KMP字符串模式匹配详解
KMP字符串模式匹配详解
int Index_BF ( char S [ ], char T [ ], int pos )
{
/* 若串 S 中从第pos(S 的下标0≤pos<StrLength(S))个字符
起存在和串 T 相同的子串,则称匹配成功,返回第一个
这样的子串在串 S 中的下标,否则返回 -1 */
int i = pos, j = 0;
while ( S[i+j] != '/0'&& T[j] != '/0')
if ( S[i+j] == T[j] )
j ++; // 继续比较后一字符
else
{
i ++; j = 0; // 重新开始新的一轮匹配
}
if ( T[j] == '/0')
return i; // 匹配成功 返回下标
else
return -1; // 串S中(第pos个字符起)不存在和串T相同的子串
} // Index_BF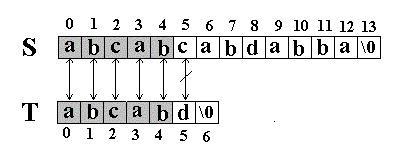
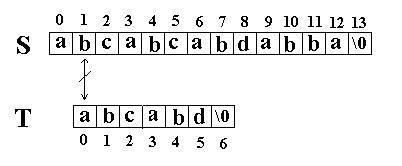
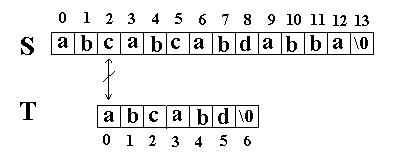
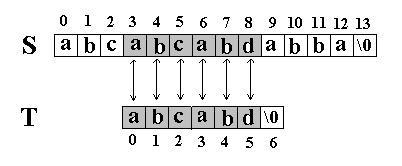
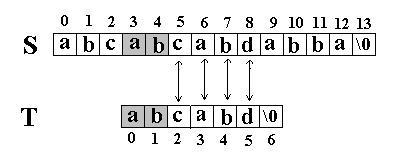
|
下标
|
0
|
1
|
2
|
3
|
4
|
|
T
|
a
|
b
|
c
|
a
|
c
|
|
next
|
-1
|
0
|
0
|
-1
|
1
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
|
T
|
a
|
b
|
c
|
a
|
b
|
|
next
|
-1
|
0
|
0
|
-1
|
0
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
T
|
a
|
b
|
a
|
b
|
c
|
a
|
a
|
b
|
c
|
|
next
|
-1
|
0
|
-1
|
0
|
2
|
-1
|
1
|
0
|
2
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
|
T
|
a
|
b
|
C
|
a
|
b
|
C
|
a
|
d
|
|
next
|
-1
|
0
|
0
|
-1
|
0
|
0
|
-1
|
4
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
|
T
|
a
|
d
|
C
|
a
|
d
|
C
|
a
|
d
|
|
next
|
-1
|
0
|
0
|
-1
|
0
|
0
|
-1
|
0
|
void get_nextval(const char *T, int next[])
{// 求模式串T的next函数值并存入数组 next。int j = 0, k = -1;next[0] = -1;while ( T[j/*+1*/] != '/0' ){if (k == -1 || T[j] == T[k]){++j; ++k;if (T[j]!=T[k])next[j] = k;elsenext[j] = next[k];}// ifelsek = next[k];}// while这里是我加的显示部分// for(int i=0;i<j;i++)//{// cout<<next[i];//}//cout<<endl;
}// get_nextval
另一种写法,也差不多。
void getNext(const char* pattern,int next[])
{next[0]= -1;int k=-1,j=0;while(pattern[j] != '/0'){if(k!= -1 && pattern[k]!= pattern[j] )k=next[k];++j;++k;if(pattern[k]== pattern[j])next[j]=next[k];elsenext[j]=k;}这里是我加的显示部分// for(int i=0;i<j;i++)//{// cout<<next[i];//}//cout<<endl;
}
下面是KMP模式匹配程序,各位可以用他验证。记得加入上面的函数
#include <iostream.h>
#include <string.h>
int KMP(const char *Text,const char* Pattern) //const 表示函数内部不会改变这个参数的值。
