蚂蚁金服开源服务注册中心 SOFARegistry
SOFAStack(Scalable Open Financial Architecture Stack )是蚂蚁金服自主研发的金融级分布式架构,包含了构建金融级云原生架构所需的各个组件,是在金融场景里锤炼出来的最佳实践。
本文根据 SOFA Meetup#1 北京站 现场分享整理,完整的分享 PPT 获取方式见文章底部。
SOFAStack 开源一周年,继续补充开源大图
2018 年 4 月, 蚂蚁金服宣布开源 SOFAStack 金融级分布式架构。这一年的时间,感谢社区的信任和支持,目前已经累积超过一万的 Star 数目,超过 30 家企业用户。
SOFARegistry 是蚂蚁金服开源的具有承载海量服务注册和订阅能力的、高可用的服务注册中心,最早源自于淘宝的初版 ConfigServer,在支付宝/蚂蚁金服的业务发展驱动下,近十年间已经演进至第五代。
GitHub 地址:https://github.com/alipay/sofa-registry
概念
注册中心在微服务架构中位置
服务发现,并非新鲜名词,在早期的 SOA 框架和现在主流的微服务框架中,每个服务实例都需要对外提供服务,同时也需要依赖外部服务。如何找到依赖的服务(即服务定位),最初我们思考了很多方式,比如直接在 Consumer 上配置所依赖的具体的服务地址列表,或者使用 LVS、F5 以及 DNS(域名指向所有后端服务的 IP)等负载均衡。
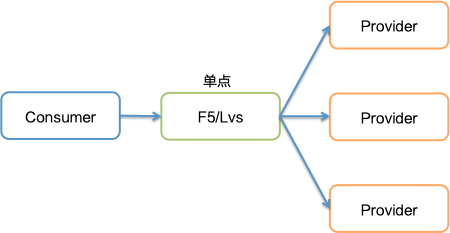
但是以上方式都有明显的缺点,比如无法动态感知服务提供方节点变更的情况,另外基于负载均衡的话还需要考虑它的瓶颈问题。所以需要借助第三方的组件,即服务注册中心来提供服务注册和订阅服务,在服务提供方服务信息发生变化、或者节点上下线时,可以动态更新消费方的服务地址列表信息,最终解耦服务调用方和服务提供方。
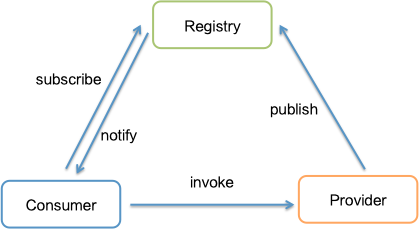
能力
服务注册中心的主要能力:
- 服务注册
- 服务订阅
演进
蚂蚁金服的服务注册中心,经历了 5 代技术架构演进,才最终形成了如今足以支撑蚂蚁海量服务注册订阅的,具有高可用、高扩展性和高时效性的架构。
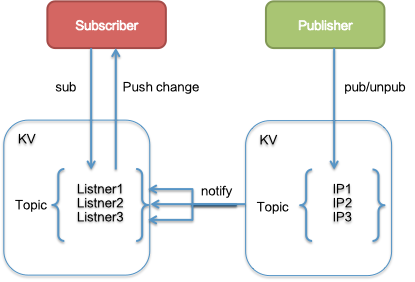
数据结构
SOFARegistry 的存储模型比较简单,主要基于 KV 存储两类数据,一类是订阅关系,体现为多个订阅方关心的 Topic(或服务键值)和他们的监听器列表,另一类是同一个 Topic(或服务键值)的发布者列表。基于观察者模式,在服务提供方发生变化时(比如服务提供方的节点上下线),会从订阅关系中寻找相应的订阅者,最终推送最新的服务列表给订阅者。
存储扩展
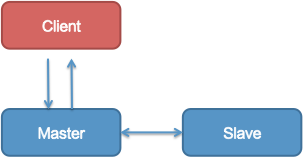
主备模式
- 既然服务注册中心最主要能力之一是存储,那么就要思考:怎么存?存哪儿?存了会不会丢?
