MySQL 覆盖索引
本文主要概述mysql的覆盖索引,以及几种常见的优化场景
内容概要
- 聚集索引和辅助索引
- 什么是覆盖索引
- 几种优化场景
- 总体建议
聚集索引和辅助索引
- 聚集索引(主键索引)
- 辅助索引(二级索引)
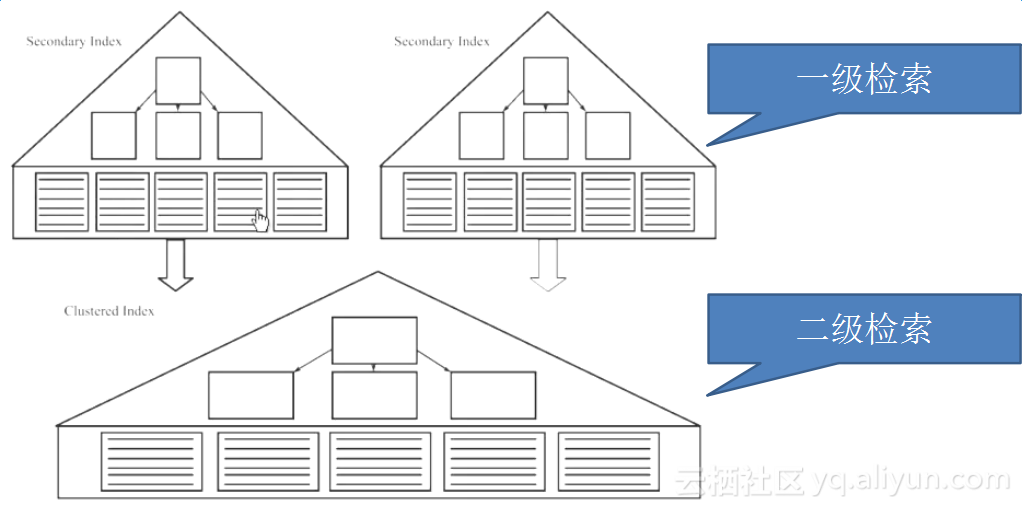
什么是覆盖索引

几种优化场景
1、无where条件的查询优化
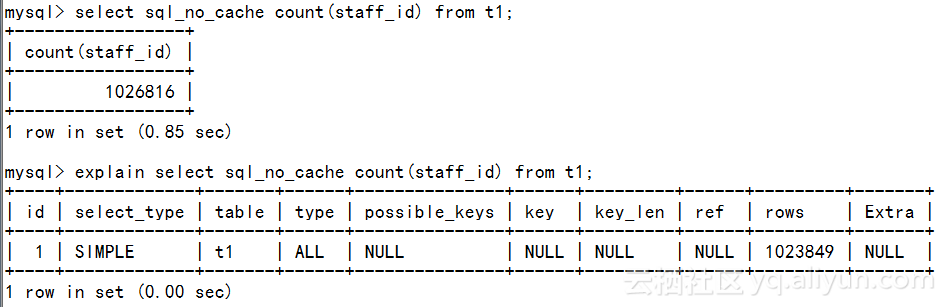
mysql> alter table t1 add key(staff_id);我们再看一下优化之后的效果
- 执行计划
mysql> explain select sql_no_cache count(staff_id) from t1\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1type: index
possible_keys: NULLkey: staff_idkey_len: 1ref: NULLrows: 10238491 row in set (0.00 sec)
Using index表示使用到了索引
- 查询消耗

2、二次检索优化
mysql> select sql_no_cache rental_date from t1 where inventory_id<80000;
…
…
| 2005-08-23 15:08:00 |
| 2005-08-23 15:09:17 |
| 2005-08-23 15:10:42 |
| 2005-08-23 15:15:02 |
| 2005-08-23 15:15:19 |
| 2005-08-23 15:16:32 |
+---------------------+
79999 rows in set (0.13 sec)执行计划:
mysql> explain select sql_no_cache rental_date from t1 where inventory_id<80000\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1type: range
possible_keys: inventory_idkey: inventory_idkey_len: 3ref: NULLrows: 153734Extra: Using index condition
1 row in set (0.00 sec)
从执行计划,我们看到,这个SQL其实是使用到了索引的,虽然查询的数据量很大,但是相对比全表扫描的性能消耗,优化器还是选择了索引。
mysql> alter table t1 add key(inventory_id,rental_date);
这个联合索引前置列为where子句的检索字段,第二个字段为查询返回的字段。下面来看下效果如何。
mysql> analyze table t1\G
*************************** 1. row ***************************Table: sakila.t1Op: analyze
Msg_type: status
Msg_text: OK
1 row in set (0.03 sec)
执行计划
mysql> explain select sql_no_cache rental_date from t1 where inventory_id<80000\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1type: range
possible_keys: inventory_id,inventory_id_2key: inventory_id_2key_len: 3ref: NULLrows: 1628841 row in set (0.00 sec)
查询消耗
mysql> select sql_no_cache rental_date from t1 where inventory_id<80000;
…
…
| 2005-08-23 15:08:00 |
| 2005-08-23 15:09:17 |
| 2005-08-23 15:10:42 |
| 2005-08-23 15:15:02 |
| 2005-08-23 15:15:19 |
| 2005-08-23 15:16:32 |
+---------------------+
79999 rows in set (0.09 sec)
从执行时间上来看,快了大约40ms,虽然只有40ms,但在实际的生产环境下,却可能会因系统的总体负载被无限放大。
3、分页查询优化
mysql> select tid,return_date from t1 order by inventory_id limit 50000,10;
+-------+---------------------+
| tid | return_date |
+-------+---------------------+
| 50001 | 2005-06-17 23:04:36 |
| 50002 | 2005-06-23 03:16:12 |
| 50003 | 2005-06-20 22:41:03 |
| 50004 | 2005-06-23 04:39:28 |
| 50005 | 2005-06-24 04:41:20 |
| 50006 | 2005-06-22 22:54:10 |
| 50007 | 2005-06-18 07:21:51 |
| 50008 | 2005-06-25 21:51:16 |
| 50009 | 2005-06-21 03:44:32 |
| 50010 | 2005-06-19 00:00:34 |
+-------+---------------------+
10 rows in set (0.75 sec)
在未优化之前,我们看到它的执行计划是如此的糟糕
mysql> explain select tid,return_date from t1 order by inventory_id limit 50000,10\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1type: ALL
