ai人工智能测面相 准吗_金融界的AI:如何最终开始相信自己的回测[1/3]
ai人工智能测面相 准吗
模拟,风险和度量 (SIMULATIONS, RISKS, AND METRICS)
Note from Towards Data Science’s editors: While we allow independent authors to publish articles in accordance with our rules and guidelines, we do not endorse each author’s contribution. You should not rely on an author’s works without seeking professional advice. See our Reader Terms for details.
Towards Data Science编辑的注意事项: 尽管我们允许独立作者按照我们的 规则和指南 发表文章 ,但我们不认可每位作者的贡献。 您不应在未征求专业意见的情况下依赖作者的作品。 有关 详细信息, 请参见我们的 阅读器条款 。
Quantitative research is a process with many intermediate steps, each of which has to be carefully and thoroughly validated. Asset selection, data collection, feature extraction, modeling — all these phases take time and are delivered and tested by different teams. But what at the end the investor wants to see? That “flawless” backtest on historical data with high Sharpe ratio, alpha with respect to the market, and maybe some fund-related metrics as capacity, leverage, average AUM, etc. However, such an approach doesn’t tell us anything about the future performance of the strategy and such backtests can be easily overfitted and are even dangerous when they’re used as a measure of “success” of a trading idea (see more details in my article on financial idea discovery).
定量研究是一个包含许多中间步骤的过程,每个步骤都必须经过仔细而彻底的验证。 资产选择,数据收集,特征提取,建模-所有这些阶段都需要时间,并且由不同的团队交付和测试。 但是最终投资者想看到什么? 对夏普比率较高,相对于市场为alpha的历史数据进行“完美”的回溯测试,也许还有一些与基金有关的指标,例如容量,杠杆,平均AUM等。但是,这种方法没有告诉我们有关如果将策略用作交易想法的“成功”度量,则该策略的未来性能以及此类回测可能很容易被过度拟合,甚至是危险的(请参阅我关于财务想法发现的文章中的更多详细信息)。
There is nothing easier than producing a backtest of a strategy that performs well in the past, but will you risk and bet your capital on it? Most of investors do.
对过去表现良好的策略进行回溯测试,没有比这容易的事了,但是您会冒险并押注您的资本吗? 大多数投资者都这样做。
In the next couple of articles, I would like to completely review the idea of testing the trading strategy itself.
在接下来的几篇文章中,我想完全回顾一下测试交易策略本身的想法。
First, to explain the dangers of a standard approach and show some alternative metrics that give more insights about the strategy performance.
首先,解释标准方法的危险,并展示一些替代指标,这些指标可以提供有关策略绩效的更多见解。
Then, I would like to show how we can get rid of the single walk-forward backtest in favor of simulations, scenarios, and probabilistic interpretations of well-known metrics. This will help us to switch from an analysis of the past to the estimation of future performance.
然后,我想展示如何摆脱已知的单步向前测试,而转向模拟,场景和对已知指标的概率解释 。 这将帮助我们从对过去的分析转变为对未来绩效的估计。
Last but not least, I would like to enrich the notion of risk: normally investors and portfolio managers calculate and take into account the risk of the portfolio, but not of the strategy itself, which leads to the inability to control and understand the strategy in live performance.
最后但并非最不重要的一点是,我想丰富一下风险的概念 :通常,投资者和投资组合经理计算并考虑投资组合的风险,而不是战略本身的风险,这导致无法控制和理解风险。现场表演。
Like most of my recent articles, this one is inspired by books of Dr. López De Prado and I recommend them to dive deeper into the topic. As always, the source could you can find on my GitHub.
像我最近的大多数文章一样,该文章的灵感来自洛佩兹·德普拉多(LópezDe Prado)博士的书,我建议他们更深入地研究该主题。 与往常一样,您可以在我的GitHub上找到源。
回测的危险 (Dangers of Backtesting)
In 2014 a team of practitioners at Deutsche Bank, led by Yin Luo, released a work called “Seven Sins of Quantitative Investing”. It talks about things you have most probably already have heard about: survivorship bias, look-ahead bias, storytelling, data snooping, transaction costs, outliers, and short issues. I expect that we already know how to get the right data and process it right, not to look into the future, and perform feature importance analysis instead of explaining random patterns on the backtest.
2014年,在罗德(Yin Luo)的带领下,德意志银行(Deutsche Bank)的一组从业人员发布了名为“ 量化投资的七种罪过 ”的著作。 它谈论的是您可能已经听说过的事情: 生存偏差,先行偏差,讲故事,数据监听,交易成本,异常值和短期问题 。 我希望我们已经知道如何获取正确的数据并正确处理它,而不是展望未来,并进行功能重要性分析,而不是在回测中解释随机模式。



