主成分分析(PCA)原理分析Python实现
目录
1 引言
2 PCA的意义
3 PCA的实现步骤
4 弄懂PCA要回答的问题
5 PCA原理
5.1 如何降维?
5.2 如何量化投影以后样本点之间的区分度?
5.3 求取k维坐标系
5.3.1 目标函数是否存在最大值?
5.3.2 求解目标函数的最大值以及对应的编辑
6 第4章节问题解答
6.1 为什么去均值(中心化)?
6.2 为什么要计算协方差矩阵?
6.3 为什么要计算协方差矩阵的特征值和特征向量?为什么要排序?
6.4 主成分个数N怎么确定?
7 Python代码——PCA
8 补充说明
1 引言
PCA代码实现的步骤网上已经有很完善的介绍,也有很多资料介绍过PCA的理论推导过程。本文的侧重点是从理论上解释PCA每一个步骤理由,便于更加深刻地理解PCA,而不是单纯地机械式的码代码。
2 PCA的意义
PCA的作用是数据降维。
为什么要进行数据降维呢?
在许多领域的研究与应用中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律。多变量大样本无疑会为研究和应用提供了丰富的信息,但也在一定程度上增加了数据采集的工作量,更重要的是在多数情况下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性,同时对分析带来不便。如果分别对每个指标进行分析,分析往往是孤立的,而不是综合的。盲目减少指标会损失很多信息,容易产生错误的结论。
因此需要找到一个合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量间存在一定的相关关系,因此有可能用较少的综合指标分别综合存在于各变量中的各类信息。主成分分析与因子分析就属于这类降维的方法。
3 PCA的实现步骤
![]()
4 弄懂PCA要回答的问题
① 为什么去均值(中心化)?
② 为什么要计算协方差矩阵?
③ 为什么要计算协方差矩阵的特征值和特征向量?为什么要按照特征值的大小排序?
④ 主成分个数N怎么确定?
5 PCA原理
要回答上述罗列的问题,就要从PCA的原理说起。
5.1 如何降维?
最大方差理论:在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。因此我们认为,最好的k维特征是将n维样本点转换为k维后,每一维上的样本方差都很大。
降维本质上就是一个去噪的过程。
如下图,有6个数据点(已中心化,中心化实际上就是将原点移动到样本的中心点):
![]()
将上述6个点分别投影到某一维上(用过原点的直线表示):
![]()
那么问题来了,我们选择了两条不同的过原点的直线进行投影,哪种更好呢?根据最大方差理论,左边的更好,因为样本点投影后的区分度最大,也就是方差最大。
从上面的分析可以看出 ,降维就是将原来n维样本点映射到新的k维坐标系(k<n),并要求新的样本点尽可能多地携带原始数据点的信息。要携带的信息最多,则要求新的样本点区分度最大,也就是方差最大。
实现降维的关键点有两个:
① 量化样本点之间的区分度(目标函数);
② 求取这个k维坐标系。
5.2 如何量化投影以后样本点之间的区分度?
根据最大方差理论,采用所有样本点投影大小的方差来衡量投影以后样本点之间的区分度。如图所示,蓝色点表示样例,绿色表示在u上的投影,u是直线的斜率也是直线的方向向量,而且是单位向量。绿色点是在u上的投影点,离原点的距离是,即为单个样本点的投影大小。
![]()
同理,其他样本点的投影大小也可以采用同样的方式计算得到。那么投影以后,所有样本点投影大小的方差(区分度)为:
式中,表示某个特征所有样本点投影的均值。由于原始点在最开始都进行了去均值操作,所以原始样本数据每一维特征的均值都为0,因此投影到u上的特征的均值仍然是0(即
)。那么上式可以化简为:
5.3 求取k维坐标系
求取k维坐标就是求取各个坐标轴的单位向量,可以转化成一个求解目标函数最大值的问题:
求解u,使得目标函数
要解答这个问题,分两步:
① 证明这个目标函数存在最大值;
② 求解当目标函数取最大值时,对应的u。
5.3.1 目标函数是否存在最大值?
目标函数可进行如下变换:
由于与
无关,上式可变为:
设:
,
表示特征数
则目标函数最终可表示为:
其中是一个常数,不会影响最大值得求解;
是一个二次型。设
的特征量是
,对应的特征向量是
,则有:
两边同时转置并乘特征向量:
去括号得:
又:
即:
由范数的正定性可以得出,所以
是半正定的对称矩阵,即
是半正定的二次型。由线性代数的相关知识可知,目标函数存在最大值。
5.3.2 求解目标函数的最大值以及对应的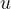
目标函数可以表示为向量的二范数平方:
求解目标函数最大值的基本问题也就转化为:对一个矩阵,它对一个向量做变换,变换前后的向量的模长伸缩尺度如何才能最大?我们有矩阵代数中的定理知,向量经矩阵映射前后的向量长度之比的最大值就是这个矩阵的最大奇异值,即:
式中,是矩阵A的最大奇异值(亦是矩阵A的二范数),它等于
![]() 的最大特征值开平方。当
的最大特征值开平方。当取最大特征值对应的特征量时等号成立。
转换成我们要求解的问题,令,则有目标函数
的最大值等于
的最大特征值,此时
等于
最大特征值对应的特征向量(第二主成分的方向为
的第二大特征值对应的特征向量的方向,以此类推)。那么k维坐标系各个坐标轴的方向向量就是前k个特征值(从大到小排序后)对应的特征向量。
小结:
,
为列向量,
为特征数
1、目标函数存在最大值,此时
最大特征值对应的特征向量;
2、求解
6 第4章节问题解答
6.1 为什么去均值(中心化)?