- 怎么存,主要是由存什么数据来决定的,由于 SOFARegistry 所存储的数据结构比较简单( KV),因为并没有基于关系数据库;另外由于服务发现对变更推送的时效性要求高,但并没有很高的持久化要求(数据可以从服务提供方恢复),所以最终我们决定自己实现存储能力。
- SOFARegistry 的存储节点,最初是主备模式。
强一致集群
随着蚂蚁的服务数据量不断增长,我们将存储改为集群方式,每个存储节点的数据是一样的,每一次写入都保证所有节点写入成功后才算成功。这种模式的特点是每台服务器都存储了全量的服务数据,在当时数据规模比较小的情况下,尚可接受。
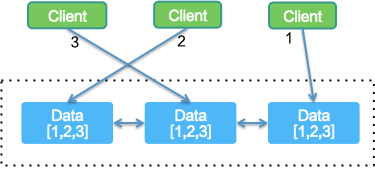
这样的部署结构有两个问题:
- 首先,根据 CAP 原理,在分区容忍性(P)的前提下,为了保持强一致(C),必然牺牲高可用(A)为代价,比如 Zookeeper 是 CP 系统,它在内部选举期间是无法对外提供服务的,另外由于需要保证 C(顺序一致性),写的效率会有所牺牲。
- 其次,每个节点都存储全量的服务数据,随着业务的发展就有很大的瓶颈问题。
数据分片
如果要实现容量可无限扩展,需要把所有数据按照一定维度进行拆分,并存储到不同节点,当然还需要尽可能地保证数据存储的均匀分布。我们很自然地想到可以进行 Hash 取余,但简单的取余算法在节点数增减时会影响全局数据的分布,所以最终采用了一致性 Hash 算法(这个算法在业界很多场景已经被大量使用,具体不再进行介绍)。
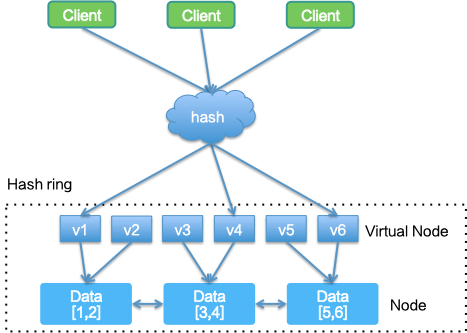
每个服务数据,经过一致性 Hash 算法计算后会存储到某个具体的 Data 上,整体形成环形的结构。理论上基于一致性 Hash 对数据进行分片,集群可以根据数据量进行无限地扩展。
内部分层
连接承载
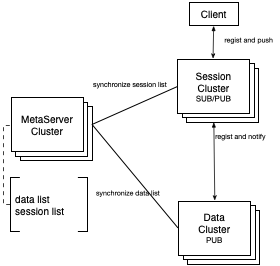
我们知道单机的 TCP 连接数是有限制的,业务应用不断的增多,为了避免单机连接数过多,我们需要将存储节点与业务应用数量成正比地扩容,而我们实际上希望存储节点的数量只跟数据量成正比。所以我们选择从存储节点上把承载连接职责的能力独立抽离出来成为新的一个角色,称之为 Session 节点,Session 节点负责承载来自业务应用的连接。这么一来,SOFARegistry 就由单个存储角色被分为了 Session 和 Data 两个角色,Session 承载连接,Data 承载数据,并且理论上 Session 和 Data 都支持无限扩展。
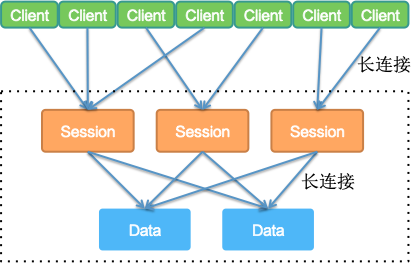
如图,客户端直接和 Session 层建立连接,每个客户端只选择连接其中一个 Session 节点,所有原本直接到达 Data层的连接被收敛到 Session 层。Session 层只进行数据透传,不存储数据。客户端随机连接一台 Session 节点,当遇到 Session 不可用时重新选择新的 Session 节点进行重连即可。
读写分离
分离出 Session 这一层负责承载连接,引起一个新的问题:数据到最终存储节点 Data 的路径变长了,整个集群结构也变的复杂了,怎么办呢?