However, to that crucially important list, I would like to add some additional moments that are doubting the idea of the backtest itself:
但是,在这个至关重要的列表中,我想补充一些其他方面,这些问题令人怀疑回测本身的想法 :
It is a single path of a stochastic process. Markets could be described with an extremely complex stochastic process with millions of variables. We could sample different scenarios and outcomes of such a process, but we observe only one that actually happened. We rely on a single outcome of infinity from a tremendously complex system to test a trading algorithm, which is insane by itself.
这是随机过程的单一路径 。 市场可以用极其复杂的随机过程来描述,该过程具有数百万个变量。 我们可以对这种过程的不同场景和结果进行采样,但是我们只能观察到实际发生的情况。 我们 依靠极其复杂的系统中无穷大的单个结果来测试一种交易算法,这本身就是疯狂的。
It doesn’t explain the financial discovery. Backtest tells what could’ve happened in the past, but it doesn’t explain why. Relying on the Sharpe or Sortino rations means staying blindfolded in the world of uncertainty. Alternative approaches such as analysis of feature importance will allow us to build financial theories first and only after testing them with the backtesting or another scheme.
它没有解释金融发现 。 回溯测试可以告诉您过去可能发生的情况,但并不能解释原因。 依靠Sharpe或Sortino的口粮意味着在不确定的世界中蒙上双眼。 诸如功能重要性分析之类的替代方法将使我们能够首先并仅在使用回溯测试或其他方案对其进行测试之后,才能建立财务理论 。
It doesn’t allow us to forecast performance and risks. Your strategy could survive in the crisis of 2008, doesn’t it mean that it could’ve passed the current COVID one easily? How do you know that you didn’t overfit to one particular scenario? Or a particular set of factors? How to estimate exactly the probabilities of such outcomes? The classical backtest doesn’t give an answer to anything of that.
它不允许我们预测性能和风险 。 您的策略可以在2008年的危机中幸存,这是否意味着它可以轻松通过当前的COVID? 您怎么知道您没有过适应某一特定情况? 还是一组特定的因素? 如何准确估计这种结果的可能性 ? 经典的回测并不能给出任何答案。
To summarize, even if we have avoided the deadly sins by the guys from the Deutsche Bank, our backtest tells us only about how some set of rules would’ve performed in the past and nothing else. That’s why it’s crucially important to have a richer strategy evaluation toolkit that allows probabilistic, scenario-based, and risk-focused approach, that we employ at Neurons Lab and which we are going to develop and test out within these couple of articles.
总而言之,即使我们避免了德意志银行(Deutsche Bank)的致命罪行,我们的回测也仅告诉我们过去将执行某些规则,而没有其他结果。 这就是为什么至关重要的一点,那就是拥有更丰富的策略评估工具包,该工具包允许我们在Neurons Lab聘用并打算在这两篇文章中进行开发和测试,以概率,基于场景和以风险为中心的方法 。
基于AI的策略概述 (AI-based strategy overview)
Let’s define a typical forecasting-based strategy: there is a signal source of going long or short on some instrument and we act accordingly. For simplicity, we will perform a typical time series forecasting exercise: taking N previous days, extract the factors, predict price change for the next day, and trade. This is a very primitive scenario, that doesn’t take into account transaction costs, slippage, shorts, take-profit, and stop-loss barriers, but let us focus on the discovery of a market understanding principles first, and on the execution later — we will always have time to discard a strategy because of bad fit to the market/exchange rules.
让我们定义一个典型的基于预测的策略:某种工具上存在做多或做空的信号源,我们将采取相应的行动。 为简单起见,我们将执行典型的时间序列预测活动:前N天,提取因素,预测第二天的价格变化并进行交易。 这是一个非常原始的场景,它没有考虑交易成本,滑点,空头,获利和止损壁垒,但让我们先关注市场理解原理 ,然后再执行-由于不符合市场/交易规则,我们将总是有时间放弃策略。
基础数据 (Underlying data)
Let’s focus on the banking sector and will learn the signals for speculation with such tickers as C, DB, BAC, WFC, and other known banks. Because of their crush in the 2008 crisis, it will be interesting to see how our ML models will deal with this regime change. We will rely mainly on the statistical factors that we will group into 3 categories:
让我们专注于银行业,并使用C,DB,BAC,WFC和其他已知银行的股票行情来学习进行投机的信号。 由于他们在2008年危机中的惨败,我们的机器学习模型将如何应对这种政权变化将非常有趣。 我们将主要依靠统计因素,将其分为三类:
Statistical features: min, max, autocorrelation, and statistical moments
统计特征 :最小,最大,自相关和统计矩
Technical indicators: classical features popular among traders
技术指标 :古典特色在交易者中很受欢迎
“AFML features”: for more details check the celebrated book :)
“ AFML功能” :有关更多详细信息,请参阅著名的书:)
We will extract these factors in rolling window fashion (statistical ones on the fractionally-differentiated time series) and sample inputs and outputs with respect to the iid rule. The input will be rolling features “today”, prediction — fixed horizon close price change for the next day.
我们将以滚动窗口的方式提取这些因子(分数微分时间序列上的统计因子),并根据iid规则采样输入和输出。 输入将是“今天”滚动特征,预测-第二天的固定水平收盘价变化。
预测模型 (Forecasting model)
Following the advice of Dr. López de Prado, we will use the bagging of decision trees, with a correction towards iid sampling. We will expect that ensembling will help to deal with overfitting and tree-based model will help in further feature importance analysis. In general, we want to keep the forecasting model as simple as possible, focusing on the quality of our factor insights.
遵循洛佩斯·德普拉多(Lópezde Prado)博士的建议,我们将使用决策树包装,并针对iid采样进行更正。 我们希望集成将有助于处理过度拟合,而基于树的模型将有助于进一步的特征重要性分析。 总的来说,我们希望使预测模型尽可能简单,并着重于要素洞察的质量。
超参数 (Hyperparameters)
We will train our model on 5 years of data, then trade with this model for the next 3 years and after that repeat the process until the data ends (from 2000 to 2020). This way we supposed to fit to constantly changing regimes at least to some extent.
我们将在5年的数据上训练我们的模型,然后在接下来的3年中使用此模型进行交易,然后重复该过程直到数据结束(从2000年到2020年)。 这样,我们应该至少在某种程度上适合不断变化的政权。
“正常”回测和分析 (“Normal” backtesting and analysis)
Let’s start with Deutsche Bank (DB) ticker and run the above-mentioned strategy and calculate returns, strategy performance, and Sharpe ratio of the benchmark (buy-and-hold) compared to the ML strategy.
让我们从德意志银行(DB)报价器开始,运行上述策略,并计算与ML策略相比基准(买入并持有)的收益,策略绩效和夏普比率。


