【应用案例】SequoiaDB+Spark搭建医院临床知识库系统
1.背景介绍
从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩。不但有数字化医院管理信息系统(HIS)、影像存档和通信系统(PACS)、电子病历系统(EMR)和区域医疗卫生服务(GMIS)等成功实施与普及推广,而且随着日新月异的计算机技术和网络技术的革新,进一步为数字化医院带来新的交互渠道譬如:远程医疗服务,网上挂号预约。
随着IT技术的飞速发展,80%以上的三级医院都相继建立了自己的医院信息系统(HIS)、电子病历系统(EMR)、合理用药系统(PASS)、检验管理系统(LIS)、医学影像存储与共享系统(PACS)以及移动查房、移动护理系统以及与大量的第三方接口整合应用,IT在医疗领域已经进入了一个大数据时代,随着HIS的广泛应用及其功能的不断完善,HIS收集了大量的医疗数据。
进入2012年,大数据及相关的大数据处理技术越来越多地被国人提及,人们也普遍的接受大数据的概念,大数据技术也影响着我们的日常生活,互联网行业已经得到广泛应用,电信、银行等行业也已经在广泛尝试使用大数据技术提供更稳健和优质的服务。
在目前情况下,医疗IT系统收集了这些集其有价值的数据,但是这些大量的有价值的历史医疗数据并没有发挥出其应有的价值,不能为一线临床医生提供医疗诊断辅助,也不能为医院管理和经营决策提供必须的支持。
针对以上现状,思考拟利用医院现有的历史就诊记录、处方、诊断、病历数据,挖掘出有价值的基于统计学的医学规则、知识,并基于这些规则、知识信息构建专业的临床知识库,为一线医务人员提供专业的诊断、处方、用药推荐功能,基于强大的关联推荐能力,极大的提高医疗服务质量,减轻一线医疗人员的工作强度。
2.主要技术架构介绍
2.1 SequoiaDB
SequoiaDB巨杉数据库,是一款企业级分布式NewSQL数据库,自主研发并拥有完全自主知识产权,没有基于任何其他外部的开源数据库源代码。SequoiaDB支持标准SQL、事务操作、高并发、分布式、可扩展、与双引擎存储等特性,并已经作为商业化的数据库产品开源。
除了JSON存储引擎以外,为了提高非结构化文件的读写性能,SequoiaDB核心引擎提供了分布式块存储模式,可以将非结构化大文件按照固定大小的数据块进行切分并存放于不同分区。这一功能可以实现海量非结构化文件的存储,可以引用于如影像存储等场景。
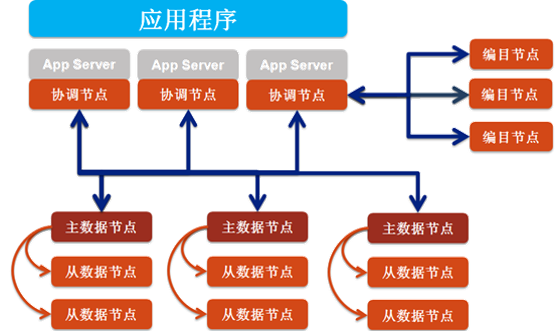
2.2 Spark
Spark是UC Berkeley大学AMP实验室开源的类似MapReduce的计算框架,它是一个基于内存的集群计算系统,最初的目标是解决MapReduce磁盘读写的开销问题,当前最新的版本是1.5.0。Spark—经推出,就以它的高性能和易用性吸引着很多大数据研究人员,在众多爱好者的努力下,Spark逐渐形成了自己的生态系统( Spark为基础,上层包括Spark SQL,MLib,Spark Streaming和GraphX),并成为Apache的顶级项目。
Spark的核心概念是弹性分布式存储(Resilient Distributed Datasets, RDD)间,它是Spark对分布式内存进行的抽象,使用者可以像操作本地数据集一样操作RDD,从而可以将精力集中于业务处理。在Spark程序中,数据的操作都是基于RDD的,例如经典的WordCount程序,其在Spark编程模型下的操作方式如下图所示:
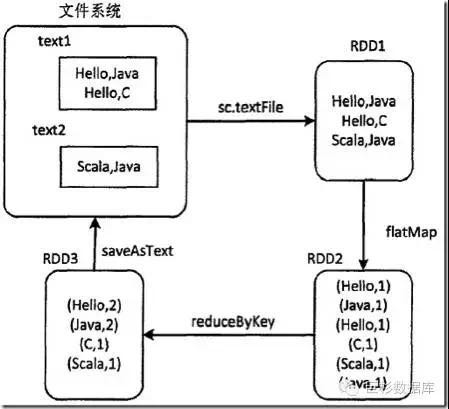
可以看到Spark先从文件系统抽象出RDD1,然后由RDD1经过flatMap算子转换得到RDD2,RDD2再经过reduceByKey算子得到RDD3,最后RDD3中的数据重新写回文件系统,一切操作都是基于RDD的。
3.思路与架构
经过多方面的思考,最终决定基于Spark技术进行构建和实现医院临床知识库系统,采用SequoiaDB构建底层数据存储平台,做为大数据的存储中心,采用Spark构建大数据分析平台,基于AgileEAS.NET SOA中间件构建ETL数据抽取转换工具(后期部分换用了Pentaho Kettle),基于AgileEAS.NET SOA中间件构建知识库的服务门户,通过WCF/WebService与HIS系统进行业务整合集成,使用AgileEAS.NET SOA+FineUI构建基础字典管理以后分析结构的图像化展示功能。
我们选择了SequoiaDB做为大数据存储中心,为此我还特意的为SequoiaDB完成了C#驱动,最初我们选择了Spark1.3.1版本之上使用scala2.10开发完成了医院临床知识库系统,项目后期我们把计算框架也由Spark1.3.1升级到了Spark1.6.2(Spark已经于近期发布了2.0版本,各种性能稳定性大幅提升)。
考虑到Spark都部署在Linux的情况,对于Spark分析的结果输出存储在也存储在SequoiaDB巨杉数据库之中。Spark数据分析部分的代码使用IntelliJ IDEA 14.1.4工具进行编写,其他部分的代码使用VS2010进行编写。
3.1 总体架构
整个系统由数据采集层、存储分析层和应用逻辑层三大部分以及本系统所选所以来的外部数据源。本系统的外部数据源目前主要是医院信息系统所产生的临床数据,目前主要集中在HIS系统之中,后期将采依赖于EMR、LIS、PACS系统。
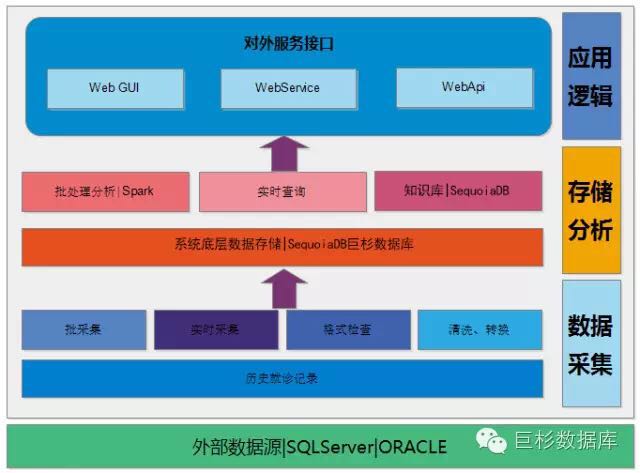
数据采集层:主要负责从临床业务系统采集海量历史临床数据同,历史记录采集方式分为批采集和实时采集,在数据采集过程之中对原始数据进行格工检查,并对原始数据进行清洗和转换,并将处理后的数据存储在大数据仓库之中。
存储分析层:主要负责数据存储以及数据分析两大部分业务,经过清洗转换的合理有效数据被存储在大数据集群之中,使用JSON格式,大数据存储引用使用SequoiaDB数据库,数据分析部分由Spark集群来完成,大数据存储经由Spark导入并进行分析,分析结果写入临床知识数据库,临床知识数据库也使用SequoiaDB巨杉数据库进行存储。
应用逻辑层:主要负责人机交互以及分析结构回馈临床系统的渠道,通过WebUI的方式向临床医生、业务管理人员提供列表式、图像化的知识展示,也为临床系统的业务辅助、推荐功能提供调用的集成API,目前API主要通过WebService、WebAPI两种方式提供。
3.2 系统数据流程
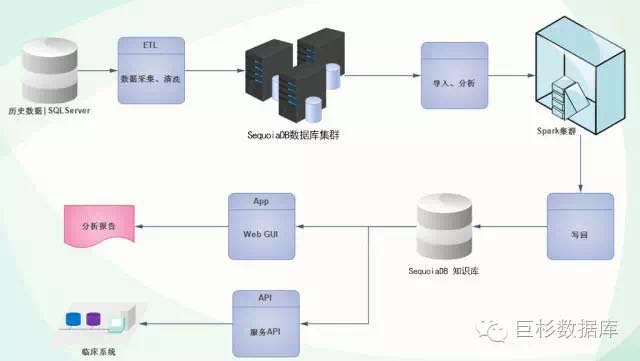
整个系统经由数据源数据采集,写入大数据存储SequoiaDB集群,然后由Spark进行分析计算,分析生成的临床知识再写入SequoiaDB知识库,经由WebUI以及标准的API交由临床使用。