我们知道,服务注册中心的一个主要职责是将服务数据推送到客户端,推送需要依赖订阅关系,而这个订阅关系目前是存储到 Data 节点上。在 Data 上存储订阅关系,但是 Client 并没有直接和 Data 连接,那必须要在 Session 上保存映射后才确定推送目标,这样的映射关系占据了大量存储,并且还会随 Session 节点变化进行大量变更,会引起很多不一致问题。
因此,我们后来决定,把订阅关系信息(Sub)直接存储在 Session 上,并且通过这个关系 Session 直接承担把数据变化推送给客户端的职责。而对于服务的发布信息(Pub)还是通过 Session 直接透传最终在 Data 存储节点上进行汇聚,即同一个服务 ID 的数据来自于不同的客户端和不同的 Session 最终在 Data 的一个节点存储。
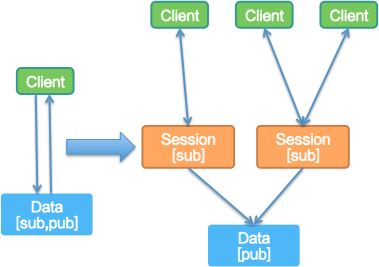
这样划分了 Sub 和 Pub 数据之后,通过订阅关系(Sub)进行推送的过程就有点类似于对服务数据读取的过程,服务发布进行存储的过程有点类似数据写的过程。数据读取的过程,如果有订阅关系就可以确定推送目标,迁移订阅关系数据到 Session,不会影响整个集群服务数据的状态,并且 Client 节点连接新的 Session 时,也会回放所有订阅关系,Session 就可以无状态的无限扩展。
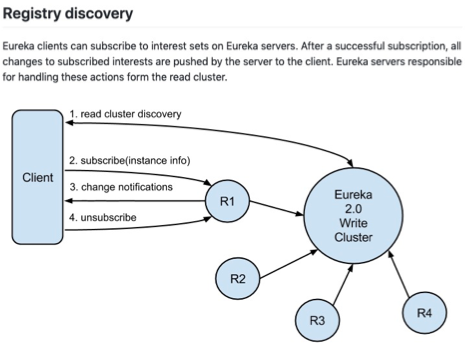
其实这个读写集群分离的概念,在 Eureka2.0 的设计文档上也有所体现,通常读取的需求比写入的需求要大很多,所以读集群用于支撑大量订阅读请求,写集群重点负责存储。
高可用
数据回放
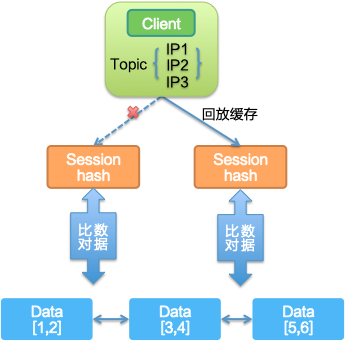
数据备份,采用逐级缓存数据回放模式,Client 在本地内存里缓存着需要订阅和发布的服务数据,在连接上 Session 后会回放订阅和发布数据给 Session,最终再发布到 Data。
另一方面,Session 存储着客户端发布的所有 Pub 数据,定期通过数据比对保持和 Data 一致性。
多副本
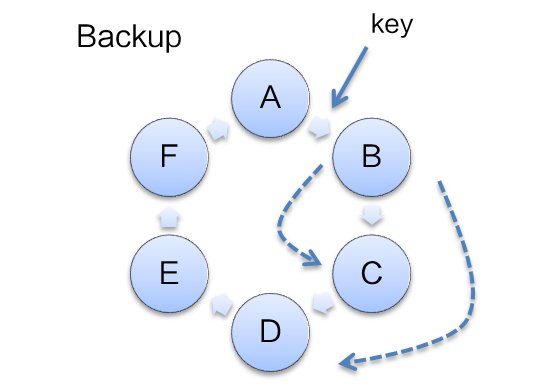
上述提到的数据回放能力,保证了数据从客户端最终能恢复到存储层(Data)。但是存储层(Data)自身也需要保证数据的高可用,因为我们对存储层(Data)还做了数据多副本的备份机制。如下图:
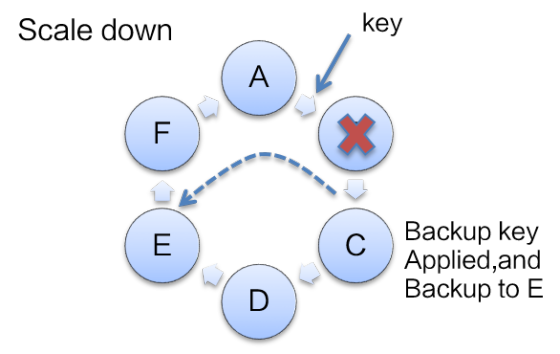
