递归神经网络/_递归神经网络
递归神经网络/
深度学习 , 自然语言处理 (Deep Learning, Natural Language Processing)
You asked Siri about the weather today, and it brilliantly resolved your queries.
您向Siri查询了今天的天气,它很好地解决了您的问题。
But, how did it happen? How it converted your speech to the text and fed it to the search engine?
但是,它是怎么发生的呢? 它如何将您的语音转换为文本并将其反馈给搜索引擎?
This is the magic of Recurrent Neural Networks.
这是递归神经网络的魔力。
Recurrent Neural Networks(RNN) lies under the umbrella of Deep Learning. They are utilized in operations involving Natural Language Processing. Nowadays since the range of AI is expanding enormously, we can easily locate Recurrent operations going around us. These play an important role ranging from Speech Translation, Music Composition to predicting the next word in your mobile’s keyboard.
递归神经网络(RNN)位于 深度学习 。 它们用于涉及自然语言处理的操作。 如今,由于AI的范围正在极大地扩展,我们可以轻松地找到我们周围的经常性运营。 这些功能起着重要作用,从语音翻译,音乐创作到预测手机键盘中的下一个单词。
The types of problems that RNN caters to are:
RNN迎合的问题类型为:
- Outputs are dependent on previous inputs. (Sequential Data)输出取决于先前的输入。 (顺序数据)
- The length of the input isn’t fixed.输入的长度不固定。
顺序数据 (Sequential Data)
To understand Sequential data, let us suppose you have a dog standing still.
为了了解顺序数据,让我们假设您有一条狗停滞不前。
Now, you’re supposed to predict in which direction will he move? So with only this limited information imparted to you, how would you do this? Well, you can irrefutably take a guess, but in my opinion, what you’d come up would be a random guess. Without knowledge of where the dog has been, you wouldn’t have enough data to predict where he’ll be going.
现在,您应该预测他将朝哪个方向移动? 因此,仅将有限的信息提供给您,您将如何做? 好吧,您可以毫无疑问地进行猜测,但是在我看来,您要提出的只是一个随机的猜测。 如果不知道那只狗去了哪里,您将没有足够的数据来预测他要去哪里。
But, now if the dog starts running in a particular direction and if you try to record the movements of dogs, you’ll be pretty sure the directions he’ll be choosing. Because at this instant you’ve enough information to make a better prediction.
但是,现在,如果狗开始沿特定方向运行,并且如果您尝试记录狗的运动,则可以肯定他会选择的方向。 因为这时您有足够的信息来做出更好的预测。
So a sequence is a particular order in which one thing follows another. With this information, you can now see that the dog is moving towards you.
因此,序列是一个事物跟随另一事物的特定顺序。 有了这些信息,您现在可以看到狗正在向您移动。
Text, Audio are also illustrations of sequence data.
文本,音频也是序列数据的图示。
When you’re talking to someone, there is a sequence of the words you utter. Similarly, when you e-mail someone, based on your texts, there is some certainty about what your next words would be.
当您与某人交谈时,您会说出一系列单词。 同样,当您根据文本向某人发送电子邮件时,可以确定下一个单词的含义。
顺序记忆 (Sequential Memory)
As mentioned earlier, RNNs cater to the problems that involve inter-dependency between outputs and previous inputs. That indirectly means, there is some memory affiliated to these kinds of Neural Networks.
如前所述,RNN解决了涉及产出与先前投入之间相互依存的问题。 这间接意味着,有些记忆与这些神经网络有关。
Sequential memory is something that helps RNN achieve its goal.
顺序存储可以帮助RNN实现其目标。
As to better understand, I would ask you to recall the alphabet in your head.
为了更好地理解,我想请您记住您脑海中的字母。
That was an easy task, if you were taught this specific sequence, it should come quickly to you.
这是一项容易的任务,如果您被教导了这个特定的顺序,那么它应该很快就会出现。
Now, if I ask you to recall alphabets in a reverse manner.
现在,如果我要您以相反的方式回忆字母。

