redis internal【转】
原文地址:https://zhuanlan.zhihu.com/p/37800945
本篇文章介绍Redis协议、内存模型、持久化以及分布式解决方案。
1. redis协议:
redisClient与redisServer之间的通信协议叫:RESP (REdis Serialization Protocol)。
RESP遵循Request-Response模型,具体实现如下:
- Clients send commands to a Redis server as a RESP Array of Bulk Strings.
- The server replies with one of the RESP types according to the command implementation.
在RESP中,数据的类型取决于该数据的第一个字节:
- For Simple Strings the first byte of the reply is "+"
- For Errors the first byte of the reply is "-"
- For Integers the first byte of the reply is ":"
- For Bulk Strings the first byte of the reply is "$"
- For Arrays the first byte of the reply is "
*"
RESP Arrays 的格式如下:
- A * character as the first byte, followed by the number of elements in the array as a decimal number, followed by CRLF.
- An additional RESP type for every element of the Array.
例如:
RESP空数组:
"*0\r\n"
两个元素的RESP数组:
"*2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n"

2. 内存模型
2.1 redis内存统计
 redis info memory
redis info memory
used_memory: 由 Redis 分配器分配的内存总量,以字节(byte)为单位used_memory_human: 以人类可读的格式返回 Redis 分配的内存总量used_memory_rss: 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和top、ps等命令的输出一致。used_memory_peak: Redis 的内存消耗峰值(以字节为单位)used_memory_peak_human: 以人类可读的格式返回 Redis 的内存消耗峰值used_memory_lua: Lua 引擎所使用的内存大小(以字节为单位)mem_fragmentation_ratio:used_memory_rss和used_memory之间的比率mem_allocator: 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc
2.2 redis内存划分
- 数据
作为数据库,数据是最主要的部分;这部分占用的内存会统计在used_memory中。
- 进程本身需要的内存:
Redis主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与Redis数据占用的内存相比可以忽略。这部分内存不是由jemalloc分配,因此不会统计在used_memory中。
