1 如何在计算机中表示一个词的意思?
本章主要介绍了**如何在计算机中表示一个词的意思**,从WordNet,OneHot,到最重要的Word2Vec算法。
参考:
https://www.zhihu.com/column/c_1507074362628374528
https://zhuanlan.zhihu.com/p/543297427
https://zhuanlan.zhihu.com/p/581212957
https://blog.csdn.net/qq_29216461/article/details/126086970
要理解语言,首先我们要学字,词,计算机也一样。对于我们而言,每个单词,每个字都是有意思的,那么计算机要怎么也能让每个字在它那里有个意思呢?换句话说,我们要怎么将每个词的意思转换成计算机能读的形态。这样说可能还是觉得模糊,我们来看看一些已经有的一些解决方案来理解一下:
1 如何在计算机中表示一个词的意思?
1.1 传统的NLP方法-使用词典或词库链接[WordNet]
传统的NLP方法-使用词典或词库链接
传统的NLP方法,包括将各个单词链接到字典(dictionary)或词库(thesaurus),它们之中包含了同义词(synonym)和上位词(hypernym)。
例如:
皇帝的同义词是君王,君主,帝王等。
熊猫的上位词是浣熊科动物,杂食动物,哺乳动物等。
之前最常见的NLP解决方法是:使用一个包含同义词集和关系的同义词词典,例如WordNet,如图1所示。
![]()
1.1.1WordNet理解
WordNet的使用方法和一些基本概念可以参考[2],这里简单说一下他的基本概念,英文中一个单词可以有很多词性,比如一个单词,可以是名词(noun),形容词(adj),副词(adv),动词(verb)。WordNet用下面这种结构来表达词义:
![]()
比如说dog既可以做名词用,又可以做动词用,那么dog就会被分为名词和动词两类,而这两类里又有不同的词义,dog做名词用时,可以有不同的涵义,而每个含义我们都给它一个符号表示。所以一个单词的一种具体含义就用“单词.词性.词义序号”这种方式来表达,比如:dog.n.01表示dog作为名词时的一种含义。下面这段代码就不难理解了:
from nltk.corpus import wordnet as wn
#将所有词性缩写映射到词性名词上。
poses = { 'n':'noun', 'v':'verb', 's':'adj (s)', 'a':'adj', 'r':'adv'}
#找出good这个词的每个词义
for synset in wn.synsets("good"):#打印出每个有这个词义的单词print("{}: {}".format(poses[synset.pos()],", ".join([l.name() for l in synset.lemmas()])))
运行发现,good可以有很多种含义,而大多数含义不是只有good才有,大多数含义都可以用其他单词表达:

再看一个WordNet的例子:
from nltk.corpus import wordnet as wn
#panda可以有两种意思,一种是giant_panda.n.01指大熊猫
#一种是lesser_panda.n.01指小熊猫,
#panda.n.01和giant_panda.n.01是一个意思
#这里panda得到的是giant_panda.n.01这个值
panda = wn.synset("panda.n.01")
#求上位词,比如panda.n.01的上位词是procyonid.n.01
hyper = lambda s: s.hypernyms()
#循环找自己的上位词
list(panda.closure(hyper))
panda = wn.synset("panda.n.01")
得到的结果如下,可以打印出大熊猫一层一层往上所属的类,可以发现WordNet是树状的,知识性的,明确的,规整的:

1.1.2WordNet优缺点
这样做的优点有:
这样的方法看似可以把每个词都对应到一群相似“含义”的词中,或者对这个词语含义的解释里去。直觉上似乎能够达到“让计算机理解人类语言meaning“的目的。
但这样做的缺点有:
(1)许多词之间虽然是同义词,但是有细微的差别,没有在这样的网络或者说结构中体现出来
