逻辑回归分析与回归分析_逻辑回归从零开始的情感分析
逻辑回归分析与回归分析
Years ago, it was impossible for machines to make text translation, text summarization, speech recognition, etc. An application of question answering system or chatbot would be like magic and hard to implement before the rise of what we call machine learning and especially natural language processing (NLP) which considered as a subfield of machine learning that deals with language and aims to push machines to understand and interpret languages in a human level of understanding. One of the hottest applications of NLP is sentiment analysis that allows us to classify a text, tweet or comment either positive, neutral or negative. For example, to evaluate people’s satisfaction about a specific product, we apply sentiment analysis on reviews and calculate the percent of positive and negative reviews.
几年前,机器不可能进行文本翻译,文本摘要,语音识别等。在我们所谓的机器学习(尤其是自然语言)兴起之前,问题解答系统或聊天机器人的应用就像魔术般难以实现。处理(NLP),它被视为机器学习的一个子领域,该领域涉及语言,旨在推动机器以人类的理解水平理解和解释语言。 NLP最热门的应用之一是情感分析,它使我们能够对文本,推文或评论进行分类,包括正面,中立或负面。 例如,要评估人们对特定产品的满意度,我们将情感分析应用于评论,并计算正面和负面评论的百分比。
In this tutorial we’d do something like that building a sentiment classifier from scratch based on logistic regression, and we’ll train it on a corpus of tweets, thus we’ll cover :
在本教程中,我们将做类似基于逻辑回归从头开始构建情绪分类器的操作,并且我们将在一系列推文上对其进行训练,因此我们将介绍:
Text processing
文字处理
Features extraction
特征提取
Sentiment classifier
情感分类器
Training & evaluating the sentiment classifier
训练和评估情感分类器
文字处理 (Text processing)
First, we’ll use Natural Language Toolkit (NLTK), it’s an open source python library, it has a bunch of functions to process textual data, it contains also a Twitter dataset that we’ll work on :
首先,我们将使用自然语言工具包(NLTK),这是一个开放源代码的python库,它具有许多处理文本数据的功能,并且还包含一个我们要处理的Twitter数据集:
import nltkfrom nltk.corpus import twitter_samplespositive_tweets =twitter_samples.strings('positive_tweets.json')negative_tweets =twitter_samples.strings('negative_tweets.json')example_postive_tweet=positive_tweets[0]example_negative_tweet=negative_tweets[0]test_pos = positive_tweets[4000:]train_pos = positive_tweets[:4000]test_neg = negative_tweets[4000:]train_neg = negative_tweets[:4000]train_x = train_pos + train_neg test_x = test_pos + test_negtrain_y = np.append(np.ones((len(train_pos), 1)), np.zeros((len(train_neg), 1)), axis=0)test_y = np.append(np.ones((len(test_pos), 1)), np.zeros((len(test_neg), 1)), axis=0)The python code above allow us to get a list of positive tweets and a list of negative tweets. We’ve divided our dataset into train_x, test_x, train_y, test_y, 20% for test and 80% for training. Those tweets contain a lot of irrelevant information like hashtags, mentions, stop words, etc. Data cleaning or data preprocessing is a key step in the process of data science in order to prepare data for training a classification algorithm. In the context of NLP, text processing includes :
上面的python代码使我们可以获得正向推文的列表和负向推文的列表。 我们将数据集分为train_x,test_x,train_y,test_y,其中20%用于测试,80%用于训练。 这些推文包含许多不相关的信息,例如主题标签,提及,停用词等。数据清理或数据预处理是数据科学过程中的关键步骤,以便为训练分类算法准备数据。 在NLP中,文本处理包括:
Tokenization : is the operation of splitting a sentence into a list of words.
记号化:是将一个句子分成单词列表的操作。
Removing stop words : stop words refer to the frequent words occurring in a text without adding a semantic value to the text.
删除停用词:停用词指的是文本中出现的常见词,而没有在文本中添加语义值。
Removing punctuation : it refers to the marks like (!”#$%&’()*+,-./:;<=>?@[\]^_`{|}~).
删除标点符号:指的是(!“#$%&'()* +,-。/ :; <=>?@ [\] ^ _`{|}〜)之类的标记。
Stemming : is the process of reducing a word to its word stem that affixes to suffixes and prefixes or to the roots of words.