补充说明:除了主进程外,Redis创建的子进程运行也会占用内存,如Redis执行AOF、RDB重写时创建的子进程。当然,这部分内存不属于Redis进程,也不会统计在used_memory和used_memory_rss中。
- 缓冲内存
缓冲内存包括客户端缓冲区、复制积压缓冲区、AOF缓冲区等;其中,客户端缓冲存储客户端连接的输入输出缓冲;复制积压缓冲用于部分复制功能;AOF缓冲区用于在进行AOF重写时,保存最近的写入命令。在了解相应功能之前,不需要知道这些缓冲的细节;这部分内存由jemalloc分配,因此会统计在used_memory中。
- 内存碎片
内存碎片是Redis在分配、回收物理内存过程中产生的。例如,如果对数据的更改频繁,而且数据之间的大小相差很大,可能导致redis释放的空间在物理内存中并没有释放,但redis又无法有效利用,这就形成了内存碎片。内存碎片不会统计在used_memory中。
内存碎片的产生与对数据进行的操作、数据的特点等都有关;此外,与使用的内存分配器也有关系:如果内存分配器设计合理,可以尽可能的减少内存碎片的产生。后面将要说到的jemalloc便在控制内存碎片方面做的很好。
如果Redis服务器中的内存碎片已经很大,可以通过安全重启的方式减小内存碎片:因为重启之后,Redis重新从备份文件中读取数据,在内存中进行重排,为每个数据重新选择合适的内存单元,减小内存碎片。
2.3 数据存储
下面是执行`SET HELLO WORLD`,所涉及到的数据模型:
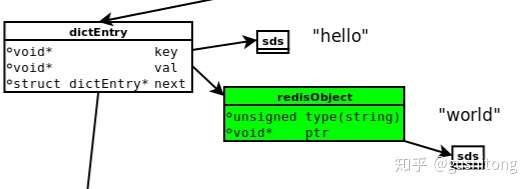 redis dictEntry
redis dictEntry
- dictEntry:Redis是Key-Value数据库,因此对每个键值对都会有一个dictEntry,里面存储了指向Key和Value的指针;next指向下一个dictEntry,与本Key-Value无关。
- Key:图中右上角可见,Key(”hello”)并不是直接以字符串存储,而是存储在SDS结构中。
- redisObject:Value(“world”)既不是直接以字符串存储,也不是像Key一样直接存储在SDS中,而是存储在redisObject中。实际上,不论Value是5种类型的哪一种,都是通过redisObject来存储的;而redisObject中的type字段指明了Value对象的类型,ptr字段则指向对象所在的地址。不过可以看出,字符串对象虽然经过了redisObject的包装,但仍然需要通过SDS存储。
- jemalloc:无论是DictEntry对象,还是redisObject、SDS对象,都需要内存分配器(如jemalloc)分配内存进行存储。以DictEntry对象为例,有3个指针组成,在64位机器下占24个字节,jemalloc会为它分配32字节大小的内存单元。
2.4 redisObject
前面说到,Redis对象有5种类型;无论是哪种类型,Redis都不会直接存储,而是通过redisObject对象进行存储。
redisObject对象非常重要,Redis对象的类型、内部编码、内存回收、共享对象等功能,都需要redisObject支持,下面将通过redisObject的结构来说明它是如何起作用的。
redisObject的定义如下(不同版本的Redis可能稍稍有所不同):
typedef struct redisObject {unsigned type:4; unsigned encoding:4; unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; } robj;redisObject的每个字段的含义和作用如下:
- type:
type字段表示对象的类型,占4个比特;目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
- encoding
encoding表示对象的内部编码,占4个比特。
对于Redis支持的每种类型,都有至少两种内部编码,例如对于字符串,有int、embstr、raw三种编码。通过encoding属性,Redis可以根据不同的使用场景来为对象设置不同的编码,大大提高了Redis的灵活性和效率。以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
- lru
lru记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占24比特,2.6版本占22比特)。
通过对比lru时间与当前时间,可以计算某个对象的空转时间;object idletime命令可以显示该空转时间(单位是秒)。object idletime命令的一个特殊之处在于它不改变对象的lru值。
lru值除了通过object idletime命令打印之外,还与Redis的内存回收有关系:如果Redis打开了maxmemory选项,且内存回收算法选择的是volatile-lru或allkeys—lru,那么当Redis内存占用超过maxmemory指定的值时,Redis会优先选择空转时间最长的对象进行释放。
- refcount
refcount记录的是该对象被引用的次数,类型为整型。refcount的作用,主要在于对象的引用计数和内存回收。当创建新对象时,refcount初始化为1;当有新程序使用该对象时,refcount加1;当对象不再被一个新程序使用时,refcount减1;当refcount变为0时,对象占用的内存会被释放。
- 共享对象
Redis中被多次使用的对象(refcount>1),称为共享对象。Redis为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象。
Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为O(1);对于普通字符串,判断复杂度为O(n);而对于哈希、列表、集合和有序集合,判断的复杂度为O(n^2)。
虽然共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象(如哈希、列表等的元素可以使用)。
就目前的实现来说,Redis服务器在初始化时,会创建10000个字符串对象,值分别是0~9999的整数值;当Redis需要使用值为0~9999的字符串对象时,可以直接使用这些共享对象。10000这个数字可以通过调整参数REDIS_SHARED_INTEGERS(4.0中是OBJ_SHARED_INTEGERS)的值进行改变。
共享对象的引用次数可以通过object refcount命令查看,如下图所示。命令执行的结果页佐证了只有0~9999之间的整数会作为共享对象。
- ptr
ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS。
2.5 SDS (Simple Dynamic String)
sds的结构如下:
struct sdshdr { int len; int free; char buf[]; };其中,buf表示字节数组,用来存储字符串;len表示buf已使用的长度,free表示buf未使用的长度。下面是两个例子。
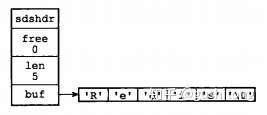 图片来源:《Redis设计与实现》