possible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 10236751 row in set (0.00 sec)
全表扫描,加上额外的排序,相信产生的性能消耗是不低的
mysql> alter table t1 add index liu(inventory_id,return_date);
Query OK, 0 rows affected (3.11 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> analyze table t1\G
*************************** 1. row ***************************Table: sakila.t1Op: analyze
Msg_type: status
Msg_text: OK
1 row in set (0.04 sec)
那么,效果如何呢?
mysql> select tid,return_date from t1 order by inventory_id limit 50000,10;
+-------+---------------------+
| tid | return_date |
+-------+---------------------+
| 50001 | 2005-06-17 23:04:36 |
| 50002 | 2005-06-23 03:16:12 |
| 50003 | 2005-06-20 22:41:03 |
| 50004 | 2005-06-23 04:39:28 |
| 50005 | 2005-06-24 04:41:20 |
| 50006 | 2005-06-22 22:54:10 |
| 50007 | 2005-06-18 07:21:51 |
| 50008 | 2005-06-25 21:51:16 |
| 50009 | 2005-06-21 03:44:32 |
| 50010 | 2005-06-19 00:00:34 |
+-------+---------------------+
10 rows in set (0.03 sec)mysql> explain select tid,return_date from t1 order by inventory_id limit 50000,10\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1type: index
possible_keys: NULLkey: liukey_len: 9ref: NULLrows: 500101 row in set (0.00 sec)
执行计划也可以看到,使用到了复合索引,并且不需要回表
mysql> select tid,return_date from t1 order by inventory_id limit 800000,10;
+--------+---------------------+
| tid | return_date |
+--------+---------------------+
| 800001 | 2005-08-24 13:09:34 |
| 800002 | 2005-08-27 11:41:03 |
| 800003 | 2005-08-22 18:10:22 |
| 800004 | 2005-08-22 16:47:23 |
| 800005 | 2005-08-26 20:32:02 |
| 800006 | 2005-08-21 14:55:42 |
| 800007 | 2005-08-28 14:45:55 |
| 800008 | 2005-08-29 12:37:32 |
| 800009 | 2005-08-24 10:38:06 |
| 800010 | 2005-08-23 12:10:57 |
+--------+---------------------+与之对比的是如下改写SQL方式
select a.tid,a.return_date from t1 a
inner join
(select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid;并在此基础上,我们为inventory_id列创建索引,并删除之前的覆盖索引
mysql> alter table t1 add index idx_inid(inventory_id),drop index liu;然后收集统计信息。
mysql> select a.tid,a.return_date from t1 a inner join (select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid;
+--------+---------------------+
| tid | return_date |
+--------+---------------------+
| 800001 | 2005-08-24 13:09:34 |
| 800002 | 2005-08-27 11:41:03 |
| 800003 | 2005-08-22 18:10:22 |
| 800004 | 2005-08-22 16:47:23 |
| 800005 | 2005-08-26 20:32:02 |
| 800006 | 2005-08-21 14:55:42 |
| 800007 | 2005-08-28 14:45:55 |
| 800008 | 2005-08-29 12:37:32 |
| 800009 | 2005-08-24 10:38:06 |
| 800010 | 2005-08-23 12:10:57 |
+--------+---------------------+
可以看到,这种优化手段较前者时间消耗多了大约140ms。
总体建议
- Select查询的返回列包含在索引列中
- 有where条件时,where条件中要包含索引列或复合索引的前导列
- 查询结果的总字段长度可以接受
MySQL 覆盖索引相关推荐
- MySQL覆盖索引(Covering Index)
MySQL覆盖索引(Covering Index) mysql高效索引之覆盖索引 概念 如果索引包含所有满足查询需要的数据的索引成为覆盖索引(Covering Index),也就是平时所说的不需要回表 ...
