pySpark | pySpark.Dataframe使用的坑 与 经历
笔者最近在尝试使用PySpark,发现pyspark.dataframe跟pandas很像,但是数据操作的功能并不强大。由于,pyspark环境非自建,别家工程师也不让改,导致本来想pyspark环境跑一个随机森林,用 《Comprehensive Introduction to Apache Spark, RDDs & Dataframes (using PySpark) 》中的案例,也总是报错…把一些问题进行记录。
1 利于分析的toPandas()
介于总是不能在别人家pySpark上跑通模型,只能将数据toPandas(),但是toPandas()也会运行慢 运行内存不足等问题。
1.1 内存不足
报错: tasks is bigger than spark.driver.maxResultSize 一般是spark默认会限定内存,可以使用以下的方式提高:
set by SparkConf: conf.set("spark.driver.maxResultSize", "3g")
set by spark-defaults.conf spark.driver.maxResultSize 3g
set when callingspark-submit --conf spark.driver.maxResultSize=3g解决方案来源:spark - tasks is bigger than spark.driver.maxResultSize
1.2 运行慢,如何优化性能
笔者主要是在toPandas()发现性能很慢,然后发现该篇博文:Spark toPandas() with Arrow, a Detailed Look提到了如何用spark.Arrow 去优化效率。
1.2.1 Using Arrow to Optimize Conversion
来看看本来运行一段.toDF的code耗时在哪。
from pyspark.sql.functions import rand
df = spark.range(1 << 22).toDF("id").withColumn("x", rand())
pandas_df = df.toPandas()那么主要的耗时在:
ncalls tottime percall cumtime percall filename:lineno(function)1 0.000 0.000 23.013 23.013 <string>:1(<module>)1 0.456 0.456 23.013 23.013 dataframe.py:1712(toPandas)1 0.092 0.092 21.222 21.222 dataframe.py:439(collect)81 0.000 0.000 20.195 0.249 serializers.py:141(load_stream)81 0.001 0.000 20.194 0.249 serializers.py:160(_read_with_length)80 0.000 0.000 20.167 0.252 serializers.py:470(loads)80 3.280 0.041 20.167 0.252 {cPickle.loads}4194304 1.024 0.000 16.295 0.000 types.py:1532(<lambda>)4194304 2.048 0.000 15.270 0.000 types.py:610(fromInternal)4194304 9.956 0.000 12.552 0.000 types.py:1535(_create_row)4194304 1.105 0.000 1.807 0.000 types.py:1583(__new__)1 0.000 0.000 1.335 1.335 frame.py:969(from_records)1 0.047 0.047 1.321 1.321 frame.py:5693(_to_arrays)1 0.000 0.000 1.274 1.274 frame.py:5787(_list_to_arrays)165 0.958 0.006 0.958 0.006 {method 'recv' of '_socket.socket' objects}4 0.000 0.000 0.935 0.234 java_gateway.py:1150(__call__)4 0.000 0.000 0.935 0.234 java_gateway.py:885(send_command)4 0.000 0.000 0.935 0.234 java_gateway.py:1033(send_command)4 0.000 0.000 0.934 0.234 socket.py:410(readline)4194304 0.789 0.000 0.789 0.000 types.py:1667(__setattr__)1 0.000 0.000 0.759 0.759 frame.py:5846(_convert_object_array)2 0.000 0.000 0.759 0.380 frame.py:5856(convert)2 0.759 0.380 0.759 0.380 {pandas._libs.lib.maybe_convert_objects}4194308 0.702 0.000 0.702 0.000 {built-in method __new__ of type object at 0x7fa547e394c0}4195416 0.671 0.000 0.671 0.000 {isinstance}4194304 0.586 0.000 0.586 0.000 types.py:1531(_create_row_inbound_converter)1 0.515 0.515 0.515 0.515 {pandas._libs.lib.to_object_array_tuples}可以看到很多时间都是花在deserializer上面。
那么应用了Arrow就不一样,原文作者的原话:Because Arrow defines a common data format across different language implementations, it is possible to transfer data from Java to Python without any conversions or processing. ,Apache Arrow:一个跨平台的在内存中以列式存储的数据层,用来加速大数据分析速度。其可以一次性传入更大块的数据,pyspark中已经有载入该模块,需要打开该设置:
spark.conf.set("spark.sql.execution.arrow.enabled", "true")或者也可以在conf/spark-defaults.conf文件中写入:spark.sql.execution.arrow.enabled=true
打开arrow可以看一下效能:
ncalls tottime percall cumtime percall filename:lineno(function)1 0.001 0.001 0.457 0.457 <string>:1(<module>)1 0.000 0.000 0.456 0.456 dataframe.py:1712(toPandas)1 0.000 0.000 0.442 0.442 dataframe.py:1754(_collectAsArrow)53 0.404 0.008 0.404 0.008 {method 'recv' of '_socket.socket' objects}4 0.000 0.000 0.389 0.097 java_gateway.py:1150(__call__)4 0.000 0.000 0.389 0.097 java_gateway.py:885(send_command)4 0.000 0.000 0.389 0.097 java_gateway.py:1033(send_command)4 0.000 0.000 0.389 0.097 socket.py:410(readline)9 0.000 0.000 0.053 0.006 serializers.py:141(load_stream)9 0.000 0.000 0.053 0.006 serializers.py:160(_read_with_length)17 0.001 0.000 0.052 0.003 socket.py:340(read)48 0.022 0.000 0.022 0.000 {method 'write' of 'cStringIO.StringO' objects}13 0.014 0.001 0.014 0.001 {method 'getvalue' of 'cStringIO.StringO' objects}1 0.000 0.000 0.013 0.013 {method 'to_pandas' of 'pyarrow.lib.Table' objects}1 0.000 0.000 0.013 0.013 pandas_compat.py:107(table_to_blockmanager)1 0.013 0.013 0.013 0.013 {pyarrow.lib.table_to_blocks}比之前快很多,同时serialization and processing的过程全部优化了,只有IO的耗时。来看网络中《PySpark pandas udf》的一次对比:
![]()
其他,一些限制:
不支持所有的 sparkSQL 数据类型,包括 BinaryType,MapType, ArrayType,TimestampType 和嵌套的 StructType。
1.2.2 重置toPandas()
来自joshlk/faster_toPandas.py的一次尝试,笔者使用后,发现确实能够比较快,而且比之前自带的toPandas()还要更快捷,更能抗压.