What about the numbers?
那数字呢?
Average returns: -0.00026 of benchmark, 0.0008 of ML strategy
平均回报率:基准的-0.00026,机器学习策略的0.0008
Sharpe ratio: -0.14 of benchmark, 0.74 of ML strategy
夏普比率:基准的-0.14,机器学习策略的0.74
Looks pretty good, but what actual insights do we get from this backtest? Literally none! Maybe our model just has overfitted to tell “short” signal almost all the time on the bearish market and will fail horribly in the future :) Let’s review more interesting metrics that could help us to understand model’s performance in more detail!
看起来不错,但是从这次回溯测试中我们可以得到什么实际的见解 ? 从字面上看没有 ! 也许我们的模型几乎总是在看跌市场上总是过时地发出“空头”信号,并且将来会严重失败:)让我们回顾一些更有趣的指标,这些指标可以帮助我们更详细地了解模型的性能!
替代指标 (Alternative metrics)
数据统计 (Data statistics)
Feature group importance: showing what data source was important at which moment (market, fundamental, sentiment, alternative), we can detect regimes and partially explain patterns
功能组重要性:显示什么数据源在哪个时刻很重要(市场,基本面,市场情绪,替代方案),我们可以检测到制度并部分解释模式
Feature exposure: if a model relies too much on some particular feature, it can become unreliable in the future. We can track such inconsistencies and consider them as a source of a risk
功能暴露:如果模型过于依赖某些特定功能,则将来可能会变得不可靠。 我们可以跟踪此类不一致之处,并将其视为风险来源
模型统计 (Model statistics)
“Accuracy proxy”: Matthew's correlation coefficient (MCC) is a relatively general measure of “accuracy” of a predictive model that can give insights about how much we can rely on the model. Also, it can be helpful for detecting regimes, where our model is unreliable.
“准确性代理”:马修的相关系数(MCC)是对预测模型的“准确性”的一种相对通用的度量,它可以为我们提供多少依赖模型的见解。 此外,它对于检测模型不可靠的状态也很有帮助。

