智慧中国杯算法赛解读 | 精准资助数据探索(一)
2019独角兽企业重金招聘Python工程师标准>>> 
智慧中国杯是由DataCastle(数据城堡)主办的全国大数据创新应用大赛,提供了百万的竞赛奖金,数据城堡的创始人周涛是《大数据时代》的中文翻译者,在业内享有很高的名气。
OpenFEA将对此次大赛进行持续关注和报道,以推进大数据在国内的发展,让更多的人参与到大数据的应用创新当中来,为社会培养大数据人才出一份自己的力量。
此次大赛分为三个环节,第一是算法赛,任何个人和组织团体都可以参加,无资格限制,提交比赛结果即可。算法赛最后截止时间为2017年2月20日,在此之前提交结果都有效,现在报名还来的及哦!
《智慧中国杯算法赛解读系列》以算法资格赛为关注点,将详细解读这次比赛的三个主题(教育、交通、金融)的算法和数据,为您深入了解这场大赛以及进入大数据分析的大门提供全方位的支持。
因此,此篇文章是这个系列的第一篇,将对教育主题的精准资助竞赛进行数据的初步探索,也将带你进入获取百万奖金的大门(哇,好多money ^v^)
一、(大学生助学金精准资助预测)概况
大数据时代的来临,为创新资助工作方式提供了新的理念和技术支持,也为高校利用大数据推进快速、便捷、高效精准资助工作带来了新的机遇。基于学生每天产生的一卡通实时数据,利用大数据挖掘与分析技术、数学建模理论帮助管理者掌握学生在校期间的真实消费情况、学生经济水平、发现“隐性贫困”与疑似“虚假认定”学生,从而实现精准资助,让每一笔资助经费得到最大价值的发挥与利用,帮助每一个贫困大学生顺利完成学业。因此,基于学生在校期间产生的消费数据运用,大数据挖掘与分析技术对实现贫困学生的精准挖掘具有重要的应用价值。
教育算法资格赛采用某高校2014、2015两学年的助学金获取情况作为标签,2013~2014、2014~2015两学年的学生在校行为数据作为原始数据,包括消费数据、图书借阅数据、寝室门禁数据、图书馆门禁数据、学生成绩排名数据,并以助学金获取金额作为结果数据进行模型优化和评价。
本次竞赛需利用学生在2013/09~2014/09的数据,预测学生在2014年的助学金获得情况;利用学生在2014/09~2015/09的数据, 预测学生在2015年的助学金获得情况。虽然所有数据在时间上混合在了一起,即训练集和测试集中的数据都有2013/09~2015/09的数据,但是学生的行为数据和助学金数据是对应的。
此竞赛赛程分为两个阶段,以测试集切换为标志,2017年2月13日切换。
二、数据初探
官方提供的数据分为两组,分别是训练集和测试集,每一组都包含大约1万名学生的信息纪录:
图书借阅数据borrow_train.txt和borrow_test.txt;
一卡通数据card_train.txt和card_test.txt;
寝室门禁数据dorm_train.txt和dorm_test.txt;
图书馆门禁数据library_train.txt和library_test.txt;
学生成绩数据score_train.txt和score_test.txt;
助学金获奖数据subsidy_train.txt和subsidy_test.txt(实际下载的数据是studentID_test.txt,即您需要预测的学生样本)。
训练集和测试集中的学生id无交集,详细信息如下(注:数据中所有的记录均为“原始数据记录”直接经过脱敏而来,可能会存在一些重复或异常的记录,请参赛者自行处理)。
OpenFEA为做好本次活动的深度支持和报道,特下载了上述数据,参赛者可以在互联网上搭建的在线试用环境中直接分析此数据(请访问www.openfea.cn的下载专区),所有数据放在match/fund目录下,文件后缀名改成了csv。
(一)助学金获奖数据
在FEA的高级交互分析功能中,可以很轻松的来将这些csv文件加载进来进行分析,示例如下:
#加载助学金发放训练数据
stn = load csv by match/fund/subsidy_train.csv with (header=-1)
#看数据量大小 (10885行)
show tables
#查看数据