- MySQL 覆盖索引、最左前缀原则、索引下推
1.覆盖索引 1.1 概念 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了.如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引 ...
- mysql覆盖索引二次查找_mysql中关于覆盖索引的知识点总结
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为'覆盖索引'. 覆盖索引是一种非常强大的工具,能大大提高查询性能,只需要读取索引而不需要读取数据,有以下优点: 1.索引项通常比记录要小,所以My ...
- 简单易懂的MySQL覆盖索引、前缀索引、索引下推
文章目录 前言 常见的索引类型 聚簇索引/非聚簇索引 覆盖索引 前缀索引 索引下推 前言 索引的出现是为了提高数据查询效率,像书的目录一样.对于数据库的表而言,索引其实就是"目录" ...
- MySQL 覆盖索引(Cover Index)
概述 一个索引包含了所有需要查询的字段值,那么就称为覆盖索引. 好处 索引的大小通常远小于数据行大小,所以如果只需要读取索引,那么MySQL会极大的减少数据访问量. 索引是按照值得顺序存储的. Inn ...
- mysql覆盖索引详解
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为'覆盖索引'.即只需扫描索引而无须回表. 只扫描索引而无需回表的优点: 1.索引条目通常远小于数据行大小,只需要读取索引,则mysql会极大地减少 ...
- mysql覆盖索引解决模糊查询失效_关于MySQL的SQL优化之覆盖索引
前些天,有个同事跟我说:"我写了个SQL,SQL很简单,但是查询速度很慢,并且针对查询条件创建了索引,然而索引却不起作用,你帮我看看有没有办法优化?". 我对他提供的case进行了 ...
- Mysql 覆盖索引及其使用注意事项
一,什么叫覆盖索引 网上对覆盖索引的定义有如下三种: 解释一: 就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖. 解释二: 索引是高效找到行的一 ...
- MySQL覆盖索引:直接从索引查询到了数据
标志:覆盖索引的标志 extra的using index ; 定义:sql直接从索引查找到了数据 没有去数据表查找 就是索引覆盖了 就是覆盖索引 结合:有using where和using id ...
最新文章
- 如何对 Rocksdb以及类似存储引擎社区 提出 有效的性能问题?
- DockOne微信分享(八十四):Docker在B站的实施之路
- OC中的几种延迟执行方式
- 优酷视频如何进行连续播放?
- Guava链式风格Ordering比较器实例
- 聚类分析在用户行为中的实例_基于行为数据的消费信贷反欺诈方案
- Python报错it could not find or load the Qt platform plugin windows
- jsp页面什么时候用 .do 和 .jsp
- Python查找中国城市、省份
- 2022SPSSPRO认证杯数学建模B题第二阶段方案及赛后总结:唐宋诗的定量分析与比较研究
- android studio 读取短信
- Quartus II :1位全加器设计
- vim的文件比较功能
- C语言中带负数的除法
- Swift之代码优化
- L1:一维圣维南方程
- 为什么单个元素的元组要加上逗号?
- 关于carsim2016破解问题
- 通达信l2接口是什么意思?
- 云基础设施之硬件安全威胁
热门文章
- Lesson 2.张量的索引、分片、合并以及维度调整
- vue笔记整理与总结
- 实战 | 深度学习轻松学:如何用可视化界面来部署深度学习模型 转载 2017年12月27日 00:00:00 109 翻译 | AI科技大本营 参与 | 王赫 上个月,我有幸结识了 DeepCogn
- 使用Pandas进行变量衍生
- @springbootapplication 注解_Spring Boot最核心的27个干货注解,你了解多少?
- 三、【线性表】线性表概述
- 深入理解分布式技术 - 理论基石 CAP
- Spring Cloud【Finchley】-10Hystrix监控
- 实战SSM_O2O商铺_14【商铺注册】View层之验证码kaptcha组件
- Linux-SFTP/SSH免密码登录