Model certainty: the model returns probabilities, we can track how confident the predictions are and study how confidence affects risk and returns
模型确定性:模型返回概率,我们可以跟踪预测的置信度,并研究置信度如何影响风险和收益
效率统计 (Efficiency statistics)
Sharpe ratios (annualized, probabilistic, deflated): basic performance metrics that, however, have to be fixed for fat-tail and skewed distributions and multiple testing.
夏普比率 (年化,概率,通货紧缩):基本性能指标,但是必须针对胖尾分布和偏斜分布以及多重测试进行固定。
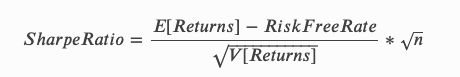


“Smart” Sharpe ratios: we want our strategy to lack autocorrelation, be memoryless, and hence, not have any long burn periods. If we penalize our Sharpe with autocorrelation, it can help us to choose such strategies via optimization.
“智能”夏普比率:我们希望我们的策略缺乏自相关性,没有记忆力,因此没有任何长时间的消耗。 如果我们用自相关惩罚Sharpe,它可以帮助我们通过优化选择此类策略。

Information ratio: this metric helps us to compare our strategy to the underlying or the benchmark beyond the “alpha”. It is the annualized ratio between the average excess return and the tracking error.
信息比率:此指标可帮助我们将我们的策略与超越“ alpha”的基础或基准进行比较。 它是平均超额收益与跟踪误差之间的年化比率。

运行统计 (Runs statistics)
Minimum Required Track Record Length: answers the question “How long should a track record be in order to have statistical confidence that its Sharpe ratio is above a given threshold?” If a track record is shorter than it, we do not have enough confidence that the observed Sharpe ratio is above the designated Sharpe ratio threshold.
最低要求的跟踪记录长度:回答以下问题:“跟踪记录应保持多长时间,才能使统计记录的夏普比率超过给定阈值?” 如果记录短于记录,我们就没有足够的信心确定观察到的夏普比率高于指定的夏普比率阈值。

Drawdown & Time Under Water: investors are interested not only in the risk of the maximum drawdown but also how long they are going to stay there. Combined with data and model statistics it can give insights about why and when the strategy will not perform well.
缩水和水下时间:投资者不仅对最大缩水的风险感兴趣,而且还对将在此停留多长时间感兴趣。 结合数据和模型统计信息,可以深入了解为什么以及何时该策略效果不佳。
泛化统计 (Generalization statistics)
Market generalization: since we aim to operate in a specific sector, we look for the factors that are consistent across different instruments, so we know, that we didn’t “overfit” our discovery just for one single security. There is no standardized way to measure such generalization, so we will improvise :)
市场概括:由于我们的目标是在特定领域运营,因此我们在不同工具之间寻找一致的因素,因此,我们知道,我们并没有仅仅针对一种证券就“过度适应”了我们的发现。 没有标准化的方法可以衡量这种概括,因此我们将即兴发挥:)
新指标和见解 (New metrics and insights)
First, let’s calculate all the above-mentioned metrics both for the benchmark and the strategy on DB ticker:
首先,让我们为基准测试和数据库行情自动收录器策略计算所有上述指标:

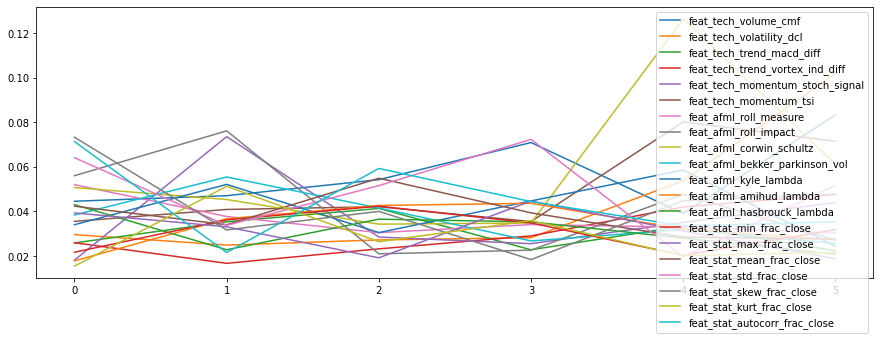
We can see, that in terms of main performance and information value metrics our ML-based strategy indeed outperforms baseline! What about overfitting? Probabilistic SR equals 1.0, which means the discovery is true, and deflated SR (calculated from multiple runs of Bagging model) also equals 1.0 which confirms that our model is also adequate. Average MCC is pretty high and even divided by the standard deviation of MCCs (some sort of SR for accuracy score) has high value. What about feature importance? We can see, that some features are stable at the bottom of the importance, and some are very high. We see empirically, that volume-based factors are performing well on this ticker.
我们可以看到,就主要绩效和信息价值指标而言,我们基于机器学习的策略确实优于基线! 过度拟合怎么办? 概率SR等于1.0,这表示发现是正确的,放气的SR(根据Bagging模型的多次运行计算)也等于1.0,这表明我们的模型也足够。 平均MCC很高,甚至除以MCC的标准偏差(某种形式的SR用于准确性评分)也具有很高的价值。 功能重要性如何? 我们可以看到,某些功能在重要性的底部是稳定的,而某些功能则非常高。 从经验上看, 基于数量的因素在此行情自动收录器中表现良好。

If we already calculate feature importance, why we don’t apply it for making the results better? For example, we could remove the bottom-3 least important features (assuming they mean nothing). Will it change the performance?
如果我们已经计算了功能重要性,为什么不应用它来使结果更好呢? 例如,我们可以删除底部3个最不重要的功能(假设它们没有任何意义)。 会改变性能吗?


Visually we can confirm, that out updated strategy with updated feature set (it’s re-evaluated every 5 years) beats our baseline of ML strategy that uses all the features. From the metrics points of view, we also see the improvement but note the MRTL (Minimum Required Track Record Length) feature that now tells us that we need many more days of observing both strategies to indeed confirm the boost (and it makes sense since they’re extremely correlated). Also, note the drop in the average certainty — removing some features could actually hurt the model.
从视觉上我们可以确认,具有更新功能集的更新策略(每5年进行一次重新评估) 优于使用所有功能的ML策略基线 。 从指标的角度来看,我们也看到了改进,但请注意MRTL(最小所需的记录长度)功能现在告诉我们,我们需要花更多的时间来观察这两种策略,以确认增长(这很有意义,因为它们是高度相关的)。 另外,请注意平均确定性的下降-删除某些功能实际上可能会损害模型。

Now we need to ensure that our strategy and hypothesis about the non-linear dependency of given features can hold on other banking tickers.
现在,我们需要确保有关给定功能的非线性依赖性的策略和假设可以适用于其他银行报价。
我们可以推广到其他股票行情吗? (Can we generalize to other tickers?)
BAC代码(美国银行) (BAC ticker (Bank of America))

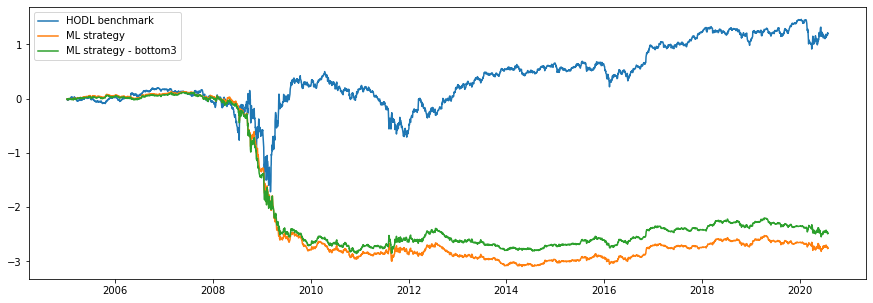


Well… it doesn’t look very well. If we examine the metrics in detail, we can see that this is a clear fault of ML models. “Important” features also differ a lot from the Deutsche Bank example. Maybe it’s just one outlier, let’s try the next one!
好吧……看起来不太好。 如果我们详细检查指标,我们可以看到这显然是ML模型的错误。 “重要”功能也与德意志银行的示例有很大不同。 也许只是一个异常值,让我们尝试下一个异常值!
WFC代码(Wells Fargo&Co) (WFC ticker (Wells Fargo & Co))