例如“proficient“在WordNet中是"good“的同义词,然而它们在实际应用中只在某些特定的场合才可以互相替换。用中文举例则是,硕大和大,在某个网络中可能被列为同义词,但我们不能在“大梦一场”或者“一件大事”中使用“硕大”来替换“大”。
(2)模型缺少一些新兴词语和一些词语被赋予的新含义。
例如ninjia,badass等。用中文举例,或许2019年的模型中没有“时空伴随者“,“密接”,“润”这样的词语,而将这样的词库或者说语料库实时更新,需要巨大的人力资源。在信息成指数增长的今天,这样的任务几乎是不可能完成的。
(3)主观的,需要人们手工创建和适应;
(4)无法准确计算词语之间的相似度。
直觉上讲,你或许会觉得,"悲伤"和"难过"或许是一对很近的近义词,"悲伤"和"痛苦"之间仿佛又远了一些。虽然有些牵强,但人为将前者的相似度定义为90%,后者定义为70%,和“快乐“的相似度则定义为一个负数,似乎也未尝不可。但仔细一想会发现,这样的定义其实非常主观,而且想要为 n 个词语之间定义相似度,则似乎需要 Cn2 个这样的关系,哪怕我们是按照统计学上它们出现的频率进行打分,不同的语言环境,不同的场合甚至不同的语气,这样的相似度都会被影响,要实现这样的赋值是不现实也没有意义的。
1.2 传统的NLP方法-用离散符号表示词[one-hot向量]
我们可以将词认为是一个离散的符号,由此一个词可以被表示为一个one-hot向量:
motel=[0 0 0 0 0 1 0]
hotel=[0 0 0 0 1 0 0]
![]()
这样做的优点有:
每个单词都用一个向量来表示,每个单词在向量里都有一个专属的位置,比如说at这个单词,那么就用[0,0,1,0,…,0]这个向量来表示,即第三个位置表示at,所以第三个位置值为1,其他位置的值都是0,之所以这个方法名字叫one-hot,就是因为向量里只有一个位置的值是1,其他位置的值都为0。
但这样做的缺点有:
(1)向量维度等于词汇表中词的数目
单词量还是挺大的,比如如果我们有10000个单词,那就得用10000个长度为10000的向量来表示这个系统。而且大多数位置还是0,特别稀疏,非常浪费.
(2)无法计算词之间的相似性
两个one-hot向量是正交的,无法计算词之间的相似性**。**因此可以通过向量自身进行学习编码词之间的相似性,这也是Word2Vec的想法之一。
1.3 现代的统计学NLP方法—使用上下文表示词语[词向量]
分布式语义:一个词的意思是由经常出现在附近的词来确定的。这是现代统计NLP最成功的想法之一。
当单词w出现在文本中时,它的上下文是附近(在固定大小的窗口内)出现的一组单词。我们用很多单词w的上下文去表示单词w。
![]()
例如:
凡劳苦担重担的人可以到我这里来, 我就使你们得安息。(马太福音 11:28)
如果我们将窗口的大小设置为3这里的“重担”的context就是 “劳苦担” 和 “的人可“ 。从这个例子中我们或许能够隐约感受到,“重担”加上“担”后,似乎类似于“劳苦”,可以用于修饰“人”——以人类的阅读习惯,似乎这个窗口里所有的信息真的能够用于推导出 w :"重担"的含义。
直觉上,这样的做法似乎是可行的,那么我们要用什么样的编码方式来实现这个过程,表示词语及其上下文和含义呢?答案仍然是**高维向量**。
这个想法似乎有点古怪,不太能想通,也显得不太可靠,应该不管用吧,但事实是按照这个想法设计的算法,产生的词义,能很好的表达单词的意思。超乎预料的管用。 我们先不管算法,看看最后的结果可以是怎么样的

比如banking这个词,就可以是一个长度为8的向量(这个长度可以根据单词量,样本量和精确度需求来决定,这里只是举个例子),每个维度应当都表达了一层意思,但这个意思不是人为去定义的,而在每个维度上的值就组成了banking的整体意思。
我们可以把一个向量想象成一个高维度的空间里的一个位置,比如说一个二维的向量,就可以表示一个平面上的点,一个三维的向量,则可以表示我们生活的这个三维空间里的一个点,一个四维的向量,立体空间再加上时间这个维度就是四维的。那么如果我们用一个长度为8的向量去表示一个词,则可以理解成,在一个高维度(八维)的空间里,banking这个词有个位置,它所在的位置即是它的意思。而在这个八个维度的空间里,每个在训练样本里的单词,都会有一个位置。比如像下图一样:
![]()
1.3.1 词向量(word vectors)
有了上诉的介绍,我们可以用一个密集的向量表示每一个词,以便它与出现在相似上下文中的单词的向量相似,以向量点积的形式衡量词之间相似性。例如,词banking(银行业)与词monetary(金融的)存在一定联系,其词向量也应该相似:

注意:词向量也被称作词嵌入(word embeddings)或者词表示(word representations),它们都是一个分布式表示。
那如何去学习得到词向量呢?由此提出了Word2Vec算法。
1.3.2 Word2Vec算法的具体思路
Word2Vec就是运用这个概念的算法。Word2Vec (Mikolov et al., 2013)[2]是一个词向量的框架,让我们来看算法具体的思路:
![]()
翻译如下:
- 我们有一个语料库,里面有很多文章或者对话,总之是语言。
- 每个单词我们都用一个向量来表示(实际算法一般是两个向量,一个中心词向量,一个周边词向量),每个单词的向量维度是一致的,刚开始的时候,向量里的值是随机赋予的随机数。
- 以位置 t 为索引(从第0个词到最后一个词),从头到尾遍历这个语料库,我们始终可以获得一个这个位置的中心词汇 c 和中心词汇外部的上下文词汇集合 o 。
- 利用c和o的相似度来计算给出c能得到o的概率,即c发生的条件下,o发生的概率P(o|c),或者反过来P(c|o)也行。
- 调整词向量里的值来提高P(o|c)或P(c|o)【使这个概率最大化】。
- 循环重复之前的三个步骤,直到P(o|c)或者P(c|o)无法再提高。
注1: 虽然本课程ppt中使用的词是maxmizing,但我认为它的意思是,将每个词都分配好两个vector以后(一个center word的vector一个context的vector)相当于这个词向量系统就构建完成,我们可以依靠词向量系统里词与词之间的相似性,计算此系统应用于整个语料的结果——用概率的累乘来表示。也就是说,我们是想找到能够让这个==整体概率最趋近于1【达不到1(语句有重复出现的字,并且他们的上下文不一样)】==的词向量系统。我觉得这样的思想有点类似于交叉熵。
1.3.3 算法思路举例
如下图所示,在给定中心词into的条件下,而临近词的区域设定为2的时候,就需要计算当into出现时,那些在区间内出现的词会出现概率【最终我们需要最大化各个上下文词出现的条件概率P(wt+j|wt)】。
假设我们已经有了一个词向量系统,每个词都已经成为了一个与彼此维度相等的dense vector。在上面这个句子中,当"into"作为一个中心词的时候,假设它的位置是 t ,我们的窗口大小为2。我们可以利用某种方法,通过基于context来定义的"into"的词向量,计算"problems", “turning”, “banking”, 和"crises"出现的概率。
![]()
计算完后,再以下一个单词为中心词,重复上面的过程。
![]()
条件概率的计算是一个softmax的方程(具体可以看Softmax):
softmax函数简而言之就是将函数的输出映射到[0, 1]。并且通过指数函数的方式,放大了分布中最大分子的概率,同时也保证更小的分子项有一个大于0的概率,并且整个函数是可导的
*[如何计算* P(wt+j|wt;θ) *的值?*]
这其实也是我前面提到的,如何将词向量和概率联系起来的关键。
这里的解决方法是,对于每个词都创建两个向量:
- 该词语作为中心词时的向量 vw
- 该词作为其它词的上下文时的向量 uw
![]()
vc是中心词向量,uo是周边词向量,V是所有单词的集合,uw是V中的单词。
这个问题的极大似然函数:
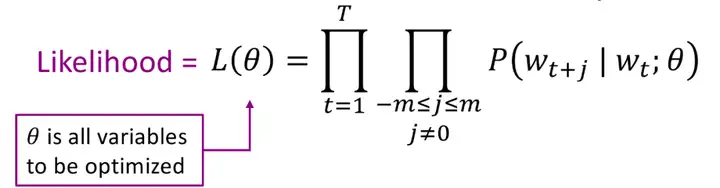
【具体的看1.3.3 算法构建数学推导】
我有这样一个想法,或许能够帮助到大家理解上面的过程:
如果"into"在本文中出现的所有地方,其上下文都是"problems", “turning”, “banking”, 和"crises",那么对于这个文本,“into"最好的词向量,就是由"problems”, “turning”, “banking”, 和"crises"组成context,计算它们出现的概率为100%(即1)的词向量。也就是说,如果是一个简单的文本:
让 | 自己 | 内心 | 藏着 | 一条 | 巨龙。
如果这就是我们"语料库"所有的内容(实际情况中的文本当然应该长很多很多),且每个字词都只出现了一次,那么我们需要寻找到的词向量系统,就应该是中心词是"自己"时,“让”,“内心”, 和"藏着"概率都为1,中心词是"内心"时,“让”,“自己”,“藏着”,和"一条"的概率是1,以此类推。由此不难知道,在这个文本简单没有重复词语的情况,我们的"概率"可以达到1。
而当文本变成
让 | 自己 | 内心 | 藏着 | 一条 | 巨龙 | ,| 既是 | 一种 | 苦刑 |,| 也是 | 一种 | 乐趣。
发现**"一种"这个词,出现了两次,且两次的上下文都不一样**。而**一个词只能有一个词向量,因此我们寻找到的最终的词向量系统,应用于这个文本,累乘的概率一定不会是1。我们要做的则是趋近于它**。
如何使用词向量计算每个"概率",如何使得每个"概率"达到全局最优。是word2vec的核心。下面我会进行一些数学推导,这也能帮助理解上述过程。
1.3.4 Word2Vec构建过程的一些数学推导
由section2提到的,我们的目标是最大化这个词向量,系统预测实际出现在每个中心词周围文本的概率之积。
![]()
likelihood() 似然函数
其中,θ是我们要去优化的参数,实际上就是词向量!
1.3.4.1 likelihood() 似然函数
![]()
为了训练模型,我们会逐渐调整参数,使得loss最小。回想之前提到的参数θ:
- θ表示模型的所有参数,用一个很长的向量表示
- 在我们讲述的例子中,我们假设每个向量都是d维,总共有V个词,并且每个词都有两个向量,分别表示中心词向量和上下文词向量
那么参数θ表示为:
![]()
T指所有位置的集合,经过一个位置时,位置上的词为中心词wt,周边的词为wt+j,m限制了周边词的范围,L( θ)求的是在参数为 θ的情况下,遍历所有的文本位置,求每个中心词和周边词的条件概率,再把它们乘起来。得到的条件概率越大,L( θ)越大。而我们要做的是调整θ 的值,使得L( θ)获得最大值。
1.3.4.2优化参数使模型得到最小的Loss
![]()
有了这样一个可导的目标函数后,我们想做的事情就很清晰了——通过调整所有参数 θ (我们会有非常非常多的参数)来使损失函数(Loss function) J(θ) 最小,从已有的条件以及输入和输出来看。类似于神经网络的模型的训练过程。
因此,我们会将所有的参数张成一列很长的高维向量,并且对其中的每一个参数来做梯度下降(另一个机器学习中非常重要的概念)。我们会计算所有向量,损失函数对每一个参数的偏导数,并根据这个梯度的方向对该参数进行调整。
![]()
所有参数长成的向量维度为 2×d×V 。其中, d 是我们选择的词向量的维度, V 是语料库中所有词的个数。(需要乘2是因为每一个词都会生成一个作为中心词时的词向量和一个作为上下文时的词向量)
我们通过梯度下降法优化这些参数。
![]()
公式(4)和公式(5)存在的问题:损失函数J(θ)是遍历语料库上所有词计算的,因此求其梯度 ∇θJ(θ)非常耗时!导致一次更新需要等待很久。
由此引入**随机梯度下降法**(SGD),即每遍历一个词,就更新一次该词和其上下文词的参数。
1.4 DEMO
最后我们来看看,怎么用别人训练好的Word2Vec做一些事情:
import numpy as np
# Get the interactive Tools for Matplotlib
%matplotlib notebook
import matplotlib.pyplot as plt
plt.style.use('ggplot')from sklearn.decomposition import PCA
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
from gensim.scripts.glove2word2vec import glove2word2vec
gensim是一个工具包,可以让我们导入训练好的模型参数,斯坦福有一个GloVe项目(https://nlp.stanford.edu/projects/glove/),在里面可以下载训练好的词向量:
#将下载的词向量文件放在合适的目录,并读入
glove_file = datapath('D:/glove.6B.100d.txt')
