mysql集群和mongodb集群_mongodb分布式集群架构
一、关于mongodb
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当***能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
二、mongodb分布式应用原理
MongoDB集群包括一定数量的mongod(分片存储数据)、mongos(路由处理)、config server(配置节点)、clients(客户端)、arbiter(仲裁节点:为了选举某个分片存储数据节点那台为主节点)。
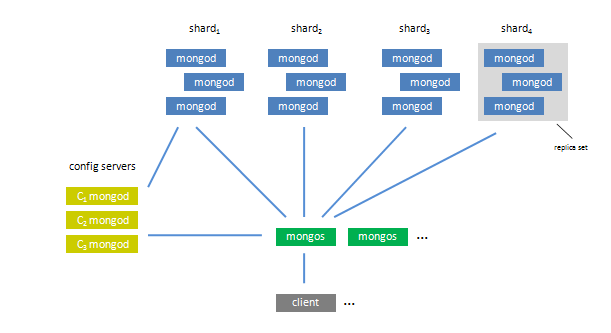
1、shards:一个shard为一组mongod,通常一组为两台,主从或互为主从,这一组mongod中的数据时相同的,具体可见《mongodb分布式之数据复制》。数据分割按有序分割方式,每个分片上的数据为某一范围的数据块,故可支持指定分片的范围查询,这同google的BigTable 类似。数据块有指定的最大容量,一旦某个数据块的容量增长到最大容量时,这个数据块会切分成为两块;当分片的数据过多时,数据块将被迁移到系统的其他分片中。另外,新的分片加入时,数据块也会迁移。
2、mongos:可以有多个,相当于一个控制中心,负责路由和协调操作,使得集群像一个整体的系统。mongos可以运行在任何一台服务器上,有些选择放在shards服务器上,也有放在client 服务器上的。mongos启动时需要从config servers上获取基本信息,然后接受client端的请求,路由到shards服务器上,然后整理返回的结果发回给client服务器。
3、config server:存储集群的信息,包括分片和块数据信息。主要存储块数据信息,每个config server上都有一份所有块数据信息的拷贝,以保证每台config server上的数据的一致性。
4、shard key:为了分割数据集,需要制定分片key的格式,类似于用于索引的key格式,通常由一个或多个字段组成以分发数据,比如:
{ name : 1 }
{ _id : 1 }
{ lastname : 1, firstname : 1 }
{ tag : 1, timestamp : -1 }
mongoDB的分片为有序存储(1为升序,-1为降序),shard key相邻的数据通常会存在同一台服务
(数据块)上。三、mongodb分布式部署方式
服务器部署可以有多种方式。首先,每台config server、mongos、mongod都可以是单独的服务器,但这样会导致某些服务器的浪费,比如config server。下图为物理机共享的集群部署,不需要额外加机器。
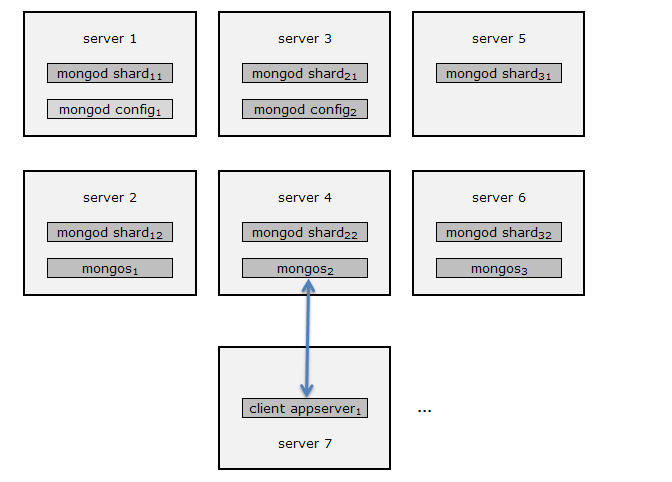
当然也有其他的方案,比如把mongos部署在所有的mongod(server1-6)上,又或者在每个运用服务器(server7)上部署mongos。这样部署有个好处在于,appserver和mongos之间的通信建立在localhost interface上,减少了通信成本。当然,此乃官方说法,但本人有想法,尽管减少了appserver和mongos之间的通信成本,但mongos与mongod之间的通信成本却增加了,而且把mongos部署在appserver上并不是很利于sa管理,mongoDB应该是一个相对独立的系统,与应用的耦合度应该尽量降到最低,万一应用想要换数据库,也能多少减少些工作量。
四、mongodb分布式的安装
1、下载wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.0.4.tgz
2、安装tar zxvf mongodb-linux-2.0.4.tgz
cp -fr mongodb-linux-*2.0.4/* /data/mongodb/
mkdir -p /data/mongodb/data/ #创建数据存储目录
mkdir -p /data/mongodb/log/ #创建日志存储目录
mkdir -p /data/mongodb/config/ #创建配置存储目录
mkdir -p /data/mongodb/arbiter/ #创建仲裁节点存储目录
3、单机模式以及个参数说明mongod --fork --bind_ip 127.0.0.1 --port 11811 --dbpath /data0/mongodb/data --directoryperdb --logpath /data0/mongodb/log/db1.log --logappend --nohttpinterface
netstat -ntlp|grep mongod
简单的参数说明:
–logpath 日志文件路径
–master 指定为主机器
–slave 指定为从机器
–source 指定主机器的IP地址
–pologSize 指定日志文件大小不超过64M.因为resync是非常操作量大且耗时,最好通过设置一个足够大的oplogSize来避免resync(默认的 oplog大小是空闲磁盘大小的5%)。
–logappend 日志文件末尾添加
–port 启用端口号
–fork 在后台运行
–only 指定只复制哪一个数据库
–slavedelay 指从复制检测的时间间隔
–auth 是否需要验证权限登录(用户名和密码)
–noauth 不需要验证权限登录(用户名和密码)
五、集群模式mongos,mongod,configsvr1.Shard分片--
第一组分片
192.168.200.226:
/data/mongodb/bin/mongod --replSet rep1 --fork --port11813--maxConns 65535 --dbpath /data/mongodb/data --directoryperdb --logpath /data/mongodb/log/db.log --logappend --nohttpinterface
#启动rep1分片的一个数据节点
