收入时间序列——之数学理解篇
前言:思路导引
最初我的脑海里提出这个问题,是来源于业务那里,她们真真切切希望能准确的分解收入指标,但苦于实际模型极其复杂,虽然她们也的确找了一个模型,里面刻画了一些她们所能想到的各种因素,并给予了一定的权重,这是传统的解决方法,但实际效果却并不好,人工不断调整的幅度非常大。后来,她们想如果能很好的预测收入就会有一个标准基线,这相当于大大减轻分解指标的工作量,如果预测的越准,那么后期需要调整的动作就越小。这个难题困惑了她们很长一段时间。
我特别希望用一个快速有效的工具解决它,在机器学习算法里找到了LSTM,并给予了一个实践,效果并不是很好,尽管后来有所提升(参见《(四)利用LSTM深度学习模型预测门店收入》)。于是我就在想这是为什么?这里面的理论支撑、数学原理究竟是什么?通过深入探究,我发现这是属于时间序列理论的领地,走进去,豁!别有洞天啊!立刻找来一些时间序列的书来看,人大王燕那本书思路连贯性特别好,脉络很清晰,但比较简单,相当于入门;Ruey.S.Tsay(是个美籍华人)的书内容丰富更有深度,就是中文翻译文字通畅稍差些;[美]Cryer克莱尔的书写的很不错,都是从简单例子入手慢慢切入复杂分析,由浅入深,能加深对时序的理解。
确实,这是个数学问题。无论是早先的赌徒问题,抑或后来的醉汉问题(据说是希尔伯特提出的),都引出了随机游走,它是最简单的时序模型。后经统计学家的努力,结合时间序列样本深入研究得更具体,也更贴合实际问题。现阶段LSTM作为一种深度学习模型是借鉴了前人的所有数学思想,从而演化成利用高计算性能的神经网络来解决问题。网上曾有人问ARMA和LSTM的区别,很多回答也很具体,然而在我看来它们是同一数学思想的不同演化,表面上看虽有区别,但本质相同。ARMA将当前和过去建立一种线性关系,从而提炼出白噪声这样的期望为零性质很好的误差序列,继而研究用于表征各时间点关系的(偏)自相关系数等一系列指标,并使用检验统计量做显著性检验,以验证当前模型反映信息提炼的效果。LSTM作为RNN的一种形式,或者往更大范围说是一种神经网络模型,它也是一种信息提炼,或者可以理解成信息流过滤机制,针对时序数据也是将当前和过去建立一种线性关系,在神经网络各层间通过感知机激活传递有价值的信息。一个是信息提炼,一个是信息过滤;一个是以白噪声纯随机序列作为终结,一个是以损失函数收敛作为终结,殊途同归啊!其背后的核心数学原理都是空间变换【将实际样本空间的点数据,经过一系列几何变换(神经网络中的W权重矩阵,ARMA中的自回归系数或特征根)】和收敛性【挖掘样本数据中的规律,无论用何种方式其充要条件是收敛(神经网络中的loss收敛,ARMA中的自协方差及残差方差收敛)】。而且,我还发现,计算机在处理循环迭代上得心应手,这种独有的特质在处理复杂模型上更有优势,而数学完成整个支撑理论体系的建功立业,这种特有的逻辑推理则更有助于发现本质和理解本质。模型或工具的思想源泉全部来自于纯数学理论领域,这样的数学思想不得不说精彩之至。
下面,我结合学习总结了一些内容,这些都将用于后续数据探索和模型预测,在获得了通往这门学科的入场券及获悉了其知识内涵后,由衷的感觉很充实很快乐,也乐于将这些心得理解记录下来,分享出来。
一. 时间序列
时间序列一般分为以下三类:
(高斯)白噪声序列:纯随机序列,也称新息或扰动,特别地,当它符合均值为 、方差齐性
正态分布时,我们称为高斯白噪声。高斯白噪声独立且同分布,白噪声序列独立未必同分布,独立的特点是自协方差函数
,这里
是延迟时长,也就是说不同时间点的状态没有任何关系。类比人这一生,它是没有记忆的,在茫茫人海中出现又悄无声息的消失,挥一挥衣袖,不带走一片云彩,在数学上被认为是没有分析价值的,提取不到新信息,正是由于它的独立无关性,所以可以用它来构造线性组合。