I bet this task is much solid. And in my opinion, it will give you a hard time.
我敢打赌,这项任务非常可靠。 我认为,这会给您带来困难。
So, the reason the former task proved to be resilient because you’ve learned the alphabets as a sequence. Sequential memory makes it easier for your brain to recognize patterns.
因此,前一个任务被证明具有弹性的原因是因为您已经按顺序学习了字母。 顺序记忆使您的大脑更容易识别模式。
递归神经网络与神经网络有何不同? (How Recurrent Neural Networks differ from Neural Networks?)
As discussed earlier, Recurrent Neural Network comes under Deep Learning but so does Neural Networks. But due to the absence of an internal state, Artificial Neural Networks are not something that we use to process our sequential data.
如前所述,递归神经网络属于深度学习,但神经网络也属于深度学习。 但是由于缺少内部状态,因此人工神经网络不是我们用来处理序列数据的东西。

To develop a Neural Network that is robust for Sequential data, we add an internal state to our feedforward neural network that provides us with internal memory. Or in nutshell, Recurrent Neural Network is a generalization of a feedforward neural network that has internal memory. RNN implements the abstract concept of sequential memory, that helps them by providing the previous experience and thus allowing it to predict better on sequential data.
为了开发对顺序数据具有鲁棒性的神经网络,我们将内部状态添加到前馈神经网络中,从而为我们提供内部记忆。 简而言之,递归神经网络是具有内部记忆的前馈神经网络的概括。 RNN实现了顺序存储器的抽象概念 ,它通过提供以前的经验,从而使他们能够更好地预测顺序数据,可以帮助他们。
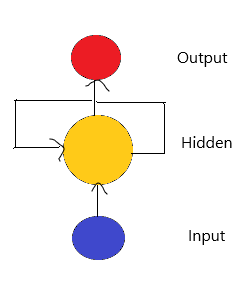
RNN proves it recurrent nature by performing the same function for every input, while the output of current input depends upon the past input. Comparing it to Feedforward Neural Network, in RNN, all the inputs are inter-dependent on each other unlike that in vanilla form.
RNN通过对每个输入执行相同的功能来证明其递归性质,而当前输入的输出取决于过去的输入。 与RNN中的前馈神经网络相比,所有输入都是相互依赖的,这与原始形式不同。
RNN的工作 (Working of RNN)
Okay, but how does RNN replicate those internal memories and actually work?
好的,但是RNN如何复制这些内部记忆并真正起作用?
Suppose, a user asked, “What is your name?”
假设一个用户问:“ 你叫什么名字? ”
Since RNN solely depends upon sequential memory, we expect our model to break up the sentence into individual words.
由于RNN仅取决于顺序记忆,因此我们希望我们的模型将句子分解为单个单词。

At first, “What” is fed into RNN. Our model then encodes it and presents us with an output.
首先,“ What”被输入到RNN中。 然后,我们的模型对其进行编码,并为我们提供输出。
For the next part, we feed the word “is” and the former output that we got from the word “What”. RNN has now access to the information imparted by both words: “What” and “is”.
在下一部分中,我们将输入“ is”和从“ What”中获得的前一个输出。 RNN现在可以访问由“什么”和“是”这两个词提供的信息。
The same process will be iterated until we reach the end of our sequence. And In the end, we can expect RNN had encoded information from all the words present in our sequence.
重复相同的过程,直到我们到达序列的末尾。 最后,我们可以期望RNN从序列中存在的所有单词中编码信息。
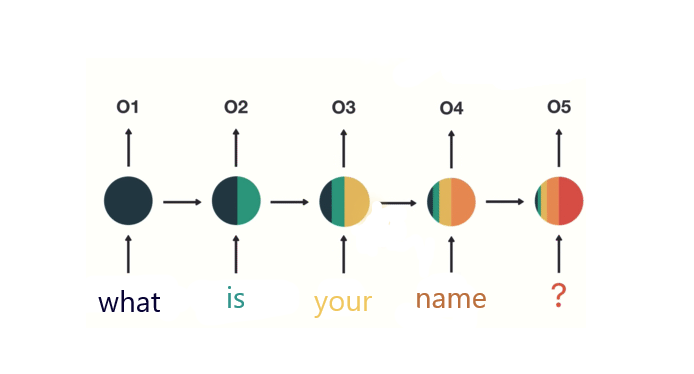
Since the last output is developed by combining the former outputs and the last input, we can pass the final output to the feedforward layer to achieve our goal.
由于最后一个输出是通过合并前一个输出和最后一个输入来开发的,因此我们可以将最终输出传递到前馈层以实现我们的目标。
To create the context, let us resemble input by x; output by y; and state vector by a.
为了创建上下文,让我们类似于x的输入 ; 由y输出 ; 和状态向量。

