pyspider architecture--官方文档
原文地址:http://docs.pyspider.org/en/latest/Architecture/
Architecture
This document describes the reason why I made pyspider and the architecture.
Why
Two years ago, I was working on a vertical search engine. We are facing following needs on crawling:
collect 100-200 websites, they may on/offline or change their templates at any time
We need a really powerful monitor to find out which website is changing. And a good tool to help us write script/template for each website.
data should be collected in 5min when website updated
We solve this problem by check index page frequently, and use something like 'last update time' or 'last reply time' to determine which page is changed. In addition to this, we recheck pages after X days in case to prevent the omission.
pyspider will never stop as WWW is changing all the time
Furthermore, we have some APIs from our cooperators, the API may need POST, proxy, request signature etc. Full control from script is more convenient than some global parameters of components.
Overview
The following diagram shows an overview of the pyspider architecture with its components and an outline of the data flow that takes place inside the system.
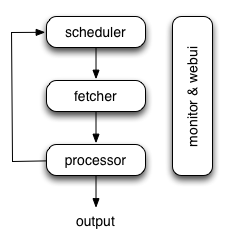
Components are connected by message queue. Every component, including message queue, is running in their own process/thread, and replaceable. That means, when process is slow, you can have many instances of processor and make full use of multiple CPUs, or deploy to multiple machines. This architecture makes pyspider really fast. benchmarking.
Components
Scheduler
The Scheduler receives tasks from newtask_queue from processor. Decide whether the task is new or requires re-crawl. Sort tasks according to priority and feeding them to fetcher with traffic control (token bucket algorithm). Take care of periodic tasks, lost tasks and failed tasks and retry later.
All of above can be set via self.crawl API.
Note that in current implement of scheduler, only one scheduler is allowed.
Fetcher
The Fetcher is responsible for fetching web pages then send results to processor. For flexible, fetcher support Data URI and pages that rendered by JavaScript (via phantomjs). Fetch method, headers, cookies, proxy, etag etc can be controlled by script via API.
Phantomjs Fetcher
Phantomjs Fetcher works like a proxy. It's connected to general Fetcher, fetch and render pages with JavaScript enabled, output a general HTML back to Fetcher:
scheduler -> fetcher -> processor|phantomjs|internet
Processor
The Processor is responsible for running the script written by users to parse and extract information. Your script is running in an unlimited environment. Although we have various tools(like PyQuery) for you to extract information and links, you can use anything you want to deal with the response. You may refer to Script Environment and API Reference to get more information about script.
Processor will capture the exceptions and logs, send status(task track) and new tasks to scheduler, send results to Result Worker.
Result Worker (optional)
Result worker receives results from Processor. Pyspider has a built-in result worker to save result to resultdb. Overwrite it to deal with result by your needs.
WebUI
WebUI is a web frontend for everything. It contains:
- script editor, debugger
- project manager
- task monitor
- result viewer, exporter
Maybe webui is the most attractive part of pyspider. With this powerful UI, you can debug your scripts step by step just as pyspider do. Starting or stop a project. Finding which project is going wrong and what request is failed and try it again with debugger.
Data flow
The data flow in pyspider is just as your seen in diagram above:
- Each script has a callback named
on_start, when you press theRunbutton on WebUI. A new task ofon_startis submitted to Scheduler as the entries of project. - Scheduler dispatches this
on_starttask with a Data URI as a normal task to Fetcher. - Fetcher makes a request and a response to it (for Data URI, it's a fake request and response, but has no difference with other normal tasks), then feeds to Processor.
- Processor calls the
on_startmethod and generated some new URL to crawl. Processor send a message to Scheduler that this task is finished and new tasks via message queue to Scheduler (here is no results foron_startin most case. If has results, Processor send them toresult_queue). - Scheduler receives the new tasks, looking up in the database, determine whether the task is new or requires re-crawl, if so, put them into task queue. Dispatch tasks in order.
- The process repeats (from step 3) and wouldn't stop till WWW is dead ;-). Scheduler will check periodic tasks to crawl latest data.
转载于:https://www.cnblogs.com/davidwang456/p/7577115.html
pyspider architecture--官方文档相关推荐
- dubbo官方文档_狂神说SpringBoot17:Dubbo和Zookeeper集成
狂神说SpringBoot系列连载课程,通俗易懂,基于SpringBoot2.2.5版本,欢迎各位狂粉转发关注学习.未经作者授权,禁止转载 分布式理论 什么是分布式系统? 在<分布式系统原理与范 ...