(弱/宽)平稳序列:非纯随机序列,均值固定,二阶矩存在(为什么止步二阶矩?因为只考察协方差和方差,故无论对原点矩还是中心距到二阶就可以了),自协方差函数 ,自协方差函数与时间点选取无关只与时段长度有关,自相关函数会衰减趋于0,可以从中提取出内在影响关系的相关信息和规律,并以白噪声作为残差序列。同样作类比,芸芸众生总会有普世价值,总归是有规律可循,有价值和意义,并得以延续,数学上对平稳序列研究的很透彻。Word分解定理告诉我们一个平稳序列可以分解为确定性平稳和随机性平稳这两个互不相关的序列之和。弱平稳一般可以表示为
形式,其中确定性平稳序列就是均值函数
,随机性平稳序列就是白噪声
的线性组合,ARMA模型拟合的就是后一部分,也就是说ARMA是对平稳序列里随机部分的分析研究。有的书将平稳序列一般形式写成
,其实是一样的,这里
是白噪声。因为当
时是
的另一种表示形式,此时
是自回归系数多项式表达(比如在AR(1)时是
);当
为某一非负整数时是
表示形式,此时
恰是移动平均系数
。这两种形式都能看出任一平稳序列都可以表示成均值(确定性)和白噪声多项式(随机性)的组成,即Word分解定理的理解形式,后一种可能更直观一些。
非平稳序列:这世上存在的大多数序列都是非平稳的,但我们可以转化为平稳序列来研究。Cramer分解定理在Word分解定理基础上进一步推广成:任何时间序列都可以分解成确定性趋势成分(确定性影响)和平稳零均值误差成分(随机性影响)这两部分的叠加。如何理解?其实和上述Word分解定理类似,只不过确定性部分未必是均值,比如可能是时间的线性函数或二次函数关系,或者是季节指数关系等等;同时剩下的随机性部分仍是含白噪声的某种组合,但未必是线性的或平稳的,比如异方差。所以依此定理,非平稳序列的研究包括了以下两种分析方法:
(1) 确定性因素分解:主要是趋势和季节,一般通过最小二乘法/迭代法线性或曲线拟合、移动平均/指数平滑、季节指数等方法只能提取到强劲的确定性信息,对随机性信息浪费严重。
(2) 随机时序分析:对随机波动,用差分/条件异方差等方法进一步分析确定性因素之间的作用关系,弥补确定性因素分解在很多情况下拟合精度不高的问题。
倘若还是类比,这样的人生大起大落,不走寻常路线,其内总能蕴含让人问津的奥秘。
二. 自相关
可能有人注意到上面的“自”这个字眼,我早些时候曾经在一篇文章中看到过“自相关性”这样的文字描述,当时纳闷了一下,但也并没在意,因为那时候还不知道是时序理论里的东西。现在一切都知晓了!之所以有“自”,是因为它没有其它维度(增加到有输入输出就是多元时序分析)做横向分析,就只好拿自己和过去的自己作纵向分析。如何理解自相关?就好比在影视作品里,很帅的男主或靓丽的女主突然失忆了,这种失忆就对应着自相关性为0,因为他/她对自己过去任何时刻的事情都不记得了,也就是说各个时刻的事情之间产生不了任何关联,这就类似前面提到的白噪声了,变成了纯随机性的事物。于是剧情发展当然就是一点点往里加自相关性啦,一方给另一方营造浪漫温馨回忆,终于有一天男主或女主被唤醒记忆了,一切都那么美好!
那么在数学上如何表达(偏)自相关函数(系数)呢?给定一时序样本,我们有ACF(autocorrelation function):
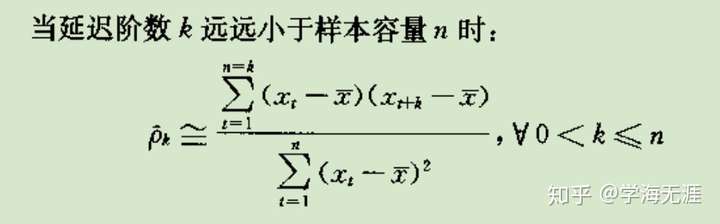
再有PACF(Partial autocorrelation function),下式中 是条件期望:
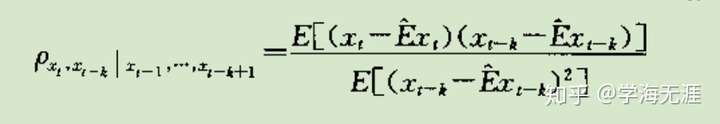
PACF和ACF的区别是:ACF迭代考虑了 k 阶延迟观察值中间因素的影响;PACF则将这些中间因素当成常数来看,只单纯看当前和第 k 阶延迟这两者的关系,Partial就是部分的意思。经过计算,延迟 k 阶PACF实际上就是 AR 模型的第 k 个自回归系数 。
三. 平稳性检验