当有 Data 节点缩容、宕机发生时,备份节点可以立即通过备份数据生效成为主节点,对外提供服务,并且把相应的备份数据再按照新列表计算备份给新的节点 E。
当有 Data 节点扩容时,新增节点进入初始化状态,期间禁止新数据写入,对于读取请求会转发到后续可用的 Data 节点获取数据。在其他节点的备份数据按照新节点信息同步完成后,新扩容的 Data 节点状态变成 Working,开始对外提供服务。
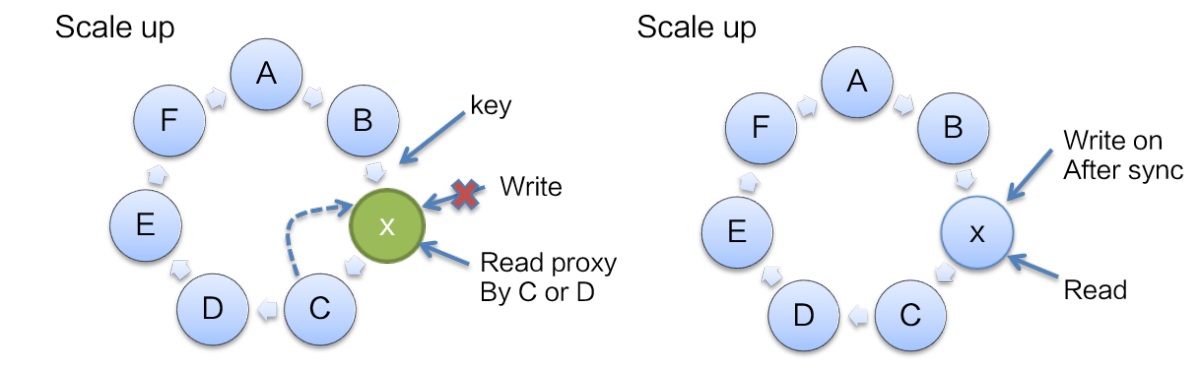
数据同步
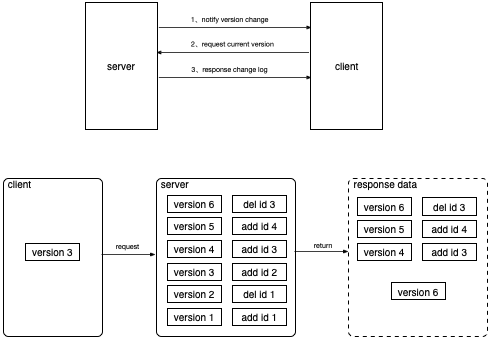
数据备份、以及内部数据的传递,主要通过操作日志同步方式。
持有数据一方的 Data 发起变更通知,需要同步的 Client 进行版本对比,在判断出数据需要更新时,将拉取最新的数据操作日志。
操作日志存储采用堆栈方式,获取日志是通过当前版本号在堆栈内所处位置,把所有版本之后的操作日志同步过来执行。
元数据管理
上述所有数据复制和数据同步都需要通过一致性 Hash 计算,这个计算最基本的输入条件是当前集群的所有 Data节点列表信息。所以如何让集群的每个节点能感知集群其他节点的状态,成为接下来需要解决的问题。
最初,我们直接将“Data 地址列表信息” 配置在每个节点上,但这样不具体动态性,所以又改为通过 DRM(蚂蚁内部的动态配置中心)配置,但是这样仍需要人为维护,无法做到自动感知。
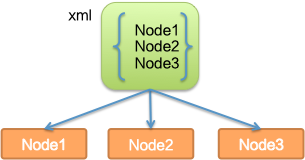
后续又想到这个集群列表通过集群内节点进行选举出主节点,其他节点直接上报给主节点,主节点再进行分发,这样主节点自身状态成为保证这个同步成功的关键,否则要重新选举,这样就无法及时通知这个列表信息。
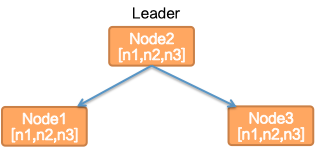
最后我们决定独立一个角色进行专职做集群列表信息的注册和发现,称为 MetaServer。Session 和 Data 每个节点都在 MetaServer 上进行注册,并且通过长连接定期保持心跳,这样可以明确各个集群节点的变化,及时通知各个其他节点。
我们的优势
目前,SOFARegistry 可以支撑如下的数据量:
- 2000+ 应用 2.3w 服务注册发现;
- 单机房 Data 集群支持百万级 Pub 数据,千万级 Sub 数据;
- 高可用,集群宕机 ½ 以内节点服务自恢复;
- 支持数百应用同时启动发布订阅。
SOFARegistry 与开源同类产品的比较:
| 比较 | SOFARegistry | Eureka 1.0 | ZooKeeper |