图片来源:《Redis设计与实现》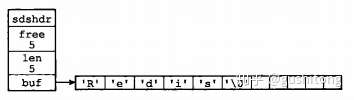 图片来源:《Redis设计与实现》
图片来源:《Redis设计与实现》
通过SDS的结构可以看出,buf数组的长度=free+len+1(其中1表示字符串结尾的空字符);所以,一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度 =4+4+free+len+1=free+len+9。
SDS在C字符串的基础上加入了free和len字段,带来了很多好处:
- 获取字符串长度:SDS是O(1),C字符串是O(n)
- 缓冲区溢出:使用C字符串的API时,如果字符串长度增加(如strcat操作)而忘记重新分配内存,很容易造成缓冲区的溢出;而SDS由于记录了长度,相应的API在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
- 修改字符串时内存的重分配:对于C字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于可以记录len和free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化:空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。
- 存取二进制数据:SDS可以,C字符串不可以。因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而SDS以字符串长度len来作为字符串结束标识,因此没有这个问题。
此外,由于SDS中的buf仍然使用了C字符串(即以’\0’结尾),因此SDS可以使用C字符串库中的部分函数;但是需要注意的是,只有当SDS用来存储文本数据时才可以这样使用,在存储二进制数据时则不行(’\0’不一定是结尾)。
Redis在存储对象时,一律使用SDS代替C字符串。例如set hello world命令,hello和world都是以SDS的形式存储的。而sadd myset member1 member2 member3命令,不论是键(”myset”),还是集合中的元素(”member1”、 ”member2”和”member3”),都是以SDS的形式存储。除了存储对象,SDS还用于存储各种缓冲区。
只有在字符串不会改变的情况下,如打印日志时,才会使用C字符串。
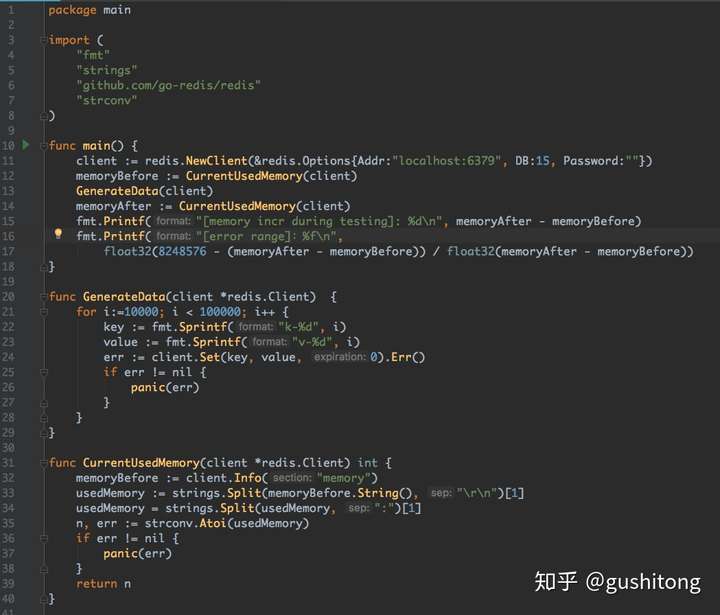
2.6 估算Redis内存使用量
假设有90000个键值对,每个key的长度是7个字节,每个value的长度也是7个字节(且key和value都不是整数);下面来估算这90000个键值对所占用的空间。
每个dictEntry占据的空间包括:
- dictEntry: 24字节,jemalloc会分配32字节的内存块
- key: 7字节,所以SDS(key)需要7+9=16个字节,jemalloc会分配16字节的内存块
- redisObject: 16字节,jemalloc会分配16字节的内存块
- value: 7字节,所以SDS(value)需要7+9=16个字节,jemalloc会分配16字节的内存块
- bucket空间:bucket数组的大小为大于90000的最小的2^n,是131072;每个bucket元素为8字节(因为64位系统中指针大小为8字节)。
综上:M = (32 + 16 + 16 + 16) * 90000 + 131072 * 80 = 8248576
验证代码如下:

3. redis 持久化:
Redis有两种持久化方式,AOF和RDB,AOF持久化是指追加写命令到aof文件的方式,RDB是指定期保存内存快照到rdb文件的方式。