时序图检验:通过看图的方式,看均值是否稳定,方差是否齐次,是否存在趋势或季节。
(偏)自相关图检验(ACF、PACF):通过看图的方式,看自相关函数ACF和偏自相关函数PACF是否具有短期相关性,以及在 2 倍标准差范围内的收敛性、截尾、拖尾等性质。
单位根检验:判断AR特征根是否落在单位圆上(单位根),适用于 过程的平稳性检验。
白噪声检验:通过假设检验更精确的方式,判断序列本身是否为白噪声序列。
四. 检验统计量
LB统计量:检验白噪声
可以用ACF(自相关函数 )混成检验方式,通过多个
延迟阶数
来判定是否平稳序列,统计量主要有Q检验统计量
和LB检验统计量
,后者用的更多,它们都是近似服从自由度为延迟阶数
的卡方分布,
为时序总数,通常
不必选取很大就可以检验出结果,一般取
,这是因为平稳序列往往具有短期相关性,而这又是由于自相关系数随着延迟阶数
的增大而迅速呈负指数下降,即
。

如果LB统计量的p值很大,则无法拒绝原假设,也即为白噪声,这种情形下各延迟阶数的自相关系数都接近于0;如果p值很小,则拒绝原假设,即为非白噪声,这种情形下各延迟阶数的自相关系数都相对比0大一些,甚至接近于1。
ADF检验:单位根检验平稳时序
ADF检验适用所有 模型的平稳性检验,其原理是当至少存在一个特征根落在单位圆上时,自回归系数之和等于1,设定
,根据
是否为 0 检验单位根,
是
的最小二乘估计。

ADF检验是DF检验的改进版,所以称为增广DF检验。DF检验只适用1阶自回归AR(1)模型且为单边检验。1阶自回归存在单位根的时序不是平稳时序,它是极其普遍的随机游走,很多场合我们需要先判断一个时序是否为随机游走(中心化)或带漂移的随机游走(未中心化)。
事实经验上,对于很多原始的明显非平稳序列,我们一般都是先取对数消除异方差,然后通过差分消除趋势或季节影响,最后再对处理后的时间序列平稳性进行ADF检验。ADF适合检验方差齐性的时间序列,对于异方差检验效果不好。
如果ADF统计量的p值大于0.05,则无法拒绝原假设,也即为非平稳时序;如果p值小于0.05,则拒绝原假设,即为平稳时序。
五. 模型优化判别准则
AIC:整合似然函数最大化和参数个数最小化的度量准则,AIC数值越小说明模型优化越好。

BIC:也有个别书称为SBC,即贝叶斯信息准则,弥补AIC在样本容量趋于无穷大时参数个数的权重仍是常数2的不足,所以将参数个数惩罚系数和样本容量对应,解决大样本容量下真实阶数的估计。同理,BIC数值越小说明模型优化越好。

六. 线性模型 ARMA:平稳时序分析
ARMA(Auto Regressive Moving Average),自回归滑动平均,可拆开,可合并。
AR:自回归,以历史时刻的自己作线性回归, 是自回归系数,
是零均值白噪声。