/data/mongodb/bin/mongos --configdb 192.168.201.226:11812 --port 11811 --fork --chunkSize 256 --logpath /data/mongodb/log/ms.log #启动路由节点,读取201.226上的配置节点的配置文件,(在配置节点启动后启动)
/data/mongodb/bin/mongod --replSet rep1 --fork --port11814--dbpath /data/mongodb/arbiter --directoryperdb --logpath /data/mongodb/log/arbiter.log --logappend --nohttpinterface
#启动分片的仲裁节点
192.168.201.226:
/data/mongodb/bin/mongod --replSet rep1 --fork --port11813--maxConns 65535 --dbpath /data/mongodb/data --directoryperdb --logpath /data/mongodb/log/db.log --logappend --nohttpinterface
#启动rep1分片的第二个数据节点
/data/mongodb/bin/mongos --configdb 192.168.201.226:11812--port11811--fork --chunkSize 256 --logpath /data/mongodb/log/ms.log
#启动第二个路由节点 (在配置节点启动后启动)
2.ConfigServer---
#启动config server
192.168.201.226:
/data/mongodb/bin/mongod --configsvr --dbpath /data/mongodb/config --port11812--fork --logpath /data/mongodb/log/mc.log
#启动配置节点,注意配置节点应该优先启动,不然路由节点读取不到配置节点信息则会启动失败。
3.Mongos路由---
#启动mongos,指定config server, chunkSize 256M
192.168.201.226:
/data/mongodb/bin/mongos --configdb 192.168.201.226:11812--port11811--fork --chunkSize 256 --logpath /data/mongodb/log/ms.log
#启动路由节点
由于机器有限,只配置了一个shard分片,该分片里有2个节点,新增加分片只需对应改replSet 名称即可。4.配置replSet: 连接任一mongod members
mongo 192.168.201.226:11813
config= {_id: 'rep1', members: [
{_id: 0, host: '192.168.200.226:11813', priority: 2}, #priority 为定义优先级,默认为1,高优先级会被认为是主节点优先启用。
{_id: 1, host: '192.168.201.226:11813'},
{_id: 2, host: '192.168.200.226:11814', arbiterOnly: true}]
}
rs.initiate(config);
rs.status()
5.连接mongos增加shard 80G
mongo 192.168.201.226:11811/admin
show dbs
use admin
db.runCommand({addshard:'rep1/192.168.201.226:11813,192.168.200.226:11813',maxsize:81920})
db.runCommand({listshards:1})
6.连接mongos增加创建test库和c1集合,并测试
mongo 192.168.201.226:11811/admin
db.runCommand({enablesharding:'test'})
printShardingStatus()
db.runCommand({shardcollection:'test.auto_increment_id', key:{_id:1}, unique : true})
db.runCommand({shardcollection:'test.c1', key:{_id:1}, unique : true})
for (var i=1; i<= 100; i++)db.c1.save({id:i,value1:"1234567890",value2:"1234567890",value3:"1234567890",value4:"1234567890"})
db.c1.stats()
db.createCollection("cap_coll", {capped:true, size:100000, max:100});
db.mycoll.validate();
7.检查: db.printCollectionStats()
8.管理: mongo 127.0.0.1:11811
show dbs
use admin
show collections
db.serverStatus()
db.shutdownServer()
exit
9.索引:
db.product_data.ensureIndex({data_id: 1}, {unique: true,dropDups: true});#创建索引
db.product_data.dropIndexes();#删除索引
至此,mongodb的分布式架构就架起来了,并且通过测试和log的分析,可看服务是否正常,下面就需要php客户端的支持,和程序的运行,之后加到监控里,就可以在线上部署使用了。
mysql集群和mongodb集群_mongodb分布式集群架构相关推荐
- 搭建高可用的MongoDB集群:MongoDB的配置与副本集
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. NOSQL有这些优势: 大数据量,可以通过 ...