When we pass our first input i.e. x0 (“What”), we are provided with the output y1 and a state vector a1, that is passed to next function s1 to accommodate the past output of x0.
当我们传递第一个输入x0(“ What”)时,我们将得到输出y1和状态向量a1,状态向量a1传递给下一个函数s1以容纳x0的过去输出。
The process iterates until we reach at the end of our sequence. At the end we are left with state vector a5 that assures us that all inputs <x1, x2, x3, x4, x5> have been fed to our model and an output is generated that is contributed by all outputs.
该过程将反复进行,直到到达序列末尾。 最后,我们留给状态向量a5,以确保我们所有输入<x1,x2,x3,x4,x5>都已馈送到我们的模型中,并生成由所有输出贡献的输出。


RNN的伪代码 (Pseudocode for RNN)
RNN架构的类型 (Types of RNN architectures)
One to One
一对一

One to Many — These kinds of RNN architectures are usually used for Image captioning/story captioning.
一对多 -这些RNN体系结构通常用于图像字幕/故事字幕。

Many to One — These kinds of RNN architectures are used for Sentiment Analysis.
多对一 -这些RNN架构用于情感分析。

Many to Many — These types of RNN architectures are utilized in Part of Speech i.e. where we are expected to find property for each word.
多对多 -语音部分使用了这些类型的RNN体系结构,即我们希望在其中找到每个单词的属性。

Encoder-Decoder — These types of RNN are the most complex ones and are used for Language Translation.
编码器-解码器 -这些类型的RNN是最复杂的类型,用于语言翻译。
RNN的缺点 (Drawbacks of RNN)
短期记忆 (Short-term Memory)
I hope you’ve pondered upon the odd color distribution in our final RNN cell.
希望您在我们的最终RNN单元中考虑了奇怪的颜色分布。

This is an interpretation of Short-term memory. In RNN, at each new timestamp(new input) old information gets morphed by the current input. One could imagine, that after “t” timestamps, the information stored at the time step (t-k) gets completely morphed.
这是短期记忆的一种解释。 在RNN中,在每个新时间戳记(新输入)处,旧信息都会被当前输入变形。 可以想象,在“ t ”个时间戳之后,在时间步长(tk)中存储的信息会完全变形。
And thus, RNNs can’t be used for very long sequences.
因此,RNN不能用于很长的序列。
消失梯度 (Vanishing Gradient)
This is the reason for Short-term memory. Vanishing Gradient is present in every type of Neural Network due to the nature of Backpropagation.
这就是短期记忆的原因。 由于反向传播的性质,每种神经网络都存在消失梯度。
When we train a Neural Network there are three major steps associated with our training. First, a forward pass is done to make a prediction. Later, it compares the prediction to theoretical value producing a loss function. Lastly, we aim to make our prediction better, therefore, we implement Backpropagation that revises values for each node.
当我们训练神经网络时,与训练相关的三个主要步骤。 首先,进行前向通过以进行预测。 随后,它将预测结果与产生损失函数的理论值进行比较。 最后,我们旨在改善我们的预测,因此,我们实施了反向传播,以修改每个节点的值。