AR的几个特点:
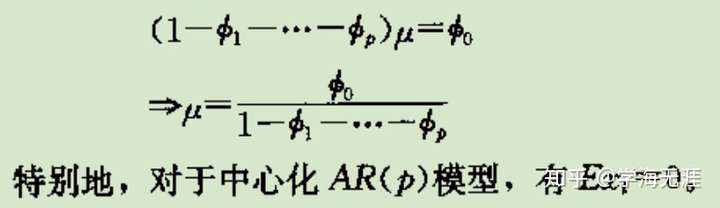
AR均值
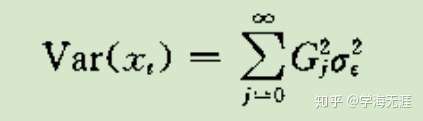
AR方差
其中G是Green函数,如下图上一行G是用特征根表示形式,下面的G是通过自回归系数递推的公式:
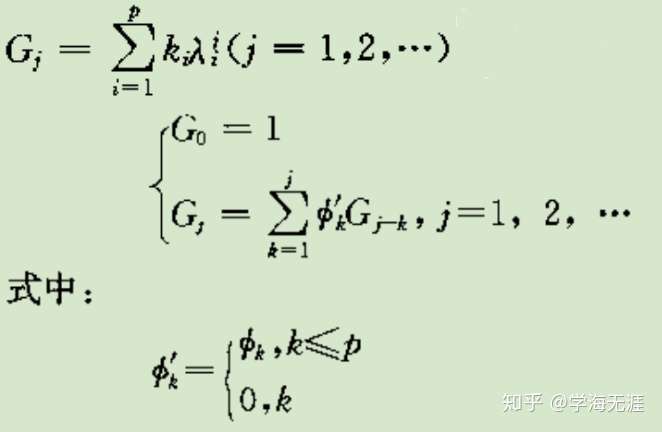
Green函数的两种表达
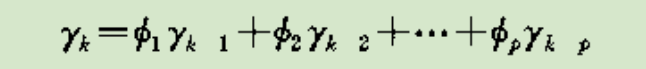
AR自协方差函数递推公式
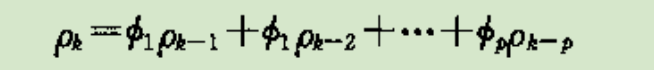
AR自相关系数递推公式:拖尾

AR偏自相关系数,p阶截尾
其中,D是自相关系数矩阵的行列式。
MA:滑动平均,以白噪声作移动加权平均, 是时序均值,
是移动平均系数,
是零均值白噪声。

MA的几个特点:
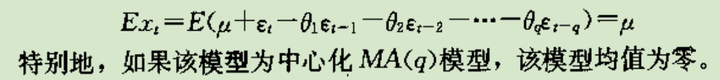
MA常数均值
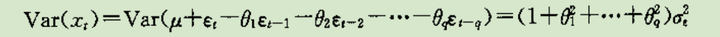
MA常数方差
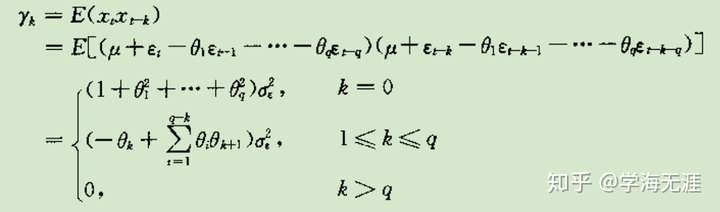
MA自协方差函数:q阶截尾
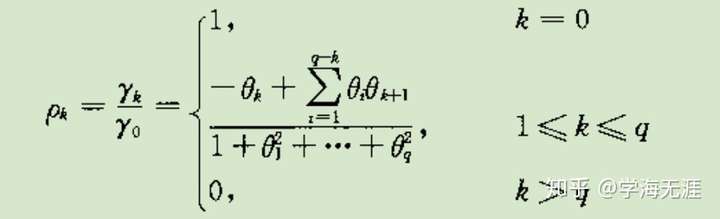
MA自相关系数,q阶截尾
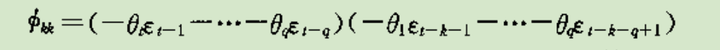
MA偏自相关系数:拖尾
ARMA:自回归滑动平均,AR和MA的加法组合, 是自回归系数,
是移动平均系数,
是零均值白噪声。

将上式右边 部分左移变为ARMA模型的另一种简化表示:
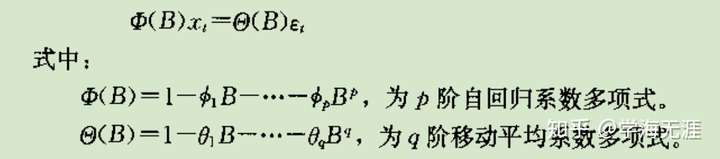
再将自回归系数多项式右除形同如下通用形式,方便记忆:

ARMA的几个特点:
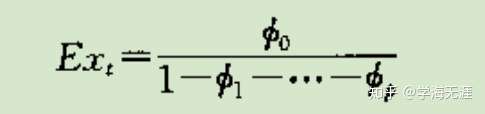
ARMA均值(MA中心化)
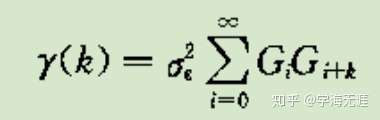
ARMA自协方差函数
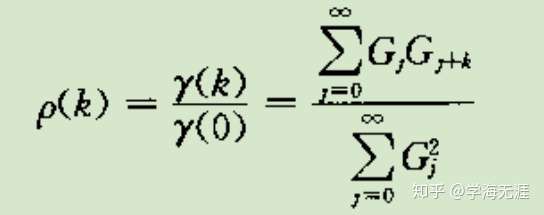
ARMA自相关系数