|---|---|---|---|
| 一致性 | 最终一致 | 最终一致 | 强一致 |
| 可用性 | 高可用,集群节点可动态扩缩容,数据保持多副本 | 高可用 | 节点选举过程整个集群不可用,无法提供服务 |
| 可扩展 | 一致性 Hash 数据分片,理论上无限制扩展 | 数据节点相互同步方式保持一致,有上限瓶颈 | 数据强一致,同样存在上限 |
| 时效性 | 秒级服务发现,通过连接状态进行服务数据变更通知 | 采用长轮询健康检查方式获取节点状态,时效不敏感 | 强一致要求,多写效率低 |
将来
挑战
- 面向现有主流微服务框架。目前主流微服务框架需要我们进行适配,比如 SpringCloud、Dubbo 等,这些框架在服务发现方面有一定的规范可以进行遵循后接入,对于适应性有所增强。此外对于云上很多服务发现组件可以进行对接比如 Cloudmap 等。
- 面向云原生微服务运维。众所周知,服务注册中心的运维非常复杂,必须要有特定的运维发布方式来严格控制步骤,否则影响是不可逆的。我们也进行了大量的运维尝试,做了很多状态划分保持整个集群发布的顺畅,后续云原生和 k8s 接入必将对传统的运维方式进行变革,这个过程要求我们产品自身可以微服务化、镜像化才能适应容器运维的需求,并且需要考虑新的数据一致性方式。
- 面对单元化部署。单元化其实在蚂蚁内部已经大规模实践,服务注册中心在这里承载的职责尤为重要,当前我们对多机房多城市等部署模式在数据结构上已经进行开放,但是对于机房间一些特定功能考虑进一步开放和完善。
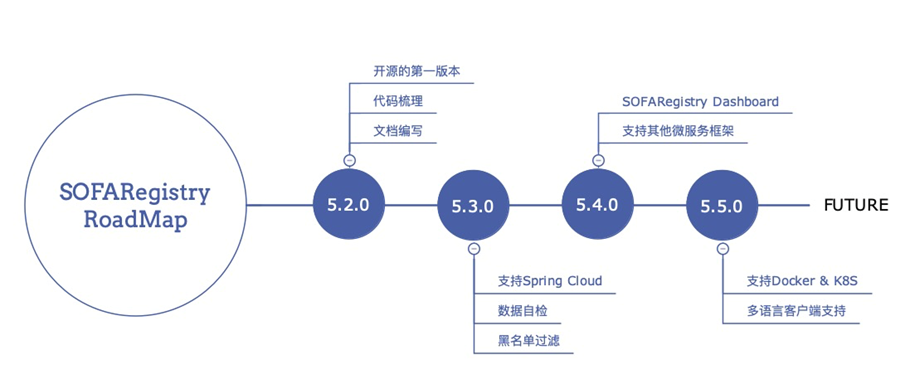
Roadmap
一些新的 Feature 规划和上述过程的开源路径:
总结
以上就是本期分享的所有内容。当前,代码已开源托管在 GitHub 上,欢迎关注,同时也欢迎业界爱好者共同创造更好的 SOFARegistry。
- GitHub 项目地址:
https://github.com/alipay/sofa-registry - 本期分享 PPT 获取地址:
https://www.sofastack.tech/posts/2019-03-27-01
蚂蚁金服开源服务注册中心 SOFARegistry相关推荐
- 蚂蚁金服服务注册中心 SOFARegistry 解析
SOFAStack (Scalable Open Financial Architecture Stack)是蚂蚁金服自主研发的金融级分布式架构,包含了构建金融级云原生架构所需的各个组件,是在金融场景 ...