RDB虽然可以通过bgsave指令后台保存快照,但fork()子进程是有开销的,在内存数据集较大的情况下会占用很长的cpu时间,fork新进程时,虽然可共享的数据内容不需要复制,但会复制之前进程空间的内存页表,如果内存空间有40G(考虑每个页表条目消耗 8 个字节),那么页表大小就有80M,这个复制是需要时间的,在有的服务器结点上测试,35G的数据bgsave瞬间会阻塞200ms以上,一般建议Redis使用内存不超过20g。I/O消耗,我们线上是在Slave节点开启rdb持久化,磁盘性能一般,1.2g的rdb文件持久化一分钟一次,一次大概耗时30s左右,所以rdb的频率也不能太频繁,需要根据情况做好配置。
AOF是追加写命令到aof文件的方式,优点是可以基本做到数据无损,缺点是文件增长较快,需要间歇性bgrewrite,bgrewrite也是一个既耗cpu又耗磁盘IO的操作,单cpu利用率最高可达100%。bgrewrite期间可以设置将新的写请求暂时缓存,bgrewrite完成后同步写盘,同步会暂时停止处理客户端请求,如果bgrewrite时间较长,缓冲区积压数据较多,核心阻塞时间会很长,所以如果必须要开启aof,一般建议找几个空闲时段设置脚本来做bgrewrite。
AOF还有一个比较坑的地方是刷盘策略fsync的设置,这个设置一般有3种方式:always、everysec、no,如果设置为no,就将写盘的时机交给操作系统,这在很大程度上牺牲了aof数据无损的优势,如果设置为always就意味着每条命令都会同步刷盘,会造成频繁I/O,所以一般建议是设置everysec,Redis会默认每隔一秒进行一次fsync调用,将缓冲区中的数据写到磁盘。但是当这一次的fsync调用时长超过1秒时。Redis会采取延迟fsync的策略,再等一秒钟。也就是在两秒后再进行fsync,这一次的fsync就不管会执行多长时间都会进行。
3.1 持久化策略选择
持久化为Redis提供了异常情况下的数据恢复机制,但开启持久化是有代价的,哪一种持久化都可能造成CPU卡顿,影响对客户端请求的处理。不开启持久化又存在风险,如果一旦误重启master节点,或者试想这样一种场景,主从切换失败,很可能因为疏忽直接重启master,这时没有开启持久化的master会把所有slave的数据清0。所以是否开启持久化,怎样开启持久化是一个难题。和运维同事探讨了一些方案,这里总结一下供大家参考:
1、极端情况下可以容忍全量数据丢失,那么建议master关闭持久化,slave关闭持久化;
2、极端情况下不能容忍全量数据丢失,但可以容忍部分数据丢失,如果内存数据集较小且不会增长建议master开启rdb,slave开启rdb;如果数据集很大,或不确定数据集增长趋势,建议master关闭持久化,slave开启rdb
开启rdb需要cpu和磁盘性能保障。如果master关闭持久化,slave开启rdb需要保证slave的rdb不会被master误重启所覆盖,这里提供几种方案:
- 重启脚本包一层命令先网络请求加载备机备份目录下的rdb文件后再执行start,可以防止误重启,但备机调整部署可能需要调整脚本,主机打开持久化也需要调整脚本
- 定时将rdb文件通过网络io传给master节点(文件大比较耗时,文件增长需要考虑定时脚本执行间隔,否则会造成持续的网络io),而且也会有一定数据损失
- 定时备份Slave的rdb到备份目录,不做任何其他操作,误重启时人工拷贝rdb到master节点(会有一定数据损失)
3、最大限度需要数据无损,建议master开启aof,slave开启aof
开启aof需要cpu和磁盘性能保障。开启aof建议fsync同步刷盘使用everysec,自定义脚本在应用空闲时定时做bgrewrite,bgrewrite期间增量数据做缓冲。