“After calculation of loss function, we’re pretty sure that our model is doing something wrong and we need to inspect that, but, it is practically impossible to check for each neuron. But, also the only way possible for us to salvage our model is to retrograde.
“计算完损失函数后,我们很确定我们的模型做错了,我们需要检查它,但是,实际上不可能检查每个神经元。 但是,挽救我们模型的唯一可能方法就是逆行。
Steps for Backpropagation
反向传播的步骤
- We compute certain losses at the output and we will try to figure out which node was responsible for that inefficiency.我们在输出端计算一定的损耗,然后尝试找出哪个节点造成了这种低效率。
- To do so, we will backtrack the whole network.为此,我们将回溯整个网络。
- Suppose, we found that the second layer(w3h2+b2) is responsible for our loss, and we will try to change it. But if we ponder upon our network, w3 and b2 are independent entities but h2 depends upon w2, b1 & h1 and h1 further depends upon our input i.e. x1, x2, x3…., xn. But since we don’t have control over inputs we will try to amend w1 & b1.假设我们发现第二层(w3h2 + b2)是造成我们损失的原因,我们将尝试对其进行更改。 但是如果我们考虑网络,w3和b2是独立实体,但是h2取决于w2,b1&h1和h1进一步取决于我们的输入,即x1,x2,x3…。,xn。 但由于我们无法控制输入,因此我们将尝试修改w1和b1。
To compute our changes we will use the chain rule.”
为了计算更改,我们将使用链式规则。”