The next try is also not profitable at all! However, here the situation is even more tricky: MCC metrics are not negative (even very close to zero), but strategy performance is horrible. Let’s check more examples, but for now, it’s worth considering the idea that Deutsche Bank's example was just a lucky one.
下次尝试也完全没有利润! 但是,这里的情况更加棘手:“我的客户中心”指标不是负数(甚至非常接近零),但是战略绩效却很糟糕。 让我们检查更多示例,但就目前而言,值得考虑的是德意志银行的示例只是一个幸运的例子。
C代码(城市组) (C ticker (City Group))




Check the graphs! Do you see it? Finally, we got it right! Wait, let me check that deflated SR? Zero? Sign of overfitting… and what about MCCs? Again close to zero! Do we really think that a model that is almost random could beat our benchmark so good? No way we can trust this result!
检查图表! 你看到了吗? 最后,我们做对了! 等待,让我检查一下放气的SR? 零? 过度拟合的迹象……而MCC呢? 再次接近零! 我们真的认为几乎是随机的模型可以超越我们的基准吗? 我们绝对不能相信这个结果!
CS(瑞士信贷集团股份公司) (CS (Credit Suisse Group AG))
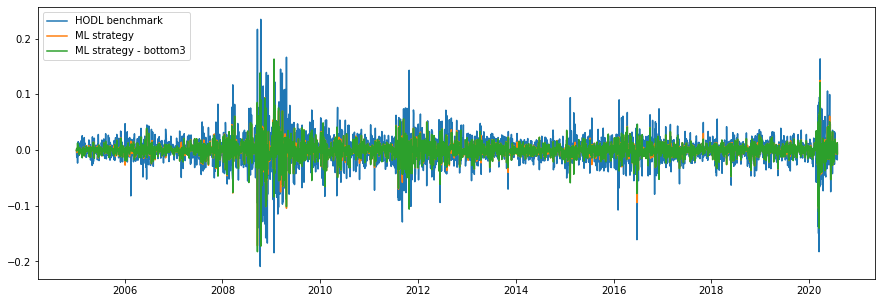


Alright, if it worked so well on DB, maybe it is about being in Europe? Let’s check Credit Suisse stocks then! And… we fail again :)
好吧,如果它在DB上运行良好,也许是在欧洲? 那么,让我们检查一下瑞士信贷股票吧! 而且……我们再次失败了:)
汇丰银行(HSBC Holdings plc) (HSBC (HSBC Holdings plc))




Just for curiosity, I’ve tried the strategy with another European bank — HSBC, and visually it looked very positive, but again, the devil lies in the model performance and MCCs — we just got lucky here again with ML models that actually didn’t learn anything useful.
出于好奇,我曾与另一家欧洲银行汇丰银行(HSBC)尝试过该策略,从外观上看,它非常积极,但同样,魔鬼在于模型性能和MCC。没有学到任何有用的东西。
ING(ING Groep NV) (ING (ING Groep NV))