import pandas as pddef _map_to_pandas(rdds):""" Needs to be here due to pickling issues """return [pd.DataFrame(list(rdds))]def toPandas(df, n_partitions=None):"""Returns the contents of `df` as a local `pandas.DataFrame` in a speedy fashion. The DataFrame isrepartitioned if `n_partitions` is passed.:param df: pyspark.sql.DataFrame:param n_partitions: int or None:return: pandas.DataFrame"""if n_partitions is not None: df = df.repartition(n_partitions)df_pand = df.rdd.mapPartitions(_map_to_pandas).collect()df_pand = pd.concat(df_pand)df_pand.columns = df.columns
return df_pand那么在code之中有一个分区参数n_partitions,分区是啥?(来源:知乎:Spark 分区?)RDD 内部的数据集合在逻辑上(以及物理上)被划分成多个小集合,这样的每一个小集合被称为分区。像是下面这图中,三个 RDD,每个 RDD 内部都有两个分区。
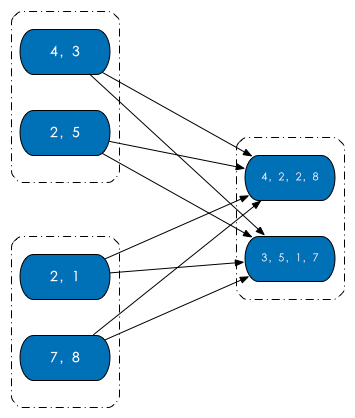
分区的个数决定了并行计算的粒度。比如说像是下面图介个情况,多个分区并行计算,能够充分利用计算资源。
pySpark | pySpark.Dataframe使用的坑 与 经历相关推荐
- Pyspark 读 DataFrame 的使用与基本操作
一.安装 基于 mac 操作系统 安装 jdk jdk 下载地址 安装 pyspark pip install pyspark 二.读取 HDFS 文件 读 json 注意,如果是多行的 json,需 ...
- PySpark之DataFrame的常用函数(创建、查询、修改、转换)
import findspark findspark.init()from pyspark import SparkContext sc = SparkContext.getOrCreate()fro ...
- pySpark创建DataFrame的方式
pySpark创建DataFrame的方式 有时候需要在迭代的过程中将多个dataframe进行合并(union),这时候需要一个空的初始dataframe.创建空dataframe可以通过spark ...
- pyspark之dataframe当前行与上一行值求差
pyspark之dataframe当前行与上一行值求差 from pyspark import SparkContext from pyspark.sql import SQLContext from ...
- pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换
# -*- coding: utf-8 -*- import pandas as pd from pyspark.sql import SparkSession from pyspark.sql im ...
- PySpark写入数据到Hbase的辛酸经历
Pyspark + Hbase 环境配置: Python:3.7.4 Spark:2.4.4 Hbase:2.2.3 前言: 首先,本人建议使用scala来做有关spark的开发,这是和前辈讨论他们给 ...
- pyspark —— spark dataframe 从hdfs读写文件:按照指定文件格式读写文件(读写csv、json、text文件,读取hive表,读取MySQL表)、按照指定分隔符读写文件
spark有3种数据结构--RDD.DataFrame.DataSet.这里展示的文件读写方式,都是针对dataFrame数据结构的,也就是文件读进来之后,是一个spark dataFrame. 0. ...
- 一文让你记住Pyspark下DataFrame的7种的Join 效果
最近看到了一片好文,虽然很简单,但是配上的插图可以让人很好的记住Pyspark 中的多种Join 类型和实际的效果.原英文链接 Introduction to Pyspark join types - ...
- sparkpython效率低_Effective PySpark(PySpark 常见问题)
构建PySpark环境 首先确保安装了python 2.7 ,强烈建议你使用Virtualenv方便python环境的管理.之后通过pip 安装pyspark pip install pyspark ...
最新文章
- 最新综述:关于自动驾驶的可解释性(牛津大学)
- SDUSTOJ 1801 LIS2(最长上升子序列不同值的数量)
- python基础知识05-控制流程
- sqlserver学习日记之一
- (精华)转:RDD:创建的几种方式(scala和java)
- 5G技术将加速智能网联汽车产业化进程
- js底部广告飘窗代码
- shuffle洗牌算法java_js打乱一个数组 的 洗牌(shuffle )算法
- rabbitmq可靠性投递_RabbitMQ 可靠投递
- JQuery --- 第三期 (jQuery事件相关)
- sql server 群集_部署SQL Server以使用群集共享卷进行故障转移群集–第1部分
- 2017linux版本号,Linux基本命令 2017-11-27
- python实现求解字符串集的最长公共前缀
- java如何使用md5加密_Java中MD5加密
- 智伴机器人自动关机后怎么开机_智伴机器人
- JQuery验证车牌号(含新能源车牌)
- ZZNU 2125:A + B 普拉斯(傻逼题+大数加法)
- 尚德机构第四季度营收5.688亿元 亏损大幅缩小
- WKwebview弹框报错Attempt to present UIAlertController on XXwhich is already presenting (null)
- 我对于测试团队建设的意见