如何使用SpanReporter接口生成链路数据
引言
Spring-Cloud-Sleuth作为微服务链路跟踪组件,默认的实现方式是RestTemplate的调用链路跟踪。
原有项目中调用外部服务接口大多数采用的是使用了第三方的HttpClient库,如:Apache HttpClient或Asynchronous Http Client。
为了保证不影响现有业务接口的稳定性和少量的代码修改达到链路跟踪目的,接下来本文会介绍改造的过程。
原理分析
有关分布式服务链路跟踪的技术论文请参考Google Dapper,Zipkin是一种分布式跟踪系统。它有助于收集解决微服务架构中的延迟问题所需的时序数据,它管理这些数据的收集和查找,Zipkin的设计也是基于Google Dapper论文的,关于Zipkin的介绍请参考zipkin官方文档,此处不做过多的赘述,具体的架构图如下所示:
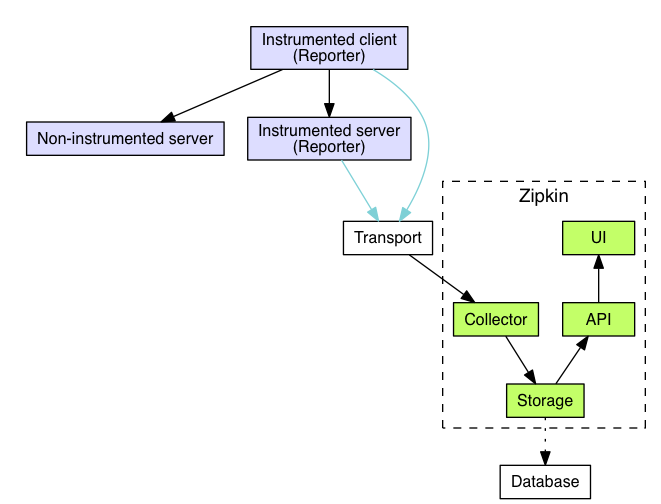
Spring-Cloud-Sleuth-Zipkin是SpringCloud体系提供的分布服务链路追踪集成套件,它基于zipkin本身的原理和Spring的特点进行有效的集成,使应用上更加的灵活方便。
Span是基本工作单元。例如,发送RPC是一个新的跨度,就像向RPC发送响应一样。跨度由跨度的唯一64位ID和跨度为其一部分的跟踪的另一个64位ID标识。Spans还有其他数据,例如描述,键值注释,导致它们的跨度的ID以及进程ID(通常是IP地址)。跨度启动和停止,他们跟踪他们的时间信息。创建跨度后,必须在将来的某个时刻停止它。一组跨度形成一个称为Trace的树状结构。例如,如果您正在运行分布式大数据存储,则可能会由put请求形成跟踪。
SpringCloud-Sleuth的主要特性包括:
- 将跟踪和跨度ID添加到Slf4J MDC,因此您可以从日志聚合器中的给定跟踪或跨度中提取所有日志。
- 提供对常见分布式跟踪数据模型的抽象:跟踪,跨距(形成DAG),注释,键值注释。松散地基于HTrace,但兼容Zipkin(Dapper)。
- 如果spring-cloud-sleuth-zipkin可用,则该应用程序将通过HTTP生成并收集与Zipkin兼容的跟踪。默认情况下,它将它们发送到localhost(端口9411)上的Zipkin收集器服务。使用spring.zipkin.baseUrl配置服务的位置。
通过它的特性可以看出它简化了应用程序的接入,在我们应用程序中只需要在应用程序主配置文件application.properties中添加相应的属性配置和相关的Maven依赖库即可快速的接入,常见的配置信息如下所示:
# 采样率,最大为1.0
spring.sleuth.sampler.percentage=0.1
## 配置消息发送方的消息类型,支持web(http),rabbitMQ,kafka
spring.zipkin.sender.type=kafka
## 配置kafka消息主题
spring.zipkin.kafka.topic=zipkin
## 配置kafka集群节点
spring.kafka.bootstrapServers=192.168.9.16:9092,192.168.9.17:9092,192.168.9.18:9092对于Maven的第三方依赖如下所示:
<dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sleuth</artifactId><version>Edgware.SR5</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>了解了基本的原理和配置后,我们来看看应用程序如何接入?