- 蚂蚁金服服务注册中心 SOFARegistry 解析 | 服务发现优化之路
SOFAStack Scalable Open Financial Architecture Stack 是蚂蚁金服自主研发的金融级分布式架构,包含了构建金融级云原生架构所需的各个组件,是在金融场景 ...
- 蚂蚁金服开源增强版 Spring Boot 的研发框架!
点击上方蓝色"方志朋",选择"设为星标" 回复"666"获取独家整理的学习资料! 来源:gitee.com/sofastack/sofa-b ...
- 蚂蚁金服开源增强版Spring Boot 的研发框架!
点击上方蓝色"方志朋",选择"设为星标" 回复"666"获取独家整理的学习资料! SOFABoot 是蚂蚁金服开源的基于 Spring Bo ...
- SOFABoot是蚂蚁金服开源的基于Spring Boot的研发框架
前言 SOFABoot是蚂蚁金服开源的基于Spring Boot的研发框架,它在Spring Boot的基础上,提供了诸如 Readiness Check,类隔离,日志空间隔离等等能力.在增强了 Sp ...
- 蚂蚁金服开源了这一款研发框架!还是增强版的
点击"开发者技术前线",选择"星标????" 在看|星标|留言, 真爱 来源:gitee.com/sofastack/sofa-boot 增强 Spring ...
- 蚂蚁金服安全应急响应中心上线 用户可提交漏洞
蚂蚁金服安全应急响应中心(AFSRC)已于今日上线.该平台旨在集合安全领域的专家.白帽子.社会团体及个人共同发现潜在的漏洞信息,并依此建立漏洞统计分析中心,预知并自查风险,及时修复漏洞,帮助提升自身产 ...
- 开源|蚂蚁金服开源AntV F2:一个专注于移动,开箱即用的可视
小蚂蚁说: AntV 是蚂蚁金服全新一代数据可视化解决方案,主要子产品包括 G2.G6.F2.此前我们已经相继发布过AntV的相关开源消息与版本迭代,包括<蚂蚁金服开源:数据驱动的高交互可视化图 ...
- 蚂蚁金服开源的机器学习工具 SQLFlow,有何特别之处?
近日,蚂蚁金服副 CTO 胡喜正式宣布开源机器学习工具 SQLFlow,他在大会演讲中表示:"未来三年,AI 能力会成为每一位技术人员的基本能力.我们希望通过开源 SQLFlow,降低人工智 ...
最新文章
- 【目标检测】yolo系列:从yolov1到yolov5之YOLOv5训练自己数据集(v6.0)
- 关于socket阻塞与非阻塞情况下的recv、send、read、write返回值
- 【MM模块】ASAP 项目实施方法简介
- Citrix XenServer XenCenter 警报
- 深度学习(1)深度学习初见
- Centos7 使用Docker 部署Nginx+mysql+tomcat+调试联通_03
- android pdf阅读器开发_如何在 Windows 10 中将 Firefox 设置为默认 PDF 阅读器
- Ubuntu16.04下部署 nginx+uwsgi+django1.9.7(虚拟环境pyenv+virtualenv)
- java js 解析器_graphqljs具有多个参数的解析器
- Path接口与Files工具类
- Windows Azure Cloud Service (6) Reboot and Reimage
- visio添加连接点
- 刘宇凡:一棵树给我的真理
- 草枯树荣,让生命活得云淡风轻
- 任意重循环(循环阶数不定、循环层数不定)
- 台式机安装Windows11正式版(跳过TPM)
- 海康威视2022 校招/社招/实习 内推WHM8BQ
- tcp 如何维护长连接
- Mysql int(10) int(11) 字符长度的设置
- geogebra使用技巧