{if( !Text||!Pattern|| Pattern[0]=='/0' || Text[0]=='/0' )//return -1;//空指针或空串,返回-1。int len=0;const char * c=Pattern;while(*c++!='/0')//移动指针比移动下标快。{ ++len;//字符串长度。}int *next=new int[len+1];get_nextval(Pattern,next);//求Pattern的next函数值int index=0,i=0,j=0;while(Text[i]!='/0' && Pattern[j]!='/0' ){if(Text[i]== Pattern[j]){++i;// 继续比较后继字符++j;}else{index += j-next[j];if(next[j]!=-1)j=next[j];// 模式串向右移动else{j=0;++i;}}}//whiledelete []next;if(Pattern[j]=='/0')return index;// 匹配成功elsereturn -1;
}
int main()//abCabCad
{char* text="bababCabCadcaabcaababcbaaaabaaacababcaabc";char*pattern="adCadCad";//getNext(pattern,n);//get_nextval(pattern,n);cout<<KMP(text,pattern)<<endl;return 0;
}|
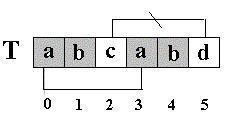
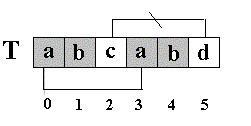
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
T
|
a
|
b
|
a
|
b
|
c
|
a
|
a
|
b
|
c
|
|
(1) next
|
-1
|
0
|
-1
|
0
|
2
|
-1
|
1
|
0
|
2
|
|
(2) next
|
-1
|
0
|
0
|
1
|
2
|
0
|
1
|
1
|
2
|
|
(3) next
|
0
|
1
|
0
|
1
|
3
|
0
|
2
|
1
|
3
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
|
T
|
a
|
b
|
c
|
A
|
c
|
|
(1)next
|
-1
|
0
|
0
|
-1
|
1
|
|
(2)next
|
-1
|
0
|
0
|
0
|
1
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
|
T
|
a
|
d
|
C
|
a
|
d
|
C
|
a
|
d
|
|
(1)next
|
-1
|
0
|
0
|
-1
|
0
|
0
|
-1
|
0
|
|
(2)next
|
-1
|
0
|
0
|
0
|
1
|
2
|
3
|
4
|
void myget_nextval(const char *T, int next[])
{// 求模式串T的next函数值(第二种表示方法)并存入数组 next。 int j = 1, k = 0;next[0] = 0;while ( T[j] != '/0' ){ if(T[j] == T[k]){next[j] = k;++j; ++k; }else if(T[j] != T[0]){next[j] = k;++j;k=0;}else{next[j] = k;++j;k=1;}}//whilefor(int i=0;i<j;i++){cout<<next[i];}cout<<endl;
}// myget_nextval下面是模式值使用第二种表示方法的匹配函数(next[0]=0)
int my_KMP(char *S, char *T, int pos)
{
int i = pos, j = 0;//pos(S 的下标0≤pos<StrLength(S))
while ( S[i] != '/0' && T[j] != '/0' )
{if (S[i] == T[j] ){++i;++j; // 继续比较后继字符}else // a b a b c a a b c// 0 0 0 1 2 0 1 1 2{ //-1 0 -1 0 2 -1 1 0 2i++;j = next[j]; /*当出现S[i] !=T[j]时,下一次的比较应该在S[i]和T[next[j]] 之间进行。要求next[0]=0。
在这两个简单示范函数间使用全局数组next[]传值。*/}
}//while
if ( T[j] == '/0' )return (i-j); // 匹配成功
elsereturn -1;
} // my_KMPKMP字符串模式匹配详解相关推荐
- KMP字符串模式匹配详解(zz)
刚看到位兄弟也贴了份KMP算法说明,但本人觉得说的不是很详细,当初我在看这个算法的时候也看的头晕昏昏的,我贴的这份也是网上找的. 且听详细分解: KMP字符串模式匹配详解 来自CSDN A_B ...
