布式的处理,例如对一个键列表执行Map/Reduce操作情况。
系统将Map和Reduce函数推送给全部的节点。Map函数分布到键所属的各个副本上处理,然后Map函数的输出被转交给Reduce函数去执行聚合操作。
对删除的处理

在多主复制系统中,用矢量时钟时间戳去判定因果序,需要非常小心处理“删除”的情况。以免丢失掉删除对象关联的时间戳信息,否则根本无法推到何时执行删除。因此,通常需要将删除当作一种特殊的更新来处理,把对象标记为删除,但仍然保留元数据、时间戳信息。当经过足够长的时间,并确信所有节点都已经对该对象标记为删除之后,才能通过垃圾回收已删除对象的空间。(Шевченко/编译)
如何应对海量数据时代的挑战相关推荐
- 大数据,轻松应对海量数据存储与分析所带来的挑战
文章目录 一.前言 二.Spark 2.1 Spark架构 2.2 Spark核心组件 2.3 Spark编程模型 2.4 Spark计算模型 2.5 Spark运行流程 2.6 Spark RDD流 ...
- Python大数据处理,应对海量数据挑战
Python大数据处理,应对海量数据挑战 Python的特点及在大数据处理中的优势 1 Python语言的特点 2 Python在大数据处理中所具备的优势 二.Python常用的大数据处理工具介绍 1 ...
- 大前端时代的挑战与机遇(深圳场)正式开放报名
2017年,以饿了么为代表的一些企业开始提出大前端的概念.2018年,InfoQ 举办了首届全球大前端技术大会,在大会中将前后端分离.跨平台和 PWA 等技术设立了专场,这次大会具有重要的意义,它预示 ...
- 京颐医疗云产品总监柏鹏:云转型布局未来,我们是如何应对医疗云的挑战与机遇...
[现场视频]京颐医疗云产品总监柏鹏:云转型布局未来,我们是如何应对医疗云的挑战与机遇,点此观看视频→https://yq.aliyun.com/video/play/1172 摘要:在9月7日云栖专家 ...
- TDSQL-A,全力应对海量数据实时分析需求
5月18日,腾讯云发布首款分布式分析型数据库TDSQL-A,全力应对海量数据实时分析需求. 这是腾讯云数据库在品牌升级后的首次新品发布.经过多年发展,腾讯积累了丰富的处理海量复杂数据的能力,如今该产品 ...
- 网页数据抓取,关键在于抓取的准确性和应对海量数据时的快速反应
无论是互联网科技.大数据.还是云计算,关键都在于技术优势,技术的成本和门槛都很高,不是两三个人零成本就可以打造一个产品. 我们以网页数据抓取来说,一门基于web结构或基于浏览器可视化的数据获取技术,关 ...
- 计算机与护理信息学,迎接信息时代的挑战——护理信息学的兴起与发展
迎接信息时代的挑战--护理信息学的兴起与发展 运用文献研究法回顾了当代护理学新兴学科--护理信息学的兴起与发展过程,介绍了护理信息学主要研究和应用的领域,包括护理词汇系统, (本文共2页) 阅读全文& ...
- 如何应对互联网大数据时代的挑战
"21世纪是一个复杂而不可预知的世纪,我们那些照目前来看已经固定的思维习惯和价值观正接受新的挑战.",这是当代著名动画导演.动画师及漫画家宫崎骏先生对快速发展的互联网时代的体悟! ...
- 应对容器时代面临的挑战:长风破浪会有时、直挂云帆济沧海
当今的时代,容器的使用越来越普及,Cgroups.Docker.Kubernetes 等项目和技术越来越成熟,成为很多大规模集群的基石. 容器是一种沙盒技术,可以对资源进行调度分配和限制配额.对不同应 ...
- 初识Hadoop,轻松应对海量数据存储与分析所带来的挑战
目录 一.前言:什么是Hadoop? 二.Hadoop生态圈 2.1 Hadoop2.x的生态系统 2.2 Hadoop2.x各个组件 2.3 大数据与云计算 三.HDFS(分布式文件系统) 3.1 ...
最新文章
- New Year Tree(dfs序+线段树+二进制)
- iOS单例创建的一点疑惑
- 设置nginx开机启动
- netflix的准实验面临的主要挑战
- 前端编码规范之JavaScript
- 学python前端需要哪些基础知识_简析前端学习python3的基础
- jQuery1.3以上版本@的问题
- windows无法安装软件
- PADS2007教程(三)——原理图和PCB封装建立关联
- visual stdio 2010与sqlserver 2008下载和安装
- Mysql支持translate函数吗_oracle 中的translate函数
- 数据控制—完整性约束
- 什么是云桌面?未来有可能替代电脑吗?
- 经历“海潮效应”,云图如何成为智能家居界的苹果?
- 连接可用AP,提示“已连接,但无法访问互联网”,过一会变成“网络连接受限”,实际可以上网
- 不知道测试什么?你需要知道的软件测试类型和常识【经典长文】
- linux 锁定用户目录,Linux vfpd锁定用户目录
- C语言输出浮点数的符号、整数部分和小数部分
- Origin图中插入另一张jpg图
- 初学怕python画图工具pen以及初学个人感悟