词干:是将单词还原为单词词干的过程,单词词干附有后缀,前缀或单词的词根。
We’ll try to implement those operations in one python function to process all the tweets before feeding them into our classifier :
我们将尝试在一个python函数中实现这些操作,以便在将所有tweet馈入分类器之前对其进行处理:
import re import stringfrom nltk.corpus import stopwords from nltk.stem import PorterStemmer from nltk.tokenize import TweetTokenizerdef text_process(tweet): tweet = re.sub(r'^RT[\s]+', '', tweet) tweet = re.sub(r'https?:\/\/.*[\r\n]*', '', tweet) tweet = re.sub(r'#', '', tweet) tokenizer = TweetTokenizer() tweet_tokenized = tokenizer.tokenize(tweet) stopwords_english = stopwords.words('english') tweet_processsed=[word for word in tweet_tokenized if word not in stopwords_english and word not in string.punctuation] stemmer = PorterStemmer() tweet_after_stem=[] for word in tweet_processsed: word=stemmer.stem(word) tweet_after_stem.append(word) return tweet_after_stem特征提取 (Features extraction)
After text processing, it's time for feature extraction. Actually, computers don’t deal with texts, computers only understand the language of numbers, that’s why we should work on transforming tweets into vectors that can be fed into our logistic regression function. It exists a lot of methods to represent texts into vectors, each technique depends on the context of the problem we are trying to solve. In our case, we are working on binary classification which means classifying a tweet either positive or negative. So basically, we’d find some words more occurring in the list of positive tweets like happy, good. In the same way, we'd find some words more frequent than the others in the list of negative tweets.
经过文本处理后,就该提取特征了。 实际上,计算机不处理文本,计算机只理解数字语言,这就是为什么我们应该致力于将推文转换为向量,然后再将其输入到逻辑回归函数中。 它存在许多将文本表示为矢量的方法,每种技术都取决于我们要解决的问题的上下文。 在我们的案例中,我们正在努力进行二进制分类,这意味着对推文进行正面或负面分类。 因此,基本上,我们会在正面推文列表中找到更多诸如快乐,善意之类的词。 同样,在负面推文列表中,我们发现某些单词比其他单词更频繁。

Like the figure shows, for each word, we count how much the word has occurred in the positive tweets and how much has occurred in the negative tweets. So, in order to represent that, we’ll build a dictionary to store as a key the word with its class positive or negative class and how much has occurred in each class as value. For example, if the word “happy” has occurred 12 times in the list of positive tweets and 5 times in the list of negative tweets, we'd have something like that :
如图所示,对于每个单词,我们计算单词在正向推文中出现了多少,在负向推文中出现了多少。 因此,为了表示这一点,我们将构建一个字典来存储具有正类或负类以及每个类中作为值发生了多少的单词作为关键字。 例如,如果“高兴”一词在正面推文列表中出现了12次,在负面推文列表中出现了5次,那么我们将得到以下内容:
dict={("happy",1):12,("happy",0):5}So, in order to implement this, we’ll build the first dictionary containing the frequency of the words in the positive tweets, and the second dictionary will contain the frequency of the words in the negative tweets. Then, well combine the two dictionaries.
