Kafka是靠什么机制保持高可靠,高可用的?
面试大厂时,一旦简历上写了 Kafka,几乎必然会被问到一个问题:说说 Acks 参数对消息持久化的影响?
这个 Acks 参数在 Kafka 的使用中,是非常核心以及关键的一个参数,决定了很多东西。
所以无论是为了面试还是实际项目使用,大家都值得看一下这篇文章对 Kafka 的 Acks 参数的分析,以及背后的原理。
如何保证宕机的时候数据不丢失?
如果想理解这个 Acks 参数的含义,首先就得搞明白 Kafka 的高可用架构原理。
比如下面的图里就是表明了对于每一个 Topic,我们都可以设置它包含几个 Partition,每个 Partition 负责存储这个 Topic 一部分的数据。
然后 Kafka 的 Broker 集群中,每台机器上都存储了一些 Partition,也就存放了 Topic 的一部分数据,这样就实现了 Topic 的数据分布式存储在一个 Broker 集群上。
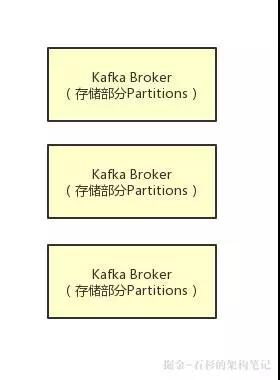
但是有一个问题,万一一个 Kafka Broker 宕机了,此时上面存储的数据不就丢失了吗?
没错,这就是一个比较大的问题了,分布式系统的数据丢失问题,是它首先必须要解决的,一旦说任何一台机器宕机,此时就会导致数据的丢失。
多副本冗余的高可用机制
所以如果大家去分析任何一个分布式系统的原理,比如说 Zookeeper、Kafka、Redis Cluster、Elasticsearch、HDFS,等等。
其实它们都有自己内部的一套多副本冗余的机制,多副本冗余几乎是现在任何一个优秀的分布式系统都一般要具备的功能。
在 Kafka 集群中,每个 Partition 都有多个副本,其中一个副本叫做 Leader,其他的副本叫做 Follower,如下图:
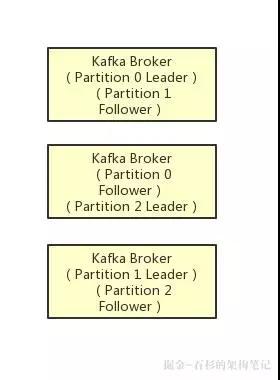
如上图所示,假设一个 Topic 拆分为了 3 个 Partition,分别是 Partition0,Partiton1,Partition2,此时每个 Partition 都有 2 个副本。
比如 Partition0 有一个副本是 Leader,另外一个副本是 Follower,Leader 和 Follower 两个副本是分布在不同机器上的。
这样的多副本冗余机制,可以保证任何一台机器挂掉,都不会导致数据彻底丢失,因为起码还是有副本在别的机器上的。
多副本之间数据如何同步?