word2vec_glove_file = get_tmpfile("glove.6B.100d.word2vec.txt")
glove2word2vec(glove_file, word2vec_glove_file)
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
接下来,我们就可以做一些事情了,比如找近义词:
>>model.most_similar('obama')
[('barack', 0.937216579914093),('bush', 0.927285373210907),('clinton', 0.896000325679779),('mccain', 0.8875633478164673),('gore', 0.8000321388244629),('hillary', 0.7933662533760071),('dole', 0.7851964831352234),('rodham', 0.7518897652626038),('romney', 0.7488929629325867),('kerry', 0.7472624182701111)]
比如找反义词:[实际单独效果不好,但是结合上面一起用就很好–见下面例子]
>>model.most_similar(negative='banana')
[('shunichi', 0.49618104100227356),('ieronymos', 0.4736502170562744),('pengrowth', 0.4668096601963043),('höss', 0.4636845588684082),('damaskinos', 0.4617849290370941),('yadin', 0.4617374837398529),('hundertwasser', 0.4588957726955414),('ncpa', 0.4577339291572571),('maccormac', 0.4566109776496887),('rothfeld', 0.4523947238922119)]
比如找对应的词:
就是做加减法
可以理解为它能计算出前两者的。把这个关系应用在第三者上得到类比
# king-woman 近似于 queen-man
>>model.most_similar(positive=['woman', 'king'], negative=['man'])[0]
('queen', 0.7698540687561035)
>>model.most_similar(positive=['australia', 'japanese'], negative=['japan'])[0]
('australian', 0.8923497796058655)
>>model.most_similar(positive=['france', 'beer'], negative=['australia'])[0]
('champagne', 0.6480063796043396)
>>model.most_similar(positive=['reagan', 'clinton'], negative=['obama'])[0]
('nixon', 0.7844685316085815)
>>model.most_similar(positive=['bad', 'fantastic'], negative=['good'])[0]
('terrible', 0.7074226140975952)
# 找出非我族类
>>model.doesnt_match("breakfast cereal dinner lunch".split())
可以看出来,Word2Vec使每个词都有了一个可以让计算机计算的独一无二的意思。而这个意思是非常非常接近人的理解的。而数值的复杂性和不可解释性也恰恰符合了语言混沌的特点。
1 如何在计算机中表示一个词的意思?相关推荐
- idea中选择一个词的快捷键
idea中选择一个词的快捷键 在idea中选择一个词用carl+w快捷键 1,鼠标所在的地方按住carl+w键 2,再按w键 连续按w会依次会选中单词-整个字符串-整个字符串包含引号-整个字符串赋值语 ...