- 数据结构 串 KMP 模式匹配详解 通俗易懂
KMP 模式匹配详解通俗易懂 KMP 模式匹配是解决字符串匹配的问题 一.原始的字符串暴力匹配 要点:子串的第一个字符匹配成功主串的字符后就依次匹配子串后面的字符,直到子串匹配结束 代码: publi ...
- [转]数据结构KMP算法配图详解(超详细)
KMP算法配图详解 前言 KMP算法是我们数据结构串中最难也是最重要的算法.难是因为KMP算法的代码很优美简洁干练,但里面包含着非常深的思维.真正理解代码的人可以说对KMP算法的了解已经相当深入了.而 ...
- 数据结构KMP算法配图详解(超详细)
KMP算法配图详解 前言 KMP算法是我们数据结构串中最难也是最重要的算法.难是因为KMP算法的代码很优美简洁干练,但里面包含着非常深的思维.真正理解代码的人可以说对KMP算法的了解已经相当深入了.而 ...
- Java正则表达式及字符串处理详解
java正则表达式及字符串处理详解 本篇博文主要是对java String类涉及正则表达式方法及java.util.regex包中相关类和方法的一个总结 String类 相关方法 boolean ma ...
- iOS富文本字符串AttributedString详解
原文链接: iOS富文本字符串AttributedString详解 简书主页:http://www.jianshu.com/users/37f2920f6848 Github主页:https://gi ...
- mysql数据库的字符串表示什么意思_MySQL数据库的字符串类型详解(01)
Mysql的数据类型主要分为三类:数字类型.字符串(字符)类型.日期和时间类型,由于时间紧迫,根据学习的需要 数字类型暂不做详解,等待有时间了在修改此文档,此文主要介绍mysql 数据类型中的字符串类 ...
- Python 字符串方法详解
Python 字符串方法详解 本文最初发表于赖勇浩(恋花蝶)的博客(http://blog.csdn.net/lanphaday),如蒙转载,敬请保留全文完整,切勿去除本声明和作者信息. 在编程中,几 ...
- BAT批处理中的字符串处理详解(字符串截取)
BAT批处理中的字符串处理详解(字符串截取 批处理有着具有非常强大的字符串处理能力,其功能绝不低于C语言里面的字符串函数集.批处理中可实现的字符串处理功能有:截取字符串内容.替换字符串特定字段.合并字 ...
最新文章
- PHP Webservice的发布与调用
- 大概了解了flexbox
- CenterNet 读书笔记
- 跟我一起写udev规则
- 002_SpringBoot整合Servlet
- C语言从青铜到王者——基础知识总结
- a5松下驱动器参数设置表_松下伺服几个参数需要熟悉并掌握设置方法
- 我的2015羊年总结
- go环境搭建_容器化 Go 开发环境的尝试
- air中wav转mp3
- centos操作---搭建环境 安装python
- java中StringBuilder为单线程做的,StringBuffer相反
- oracle卸载步骤图解,Oracle详细卸载步骤
- Java蓝桥杯 算法提高 九宫格
- mysql error 1114,MySQL错误1114“表已满”使用MyISAM引擎
- 从事分布式工作10余年,这本书颠覆了我的认知 | 文末赠书
- 每日一篇系列---CSS3实现下雨动效
- 计算机专业山东省内大学排名,山东计算机科学与技术专业大学排名 2020年省内录取分数线...
- 2020 社招 JAVA面试题总结
- 辐射76 服务器离线维护,如果能有离线模式 完善《辐射76》的9种方法
热门文章
- USB基础---设备、配置、接口、端点和字符串描述符
- windows 3.x编程指南_18000 MHz 可编程衰减器
- Python文件基本操作
- iOS Icon Size 快速得到三种大小的图标
- 跨界创立PayPal、特斯拉、SpaceX……,埃隆·马斯克是这样“掌控”知识的
- Secure-CRT使用技巧
- 用C#访问Hotmail -转
- error while loading shared libraries: xxx.so.0:cannot open shared object file: No such file or
- 【Python学习系列二十一】pandas库基本操作
- 机器学习知识点(三十五)蒙特卡罗方法