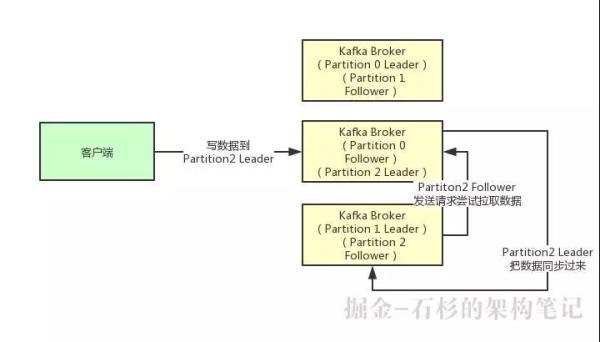
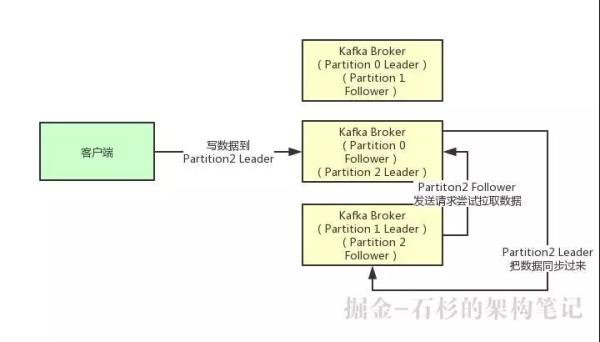
接着我们就来看看多个副本之间数据是如何同步的?其实任何一个 Partition,只有 Leader 是对外提供读写服务的。
也就是说,如果有一个客户端往一个 Partition 写入数据,此时一般就是写入这个 Partition 的 Leader 副本。
然后 Leader 副本接收到数据之后,Follower 副本会不停的给它发送请求尝试去拉取最新的数据,拉取到自己本地后,写入磁盘中。
如下图所示:
ISR 到底指的是什么东西?
既然大家已经知道了 Partiton 的多副本同步数据的机制了,那么就可以来看看 ISR 是什么了。
ISR 全称是“In-Sync Replicas”,也就是保持同步的副本,它的含义就是,跟 Leader 始终保持同步的 Follower 有哪些。
大家可以想一下 ,如果说某个 Follower 所在的 Broker 因为 JVM FullGC 之类的问题,导致自己卡顿了,无法及时从 Leader 拉取同步数据,那么是不是会导致 Follower 的数据比 Leader 要落后很多?
所以这个时候,就意味着 Follower 已经跟 Leader 不再处于同步的关系了。
但是只要 Follower 一直及时从 Leader 同步数据,就可以保证它们是处于同步的关系的。
所以每个 Partition 都有一个 ISR,这个 ISR 里一定会有 Leader 自己,因为 Leader 肯定数据是最新的,然后就是那些跟 Leader 保持同步的 Follower,也会在 ISR 里。
Acks 参数的含义
铺垫了那么多的东西,最后终于可以进入主题来聊一下 Acks 参数的含义了。
如果大家没看明白前面的那些副本机制、同步机制、ISR 机制,那么就无法充分的理解 Acks 参数的含义,这个参数实际上决定了很多重要的东西。
首先这个 Acks 参数,是在 Kafka Producer,也就是生产者客户端里设置的。
也就是说,你往 Kafka 写数据的时候,就可以来设置这个 Acks 参数。然后这个参数实际上有三种常见的值可以设置,分别是:0、1 和 all。
第一种选择是把 Acks 参数设置为 0,意思就是我的 Kafka Producer 在客户端,只要把消息发送出去,不管那条数据有没有在哪怕 Partition Leader 上落到磁盘,我就不管它了,直接就认为这个消息发送成功了。
如果你采用这种设置的话,那么你必须注意的一点是,可能你发送出去的消息还在半路。
结果呢,Partition Leader 所在 Broker 就直接挂了,然后结果你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了。
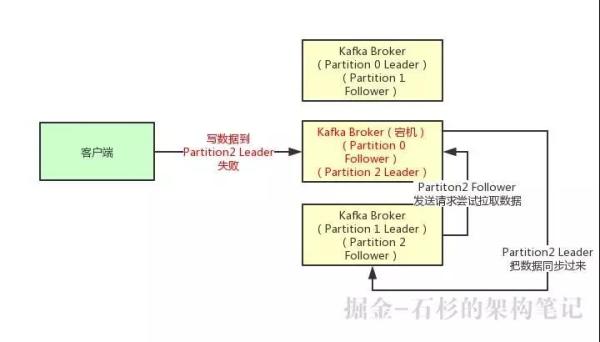
第二种选择是设置 Acks = 1,意思就是说只要 Partition Leader 接收到消息而且写入本地磁盘了,就认为成功了,不管它其他的 Follower 有没有同步过去这条消息了。