dump stn
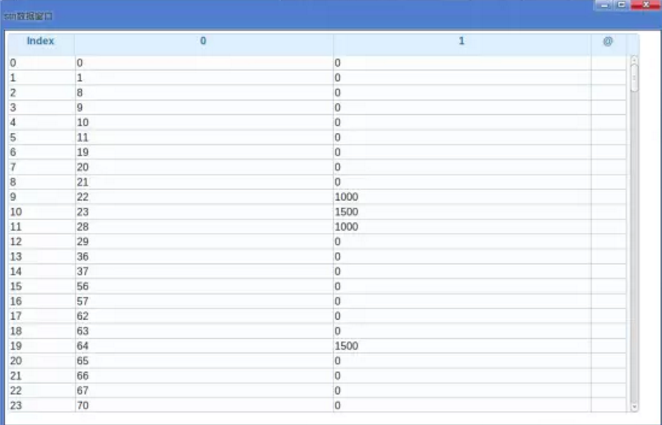
0列是学生ID,1列是发放金额,接下来修改列名,对发放的数量进行统计:
#修改列名
rename stn as (0:"id",1:"money")
#按发放数量进行分组
gt = group stn by money
#统计人数
stn_count = agg gt by id:count
#查看
dump stn_count

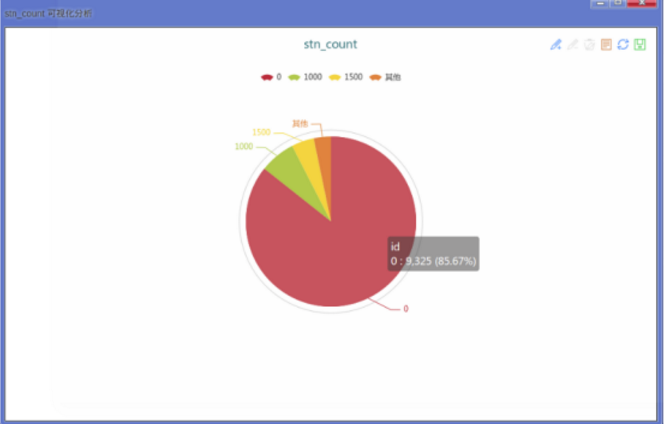
用图看一下更直观,plot stn by 04。如下图:没有助学金的占85%以上。
助学金的另外一个文件是studentID_test.csv,是需要最终预测的学生样本,只有学生id一列,和训练数据关联重复,有10783行,和训练数据(10885)是同一个量级。
(二)一卡通数据
一卡通的数据是学生的消费数据,能比较好的反应学生在学校的消费情况,对本次比赛来讲很关键,这部分数据在card_train.csv和card_test.csv。这两个文件都很大,都在1G左右,装载到内存要将近10G左右,一般的机器是跑不起来的,好在OpenFEA提供的在线环境是256G的,这点数据还是小意思了。如果装载数据的时间长的话,load数据时可以使用:=,这样就是在后台执行,我们不用关心超时,只要看任务结束就好了。
#加载一卡通训练数据
card := load csv by match/fund/card_train.csv with (header=-1)
#产看任务执行情况
show tasks
#看数据量大小 (12455558行)
show tables
#查看数据
dump card
装载花了22秒,一共是1245.5万,相当于每秒56.6万条。(哈哈,FEA的速度比较给力吧!),下面看数据:
第5列是消费数据,淋浴只要5毛钱,看看真怀念学生时代啊。
接下来对列名进行修改,计算一下每个人的消费次数,消费金额,最大剩余金额和最小剩余金额和平均剩余金额,以及消费行为的种类等。
#修改列名
rename card as (0:"id",1:"pos",2:"address",3:"catalog",4:"time",5:"cost",6:"have")
#根据id进行分组
gt2 = group card by id
#计算每个人的消费情况,消费总额,单次最大消费,单次最小消费,消费均值,消费中位数,消费次数
card_cost = agg gt2.cost by (cost_sum:sum,cost_max:max,cost_min:min,cost_mean:mean,cost_meidan:median,cost_count:count)
#然后计算卡内剩余金额的最大数,最小数,平均数
card_have = agg gt2.have by (have_max:max,have_min:min,have_mean:mean,have_median:median)
#两张合起来,一个人的消费状况就非常清晰了
card_money = join card_cost,card_have by index
#查查
dump card_money
看了结果也吓一跳,总消费上万的也好多啊,消费的均值也不高,总体情况我们使用card_desc = @udf card_money by udf0.df_desc来查看一下:
消费总额最高的是3万多,中位数是8903,单笔最大的消费是4407元,中位数是300,有人单笔最低是93元,看来此同学属于土豪行列,出现的负数可能是退款或误扣等,这个要结合业务知识去判断了,也可以作为噪音处理一下。
卡里保有金额最大为4399元,中位数为316元,还比较符合对学生的印象。
(三)小结
数据探索这里,有经验的老司机都可以直接使用FEA中的机器算法进行训练了!当然本篇是数据探索的第一篇,下一篇将继续探索剩下的4种数据,机器学习要放到第三篇。哈哈不要急,只要你关注OpenFEA的微信公众号,跟着我们的解读节奏,一定能让您开启机器学习的大门,赢取百万奖金也不是梦哦!