- mongodb一致性协议_mongodb副本集用一致性快照方法添加从节点步骤
环境描述 主节点 192.168.0.1:27002 两个从节点 192.168.0.2:27002 192.168.0.3:27002 目标:用一致性快照方式添加第三个从节点192.168.0.3 ...
- ClickHouse数据库培训实战 (PB级大数据分析平台、大规模分布式集群架构)
一.ClickHouse数据库培训实战课程 (PB级大数据分析平台.大规模分布式集群架构)视频教程 为满足想学习和掌握ClickHouse大数据分析专用的数据库,风哥特别设计的一套比较系统的Click ...
- java集群_Kafka多节点分布式集群搭建实现过程详解_java
上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法.多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建. 一.安装Jdk 具体安 ...
- hbase完整分布式集群搭建
简介: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop2.8 ha 集群搭建 hbase完整分布式集群搭建 hadoop完整集群遇到问题汇总 Hb ...
- Hadoop伪分布式集群的安装部署
Hadoop伪分布式集群的安装部署Hadoop伪分布式集群的安装部署 首先可以为Linux虚拟机搭建起来的最初状态做一个快照,方便后期搭建分布式集群时多台Linux虚拟机的准备. 一.如何为虚拟机做快 ...
- 生产环境实战spark (5)分布式集群 5台设备之间hosts文件配置 ssh免密码登录
生产环境实战spark (5)分布式集群 5台设备之间 ssh免密码登录 之前已经在master节点单台设备上配置ssh免密码的登录工作,现在要做的事情是在5台设备之间实现ssh免密码操作.我在整个大 ...
- 大数据开发技术课程报告(搭建Hadoop完全分布式集群操作集群)
文章目录 大数据开发技术课程报告内容及要求 一. 项目简介和实验环境 二. 虚拟机的各项准备工作 三. 安装JDK并配置环境变量 四. 安装Hadoop并配置环境变量 五. 配置Hadoop完全分布式 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.1)
原文地址:https://www.cnblogs.com/zhengna/p/9316424.html Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本 2 ...
最新文章
- C/C++数组名与指针区别深入探索
- 路由表及路由的选择算法
- css 元素类型 行内元素 块元素 内联块元素 0302
- chrome里面的一些小技巧
- 做一个有趣的有意思的人
- 浅谈oracle中for update 和 for update nowait 和 for update wait x的区别
- 计算机基础知识_计算机基础知识汇总
- java都要caps标点_Java Button.setAllCaps方法代码示例
- 分布式搜索引擎ElasticSearch(四) -- 插件使用
- python中如何创建一个空列表_Python创建空列表的字典2种方法详解
- 怎么把外部参照合并到图纸_怎么对两个图纸内容进行合并操作
- 《linux核心应用命令速查》连载十五:fuser:用文件或者套接口表示进程
- 姜启源《数学模型》笔记
- epoll的LT模式(水平触发)和ET模式(边沿触发)
- 航旅纵横被质疑泄露用户数据;杭州网警破获67万台电脑数据遭黑客偷窃案;简历倒卖黑产:低至3毛一条,700元买采集器可无限量导数据...
- 涉密计算机杀毒记录表,保密工作自检自查记录表
- 使用Docker安装MySQL
- 计算机网络学习笔记(3.数据链路层 4.网络层)
- 东方国信携手Cloudera 共创Hadoop生态圈辉煌
- HTML+CSS 登录界面设计