这种设置其实是 Kafka 默认的设置,大家请注意,划重点!这是默认的设置。
也就是说,默认情况下,你要是不管 Acks 这个参数,只要 Partition Leader 写成功就算成功。
但是这里有一个问题,万一 Partition Leader 刚刚接收到消息,Follower 还没来得及同步过去,结果 Leader 所在的 Broker 宕机了,此时也会导致这条消息丢失,因为人家客户端已经认为发送成功了。
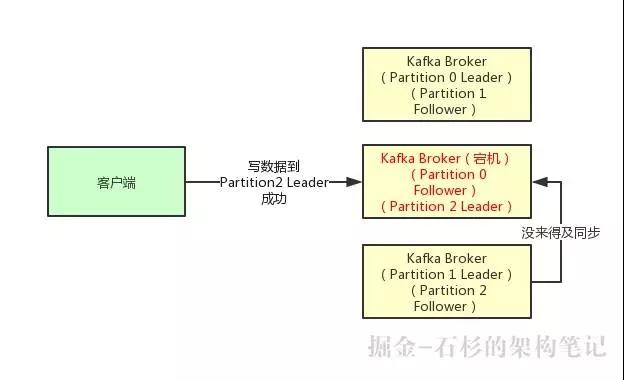
最后一种情况,就是设置 Acks=all,这个意思就是说,Partition Leader 接收到消息之后,还必须要求 ISR 列表里跟 Leader 保持同步的那些 Follower 都要把消息同步过去,才能认为这条消息是写入成功了。
如果说 Partition Leader 刚接收到了消息,但是结果 Follower 没有收到消息,此时 Leader 宕机了,那么客户端会感知到这个消息没发送成功,他会重试再次发送消息过去。
此时可能 Partition2 的 Follower 变成 Leader 了,此时 ISR 列表里只有最新的这个 Follower 转变成的 Leader 了,那么只要这个新的 Leader 接收消息就算成功了。
最后的思考
Acks=all 就可以代表数据一定不会丢失了吗?当然不是,如果你的 Partition 只有一个副本,也就是一个 Leader,任何 Follower 都没有,你认为 acks=all 有用吗?
当然没用了,因为 ISR 里就一个 Leader,它接收完消息后宕机,也会导致数据丢失。
所以说,这个 Acks=all,必须跟 ISR 列表里至少有 2 个以上的副本配合使用,起码是有一个 Leader 和一个 Follower 才可以。
这样才能保证说写一条数据过去,一定是 2 个以上的副本都收到了才算是成功,此时任何一个副本宕机,不会导致数据丢失。
所以希望大家把这篇文章好好理解一下,对大家出去面试,或者工作中用 Kafka 都是很好的一个帮助。
Kafka是靠什么机制保持高可靠,高可用的?相关推荐
- Nginx+Keepalived实现web服务高可靠/高可用
一般情况下,为了提升后台服务性能扩充及高可用,前端用一个nginx做反向代理即可 但是,作为互联网项目,纯2C的话必然需要做整体的高可用,不仅后台服务有N个,Nginx同样需要有N个,一主N备,当有一 ...
- 分布式高可靠消息中间件-Hippo
前言 随着大数据产品的日渐丰富以及数据应用场景需求的增加,TDBank作为腾讯大数据平台的数据接入环节的位置也越发显得重要(见下图).截止目前为止TDBank日均接入数据已经超过2W亿 ...
- Kafka到底有多高可靠?
什么叫可靠性? 大家都知道,系统架构有三高:「高性能.高并发和高可用」,三者的重要性不言而喻. 对于任意系统,想要同时满足三高都是一件非常困难的事情,大型业务系统或者传统中间件都会搭建复杂的架构来保证 ...
- Nginx多进程高并发、低时延、高可靠机制在缓存(redis、memcache)twemproxy代理中的应用...
