nodejs实现拉钩网爬虫
概述
详细
代码下载:http://www.demodashi.com/demo/10398.html
一、准备工作
1、安装最新版本的nodejs,其中npm会被自动安装
2、安装该项目需要的包
npm install cheerio jsdom mysql request -S
其中package.json中的内容为:
"dependencies": {"cheerio": "^1.0.0-rc.1","jsdom": "^11.0.0","mysql": "^2.13.0","request": "^2.81.0"}
二、程序实现
1、程序实现的目录结构如下:
2、实现思路如下:
index.js:程序主文件,各种数据清洗工作,url构造在这个文件中完成
Job.js : 用于构建Job对象,有助于写入数据库
db.js:连接数据库并写入数据
url_construct.js:可以自己配置抓取那些公司的职位信息。如阿里巴巴,百度,腾讯等。部分代码如下:
const companyNames = ["网易","阿里巴巴","百度","腾讯","去哪儿","浪潮"];
const encodedCompanyNames = [];
//转化为urlencoded
for(let i=0;i<companyNames.length;i++){encodedCompanyNames.push(encodeURIComponent(companyNames[i]));
}
module.exports = encodedCompanyNames;
3、数据库设计截图

上面是本例子的数据库截图,其中id是主键,同时是自增的。
4、连接数据库注意点
下面的user和password的值是你安装数据库时候设置的,请自己修改
const pool = mysql.createPool({connectionLimit:10,database:TEST_DATABASE,user:"root",password:"root"
});
三、运行效果
首先cd到src目录下,然后简单的运行下面的命令就可以了:
node index.js
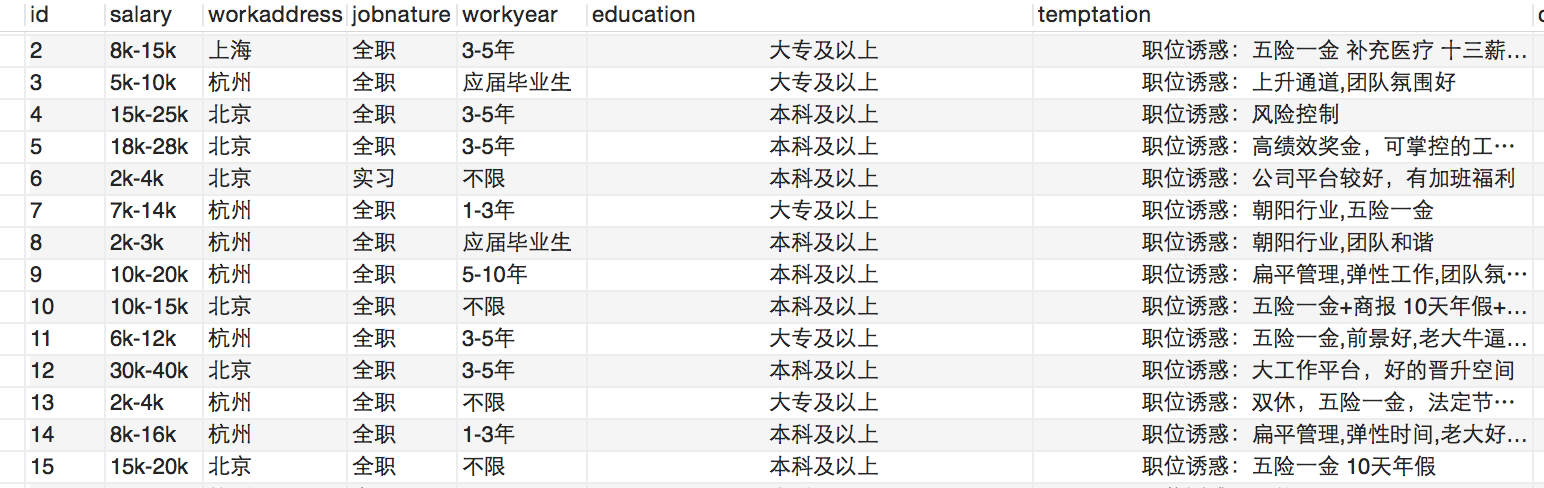
下面是数据库抓取的部分信息截图:
四、其他补充
如果你需要增加更多功能,可以在demo大师的"没有找到例子?"功能提出,我会增加例子,谢谢
注:本文著作权归作者,由demo大师(http://www.demodashi.com)宣传,拒绝转载,转载需要作者授权
nodejs实现拉钩网爬虫相关推荐
- python爬虫解决频繁访问_python3拉钩网爬虫之(您操作太频繁,请稍后访问)
你是否经历过这个: 那就对了~ 因为需要post和相关的cookie来请求~ 所以,一个简单的代码爬拉钩~~~ import requests import time import json def ...