其实很简单,只要Spring Cloud Sleuth位于类路径上,任何Spring Boot应用程序都将生成跟踪数据,具体的示例代码如下:
@SpringBootApplication
@RestController
public class Application {private static Logger log = LoggerFactory.getLogger(DemoController.class);@RequestMapping("/")public String home() {log.info("Handling home");return "Hello World";}public static void main(String[] args) {SpringApplication.run(Application.class, args);}}运行此应用程序,然后点击主页。您将在日志中看到填充了traceId和spanId。如果这个应用程序调用另一个应用程序(例如使用RestTemplate),它将在标头中发送跟踪数据,如果接收器是另一个Sleuth应用程序,您将看到整个跟踪的过程。
业务需求
上述的实现方式都是基于RestTemplate接口的情况,现在我们回到文章最开始我们要解决的问题,旧有项目采用的是其它的方式来调用外部服务接口的,我们不可能将所有的业务接口重新按照RestTemplate重新实现一遍,这样研发的同学、测试同学、产品同学甚至上层都会有很大的意见,因为这样的改动不只是要投入研发人力去改动接口且接口的稳定性也会受到影响,原本稳定运行的接口由于改动测试的同学需要重新对业务接口做回归测试等等。
基于上述的原因,所以需要寻求一种折中方案,如何保证不修改原有业务接口代码的情况下加入少量的代码生成服务链路跟踪数据并进行存储。
解决方案
阅读Spring-Cloud-sleuth-zipkin的源码发现ZipkinSpanReporter实现了SpanReporter接口,该接口的主要作用是监听Sleuth的事件,然后通过report方法创建zipkin Span对象报告给Zipkin收集器,具体实现代码如下:
public class ZipkinSpanReporter implements SpanReporter {private static final org.apache.commons.logging.Log log = org.apache.commons.logging.LogFactory.getLog(ZipkinSpanReporter.class);private final Reporter<zipkin2.Span> reporter;private final Environment environment;private final List<SpanAdjuster> spanAdjusters;/*** Endpoint is the visible IP address of this service, the port it is listening on and* the service name from discovery.*/// Visible for testingfinal EndpointLocator endpointLocator;public ZipkinSpanReporter(Reporter<zipkin2.Span> reporter, EndpointLocator endpointLocator,Environment environment, List<SpanAdjuster> spanAdjusters) {this.reporter = reporter;this.endpointLocator = endpointLocator;this.environment = environment;this.spanAdjusters = spanAdjusters;}/*** Converts a given Sleuth span to a Zipkin Span.* <ul>* <li>Set ids, etc* <li>Create timeline annotations based on data from Span object.* <li>Create tags based on data from Span object.* </ul>*/// Visible for testingzipkin2.Span convert(Span span) {//TODO: Consider adding support for the debug flag (related to #496)Span convertedSpan = span;for (SpanAdjuster adjuster : this.spanAdjusters) {convertedSpan = adjuster.adjust(convertedSpan);}zipkin2.Span.Builder zipkinSpan = zipkin2.Span.newBuilder();zipkinSpan.localEndpoint(this.endpointLocator.local());processLogs(convertedSpan, zipkinSpan);addZipkinTags(zipkinSpan, convertedSpan);if (zipkinSpan.kind() != null && this.environment != null) {setInstanceIdIfPresent(zipkinSpan, Span.INSTANCEID);}zipkinSpan.shared(convertedSpan.isShared());zipkinSpan.timestamp(convertedSpan.getBegin() * 1000L);if (!convertedSpan.isRunning()) { // duration is authoritative, only write when the span stoppedzipkinSpan.duration(calculateDurationInMicros(convertedSpan));}zipkinSpan.traceId(convertedSpan.traceIdString());if (convertedSpan.getParents().size() > 0) {if (convertedSpan.getParents().size() > 1) {log.error("Zipkin doesn't support spans with multiple parents. Omitting "+ "other parents for " + convertedSpan);}zipkinSpan.parentId(Span.idToHex(convertedSpan.getParents().get(0)));}zipkinSpan.id(Span.idToHex(convertedSpan.getSpanId()));if (StringUtils.hasText(convertedSpan.getName())) {zipkinSpan.name(convertedSpan.getName());}return zipkinSpan.build();}// Instead of going through the list of logs multiple times we're doing it only oncevoid processLogs(Span span, zipkin2.Span.Builder zipkinSpan) {for (Log log : span.logs()) {String event = log.getEvent();long micros = log.getTimestamp() * 1000L;// don't add redundant annotations to the outputif (event.length() == 2) {if (event.equals("cs")) {zipkinSpan.kind(zipkin2.Span.Kind.CLIENT);} else if (event.equals("sr")) {zipkinSpan.kind(zipkin2.Span.Kind.SERVER);} else if (event.equals("ss")) {zipkinSpan.kind(zipkin2.Span.Kind.SERVER);} else if (event.equals("cr")) {zipkinSpan.kind(zipkin2.Span.Kind.CLIENT);} else if (event.equals("ms")) {zipkinSpan.kind(zipkin2.Span.Kind.PRODUCER);} else if (event.equals("mr")) {zipkinSpan.kind(zipkin2.Span.Kind.CONSUMER);} else {zipkinSpan.addAnnotation(micros, event);}} else {zipkinSpan.addAnnotation(micros, event);}}}private void setInstanceIdIfPresent(zipkin2.Span.Builder zipkinSpan, String key) {String property = defaultInstanceId();if (StringUtils.hasText(property)) {zipkinSpan.putTag(key, property);}}String defaultInstanceId() {return IdUtils.getDefaultInstanceId(this.environment);}/*** Adds tags from the sleuth Span*/private void addZipkinTags(zipkin2.Span.Builder zipkinSpan, Span span) {Endpoint.Builder remoteEndpoint = Endpoint.newBuilder();boolean shouldAddRemote = false;// don't add redundant tags to the outputfor (Map.Entry<String, String> e : span.tags().entrySet()) {String key = e.getKey();if (key.equals("peer.service")) {shouldAddRemote = true;remoteEndpoint.serviceName(e.getValue());} else if (key.equals("peer.ipv4") || key.equals("peer.ipv6")) {shouldAddRemote = true;remoteEndpoint.ip(e.getValue());} else if (key.equals("peer.port")) {shouldAddRemote = true;try {remoteEndpoint.port(Integer.parseInt(e.getValue()));} catch (NumberFormatException ignored) {}} else {zipkinSpan.putTag(e.getKey(), e.getValue());}}if (shouldAddRemote) {zipkinSpan.remoteEndpoint(remoteEndpoint.build());}}/*** There could be instrumentation delay between span creation and the* semantic start of the span (client send). When there's a difference,* spans look confusing. Ex users expect duration to be client* receive - send, but it is a little more than that. Rather than have* to teach each user about the possibility of instrumentation overhead,* we truncate absolute duration (span finish - create) to semantic* duration (client receive - send)*/private long calculateDurationInMicros(Span span) {Log clientSend = hasLog(Span.CLIENT_SEND, span);Log clientReceived = hasLog(Span.CLIENT_RECV, span);if (clientSend != null && clientReceived != null) {return (clientReceived.getTimestamp() - clientSend.getTimestamp()) * 1000;}return span.getAccumulatedMicros();}private Log hasLog(String logName, Span span) {for (Log log : span.logs()) {if (logName.equals(log.getEvent())) {return log;}}return null;}@Overridepublic void report(Span span) {if (span.isExportable()) {this.reporter.report(convert(span));} else {if (log.isDebugEnabled()) {log.debug("The span " + span + " will not be sent to Zipkin due to sampling");}}}@Overridepublic String toString(){return "ZipkinSpanReporter(" + this.reporter + ")";}
}当调用report方法时会调用内部的convert函数生成符合zikin2 Span的数据结构。然后数据采集将span数据交给存储组件存储。
了解了基本的原理和工作流程,我们就可以通过SpanReporter接口在我们的业务代码中使用report方法创建链路跟踪数据了,以下是具体的实现代码:
@Autowired
private SpanReporter reporter;public User getUserBySsoid(Integer ssoid) {String requestUrl = reconstructURL(setting.API_User_Profile);User user = new User();String url = MessageFormat.format(requestUrl, String.valueOf(ssoid));log.info(MessageFormat.format("通过ssoid:[{0}] 获取用户信息,url:[{1}]", ssoid, url));try {Response response = httpComponent.syncHttpRequest(url, null, RequestMethod.GET);if (response.getStatusCode() != 200) {throw new Exception("查找用户信息接口出错,code: " + response.getStatusCode());}String data = response.getResponseBody();JSONObject object = JSONObject.parseObject(data);JSONObject userObject = object.getJSONObject("data");user = JSON.parseObject(userObject.toString(), User.class);} catch (Exception e) {log.error(MessageFormat.format("通过ssoid:[{0}] 获取用户信息出错,url:[{1}],错误信息:{2}", ssoid, url, e.toString()));}reporter.report(Span.builder().name(url).build());return user;
}上述的reporter.report(Span.builder().name(url).build());主要的作用是根据请求的URL地址构建SpringCloud-Sleuth Span对象,然后通过Spring-Cloud-sleuth-zipkin SpanReporter接口的report方法创建链路跟踪数据。
由于项目本身采用的数据采集存储组件为kafka,所以需要在我们的应用程序配置文件application.properties中添加如下配置:
spring.sleuth.sampler.percentage=0.1
## 配置消息发送方的消息类型,支持web(http),rabbitMQ,kafka
spring.zipkin.sender.type=kafka
## 配置kafka消息主题
spring.zipkin.kafka.topic=zipkin
## 配置kafka集群节点
spring.kafka.bootstrapServers=192.168.9.16:9092,192.168.9.17:9092,192.168.9.18:9092如何使用SpanReporter接口生成链路数据相关推荐
- 写接口文档及生成mock数据
写接口文档及生成mock数据 在web应用开发的过程中,与前端联调时总会有一些接口,需要接口文档,在接口先行的情况下,前端不能拿到实际的接口进行开发,所以就需要mock数据. 今天搜索了下,阿里在这方 ...