截尾/拖尾
注意:AR和MA就像一对亲姊妹,它们互为对偶关系,MA可逆对应AR平稳,并延续到ARMA的可逆性和平稳性。数学上还有很多对偶关系的现象,比如运筹学里的对偶理论,它对SVM的最优化结论推导就起到了很大作用。
七. 线性模型 ARIMA:非平稳时序分析
ARIMA,自回归滑动平均求和模型,是在ARMA的基础上,增加了差分, 中间的
就是差分阶数。

不难验证,差分的d阶操作就是 ,比如
,
,那么做二阶差分后
,以此类推。
特别的,当 ,
和
都为
时,
就是随机游走序列:
,因为有差分所以随机游走不是平稳序列。
趋势模型
上述ARIMA模型可以简化成如下形式:
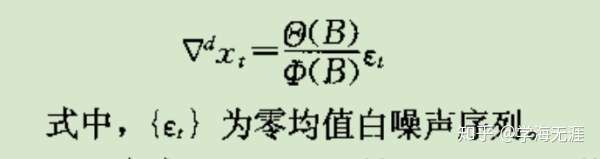
左边 可以理解成对
序列
阶差分后形成的序列,右边就是一个ARMA平稳时序。从中看出差分操作主要意义是为消除趋势因素,即
,
是提取的趋势因素序列,
是平稳时序。对于
,一般如果有很明显的线性趋势,
就可以完成趋势提取;如果是非线性趋势,一般 2 到 3 阶低阶差分也基本能看出趋势端倪;如果阶数取的很高,不但容易产生过差分(
方差增大),且说明原序列很可能没有趋势 或 具有长期记忆不具备短期相关性 或 不适用线性模型。
疏系数模型
当ARIMA中拟合的多项式系数有等于零的情况,也即 和
未取满,这就是疏系数模型。

判断疏系数一般是通过观察ACF图和PACF图,如果发现某延迟阶的系数显著大于 2 倍标准差,而其它延迟阶的系数都在 2 倍标准差内甚至很小,那么就可以考虑拟合上述对应的显著的延迟阶数。比如:经一阶差分后,发现PACF出现 1 阶和 4 阶在两倍标准差之外,则AR模型可定阶为 ,发现ACF全部落在两倍标准差内或呈现短期相关性并拖尾,则整体可拟合模型
,也即
中只出现
系数项。也就是说我们要删除不显著的延迟阶,而保留显著的延迟阶,当然这个过程可能需要不断尝试后,通过显著性检验而调整的。
季节模型
季节模型分加法和乘法两种,先看加法:
,
是提取的季节因素序列,
是提取的趋势因素序列,
是平稳时序,可以用ARMA建模拟合。一般的做法是
用
阶差分提取,
用
步差分提取,这里要注意阶和步的区别,
步的意思是
,所以对应的延迟算子是
,乘方一个是在里面(步),一个是在外面(阶)。如果数据源呈现月周期的形式,一般上述
做12步差分,如果是季周期特点,则
做4步差分。
注意:这个加法不是数学运算加法的含义,而是指各因素的简单叠加,提取各因素在数学运算上其实是连续先后做差分运算处理,也就形成了下式中所体现的形式上的“乘除”关系。

再看乘法:
表述成 形式,所谓乘法意义在于
、
、
不是简单的叠加影响,而是相互作用影响,体现在ACF/PACF图上就是经加法差分处理后的
随机波动时序仍然具有短期相关性(个别延迟阶系数在 2 倍标准差之外)和季节效应(显著延迟阶正好位于季节延迟步),从而导致用ARMA拟合效果不好。结合上面加法理解,其运算处理形式如下:

可以看出,它的思路是为了将趋势和季节完全分离开,分别作ARIMA处理,有别于加法是揉合在一起操作的。具体说就是将上式看成 和
两部分组合,前式是对趋势作
阶差分的
,后式是对季节作
阶差分和
步差分的
,这样就彻底分离开两个搅在一起的因素,最后对剩下的残差序列
作白噪声检验。
八. 线性模型 条件异方差
我是这么理解异方差的,就相当于把上面的ARMA这套再在残差序列里玩一次。什么意思呢?就是说通过ARMA或ARIMA拟合过后的残差序列,它并不完全是白噪声,特别遗憾的一种情况是除了满足期望为0、自相关系数为0这两个条件外,只差方差齐性这个条件不满足。表现在数据上就是随着时间推移,其残差序列的方差是跟时间相关的函数,比如正比函数或二次方函数关系,即 。实际上,由于零均值,所以残差序列的方差就是残差平方的期望
,于是人们主要围绕这个
开展一系列成熟有效的研究。
方差齐性变换:
假定存在函数明确关系,比如 或
,通过一阶泰勒展开很容易推导作对数变换即能保证方差齐性。这就是为什么很多时候我们喜欢先取对数再作后续分析的缘故,主要就是希望转换为方差齐性的优良特性。
ARCH:自回归条件异方差
事实上,我们几乎不可能知道残差序列方差和时间的函数关系。所以,又回到开头,以残差平方序列 为对象考察其自相关性的问题,当自相关系数
不为 0 时,可以用残差平方序列的自回归模型进一步拟合;而当
为 0 时,目前还没有解决方案提取异方差信息。

上述第三个式子 也被称为
的波动率方程(动态方程),更多的写法是
为条件方差,是一个随时间而变化的量,表示在
时刻的方差
是过去平方扰动
的线性组合,
和
为参数。第一个式子
被称为
的均值方程,可以通过ARMA建模得到,残差
称为在
时刻的扰动或新息,相比较于高斯白噪声其特点是虽无自相关性但并不同分布。一种更常见的分析情形是金融资产收益率
,它通常为零均值序列无关(相当于上面的
),所以就没有均值方程或ARMA过程,或者为常数均值,均值方程就是个常数。第二个式子
是高斯白噪声,均值为0,方差为1,独立同分布,比如标准正态分布或标准学生
分布或GED。最后,我们通过对标准残差
进行独立同分布检验来验证模型拟合充分。
通过计算ARCH(1)的峰度不难得出,扰动 往往具有尖峰厚尾性质,比高斯白噪声更易产生异常值(outliers),结合《探索数据》文章中提到的,我们发现日收入数据所具有的尖峰厚尾,实际上就是显著存在ARCH效应,扰动的复杂度使得日收入出现异常值的频率比正态分布的纯随机扰动出现的异常值频率要高。但ARCH的缺点是它给不了出现异常扰动的原因或因素,它只能刻画这样的存在性。
从上述ARCH模型公式的形式上看,如果定阶可只看 部分,则是典型的自回归模型,通过查看
的PACF图,选择 AR 模型拟合,所以名称上被称为
模型;如果把
看成因变量,把
看成白噪声序列,则是典型的滑动平均模型,为和后面GARCH的阶保持一致标识,所以用字母
。
的PACF图需要
阶截尾才能定阶AR(q),如果不是,则需要更高阶的ARCH模型或GARCH模型。
GARCH:广义自回归条件异方差
为解决长期自相关,提高ARCH拟合精度,于是又加上了对条件方差 的自回归,这样本质上相当于对
做
模型拟合,对
做
模型拟合,所以整体上看就相当于对整个残差序列又做了一遍ARMA建模。
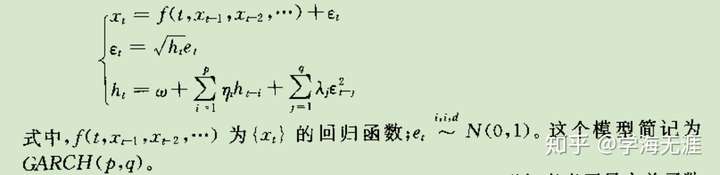
通过作变换 ,
是鞅差序列,这里
相当于上式的
,
相当于上式的
,那么上式可以改写成如下形式:
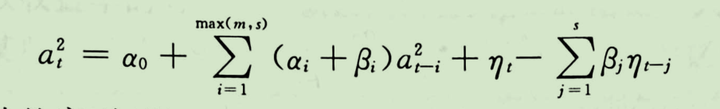
可以明显看出是对平方扰动 应用ARMA模型,GARCH(1,1)也呈现有尖峰厚尾特点,但同时它有一个更为重要的特性就是波动率聚集,即大的平方扰动会紧跟一个大的平方扰动,也许这就是我们平时所说的“买涨不买跌”的道理。GARCH是目前最为常用可行的条件异方差序列拟合模型,当然后来又衍生了其它变体,这里不再赘述。
事实上,早在20世纪80年代,美国统计学家、计量经济学家Engle因深入分析经济时间序列,提出了上述ARCH条件异方差模型,并用以解决通货膨胀率建模,从而获得2003年诺贝尔经济学奖。英国统计学家、计量经济学家Granger提出了协整理论,从而促进了多元时间序列分析方法的发展,也因此获得2003年诺贝尔经济学奖。
九. 多元时序分析
ARIMAX:动态回归模型
将自变量序列 从
维变成
维序列(输入序列),并在此基础上,增加了响应序列
(输出序列),构造它们之间的线性关系回归模型。