PCA里的中心化是按列去均值,即中心化后每一个特征下所有样本点的均值为0。
① 目标函数
是基于所有样本点的均值为0(中心化后)推导出来,因此PCA的整个求解过程是以某一特征下所有样本点的均值为0这个条件为前提。也就是说如果原始样本点没有中心化,整个求解过程是不成立的;
②的协方差矩阵能够等同的前提也是某一特征下所有样本点的均值为0(这个会在第2个问题详细介绍)。
因此,去均值(中心化)这一步,并不是独立于 PCA 的预处理步骤,而是由 PCA 求解所规定的必须步骤。
6.2 为什么要计算协方差矩阵?
从PCA的理论可知,k维坐标系的各个坐标轴的方向向量就是
实际上,当某一特征下所有样本的均值为0(中心化)时,
举例说明,假设有两个特征,则有:
中心化后列向量的均值为0,即,上式可化简为:
cov函数求协方差的时候是除以n-1,所以则有:
式中,表示样本数,
表示求协方差矩阵。由于
和
是线性关系,所以它们的最大特征值对应的特征向量是等同的。上面的证明过程也同样说明了中心化的必要性。
也可以采用如下代码来验证:
import numpy as np
x=np.array([[2.5,2.4],[0.5,0.7],[2.2,2.9],[1.9,2.2],[3.1,3. ]])#行数表示样本数,列数表示特征数
print(x)
raw=len(x) #行数
col=len(x[0]) #列数
x_new=np.zeros((raw, col))#创建全为0的数组
x_new=x-np.mean(x,axis=0)#按列去均值
x_cov_1=np.dot(x_new.T,x_new)/(raw-1)#采用(X^T)X的方式计算协方差矩阵
x_cov_2=np.cov(x_new.T) #采用cov()函数计算协方差矩阵,Python里面计算协方差是按照行向量来的
print(x_cov_1)
print(x_cov_2)6.3 为什么要计算协方差矩阵的特征值和特征向量?为什么要排序?
求解特征向量是为了获取k维坐标系的方向向量,特征向量对应的特征量大小代表了原始样本点投影以后携带的信息多少。特征量越大,携带的信息量就越多。降维就是保留携带信息多的投影方向,剔除携带信息少的投影方向,从而实现数据在降维的同时,而不失真。
6.4 主成分个数N怎么确定?
进行主成分分析的目的之一是减少变量的个数,所以一般不会选取P个主成分,而是取k(k<p)个主成分,通常情况下,主成分数量筛选依据为:
- 累积方差贡献率:当前k个主成分的累积方差贡献率达到某一特定值(一般85%以上),就可以保留前k个主成分;
- 特征值:一般选取特征值大于等于1的主成分;
- 碎石图:一般选取碎石图的曲线上由陡峭变为平稳的结点前的结点为主成分。
其中,
方差贡献率:指的是一个主成分所能够解释的方差占全部方差的比例,这个值越大,说明主成分综合原始变量的信息的能力越强。 计算公式如下:
累积方差贡献率:主成分筛选中所确定的前m个主成分所能解释的全部方差占总方差的比例称为累计方差贡献率。
碎石图:纵轴是特征值,横轴是成分个数,通过拐点来判断获取的主成分个数。
![]()
7 Python代码——PCA
import numpy as np
x=np.array([[2.5,0.5,2.2,1.9,3.1,2.3,2,1,1.5,1.1],[2.4,0.7,2.9,2.2,3.0,2.7,1.6,1.1,1.6,0.9]])
x=x.T #输入数据,样本数为10,特征数为2;行数为样本数,列数是特征数
print(x)
#-----按列中心化-----#
raw=len(x) #行数
col=len(x[0]) #列数
x_new=np.zeros((raw, col))#创建全为0的数组
x_new=x-np.mean(x,axis=0)#-----求协方差矩阵-----#
x_cov=np.cov(x_new.T) #Python里cov()函数是按照行向量来计算协方差的#-----求协方差矩阵的特征值和特征向量
feature_value,feature_vector=np.linalg.eig(x_cov) #由特征值、特征向量组成的元组,第一个元素是特征值,第二个是特征量#-----特征值由大到小排序-----#
index=np.argsort(feature_value)[::-1] #获取特征值从大到小排序前的索引
feature_value_sort=feature_value[index] #特征值由大到小排序
feature_vector_sort=feature_vector[:,index] #特征向量按照特征值的顺序排列#-----选取主成分,可以根据累积贡献率来选取-----#
for i in range(len(feature_value_sort)):if sum(feature_value_sort[0:i+1])/np.sum(feature_value_sort)>0.9: #累积贡献率大于90%的主成分k=i+1 #主成分个数break
main_component = feature_vector_sort[:,0:k] #k维向量#-----将样本点映射到k维向量上-----#