I wanted to finish experiments on a positive note, however, miracles, if happen, not in quantitative finance, especially if we measure everything right ;) Good-looking from the performance and MCC strategy, unfortunately, has deflated SR of zero — a big chance of not performing well out-of-sample. Also, it performs worse with removed bottom features, which is weird by itself.
我想以积极的姿态完成实验,但是,如果发生奇迹,可能不是量化金融,特别是如果我们正确地衡量一切的话;)绩效和MCC策略的好看,不幸的是,SR降低了零,这是很大的样本中表现不佳的机会。 而且,它在删除了底部功能后效果更差,这本身就很奇怪。
结论 (Conclusions)
The main outcome of the work we did is straightforward — we have learned how to evaluate a backtest of an ML-based strategy from many more dimensions than we used to. We need to fight overfitting, multiple comparisons, and “black-boxness” of our models and to fix these issues we need to spot them first. New proposed statistics do the following:
我们所做工作的主要结果很简单-我们已经学会了如何从比以往更多的角度评估基于ML的策略的回测。 我们需要克服模型的过度拟合,多重比较和“黑匣子”问题,并解决这些问题,我们需要首先发现它们。 拟议的新统计数据执行以下操作:
explain factors in the data even with non-linear models
即使使用非线性模型也可以解释数据中的因素
explain the connection between model and strategy performance
解释模型与策略绩效之间的联系
enrich the notion of “beating the benchmark”
丰富“超越基准”的概念
give a hint about generalization and overfitting
给出有关泛化和过度拟合的提示
However, the results were discouraging but I hope, no one expected that we can actually beat the market and create new economic findings with a couple of formulas from the book :) Checking important features we could see, that there is no consensus between different tickers — all the time different factors are in the top, which doesn’t allow us to build a strong theory about statistical factors that drive banking stocks. What we could do to actually make it right?
但是,结果令人沮丧,但我希望,没有人期望我们可以用书中的几个公式来真正击败市场并创造新的经济发现:)检查我们可以看到的重要特征,不同的报价器之间没有共识—始终有不同的因素排在首位,这使我们无法建立有关驱动银行股的统计因素的强有力的理论 。 我们可以做些什么来使其正确?
Find new features that define differences between banks — fundamentals, macro, alternative data — in 2020 it’s not very smart to rely on statistical factors ;)
查找定义银行之间差异的新功能 -基本面,宏,替代数据-到2020年,依靠统计因素并不是很明智;)
Change hyperparameters — who said that 5 years for training, 3 years for trading, 14 days averaging window, etc and correct numbers? We need actually to run a hyperparameter search to find optimal values. We will check it in detail in the next post, meanwhile, check this article of mine (many mistakes here and there, but the search part is correct)
更改超参数 -谁说训练5年,交易3年,平均窗口14天等,并确定数字? 实际上,我们需要运行超参数搜索以找到最佳值。 我们将在下一篇文章中对其进行详细检查,同时,请检查我的这篇文章 (这里和那里有很多错误,但是搜索部分是正确的)
Work more on feature importance — we see that almost in every case removing that bottom features helps ML strategy a bit. Maybe we need to remove more? Or apply a better algorithm for feature importance? Or since we observe overfitting, maybe we can remove not only the bottom but also top features? ;)
在功能重要性上做更多的工作-我们看到几乎在每种情况下,删除底部功能都会对ML策略有所帮助。 也许我们需要删除更多? 还是针对特征重要性应用更好的算法? 还是因为我们观察到过度拟合,也许我们不仅可以移除底部特征,还可以移除顶部特征? ;)
In the next blog post, we will dive much deeper into the notions we have introduced today. Instead of calculation of those numbers on one historical dataset, we will develop schemes for simulations and data augmentations and will come up not with the point estimates, but with probabilistic interpretations. Who knows, maybe our models performed badly on one time series realization, but at the scale, they’re pretty reliable? Stay tuned and don’t forget to check out the source code :)