- 爬虫项目实战:拉钩网职位需求采集
文章目录 需求分析 项目简介 职位需求页面分析 PositionId 数据采集 真实的URL获取 请求头信息 表单信息 返回的JSON数据 PositionId 页面解析 数据分析 可视化中文显示问题 ...
- python爬取拉勾网_python爬虫—爬取拉钩网
本人自学python,小试牛刀,爬取广州片区拉钩网招聘信息.仅用于学习 参考文章:https://blog.csdn.net/SvJr6gGCzUJ96OyUo/article/details/805 ...
- Python3网络爬虫之requests动态爬虫:拉钩网
操作环境: Windows10.Python3.6.Pycharm.谷歌浏览器 目标网址: https://www.lagou.com/jobs/list_Python/p-city_0?px=def ...
- python爬虫—爬取拉钩网
本人自学python,小试牛刀,爬取广州片区拉钩网招聘信息.仅用于学习 参考文章:https://blog.csdn.net/SvJr6gGCzUJ96OyUo/article/details/805 ...
- scrapy爬虫实践之抓取拉钩网招聘信息(4)
拉勾的302搞的我不心力憔悴,几乎失去了动力继续再研究拉勾爬虫-实际上,这种无力感很大程度上来源于知识结构的匮乏(尤其是基础方面)和毫无进展带来的挫败感. 于是乎去读基础教程<learning ...
- 结束 txt进程_Python多进程抓取拉钩网十万数据
转载:Python多进程抓取拉钩网十万数据 准备 安装Mongodb数据库 其实不是一定要使用MongoDB,大家完全可以使用MySQL或者Redis,全看大家喜好.这篇文章我们的例子是Mongodb ...
- Python selenium 拉钩爬虫
selenium 用作自动化测试工具,并非爬虫工具,用作爬虫性能没那么好.但既然可以读取网页信息,那还是可以用来爬取数据的.用该工具模拟访问,网站会认为是正常的访问行为. 项目创建几个文件,都在同一个 ...
- python 爬取拉钩网数据
python 爬取拉钩网数据 完整代码下载:https://github.com/tanjunchen/SpiderProject/blob/master/lagou/LaGouSpider.py # ...
最新文章
- Android图片缓存框架Glide
- 架构师之路 — 数据库设计 — 关系型数据库的约束类型
- Oracle编程入门经典 第10章 PLSQL
- [HDCTF2019]MFC
- Maven修改远程仓库配置
- sign python_python机器学习
- 「3.4w字」超保姆级教程带你实现Promise的核心功能
- 2018-07-06笔记(LNMP配置)
- 转 java synchronized详解
- 收购小蓝单车部分资产、与ofo蜜月期结束,滴滴重构共享单车布局
- 使用FFMPEG类库分离出多媒体文件中的H.264码流
- linux怎么编译python_linux 编译安装python3
- H3C交换机配置的备份与恢复[3CDaemon]
- python下载小说
- 异常:could not initialize proxy - the owning Session
- The Sultan's Successors (八皇后)DFS
- Failure to find xxx in http://maven.aliyun.com/nexus/content/groups/public
- C语言实现通讯录代码详解(保姆级讲解)
- 牛客网华为云服务器,把通过牛客网注册的华为云服务器用起来!
- 世界杯营销战,中国企业赢麻了