final_data=np.dot(x_new,main_component) #n维数据变成k维数据
print(final_data)参考链接:
【建模应用】PCA主成分分析原理详解 - pigcv - 博客园
一篇深入剖析PCA的好文 - 能力工场-小马哥 - 博客园
主成分分析法基本步骤(PCA) - 哔哩哔哩
8 补充说明
也可以采用拉格朗日乘子法来求最大值,思路更加清晰简单。从第5章可以知道PCA求解的问题可以描述为:
构造拉格朗日函数:
对求导有:
求解上述方程有:
从上式可以看出,为矩阵
的特征向量,
为矩阵
的特征值。此时,目标函数取极值,极值为:
于是我们发现,X投影后的方差就是协方差矩阵的特征值。最大方差也就是协方差矩阵()最大的特征值,最佳投影方向就是最大特征值所对应的特征向量,次佳就是第二大特征值对应的特征向量,以此类推。
主成分分析(PCA)原理分析Python实现相关推荐
- 偏最小二乘(PLS)原理分析Python实现
目录 1 偏最小二乘的意义 2 PLS实现步骤 3 弄懂PLS要回答的问题 4 PLS的原理分析 4.1 自变量和因变量的主成分求解原理 4.1.1 确定目标函数 4.1 ...
- python解析原理_主成分分析法原理及其python实现
主成分分析法原理及其python实现 前言: 这片文章主要参考了Andrew Ng的Machine Learning课程讲义,我进行了翻译,并配上了一个python演示demo加深理解. 本文主要介绍 ...
- 主成分分析(PCA)原理及R语言实现及分析实例
主成分分析(PCA)是一种数据降维技巧,它能将大量相关变量转化为一组很少的不相关变量,这些无关变量称为主成分.最近我们被客户要求撰写关于主成分分析(PCA)的研究报告,包括一些图形和统计输出.例如,使 ...
- 清风数学建模学习笔记——主成分分析(PCA)原理详解及案例分析
主成分分析 本文将介绍主成分分析(PCA),主成分分析是一种降维算法,它能将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间互不相关,其能反映出原始数据的大部分信息. 一般 ...
- PCA原理分析和Matlab实现方法(三)
PCA主成分分析原理分析和Matlab实现方法(三) [尊重原创,转载请注明出处]http://blog.csdn.net/guyuealian/article/details/68487833 ...
- PCA原理分析和意义(一)
原文链接:http://blog.codinglabs.org/articles/pca-tutorial.html PCA(Principal Component Analysis)是一种常用的数据 ...
- 主成分分析(PCA)原理及推导
转载请声明出处http://blog.csdn.net/zhongkejingwang/article/details/42264479 什么是PCA? 在数据挖掘或者图像处理等领域经常会用到主成分分 ...
- PCA原理分析和意义(二)
原文链接:http://blog.csdn.net/xl890727/article/details/16898315 在进行图像的特征提取的过程中,提取的特征维数太多经常会导致特征匹配时过于复杂,消 ...
- 基于特征向量的主成分分析(PCA)原理解释
引子 首先看一下如何对一维向量的进行分解,我们知道,一个 nnn 维向量 aaa 可以由 nnn 个正交向量线性 vi,i=1,2,...,nv_i,i=1,2,...,nvi,i=1,2,..., ...
最新文章
- python测试脚本 进制转换_使用Python进行新浪微博的mid和url互相转换实例(10进制和62进制互算)...
- 【数据挖掘笔记十】聚类分析:基本概念和方法
- rawquery 没扎到返回什么_当mysql_query返回false时
- Python中常用字符串 函数-转
- 微信分享自定义标题摘要和缩略图
- SSM中 出现错误 Could not open ServletContext resource [/WEB-INF/dispatcherServlet-servlet.xml]
- Pile 0009: Vim命令梳理
- 反思 大班 快乐的机器人_幼儿园大班教案《快乐的桌椅》含反思
- 用 Python 检验数据正态分布的几种方法
- Java爬取网页源代码解析
- Amoeba及其类似产品
- php想做一个无刷新弹窗,php+ajax实现无刷新的新闻留言系统
- 玩转安卓10源码开发定制(17)编译Windows平台adb和fastboot工具
- Java反射常见面试题
- 终极算法【4】——联结学派
- 大一c语言大作业实验报告,大一c语言实验报告
- 林淮川孙玄:分布式锁选型背后的架构设计思维【附源码】
- 10个英文手写字体下载
- 网站服务器ip解析,服务器 域名 解析ip
- 校园小说男主是计算机系,十大完本校园小说排行榜 经典好看的青春校园小说...