因此,为了实现此目的,我们将构建第一个字典,其中包含正向推文中单词的频率,第二个字典将包含负向推文中单词的频率。 然后,将两个字典很好地结合起来。
pos_words=[]for tweet in all_positive_tweets: tweet=process_tweet(tweet)
for word in tweet:
pos_words.append(word)freq_pos={}for word in pos_words: if (word,1) not in freq_pos: freq_pos[(word,1)]=1 else: freq_pos[(word,1)]=freq_pos[(word,1)]+1neg_words=[]for tweet in negative_tweets: tweet=text_process(tweet)
for word in tweet:
neg_words.append(word)freq_neg={}for word in neg_words: if (word,0) not in freq_neg: freq_neg[(word,0)]=1 else: freq_neg[(word,0)]=freq_neg[(word,0)]+1freqs_dict = dict(freq_pos)freqs_dict.update(freq_neg)back to feature extraction, now after building this dictionary, we'd convert each tweet to a vector of 3 dimensions as below :
回到特征提取,现在在构建此字典之后,我们将每个推文转换为3维向量,如下所示:

Each vector is a representation of a tweet. Now, we need to combine those vector in one matrix holding all tweet’s features. As we have 10000 tweets, and each tweet is represented as vector of 3 dimensions, the shape of our matrix X would be (10000,3) :
每个向量都代表一条推文。 现在,我们需要将这些矢量合并到一个具有所有tweet功能的矩阵中。 因为我们有10000条推文,并且每条推文都表示为3维向量,所以矩阵X的形状为(10000,3):
import numpy as npdef features_extraction(tweet, freqs_dict): word_l = text_process(tweet) x = np.zeros((1, 3)) x[0,0] = 1 for word in word_l: try: x[0,1] += freqs_dict[(word,1)] except: x[0,1] += 0 try: x[0,2] += freqs_dict[(word,0.0)] except: x[0,2] += 0 assert(x.shape == (1, 3)) return xX = np.zeros((len(train_x), 3))
for i in range(len(train_x)):
X[i, :]= features_extraction(train_x[i], freqs)情感分类器 (Sentiment classifier)
To build the sentiment classifier, and instead of using libraries like scikit-learn, we are going to build a logistic regression classifier from scratch :
要构建情感分类器,而不是像scikit-learn这样的库,我们将从头开始构建一个逻辑回归分类器:
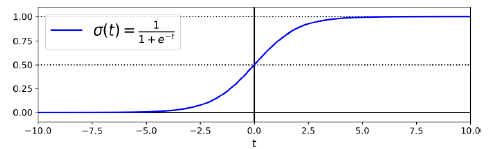
The logistic or sigmoid function uses the features as input to calculate the probability of a tweet being labeled as positive, if the output is greater or equal 0.5, we classify the tweet as positive. Otherwise, we classify it as negative.
logistic或sigmoid函数使用这些功能作为输入来计算将tweet标记为正的概率,如果输出大于或等于0.5,则将tweet分类为正。 否则,我们将其分类为否定。
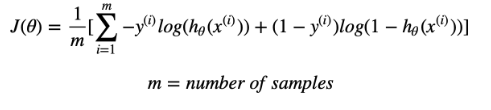
So the idea behind classification using logistic regression is minimizing the cost function which is representation for the relation between the real output and the output predicted using sigmoid function. We’ll work on updating the weights using gradient descent algorithm till we get a minimized cost function, thus getting the optimal weights :
因此,使用逻辑回归进行分类的思想是最小化成本函数,该成本函数表示实际输出与使用S型函数预测的输出之间的关系。 我们将使用梯度下降算法来更新权重,直到获得最小的成本函数,从而获得最佳权重:
def sigmoid(x): h = 1/(1+np.exp(-x)) return hdef gradientDescent_algo(x, y, theta, alpha, num_iters): m = x.shape[0] for i in range(0, num_iters): z = np.dot(x,theta) h = sigmoid(z) J = -1/m*(np.dot(y.T,np.log(h))+np.dot((1-y).T,np.log(1-h))) theta = theta-(alpha/m)*np.dot(x.T,h-y) J = float(J) return J, theta训练和评估情感分类器 (Training & evaluating the sentiment classifier)
After implementing gradient descent, now we’ll move to training in order to calculate the optimal weights theta :
实施梯度下降后,现在我们开始进行训练,以计算最佳权重theta:
X = np.zeros((len(train_x), 3))for i in range(len(train_x)): X[i, :]= features_extraction(train_x[i], freqs_dict)Y = train_yJ, theta = gradientDescent_algo(X, Y, np.zeros((3, 1)), 1e-9, 1500)It’s time for testing our sentiment classifier in order to evaluate how it performs on test_x:
现在是时候测试我们的情感分类器,以评估它在test_x上的表现了:
def predict(tweet, freqs_dict, theta): x = features_extraction(tweet,freqs_dict) y_pred = sigmoid(np.dot(x,theta)) return y_preddef test_accuracy(test_x, test_y, freqs_dict, theta): y_hat = [] for tweet in test_x:
y_pred = predict(tweet, freqs_dict, theta)
if y_pred > 0.5:
y_hat.append(1) else:
y_hat.append(0) m=len(y_hat) y_hat=np.array(y_hat) y_hat=y_hat.reshape(m) test_y=test_y.reshape(m)
c=y_hat==test_y j=0 for i in c: if i==True: j=j+1 accuracy = j/m return accuracyaccuracy = test_accuracy(test_x, test_y, freqs_dict, theta)We’ve got more 98% in the accuracy, our model is almost perfect !!
