php获取微博热搜,爬取微博热搜top50(示例代码)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称:爬取微博热搜top50
2.主题式网络爬虫的内容与数据特征分析:排名 关键词 点击量
3.主题式网络爬虫设计方案概述:
先分析页面 对比源代码找出规律,然后对网页进行爬取,再对爬取的数据进行分析和可视化。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征分析:
2.Htmls页面解析:
右击查看网页源代码
3.节点(标签)查找方法与遍历方法:
(1)热搜的名字都在
的子节点里
(2)热搜的排名都在
里(置顶热搜没有排名)
(3)热搜的访问量都在
的子节点里

三、网络爬虫程序设计
1.爬取数据
###导入模块
importrequestsfrom lxml importetree###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器
header={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36‘}###伪装爬虫
###主函数
defmain():###获取html页面
html=etree.HTML(requests.get(url,headers=header).text)
rank=html.xpath(‘//td[@class="td-01 ranktop"]/text()‘)
affair=html.xpath(‘//td[@class="td-02"]/a/text()‘)
view= html.xpath(‘//td[@class="td-02"]/span/text()‘)
top=affair[0]
affair=affair[1:]print(‘{0:<10}{1:<40}‘.format("top",top))for i inrange(0, len(affair)):print("{0:<10}{1:{3}<30}{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
main()
爬取结果:

将top5存入Excel表格中

2.对数据进行清洗和处理:
import pandas as pd
df = pd.read_excel(‘weibotop5.xlsx‘)
df.head()``
结果如下:

3.数据分析与可视化
importmatplotlib.pyplot as plt
plt.figure(figsize=(6,4))
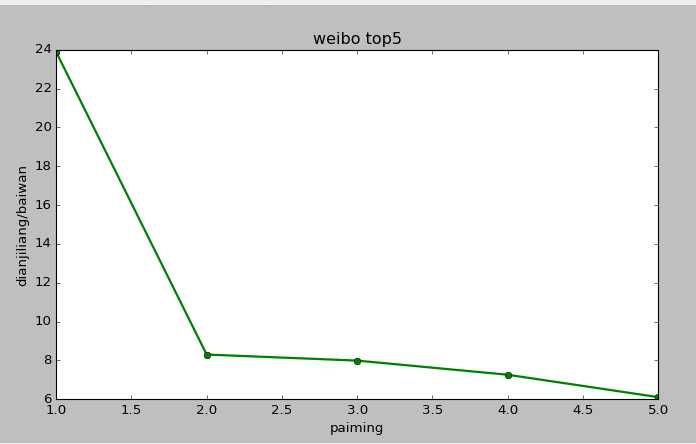
plt.plot([1,2,3,4,5],[23.887431,8.304191,7.992173,7.264128,6.110506],‘go-‘,linewidth=2)
plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘]
plt.legend()
plt.xlabel(‘paiming‘)
plt.ylabel(‘dianjiliang/baiwan‘)
plt.title(‘weibo top5‘)
plt.show()
结果如下:
importmatplotlib.pyplot as plt
plt.figure(figsize=(6,4))
x=[1,2,3,4,5]
y=[23.887431,8.304191,7.992173,7.264128,6.110506]
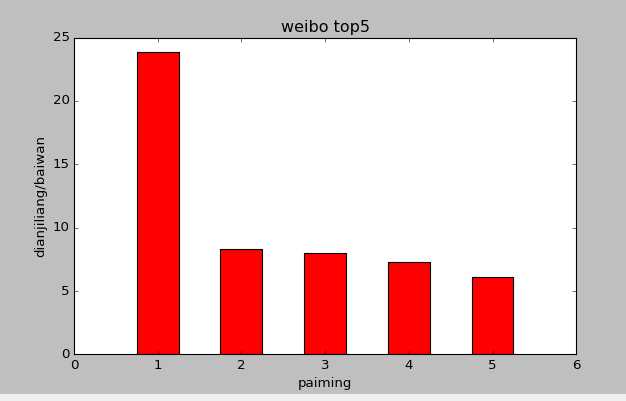
plt.bar(x,y,width=0.5,align=‘center‘,color=‘r‘)
plt.xlabel(‘paiming‘)
plt.ylabel(‘dianjiliang/baiwan‘)
plt.title(‘weibo top5‘)
plt.show()
结果如下:
四、结论
1.经过对主题分析和可视化可以得知热搜的排行与差异
2.本次作业让我学习了学习了几个新的库
php获取微博热搜,爬取微博热搜top50(示例代码)相关推荐
- 爬一个人的所有微博 python_Python爬虫--爬取微博指定用户主页下的所有图片
Python爬虫--爬取微博指定用户主页下的所有图片 写在前面 最近比较无聊,冒出来一个想法,去各大图片网站爬取大妹子的图片,然后自己写个简单的网站,按网站分类显示图片,第一个想到的是爬取知乎问题下面 ...
- python怎么爬网站视频教程_python爬虫爬取某网站视频的示例代码
把获取到的下载视频的url存放在数组中(也可写入文件中),通过调用迅雷接口,进行自动下载.(请先下载迅雷,并在其设置中心的下载管理中设置为一键下载) 实现代码如下: from bs4 import B ...
- html微博不能登录,爬取微博信息,使用了cookie仍然无法登录微博
按照网上的模板自己写了类似的代码爬取微博,可是response回来的html是登录界面的html,应该是没有成功登陆微博,但是和网上的代码是基本一样的 from bs4 import Beautifu ...
- 爬一个人的所有微博 python_pyhton爬虫爬取微博某个用户所有微博配图
前几天写了个java爬虫爬花瓣网,但是事后总感觉不够舒服,终于在今天下午写了个python爬虫(爬微博图片滴),写完之后就感觉舒服了,果然爬虫就应该用python来写,哈哈(这里开个玩笑,非引战言论) ...
- python爬虫微博图片_python爬取微博图片及内容
import random import urllib.request import json import re import requests import time id=(input(&quo ...
- python爬取微博用户信息(三)—— 创建MicroBlog类实例
这一节,主要讲述 main.py文件,该文件创建了一个MicroBlog类,MicroBlog类中包含一些爬取微博内容的函数. 以及简单介绍traceback的用法. 感兴趣的小伙伴可以收藏哦! 另外 ...
- c#使用正则表达式获取TR中的多个TD_使用python+BeautifulSoup爬取微博热搜榜
本文将介绍基于Python使用BeautifulSoup爬取微博热搜榜的实现过程 1.首先导入需要使用的库 from bs4 import BeautifulSoup from urllib.requ ...
- python 爬虫热搜_Python网络爬虫之爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 1.分析网页的源代码:右键--查看网页源代码. 从网页代码中可以获取到信息 (1)热搜的名字都在 的子节点里 (2)热搜的排名都在 ...
- python 爬关键词,Python爬虫实战:爬取微博热搜关键词
一.爬取微博热搜关键词需要的第三方库 1.requests 2.BeautifulSoup 美味汤 3.worldcloud 词云 4.jieba 中文分词 5.matplotlib 绘图 二.爬取微 ...
最新文章
- 狂神Spring Boot 员工管理系统 超详细完整实现教程(小白轻松上手~)
- 如何将NSString转换为NSNumber
- 分组聚合显示全部列_小胖带你学SQL(三)聚合与排序
- 使用 xCAT 简化 AIX 集群的部署和管理
- webpack对icon-font图片的处理
- Linux CentOS6.7设置为固定静态IP的方法
- 平台or职位,你怎么选?
- 如何在C/C++中动态分配二维数组
- MYSQL—— 启动MYSQL 57 报错“The service MYSQL57 failed the most recent........等”的问题解决方式!...
- JPA整合达梦数据库
- Ubuntu18.04 wifi不稳定
- Chrome插件-百度网盘视频调速器
- 如何将电脑设置为定时关机?
- 奶酪巫师的黑客乐园 - 第一个进行硬分叉的区块链游戏?
- 在线进行立体几何画图——GeoGebra
- log4cpp库的使用
- 《如何设计一个秒杀系统》——专栏笔记
- 【计算机网络】湖科大学习笔记---数据链路层
- QQ圈子凭借什么原理进行划分的?
- STM32之bxCAN