When we perform backpropagation, we calculate weights and biases for each node. But, if the improvements in the former layers are meager then the adjustment to the current layer will be much smaller. This causes gradients to dramatically diminish and thus leading to almost NULL changes in our model and due to that our model is no longer learning and no longer improving.
当我们执行反向传播时,我们为每个节点计算权重和偏差。 但是,如果前几层的改进很少,那么对当前层的调整将小得多。 这将导致梯度急剧减小,从而导致模型中的变化几乎为NULL,并且由于我们的模型不再学习并且不再改进。
LSTM和GRU (LSTMs and GRUs)
To combat the drawbacks of RNNs, we have LSTM(Long Short Term Memory) and GRU(Gated Recurrent Unit). LSTMs and GRUs are basically advanced versions of RNNs with little tweaks to overcome the problem of Vanishing Gradients and learning long-term dependencies using components known as “Gates”. Gates are a tensor operation that can learn the flow of information and thus short-term memory isn’t an issue for them.
为了克服RNN的缺点,我们提供了LSTM ( 长期短期记忆 )和GRU ( 门控循环单元 )。 LSTM和GRU基本上是RNN的高级版本,几乎不需要进行任何调整即可克服消失梯度的问题,并使用称为“门”的组件学习长期依赖关系。 Gates是一个张量运算,可以了解信息流,因此短期存储对他们而言不是问题。
During Forward propagation, the gates control flow of information. Thus, preventing any irrelevant information from being written to states.
在正向传播过程中 ,门控制信息流。 因此,防止了任何不相关的信息被写入状态。
During Backpropagation, the gates control the flow of gradient, and these gates are capable of multiplying the gradients to avoid vanishing gradient.
在反向传播期间,门控制梯度的流动,并且这些门能够使梯度相乘以避免梯度消失。
To learn more about LSTM and GRUs, you can check out:
要了解有关LSTM和GRU的更多信息,可以查看以下内容:
LSTM doesn’t solve problem of Exploding Gradients, therefore, we tend to use Gradient Clipping while implementing LSTMs.
LSTM不能解决爆炸梯度的问题,因此,在实现LSTM时,我们倾向于使用梯度剪切。
结论 (Conclusion)
Hopefully, this article will help you to understand about Recurrent Neural Network in the best possible way and also assist you to its practical usage.
希望本文能以最佳方式帮助您了解递归神经网络,并帮助您实际使用它。
As always, thank you so much for reading, and please share this article if you found it useful!
与往常一样,非常感谢您的阅读,如果您觉得有用,请分享这篇文章!
Feel free to connect:
随时连接:
LinkedIn ~ https://www.linkedin.com/in/dakshtrehan/
领英〜https: //www.linkedin.com/in/dakshtrehan/
Instagram ~ https://www.instagram.com/_daksh_trehan_/
Instagram〜https: //www.instagram.com/_daksh_trehan_/
Github ~ https://github.com/dakshtrehan
Github〜https: //github.com/dakshtrehan
Follow for further Machine Learning/ Deep Learning blogs.
请关注进一步的机器学习/深度学习博客。
Medium ~ https://medium.com/@dakshtrehan
中〜https ://medium.com/@dakshtrehan
想了解更多? (Want to learn more?)
Detecting COVID-19 Using Deep Learning
使用深度学习检测COVID-19
The Inescapable AI Algorithm: TikTok
不可避免的AI算法:TikTok
An insider’s guide to Cartoonization using Machine Learning
使用机器学习进行卡通化的内部指南
Why are YOU responsible for George Floyd’s Murder and Delhi Communal Riots?
您为什么要为乔治·弗洛伊德(George Floyd)的谋杀和德里公社暴动负责?
Convolution Neural Network for Dummies
卷积神经网络
Diving Deep into Deep Learning
深入学习
Why Choose Random Forest and Not Decision Trees
为什么选择随机森林而不是决策树
Clustering: What it is? When to use it?
聚类:是什么? 什么时候使用?
Start off your ML Journey with k-Nearest Neighbors
通过k最近邻居开始您的ML旅程
Naive Bayes Explained
朴素贝叶斯解释
Activation Functions Explained
激活功能介绍
Parameter Optimization Explained
参数优化说明
Gradient Descent Explained
梯度下降解释
Logistic Regression Explained
逻辑回归解释
Linear Regression Explained
线性回归解释
Determining Perfect Fit for your ML Model