我们的准确率更高,达到98%,我们的模型几乎完美!
Note : This blog is based on the new specialization NLP at DeepLearning.ai
注意: 此博客基于 DeepLearning.ai 上的新专业NLP
翻译自: https://medium.com/swlh/sentiment-analysis-from-scratch-with-logistic-regression-ca6f119256ab
逻辑回归分析与回归分析
http://www.taodudu.cc/news/show-1874175.html
相关文章:
- 构建ai数据库_为使用AI的所有人构建更安全的互联网
- 社会达尔文主义 盛行时间_新达尔文主义的心理理论
- 两种思想
- 强化学习推荐系统_推荐人系统:价值调整,强化学习和道德规范
- ai带来的革命_AI革命就在这里。 这与我们预期的不同。
- 卷积神经网络解决拼图_使用神经网络解决拼图难题
- 通用逼近定理证明_通用逼近定理:代码证明
- ai人工智能的本质和未来_人工智能如何塑造音乐产业的未来
- 机器学习指南_管理机器学习实验的快速指南
- 强化学习与环境不确定_不确定性意识强化学习
- 部署容器jenkins_使用Jenkins部署用于进行头盔检测的烧瓶容器
- 贝叶斯网络 神经网络_随机贝叶斯神经网络
- 智能机器人机器人心得_如果机器人说到上帝
- 深度前馈神经网络_深度前馈神经网络简介
- 女人在聊天中说给你一个拥抱_不要提高技能; 拥抱一个机器人
- 机器学习中特征选择_机器学习中的特征选择
- 学术会议查询 边缘计算_我设计了可以预测边缘性的“学术不诚实”的AI系统(SMART课堂)...
- 机器学习 深度学习 ai_用AI玩世界末日:深度Q学习的多目标优化
- 学习自动驾驶技术 学习之路_一天学习驾驶
- python 姿势估计_Python中的实时头姿势估计
- node-red 可视化_可视化和注意-第4部分
- 人工智能ai算法_AI算法比您想象的要脆弱得多
- 自然语言理解gpt_GPT-3:自然语言处理的创造潜力
- ai中如何建立阴影_在投资管理中采用AI:公司如何成功建立
- ibm watson_IBM Watson Assistant与Web聊天的集成
- ai替代数据可视化_在药物发现中可视化AI初创公司
- 软件测试前景会被ai取代吗_软件测试人员可能很快会被AI程序取代
- ansys电力变压器模型_最佳变压器模型的超参数优化
- 一年成为ai算法工程师_我作为一名数据科学研究员所学到的东西在一年内成为了AI领导者...
- openai-gpt_为什么GPT-3感觉像是编程
逻辑回归分析与回归分析_逻辑回归从零开始的情感分析相关推荐
- python实现情感分析_利用python实现简单情感分析
最近选修的大数据挖掘课上需要做关于情感分析的pre,自己也做了一些准备工作,就像把准备的内容稍微整理一下写出来,下次再做类似项目的时候也有个参考. 情感分析是什么? 文本情感分析是指用自然语言处理(N ...
- 实体词典 情感词典_人工智能技术落地:情感分析概述
从自然语言处理技术的角度来看,情感分析的任务是从评论的文本中提取出评论的实体,以及评论者对该实体所表达的情感倾向,自然语言所有的核心技术问题.因此,情感分析被认为是一个自然语言处理的子任务. 情感分析 ...
- 实体词典 情感词典_基于词典的文本情感分析(附代码)
一.引言 目前中文文本情感分析主要分为三个类型,第一个是由情感词典和句法结构来做的.第二个是根据机器学习来做的(Bayes.SVM等).第三个是用深度学习的方法来做的(例如LSTM.CNN.LSTM+ ...