上式中,有 个输入变量,针对第
个输入变量对应有
延迟阶数,
,
是延迟算子,
是回归残差序列。如果所有的输入
以及输出
都是平稳序列,那么
也是平稳序列。从上看出,
代表的是第
个输入变量序列经
阶差分以后的残差序列,再用
系数多项式左乘即为前面提到的一元变量序列的ARIMA模型,然后
是一个ARMA模型,所以这里共有 1 个ARIMA模型和 1 个ARMA。
单整
原序列经过 阶差分后成为平稳序列,则称原序列为
阶单整序列,记
。
协整
输入输出序列各自都是非平稳序列,但把它们合在一起考虑时可能就是平稳序列,这种现象叫协整。协整给研究多元时序关系时要求必须每个序列都平稳的严格要求松绑,条件变得更为宽泛,只要求整合在一起后的序列的残差平稳就可以。
十. 非线性模型:TAR门限自回归
我们发现,不管是ARMA模型,还是GARCH模型,它们都是用线性关系去近似逼近,比如ARMA模型线性拟合原时间序列,GARCH模型线性拟合条件异方差(波动)。如果序列是非线性的(通常情形下都是),那么这样的线性拟合效果一般都不会太好,所以引入了诸多非线性模型,其中比较惹人注目的是TAR门限模型。
模型是由中国香港汤家豪(Tong)于1978年首次提出的非线性模型,其起因是序列的时间不可逆情形,即非平稳、非对称的上升或下降,举个例子:股票从低缓的时间点突然呈现剧烈上升趋势,这就形成时间不可逆。一般的,非线性序列的平稳性研究可以通过分解成线性或逼近线性来解决(比如一个双线性模型),于是就产生分段线性的想法,就好比用一个阀门来控制大坝水位的高低。