确定最适合您的ML模型
Cheers!
干杯!
翻译自: https://medium.com/towards-artificial-intelligence/recurrent-neural-networks-for-dummies-8d2c4c725fbe
递归神经网络/
http://www.taodudu.cc/news/show-1873897.html
相关文章:
- Kardashev量表和AI:可能的床友
- 变异数分析_人工智能系统中分析变异的祸害
- ai时代大学生的机遇和挑战_评估AI对美术的影响:威胁或机遇
- 人工智能+智能运维解决方案_人工智能驱动的解决方案可以提升您的项目管理水平
- c语言 机器语言 汇编语言_多语言机器人新闻记者
- BrainOS —最像大脑的AI
- 赵本山 政治敏锐_每天5分钟保持敏锐的7种方法
- 面试问到处理过什么棘手问题_为什么调节人工智能如此棘手?
- python svm向量_支持向量机(SVM)及其Python实现
- 游戏世界观构建_我们如何构建技术落后的世界
- 信任的机器_您应该信任机器人吗?
- ai第二次热潮:思维的转变_基于属性的建议:科技创业公司如何使用AI来转变在线评论和建议
- 建立RoBERTa模型以发现Reddit小组的情绪
- 谷歌浏览器老是出现花_Google全新的AI平台值得您花时间吗?
- nlp gpt论文_开放AI革命性的新NLP模型GPT-3
- 语音匹配_什么是语音匹配?
- 传统量化与ai量化对比_量化AI偏差的风险
- ai策略机器人研究a50_跟上AI研究的策略
- ai人工智能 工业运用_人工智能在老年人健康中的应用
- 人工智能民主化无关紧要,数据孤岛以及如何建立一家AI公司
- 心公正白壁无瑕什么意思?_人工智能可以编写无瑕的代码后,编码会变得无用吗?
- 人工智能+社交 csdn_关于AI和社交媒体虚假信息,我们需要尽快进行三大讨论
- 标记偏见_人工智能的影响,偏见和可持续性
- gpt2 代码自动补全_如果您认为GPT-3使编码器过时,则您可能不编写代码
- 机器学习 深度学习 ai_什么是AI? 从机器学习到决策自动化
- 艺术与机器人
- 中国ai人工智能发展太快_中国的AI:开放采购和幕后玩家
- 让我们手动计算:深入研究Logistic回归
- vcenter接管_人工智能接管广告创意
- 人工智能ai算法_当AI算法脱轨时
递归神经网络/_递归神经网络相关推荐
- 卷积网络和卷积神经网络_卷积神经网络的眼病识别
卷积网络和卷积神经网络 关于这个项目 (About this project) This project is part of the Algorithms for Massive Data cour ...
- rnn 递归神经网络_递归神经网络rnn的简单解释
rnn 递归神经网络 Recurrent neural network is a type of neural network used to deal specifically with seque ...
- 模型 标签数据 神经网络_大型神经网络和小数据的模型选择
模型 标签数据 神经网络 The title statement is certainly a bold claim, and I suspect many of you are shaking yo ...
- 递归函数非递归化_递归神秘化
递归函数非递归化 by Sachin Malhotra 由Sachin Malhotra 递归神秘化 (Recursion Demystified) In order to understand re ...
- 递归 尾递归_递归,递归,递归
递归 尾递归 by Michael Olorunnisola 通过Michael Olorunnisola 递归,递归,递归 (Recursion, Recursion, Recursion) Bef ...
- 人工神经网络_人工神经网络实践
人工神经网络(Artificial Neural Network,ANN) 使一种受人脑生物神经网络信息处理方式启发而诞生的一种计算模型,得益于语音识别.计算机视觉和文本处理方面的许多突破性成果,人工 ...
- java 递归 尾递归_递归和尾递归
C允许一个函数调用其本身,这种调用过程被称作递归(recursion). 最简单的递归形式是把递归调用语句放在函数结尾即恰在return语句之前.这种形式被称作尾递归或者结尾递归,因为递归调用出现在函 ...
- 卷积云神经网络_卷积神经网络简介
广告 一.卷积 我们在 2 维上说话.有两个 的函数 f(x, y) 和 g(x, y) .所谓 f 和 g 的卷积就是一个新的 的函数 c(x, y) .通过下式得到: 这式子的含义是:遍览从负无穷 ...
- cnn卷积神经网络_卷积神经网络(CNN)原理及应用
一.CNN原理 卷积神经网络(CNN)主要是用于图像识别领域,它指的是一类网络,而不是某一种,其包含很多不同种结构的网络.不同的网络结构通常表现会不一样.从CNN的一些典型结构中,可以看到这些网络创造 ...
- java 递归 时间复杂度_递归到底是怎么实现的?它的时间复杂度怎么算?
递归到底是个啥? 常听见的一句话就是:自己调用自己. 按照这个说法,写个简单的递归自己推导一下的确可以,但是总是有点绕,推着推着自己把自己陷进去了. 递归函数运行时,实际上会进行一个压栈(思考栈的特点 ...
最新文章
- python 四种逐行读取文件内容的方法
- 如何正确解码用户的“玄学需求”?
- 请实现一个函数,将字符串中的空格替换成“%20”
- 代码管理 防止员工_低代码开发现形记
- Java中JSON字符串与java对象的互换实例详解
- Oracle 服务器 进程中的 LOCAL=NO 和 LOCAL=YES
- MongoDB最佳实践(转)
- 武忠祥.高等数学.基础课-第一章函数 极限 连续P10
- 2021年下半年网络工程师下午真题及答案解析
- 【Scala】Scala中常见集合的使用---代码详解
- 4、Hive数据仓库——加载数据
- IE 0day,2010传说中的攻击Google等公司的代码
- Python Turtle绘图基础(一)——Turtle简介、绘图窗体与绘图区域
- win7记事本如何转换html,记事本格式_win7记事本怎么改格式
- 步进电机驱动之相数、步距角、细分、拍数
- 使用C语言判断一个机器是大端机还是小端机
- kermit的安装、配置、使用 .
- 年节约10亿美元 微软宣布裁员
- 山寨王被山寨 腾讯九城恶性竞争害产业
- Java项目:ssh酒店管理系统
热门文章
- 关于回车自动跳转的问题,能不能有选择的跳转??
- 面向对象设计 腾讯代码案例 学习人家的模式和格式
- latex编译错误尝试生产pdf
- 190412每日一句
- Atitit 深入理解耦合Coupling的原理与attilax总结 目录 1.1. 耦合作为名词在通信工程、软件工程、机械工程等工程中都有相关名词术语。 2 1.2. 所有的耦合形式可分为5类:
- Atitit 项目成本之道 attilax著 1.1. 循环使用 效果明显 降低50%费用 1 1.2. Diy战略(效果显著)缩短供应链 自己组合使用,效率更高 2 1.3. 扎堆战略 使用广泛
- Atitit 减少财政支出之减少通讯支出 解决方案attilax总结
- paip.提升用户体验---搜索功能设计
- 西贝凭什么一年做到50多亿?| 独创的合伙人制:创业分部+赛场制
- (转)向浑水(Muddy Waters Research)学习如何调查公司