- 接口查询的数据生成excel上传到七牛云
接口查询的数据生成excel上传到七牛云 一.注册七牛云并新建一个存储空间 我们公司已经有一个七牛云的账号,登录进去之后创建一个新的对象存储空间.命名为eval_mobile.酒会有一个默认的融合 C ...
- 人工智能对联生成 API 数据接口
人工智能对联生成 API 数据接口 基于百万数据训练,AI 训练与应答,多结果返回. 1. 产品功能 AI 基于百万历史对联数据训练应答模型: 机器学习持续训练学习: 一个上联可返回多个下联应答: 毫 ...
- 全链路数据血缘在满帮的实践
摘要:全链路数据血缘,指在数据的全生命周期内,数据与数据之间会形成各式各样的关系,贯穿整个数据链路中. 本文分享自华为云社区<全链路数据血缘在满帮的实践>,作者: 你好_TT. 什么是全链 ...
- 大批量生成假数据,faker.js获得近28k个Star
整理 | 夕颜 图源 | 视觉中国 来源 | CSDN(ID:CSDNnews) 近日,GitHub上一个生成假数据的项目faker.js火了,攀升Trendinging榜单第二,标星目前已超过27. ...
- Java实现pdf和Excel的生成及数据动态插入、导出
点击上方蓝色"方志朋",选择"设为星标"回复"666"获取独家整理的学习资料! 作者:慢时光 cnblogs.com/Tom-shushu/ ...
- 改用C++生成自动化数据表
改用C++生成自动化数据表 前面的文章中,我们讨论了使用一个基于.NET的第三方程序库来从程序中来生成数据表.在我看来,这整个思路是非常有用的,例如为显示测试结果.我经常会自己在博客中尝试各种像这样的 ...
- 一步一步教你使用AgileEAS.NET基础类库进行应用开发-基础篇-基于接口驱动的数据层...
系列回顾 在前面的文章中,我用了大量的篇幅对UDA及ORM的使用进行了讲解和演示,我们已经知道并熟悉的使用UDA和ORM构建简单的应用,AgileEAS.NET在应用的纵向结构上建议使用分层结构,提出 ...
- vue中如何使用mockjs摸拟接口的各种数据
mockjs的作用 生成模拟数据 模拟 Ajax 请求,返回模拟数据 基于 HTML 模板生成模拟数据(后续更新) 帮助编写单元测试(后续更新) Vue 中使用 mock 有两种使用方式,一种是仅编写 ...
- mock模拟的数据能增删改查吗_使用Swager API Docs和easy-mock生成模拟数据
前面文章已经搭建了本地的easy-mock 本地搭建Easy-Mock实现模拟数据 常见的Mock方式: 将模拟数据直接写在代码里 利用javascript拦截请求 利用Charles.Fiddler ...
最新文章
- WAMPSERVER安装之笑话
- dedecms标签使用
- RecycleView的正确打开方式
- ImageView的scaleType理解
- rust实现wss访问_Rust的所有权,第2部分
- Centos下安装X Window+GNOME Desktop+FreeNX
- Kotlin学习笔记 第二章 类与对象 第五节 可见性 第六节 扩展
- MP3播放器横向比较专题之二:闪存式
- SPSS配对样本t检验
- 论文写作:如何写论文
- 被退回的劳务派遣工需要支付补偿金吗?
- 蓝桥杯之平面切分(几何问题)
- 程序员复工后被裁,600万房21000房贷无力偿还,给年轻人3点忠告
- 吊炸天MyCat入门
- 【SpringBoot】SpringBoot2.x 配置 笔记
- 重上吹麻滩——段芝堂创始人翟立冬游记
- edge浏览器仿真IE时发现的问题
- 硬件行业知识体系概要
- android wi-fi框架,Android Wi-Fi 网络选择
- Intellij idea Ultimate版本学生免费注册使用步骤以及Github学生包