- 深度学习 情感分析_使用深度学习进行情感分析
深度学习 情感分析 介绍 (Introduction) The growth of the internet due to social networks such as Facebook, Twit ...
- python文本聚类 词云图_文本挖掘:避孕药主题情感分析
关于舆情分析的实例分析,希望给你带来一些帮助. 前言 距离上次文本挖掘小文章时间已经过了3个月了,北京已经入冬,有人说北京的冬天很冷,但是吃上火锅很暖:也有人说北京的冬天雾霾严重,太干.这两句表达的是 ...
- python怎么做情感分析_如何用python进行情感分析
我们在计划中遵循以下三个主要步骤:授权twitter API客户端. 向Twitter API发出GET请求以获取特定查询的推文. 解析推文.将每条推文分类为正面,负面或中立. 首先,我们创建一个Tw ...
- aws ebs 分析_使用AWS Comprehend进行情感分析
aws ebs 分析 情感分析使用AI来识别一段文字背后的核心情感. 在本文中,我们将研究如何使用AWS Comprehend构建情感分析器. 情绪分析 情感分析是分析一段文本以了解其背后情感的过程. ...
- python微博评论情感分析_基于Python的微博情感分析系统设计
2019 年第 6 期 信息与电脑 China Computer & Communication 软件开发与应用 基于 Python 的微博情感分析系统设计 王 欣 周文龙 (武汉工程大学邮电 ...
- python微博文本分析_基于Python的微博情感分析系统设计
基于 Python 的微博情感分析系统设计 王欣 ; 周文龙 [期刊名称] < <信息与电脑> > [年 ( 卷 ), 期] 2019(000)006 [摘要] 微博是当今公众 ...
- lstm训练情感分析的优点_使用LSTM进行文本情感分析
文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类.它是对带有情感色彩的主观性文本进行分析.处理 ...
最新文章
- win7 修改hosts 不起作用
- linux按进程分配物理内存,linux下内存管理学习心得(一)
- SQL Server 2008 R2 开启数据库远程连接
- MySQL8.0修改密码问题
- created写法_在vue中created、mounted等方法使用小结
- 遍历矩阵每一行穷举_LeetCode:二维数组—旋转矩阵
- java对象和json对象之间互相转换
- 顶目群定义及项目群管理
- 流程控制示例:---3个实例示例:
- 阿里 计算机底层架构原理 pdf,完美起航-震撼!8位阿里大牛编写的2500页计算机底层架构原理解析,香香香...
- 【图像处理】基于灰度矩的亚像素边缘检测方法理论及MATLAB实现
- 车载DSP音频项目研究开发技术的深化
- 付费系列 6 - 离散型障碍和触碰期权 PDE 有限差分
- APP流量变现,SDK聚合技术流量变现
- 自下而上:万物进化简史,罗辑思维强烈推荐,优生学在欧美造的孽令人震惊...
- linux服务器下mysql完全卸载
- Win10家庭版Hyper-V出坑(完美卸载,冲突解决以及Device Guard问题)
- 程序员博客遭攻击,炸出华为云前员工吐槽自家业务;谷歌宣布推出第二个版本 Git 协议,带来显著的性能提升...
- 使用Druid,C3P0连接池连接达梦主备集群
- mac下导出chrome插件及安装
热门文章
- mojoportal学习——文章翻译之使用Artisteer快捷的创建模板
- Adobe 成功案例之 ebay项目构建
- Unity直接调用Python脚本
- 2018ISMAR Comparing Different Augmented Reality Support Applications for Cooperative Repair...
- 181026英语每日一句
- C++读xml 文件信息
- Atitit 账号实名制验证等制度和手段 1. 实名制 - 身份证明的一种制度 免费编辑 修改义项名 1 1.1. 匿名制优缺点 2 1.2. 而实名制的弊端缺点是可影响信息安全,造成信息或隐私泄露。
- Atitit fsm有限状态机概念与最佳实践 目录 1. 概念组成与原理成分 1 1.1. 1、状态机的要素 4个要素,即现态、条件、动作、次态 2 1.2. 状态表 2 2. 性状 2 2.1.
- 从统计显著性到显著性统计
- 股市法则:长线大钱最终胜出(荀玉根、姚佩)