1. 开发背景 现有开源缓存代理中间件有twemproxy.codis等,其中twemproxy为单进程单线程模型,只支持memcache单机版和redis单机版,都不支持集群版功能. 由于twemp ...
- Nginx多进程高并发、低时延、高可靠机制在滴滴缓存代理中的应用
开发背景 现有开源缓存代理中间件有twemproxy.codis等,其中twemproxy为单进程单线程模型,只支持memcache单机版和redis单机版,都不支持集群版功能. 由于twemprox ...
- Kafka-0.10.0.0 集群高可靠实验
记录实验过程之前,先谈一谈学习Kafka过程的心得. 大数据包含一个生态,需众多组件配合使用.逐个学习各个组件非常费力,想摸索出一种快速入门的方法,可能是每个学习大数据的同学都想要的. 我的方法是,每 ...
- kafka和mysql内存机制_一文五分钟让你彻底理解Kafka架构原理
对于kafka的架构原理我们先提出几个问题? 1.Kafka的topic和分区内部是如何存储的,有什么特点? 2.与传统的消息系统相比,Kafka的消费模型有什么优点? 3.Kafka如何实现分布式的 ...
- Reliable, Scalable, and Maintainable Applications 高可靠、易扩展、易运维应用
寻找翻译本书后续章节合作者 微信:18600166191 ---------------------------------- PART I Foundations of Data Systems ...
- 普元应用服务器高可靠方案
转载本文请注明出处:微信公众号EAWorld 前言: 伴随着网络带宽的提升和移动终端的普及,现代的web应用平台几乎时时刻刻都在处理着来自用户成千上万的访问请求.在某些特定的场景下(如电商抢购.春运抢 ...
- 基于Flink的高可靠实时ETL系统
GIAC(GLOBAL INTERNET ARCHITECTURE CONFERENCE)是长期关注互联网技术与架构的高可用架构技术社区和msup推出的,面向架构师.技术负责人及高端技术从业人员的年度 ...
最新文章
- AI总监王长虎被曝离职,字节跳动AI Lab 再失一将!
- python函数式编程模式_函数式编程指引
- Local Response Normalization作用——对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力...
- 橙白oj18训练作业2-题解、代码
- 可以在中断服务程序执行malloc吗?
- Java编程中“为了性能”尽量要做到的一些地方 [转]
- 周鸿祎:希望将互联网基因与汽车制造企业基因进行重组
- 拼多多首届“非遗购物节”开幕 十一省市“非遗馆”入驻
- ios13.4.1续航怎么样?
- ecshop 支持 php,ecshop支持PHP7的修改方法
- ubuntu 的使用
- Altium Designer(三):基础
- 关于git的cherry-pick命令
- 计算机网络复习-互联网概述
- @Transactional什么情况才生效
- 钢琴乐谱怎么看?学习五线谱及其口诀
- PCB绘制成长日记1
- Unity烘焙时UV Overlap的解决办法
- Win10 修复引导
- 折纸珠峰c语言程序,c语言折纸超过珠穆拉玛峰
热门文章
- 计算机网络实验(思科模拟器Cisco Packet Tracer)——交换机配置以及虚拟局域网VLAN
- 虚拟Web主机(基于域名配置,基于ip地址,基于端口)
- matlab如何使音频文件声音变大_如何制作视频课程
- copyonwritearraylist原理_Java集合干货——CopyOnWriteArrayList源码分析
- 自检代码中trustmanager漏洞_2020-11微软漏洞通告
- 高校计算机基础能力测试文字处理,高校计算机基础论文3篇(共8238字).doc
- abaqus的python安装文件在哪_在abaqus2016中安装xlwt和xlrd库教程
- opencv轻松入门面向python下载_OpenCV轻松入门:面向Python
- docker hub 代理_MAC版 的最新Docker 2.2版本配置国内代理的解决办法
- python实验报告代写价格_代写OS python程序作业、代写代写OS作业、代写OS实验报告...