4. 集群解决方案
Redis是一个内存数据库,也就是说存储数据的容量不能超过主机内存大小。普通主机服务器的内存一般几十G,但是我们需要存储大容量的数据(比如上百G的数据)怎么办? 由于内存大小的限制,使用一台 Redis 实例显然无法满足需求,这时就需要使用 多台 Redis (集群)作为缓存数据库,才能在用户请求时快速的进行响应。
4.1 类 codis 的架构
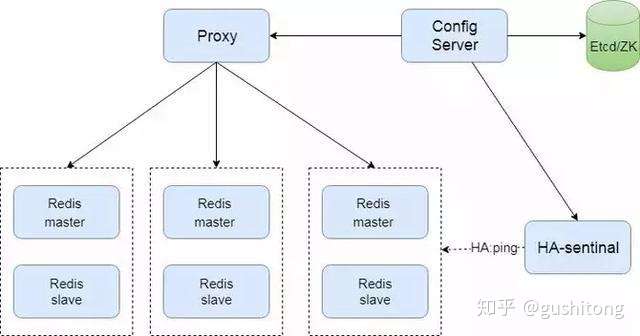
- 分片算法:基于 slot hash 桶;
- 分片实例之间相互独立,每组 一个 master 实例和多个 slave;
- 路由信息存放到第三方存储组件,如 zookeeper 或 etcd
- 旁路组件探活;
slot的迁移方案:
slots 方案:划分了 1024 个 slot, slots 信息在 proxy 层感知; redis 进程中维护本实例上的所有 key 的一个 slot map;
迁移过程中的读写冲突处理:最小迁移单位为 key; 访问逻辑都是先访问 src 节点,再根据结果判断是否需要进一步访问 target 节点;
访问的 key 还未被迁移:读写请求访问 src 节点,处理后访问:
访问的 key 正在迁移:读请求访问 src 节点后直接返回; 写请求无法处理,返回 retry
访问的 key 已被迁移 (或不存在):读写请求访问 src 节点,收到 moved 回复,继续访问 target 节点处理
4.2 基于官方redis cluster的方案
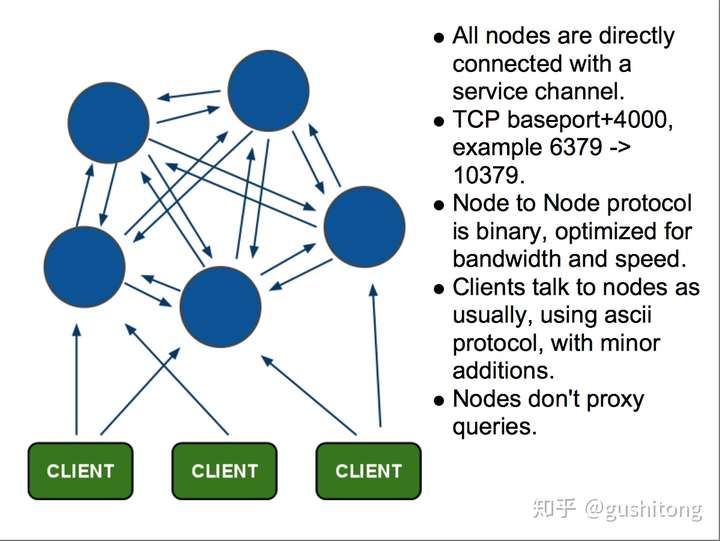
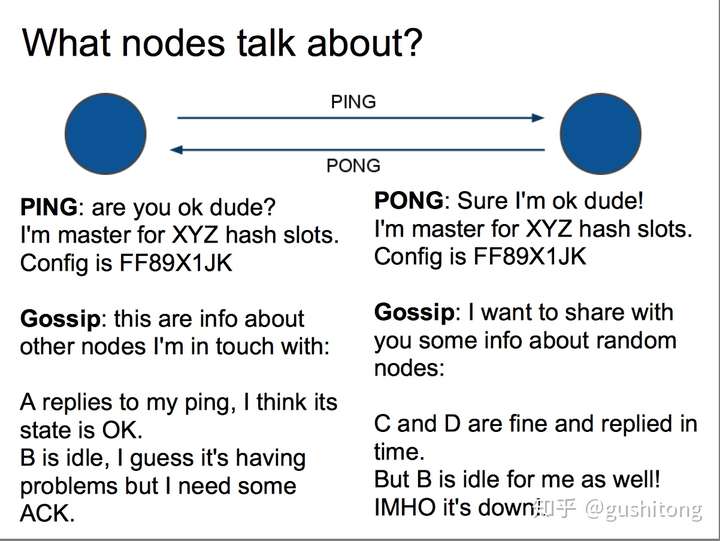
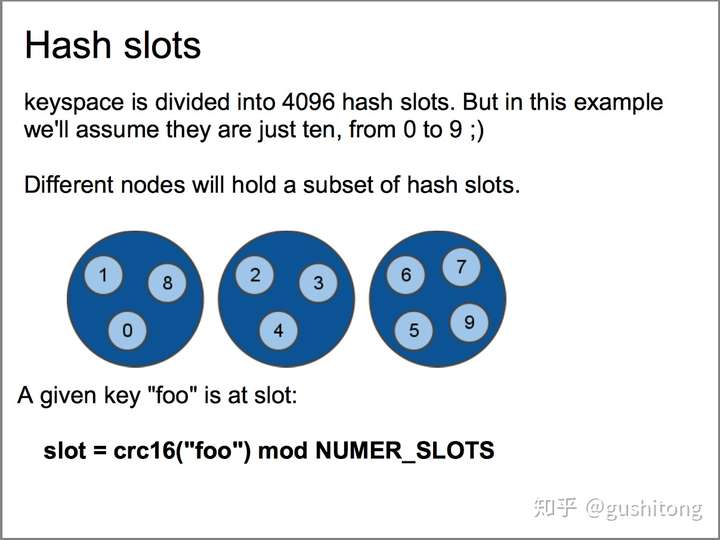
特点:
- 无中心架构,支持动态扩容,对业务透明
- 具备Sentinel的监控和自动Failover能力
- 客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- 高性能,客户端直连redis服务,免去了proxy代理的损耗
缺点是不兼容原有客户端,未在生产环境中大规模验证,运维也很复杂,数据迁移需要人工干预,只能使用0号数据库,不支持批量操作,分布式逻辑和存储模块耦合等。
参考链接:
Redis Protocol specification - Redisredis.iohttps://redis.io/presentation/Redis_Cluster.pdfredis.io深入学习Redis(1):Redis内存模型 - 编程迷思 - 博客园www.cnblogs.com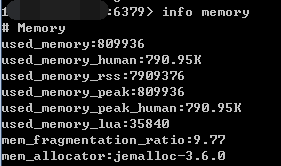
转载于:https://www.cnblogs.com/davidwang456/articles/11258196.html
redis internal【转】相关推荐
- 在CentOS 6.9 x86_64的OpenResty 1.13.6.1上使用基于Redis实现动态路由示例
下面是我阅读春哥OpenResty官网主页中"Dynamic Routing Based On Redis"一节的实操记录,整理如下. https://openresty.org/ ...
- srcache_nginx redis 构建缓存系统应用一例
为什么80%的码农都做不了架构师?>>> srcache_nginx模块相关参数介绍,可以参见 <memc_nginx+srcache_nginx+memcached构建 ...