在下一篇博客文章中,我们将更深入地介绍我们今天介绍的概念。 代替在一个历史数据集上计算这些数字,我们将开发用于模拟和数据扩充的方案,并且不会提出点估计,而是提出概率解释。 谁知道,也许我们的模型在一个时间序列的实现上表现不佳,但是从规模上讲,它们是非常可靠的吗? 请继续关注,不要忘记查看源代码 :)
P.S.You also can connect with me on the Facebook blog or Linkedin, where I regularly post some AI articles or news that are too short for Medium and Instagram for some more personal content :)
PS您还可以在Facebook博客或Linkedin上与我联系,我经常在其中发布一些AI文章或新闻,这些文章或新闻对于Medium和Instagram来说太短了,无法提供更多个人内容:)
翻译自: https://towardsdatascience.com/ai-in-finance-how-to-finally-start-to-believe-your-backtests-1-3-1613ad81ea44
ai人工智能测面相 准吗
http://www.taodudu.cc/news/show-4375953.html
相关文章:
- docker学习5-docker安装tomcat环境和部署war包
- 在MMClassification中使用Swin-Transformer开始一个分类任务
- Git学习之旅--撤销与删除
- Docker Swarm学习教程【转载】
- Web安全之SQL注入漏洞学习(一)
- java并发集合框架学习记录
- Celery 全面学习笔记
- 探索学习:网红容器引擎Docker
- Docker学习笔记 — Swarm搭建Docker集群
- docker学习至docker-compose
- Flutter学习笔记 —— 完成一个简单的新闻展示页
- AutoLeaders控制组——五一单片机学习笔记(一)
- MySQL--基础知识点--51--dual
- 思科新版ccnp中教你如何EIGRP协议DUAL弥散更新算法简述
- C语言1.5e10什么意思,汽车排量1.5e是什么意思
- 自己写的代码太low?想提升代码质量但是不知道怎么做?IDEA安这个插件~
- 点评阿里云盛大云代表的云计算IaaS产业---中国云计算
- 她二本科毕业,拿到阿里年薪40万offer!经验都记录在这几个公众号日记中
- 多个excel合并到一个excel的不同sheet中
- Rust 社区 RFC 导读 | 构建安全的 I/O
- VB.net 删除文件、文件夹
- 多个excel快速合并到一个excel的多个sheet
- Android Studio使用技巧系列教程(二)
- 小学计算机基础知识题目,小学信息技术基础知识复习题(清华版第三册)
- 软件测试Selenium-API 操作(上机练习文档)分享
- Android Studio使用技巧系列教程(四)
- 第二章 Selenium-API操作
- Android Studio使用技巧系列教程(七)
- selenium+python:元素定位的八种方式
- Web自动化测试02
ai人工智能测面相 准吗_金融界的AI:如何最终开始相信自己的回测[1/3]相关推荐
- ai人工智能测面相 准吗_对AI的信任值得信赖吗?
ai人工智能测面相 准吗 In my last article on Trust in AI, I wrote about how building trust in AI needs to incl ...
- YDOOK: 学习 AI 人工智能需要必备哪些数学知识?学AI需要学习的数学书与领域
学习 AI 人工智能需要必备哪些数学知识?学AI需要学习的数学书与领域 1 数学分析,较低要求为高等数学 2 高等线性代数,较低要求为线性代数,空间解析几何 3 概率论.数理统计 与 随机过程 4 张 ...
- ai人工智能的本质和未来_人工智能的未来在于模型压缩
ai人工智能的本质和未来 The future looks towards running deep learning algorithms on more compact devices as an ...
- ai人工智能在手机的应用_常识在人工智能中仍然不常见
ai人工智能在手机的应用 Tassilo Klein and Moin Nabi (SAP AI Research) Tassilo Klein和Moin Nabi(SAP AI研究) Deep le ...
- ai人工智能的本质和未来_是人工智能手中的网络安全的未来AI 1
ai人工智能的本质和未来 Chinese philosophy yin and yang represent how the seemingly opposite poles can compleme ...
- ai人工智能的本质和未来_人工智能手中的网络安全的未来
ai人工智能的本质和未来 A recent Synack Report claims that combining cybersecurity talent and AI-enabled techno ...
- ai人工智能的本质和未来_是人工智能手中网络安全的未来AI 3
ai人工智能的本质和未来 The Use of Artificial Intelligence for Cyber Defense 人工智能在网络防御中的应用 The possible cyber d ...
- ai人工智能在手机的应用_强化学习在人工智能中的应用
ai人工智能在手机的应用 The reinforcement learning is being used in many Intelligent Systems and the developers ...
- ai人工智能在手机的应用_何时更重要地在产品中利用人工智能
ai人工智能在手机的应用 You need to go from your house to the Airport. Do you take a Limo or a bike? Of course ...
最新文章
- 在Linux中同时删除一百万个小文件的最快方法
- Linux之LVM与磁盘配额(quota)详解
- 学习node js 之微信公众帐号接口开发 准备工作之三
- java 12错误_Java异常处理的12条军规总结
- ThinkPHP6项目基操(8.多应用模式)
- 在preferences窗口找不到要运行的tomcat_基于docker安装tomcat例子
- iOS 仿支付宝密码支付
- 删除Chrome自动完成功能的输入背景色?
- android 退出应用没有走ondestory方法,[Android基础论]为何Activity退出之后,系统没有调用onDestroy方法?...
- NOI题库 CSP-J 历年真题 蓝桥杯 Scratch 代码等-2022.03.15
- 基于php校园官方网站的背景,校园微信平台的设计
- 树形DP·1771仓库选址
- ImageNet数据集 下载
- c语言中如何将字体弄大,CFree怎样调大字体
- 如何虚拟机里安装win7操作系统
- favicon.ico介绍,网页图标的制作动态网页图标
- 华为mate40pro鸿蒙冷散热,华为mate40pro曝光,2K屏+麒麟9000+鸿蒙系统+双6400万,售价感人...
- PKCS#11标准解读-Cryptoki库如何工作
- 离散控制 discrete control
- 图像处理------简单综合实例(大米计数)