- Spring 4 官方文档学习 Spring与Java EE技术的集成
本部分覆盖了以下内容: Chapter 28, Remoting and web services using Spring -- 使用Spring进行远程和web服务 Chapter 29, Ent ...
- [Linux Kernel] memory-barriers 内存屏蔽 官方文档
文章目录 DISCLAIMER | 免责声明 CONTENTS | 目录 一.ABSTRACT MEMORY ACCESS MODEL | 抽象内存访问模型 1. DEVICE OPERATIONS ...
- 什么!作为程序员你连英文版的官方文档都看不懂?
目录 一.笔者英文基础介绍 二.为啥程序员需要阅读官方文档? 三.如何才能无障碍阅读英文文档? 四.坚持!坚持!坚持! 五.来个约定吧! 这篇文章不聊技术,我们来聊一个某种程度上比技术更重要的话题:一 ...
- 【开源项目推荐】Android Jetpack 官方文档 中文翻译
Jetpack 是 Android 软件组件的集合,使您可以更轻松地开发出色的 Android 应用.这些组件可帮助您遵循最佳做法.让您摆脱编写样板代码的工作并简化复杂任务,以便您将精力集中放在所需的 ...
- CDH6官方文档中文系列(2)----Cloudera安装指南(安装前)
Cloudera安装指南 最近在学习cdh6的官方文档,网上也比较难找到中文的文档. 其实官方英文文档的阅读难度其实并不是很高,所以在这里在学习官方文档的过程中,把它翻译成中文,在翻译的过程中加深学习 ...
- OpenCV-Python官方文档学习笔记(上)
整理自OpenCV-Python官方文档 一. OpenCV-Python Tutorials 1 安装及验证 2 图片读写,展示 3 视频读写,展示 4 绘图功能(绘制几何形状:线.圆.椭圆.矩形. ...
- Ant Design 入门-参照官方文档使用组件
微信小程序开发交流qq群 173683895 承接微信小程序开发.扫码加微信. 先来一个按钮组件使用的对比,官方文档的(不能直接用)和实际能用的. 官网demo: import { Tabl ...
- 坑爹的微软官方文档:SQL无人值守安装
我在部署项目的时候,需要用批处理无人值守安装SQLserver,.Net等组件. 于是查了微软官方文档,其中一项内容如下: http://msdn.microsoft.com/zh-cn/librar ...
- Tomcat官方文档关于数据源配置的内容
虽然有网上有网友自己总结的文章,但说明得总是不够清晰,还是参考官方文档理解得比较透彻: http://tomcat.apache.org/tomcat-7.0-doc/jdbc-pool.html h ...
最新文章
- C语言的第一例,简单易操作
- python小白逆袭大神课程心得_Python小白逆袭大神学习心得
- 编写程序来模拟计算机LRU算法,操作系统-页式虚拟存储管理程序模拟.doc
- JDK1.10+scala环境的搭建之linux环境(centos6.9)
- Go 如何实现热重启
- 标准模板库(STL) map —— 初始化问题
- 笔记本电脑运行卡顿的真正原因和解决方案
- pfc颗粒linux安装包,离散元颗粒流软件(PFC3D/PFC2D)
- 微信双开方法windows Mac iOS
- verilog实现N分频电路
- flask 蓝本(blueprint)
- blastn 输出结果每列啥意思_本地blast的详细用法
- [分享]RFID之我的M1离线卡爆破过程
- 判断触发器是否被禁用
- office 宏病毒分析
- 关于工程导论的读书计划表
- Koa在实际的业务场景中,路由如何做分割?【文末留言送书】
- php数组的奇数_php数组如何将奇数偶数分开
- python开发h5页面_使用Python的Tornado框架实现一个Web端图书展示页面
- python字典zip函数_Python zip函数及用法
热门文章
- linux驱动 打印变量,linux驱动 内核函数 变量 宏定义
- python缩进的用途和使用方法_如何用Python减少循环层次和缩进的技巧
- android 7 蓝牙版本,[Android]Android什么版本开始支持蓝牙4.2?答案:Android 7.0
- mysql当前时间减一分钟_MySQL数据库事务的机制【总结】
- 新闻与传播c刊_新闻传播类c刊有哪些
- redis 发布订阅实际案例_Redis源码分析之发布订阅+慢查询+排序以及监视器
- python定义字典列表_[Python基础]五、列表、元组和字典
- java rest post list,Java RestTemplate.postForLocation方法代码示例
- 反向传播算法_9.3 反向传播算法的直观理解 Backpropagation Intuition
- bert中的sep_基于向量的深层语义相似文本召回?你需要BERT和Faiss