转载于:https://my.oschina.net/u/3115904/blog/809728
智慧中国杯算法赛解读 | 精准资助数据探索(一)相关推荐
- 机器学习算法竞赛实战--3,数据探索
数据挖掘是竞赛的核心模块之一,贯彻竞赛始终也是很多竞赛胜利的关键那么数据探索又是什么呢?可以解决哪些问题?首先应该明确3点,即如何确保自己准备好竞赛使用的算法模型如何为数据集选择最合适的算法如何定义可 ...
- 2020DCIC智慧海洋建设算法赛学习01-赛题北京及地理数据分析常用工具
序: 本系列的博客旨在学习2020DCIC智能算法赛-智慧海洋建设的优秀方案,对地理数据分析问题积累一些思路和经验. 作为这一系列博客的开篇,这篇博客主要内容包括对赛题的解析和对项目中会用到的一些常用 ...
- 2020DCIC智慧海洋建设算法赛学习02-数据分析
序: 这篇博客旨在对赛题数据做一些初步的探索,包括查看数据中的缺失值.异常值等,以及通过可视化来观察各个特征的分布情况,为之后进行特征工程提供一些思路. 1. 查看数据整体情况 对于一份数据集,首先要 ...
- 天池算法赛:数据挖掘经典赛事!DCIC 2020 数字中国创新大赛启动!
2020数字中国创新大赛(Digital China Innovation Contest, DCIC2020),以"培育数字经济新动能,助推数字中国新发展"为主题,采取多赛道并行 ...
- 2020数字中国创新大赛-智能算法赛-冠军方案
写在前面的话 大家好,我是 Champion Chasing Boy 的 DOTA,在队友 鱼遇雨欲语与余. 尘沙杰少.林有夕.嗯哼哼唧 的Carry下,最终在本届智能算法赛拿到了复赛总榜单Top1的 ...
- 2020数字中国创新大赛-智能算法赛-冠军方案分享
写在前面的话 大家好,我是 Champion Chasing Boy 的 DOTA,在队友 鱼遇雨欲语与余. 尘沙杰少.林有夕.嗯哼哼唧 的Carry下,最终在本届智能算法赛拿到了复赛总榜单Top1的 ...
- Follow me!百万奖金由你拿 | 精准资助机器学习(三)
2019独角兽企业重金招聘Python工程师标准>>> 通过前面两篇的数据探索,我们对教育精准资助的数据已经有所了解了,接下来我们就要建立模型来进行机器学习了. 一.机器学习之分类概 ...
- 【2021杭电多校赛】2021“MINIEYE杯”中国大学生算法设计超级联赛(3)签到题3题
2021"MINIEYE杯"中国大学生算法设计超级联赛(3) Start Time : 2021-07-27 12:00:00 End Time : 2021-07-27 17:0 ...
- 【2021杭电多校赛】2021“MINIEYE杯”中国大学生算法设计超级联赛(1)签到题15869
2021"MINIEYE杯"中国大学生算法设计超级联赛(1) Start Time : 2021-07-20 12:10:00 End Time : 2021-07-20 17:1 ...
最新文章
- Model Search,了解一下?
- python 搭配 及目录结构
- Express + mongoDB + nodejs
- 2020-11-27
- 六大举措深耕光通信市场
- 服务器双网卡设置安全_服务器的基础知识
- 全局替换安卓应用字体
- HTML/HTML5/CSS/CSS3教程速查手册地址以及如何快速直到webkit的用法
- matlab非线性系统频域标识,基于MATLAB的最小二乘法系统辨识与仿真
- 数据库系统概论(第五版) 王珊 第一章课后习题答案
- Oracle不常用函数
- 机房管理降本增效:Hightopo如何将可视化监控做到行业高阶?
- html超链接下划线改虚线_CSS和html中超链接去掉下划线的方法总结
- Linux Docker镜像上传阿里云和网络配置
- c语言 类型、运算符、表达式
- 智能服装:引爆2016智能穿戴新发展
- 【CO2二氧化碳传感器】senseair S8 LP
- MySQL查询之分组查询
- R 计算时间序列的交叉相关性教程
- 雪峰磁针石博客]渗透测试简介2入侵工具