- 怎么把整个网站的代码中的一个词去掉_【杭州南牛网络】网站优化的最新优化方法...
[杭州南牛网络]如果你是一名企业主,你有建立企业官方网站的经验,在2-3年的运营过程中,我相信你至少对网站做了一次修改,甚至对SEO战略进行了重大调整. 原因很简单:当我们刚开始建一家公司时,很多时间 ...
- 计算机中一个汉字占用 存储空间,一个字母、数字、汉字所占用的内存空间
字节(Byte):通常将可表示常用英文字符8位二进制称为一字节. 一个英文字母(不分大小写)占一个字节的空间.一个中文汉字占两个字节的空间. 符号:英文标点2占一个字节.中文标点占两个字节. 一个二进 ...
- 悖论在计算机中的应用,“索洛悖论”悖论 计算机影响随处可见
随着信息技术的深化发展,拿"索洛悖论"讽刺新经济的人变少了,或者说主流经济学家这方面的亢奋被抑制住了.这主要是因为,在美国和oecd官方的生产率统计中,ict的影响已经随处可在了. ...
- 微型计算机中内存比外存怎样,在同一台计算机中,内存比外存( )。
答案 查看答案 解析: [解析题]小单的计算机老师本学期采用翻转课堂教学法,课前为学生提供视频,要求学生先自学基础知识,然后在上课的时候再组织同学们一起通过讨论.练习等方式内化知识.小单觉得有些不适应 ...
- 计算机中表示信息量最小的单位是什么,计算机中信息的最小单位是什么?
原文:https://www.php.cn/faq/465644.html 在计算机中,信息的最小单位是"位".计算机中,一个二进制位(bit)是构成存储器的最小单位,即表示信息量 ...
- 7.计算机中的数据的表示及编码
计算机中数据的表示与编码 1.数的进位计数制 2.数值型数据在计算机中的表示 3.二进制的编码 1.数的进位计数制 基数:每个数位上所能使用的数码的个数 位权:处在某一位上的 1 所表示的数值的大小, ...
- 一字长计算机,计算机中一个字到底等于多少个字节啊
一个汉字在ASCII码中占两个字节,UTF-8编码中占三个字节,Unicode编码占两个字节.ASCII码:一个英文字母(不分大小写)占一个字节的空间.一个二进制数字序列,在计算机中作为一个数字单元, ...
- 计算机中常用的储存度量单位有,计算机中度量存储信息容量的基本单位是什么?...
计算机中度量存储信息容量的基本单位是什么? (2006-09-04 15:58:08) 1KB=1024字节, KB也叫千字节 1MB=1024KB,MB是兆字节 1GB=1024MB,GB是千兆字节 ...
最新文章
- SAP EWM Table Overview [转]
- java操作字符串的工具类StringUtil
- Scala print语句格式打印
- python制作射击游戏_用python3从零开始开发一款烧脑射击游戏#2
- Vue的computed(计算属性)使用实例之TodoList
- Linux下nginx的安装及部署
- 图解clientWidth,offsetWidth,scrollWidth,scrollTop
- 解决办法:C++编译中[-Wreorder]
- win linux批处理删除指定N天前文件夹的文件
- matlab画奇异吸引子,第四节 混沌理论和奇异吸引子
- 数字图像处理——图像边缘检测
- c语言编程中crol,单片机C语言“_crol_” 与“_cror_”的用法
- PDF批量合并拆分并
- python程序设计实用教程答案_Python程序设计实用教程
- 病毒木马查杀实战第017篇:U盘病毒之专杀工具的编写
- 两层板如何做阻抗控制呢
- 模仿UP主,用Python实现一个弹幕控制的直播间
- 有房间匹配和无房间匹配
- 数据结构【一轮复习】---绪论(王道+天勤)
- [JAVA]百度官方IP查询定位