- nginx+redis 实现 jsp页面缓存,提升系统吞吐率
最近在开发的时候,发现之前APP客户端的一部分页面用的是webview交互,这些页面请求很多,打开一套试卷,将会产生100+的请求量,导致系统性能下降.于是考虑在最靠近客户端的Nginx服务器上做Re ...
- 用lua扩展你的Nginx(写的非常好)
一. 概述 Nginx是一个高性能,支持高并发的,轻量级的web服务器.目前,Apache依然web服务器中的老大,但是在全球前1000大的web服务器中,Nginx的份额为22.4%.Nginx采用 ...
- 用lua扩展你的Nginx(整理)
首先得声明.这不是我的原创,是在网上搜索到的一篇文章,原著是谁也搞不清楚了.按风格应该是属于章亦春的文章. 整理花了不少时间,所以就暂写成原创吧. 一. 概述 Nginx是一个高性能.支持高并发的,轻 ...
- 云原生yaml部署harbor
云原生yaml部署harbor 1 .创建自定义证书 安装 Harbor 我们会默认使用 HTTPS 协议,需要 TLS 证书,如果我们没用自己设定自定义证书文件,那么 Harbor 将自动创建证书文 ...
- Kubernetes 集群仓库 Harbor Helm3 部署
文章目录 Kubernetes 集群仓库 harbor Helm3 部署 一.简介 二.先决条件 三.准备环境 1.系统环境 2.核实动态存储 3.安装 Helm3 3.1.在线安装 3.2.下载安装 ...
- DEVOPS架构师 -- 03Kubernetes进阶实践
文章目录 第三天 Kubernetes进阶实践 ETCD常用操作 Kubernetes调度 为何要控制Pod应该如何调度 调度的过程 Cordon NodeSelector nodeAffinity ...
- 在 Kubernetes 中部署高可用 Harbor 镜像仓库
该文章随时会有校正更新,公众号无法更新,欢迎订阅博客查看最新内容:https://fuckcloudnative.io 前言 系统环境: kubernetes 版本:1.18.10 Harbor Ch ...
最新文章
- 谈谈弹性Web托管的“弹性”
- 单元测试以及dagger的使用
- 高并发编程-Thread_正确关闭线程的三种方式
- 语音识别-过零率和短时能量-端点检测
- 【笔记】Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to La
- 什么是 APT 攻击
- php获取回调url方法,php回调函数的实现方法介绍(代码)
- Linux20180528 apache结合php 虚拟主机
- 【OpenCV】OpenCV函数精讲之 -- 通道合并:merge()函数
- Postman最被低估的功能,自动化接口测试效率简直无敌!
- maven依赖avro_avro序列化详细操作
- [转]mysql慢查询日志
- 中琛源主要的产品是什么
- windows交互式登陆
- 1、使用Keras构建图像分类器
- APEX 文件格式学习记录
- Oracle Database-基础及查询部分
- 自定义View将圆角矩形绘制在Canvas上
- 对量子态和运算的一些基础认识
- 无法解析 maven包的问题
热门文章
- python图书馆管理系统实验报告_基于Python的图书馆业务报表自动生成研究
- lighttpd+fastcgi 返回500错误码_阿根廷著名电视减肥冠军去世 临终前体重达到500公斤...
- opsforhash 过期时间_药品过期还能吃吗?本文带你秒懂药品有效期~
- 二值化图像的欧拉数_Android OpenCV(八):图像二值化
- stm32怎么加载字库_收藏 | STM32单片机超详细学习汇总资料(二)
- 转 Oracle 删除表,oracle 中删除表 drop delete truncate 的区别
- php$pat,PHP的Session管理框架 patSession | 码农软件 - 码农网
- xa 全局锁_fescar锁设计和隔离级别的理解
- file 选择的文件胖多有多大_「HTML5 进阶」FileAPI 文件操作实战,内附详细案例,建议收藏...
- dnf强化卷代码_DNF:夏日套时装礼盒开服竟卖八千万金币,500万捡漏到黄金书