其实,1 阶 就是由 2 个
模型组合而成,只不过是通过一个开关控制,
被称为门限参数。
模型可以用来解释数据中的条件异方差现象。
现在回到我之前写的那篇《(四)利用LSTM深度学习模型预测门店收入》,回顾一下LSTM模型图及公式:
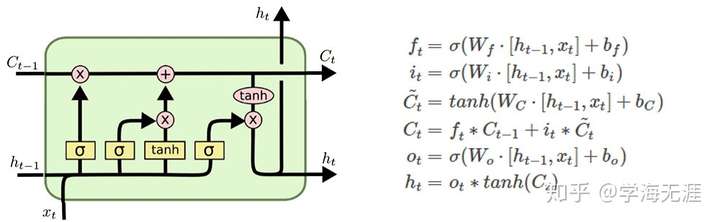
有没有发现这两者的公式很相像?我在 Schmidhuber 那篇 LSTM 论文里也没有找到一丝一毫数学原理,而更多的是对反向传播过程中梯度消失和梯度爆炸的误差推导分析以及一系列实验。现在我觉得我找到了理论来源,之前一直不得其解为何要弄这一堆门限,我想其本质是通过这样的 模型将非线性转化为线性来处理,并产生一些记忆。这也告诉我们,数学中的分段函数是带有记忆功能的,现实中的例子就是水库大坝,在不同段位设置水闸阀门控制水位。
所以,懂得理论原理后,我就在想,应该事先分析数据的本质,然后有针对性的采用哪种算法、模型会比较好,否则会陷入盲目的试错,而且可能还找不到错误原因!
总结
OK,讲到这里,通过对时序理论的清晰理解,现在就让我们开始用这把理论原理的万能钥匙拧开探究收入时序数据的大门吧!请关注我的下一篇《收入时间序列——之模型探索篇》!
收入时间序列——之数学理解篇相关推荐
- 收入时间序列——之模型探索篇
前文<收入时间序列--之数学理解篇>已经梳理了时序分析所具备的基本数学原理,现在开始着手探索收入数据的内在规律,主要提出以下几个问题并给予解答. 收入时间序列是平稳的吗?(偏)自相关情况如 ...
- 全部物理宇宙全部能由数学理解
在这神圣的宇宙之中,通过学习数学和科学来分享神圣的心灵,这一信念可以说是理性思维的时间最长的动机,"上帝"似乎在时空世界既非一个对象,也非似物理世界中的对象综合,更不是罗拉图世界中 ...
- SVD奇异值分解 中特征值与奇异值的数学理解与意义
前言 之前的博客中SVD推荐算法写得不是很严谨,r̂ ui=∑Ff=1PufQfi+μ+bu+bir^ui=∑f=1FPufQfi+μ+bu+bi\hat{r}_{ui}=\sum_{f=1}^{F} ...
- 一点就分享系列(理解篇_4+实践篇_2)”干货-全网最简且全”的理解!2020年了!您只知道GAN?ECCV超分论文“IRN” 全家桶大放送!!
一点就分享系列(理解篇_4+实践篇_2)"最新干货"--2020 ECCV 超分论文之一"IRN"(更新中..) 最近开始了csdn坚持原创之旅,目前到了理解篇 ...
- 一点就分享系列(理解篇3)—Cv任务“新世代”之Transformer(下篇)提前“cv领域展开”——快速学习“视觉transformer的理解”+“一些吐槽”
一点就分享系列(理解篇3)Cv任务"新世代"之Transformer(下篇)--"cv领域展开" 提示:本篇内容为下篇,如感兴趣可翻阅上和中篇! 理解篇3 上 ...
- 一点就分享系列(理解篇3)—Cv任务“新世代”之Transformer系列 (中篇-视觉模型篇DETR初代版本)
一点就分享系列(理解篇3)-Cv任务"新世代"之Transformer系列 (中篇-视觉模型篇) 对于上篇介绍transformer得原理,自认为把细节讲得很详细了,作为" ...
- 一点就分享系列(理解篇5)Meta 出品 Segment Anything 4月6号版核心极速解读——主打一个”Zero shot“是贡献和辅助,CV依然在!
一点就分享系列(理解篇5)Meta 出品 Segment Anything 通俗解读--主打一个"Zero shot"是贡献,CV依然在! 文章目录 一点就分享系列(理解篇5)Me ...
- 用高中数学理解AI “深度学习”的基本原理
本文作者尚俊霖,全职产品经理,业余自学机器学习.最近开始写硬核科普,欢迎关注公众号欠拟合(ID:Underfit). Google 研发了十年自动驾驶后,终于在本月上线了自动驾驶出租车服务.感谢&qu ...
- 天籁数学——数列篇(1)
好久没写博客了,这个系列就来聊聊数学,我们知道数学是一种工具,更是一种思想,在我们的日常生活和工作中都有广泛的应用. 比如算法中有一种叫做"递推思想",转化到数学上来说就是&quo ...
最新文章
- 撑起整个互联网的7大开源技术
- 浅谈String和StringBuffer类:
- 渲染优化 lock unlock
- Python学习十大良好习惯
- 让sourceSafe每天自动备份及修复(适用于vss6.0和vss2005)
- 设计模式09_代理模式
- JavaScript数据类型之逻辑运算符(9)
- python--列表,元组,字符串互相转换
- Focal Loss 和 LightGBM 多分类应用-python实现
- ollvm源码分析之指令替换(1)
- Picture Control控件图象保存为bmp,jpg,emf,tif,gif
- 一位财务自由人士的投资修行
- 计算机技术专业求职简历,计算机技术专业求职简历模板
- 基于C#和三菱PLC通过MX Component进行通信的具体方法
- 学完计算机绘图收获有哪些,概率论与数理统计热合买提江网课参考答案查询,画法几何及土木工程制图计算机绘图...
- vue3 + crypto-js加密解密(普通版本/TS版本)
- 三角肌前束(05):杠铃颈前推举
- C语言九:位域(位域声明、位域的定义和位域变量的说明、对于位域定义的几点说明:、位域的使用)、typedef(typedef vs #define)、强制类型转换(整数提升、常用的算术转换)
- 服务计算作业二——GO语言TDD实践报告
- 摩托车闪光控制器专用芯片MST1172