3.3 数据导入流程
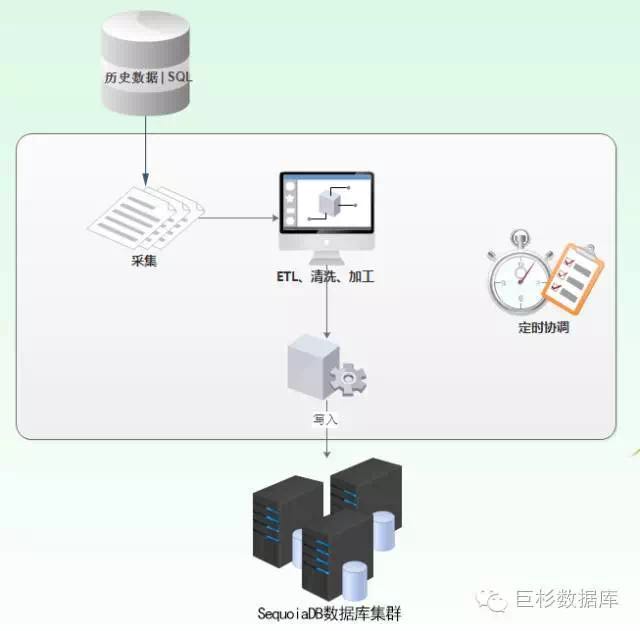
历史数据的采集导入使用初期使用http://AgileEAS.NET SOA 的计划任务配何C#脚本进行实现,由计划任务进行协调定时执行,具体的数据导入代码根据不同的临床业务系统不同进行脚本代码的调整,也可以使用Pentaho Kettle进行实现,通过Pentaho Kettle可配置的实现数据的导入。
3.4 系统物理架构
临床数据源为本系统进行分析的数据来源,源自于临床HIS、EMR,目前医院的HIS使用SQL Server 2008 R2数据库,EMR使用ORACLE 11G数据库,运行于Windows2008操作系统之上。
SequoiaDB集群为大数据存储数制库集群,目前使用SequoiaDB v2.0,运行于Centos6.5操作系统之上,根据业务来规模使用2-16节点集群,其用于存储经过清洗转换处理的海量历史临床数据,供Spark集群进行分析,以及供应SOA服务器进行历史数据查询和历史相关推荐使用。
Spark集群为本系统的分析计算核心节点,用于对SequoiaDB集群之中的历史数据进行分析,生成辅助临床医生使用的医学知识,本集群根据业务来规模使用2-16节点集群,使用Centos6.5操作系统,安装JAVA1.7.79运行环境、scala2.11.4语言,使用Spark1.3.1分析框架。
同时,SequoiaDB作为作为本系统的知识库存储数据库时。Spark集群所生产的分析结构写入本数据库,经由SOA服务器和Web服务处理供临床系统集成使用和WebGUI展现。
SOA Server为本系统的对外接口应用服务器,向临床业务系统和Web Server提供业务运算逻辑,以及向临床业务系统提供服务API,目前运行于Windows2008操作系统,部署有.NET Framework 4.0环境,运行http://AgileEAS.NET SOA 中间件的SOA服务,由http://AgileEAS.NET SOA 中间件SOA服务向外部系统提供标准的WebService以及WebAPI。
Web Server为系统提供基于标准的B/S浏览器用户接口,供业务人员通过B/S网页对系统进行管理,查询使用知识库之中的医学知识,目前运行于Windows2008操作系统,部署有.NET Framework 4.0环境,运行于IIS7.0之中。
临床工作站系统运行HIS、EMR系统,两系统均使用C#语言SOA架构思路进行开发,与本系统集成改造后,使用标准WebService接口本系统,使用本系统所提供的API为临床提供诊疗辅助。
4.结语
不论是NoSQL技术还是Spark技术,作为当前大数据新兴的技术架构,都将是大数据应用的核心基础。SequoiaDB的分布式架构支持了海量的数据的村存储,同时其JSON/LOB的架构又可以满足非结构化数据的存储。这两个特性可以说是医疗行业对于数据的核心需求。同时SequoiaDB作为数据源又能很好的对接Spark架构(SequoiaDB是Spark官方的全球10多家认证发行商之一),选择SequoiaDB可以说也是大大提升了整个数据系统的性能和稳定性。
本文源自巨杉数据库社区用户实际应用案例
SequoiaDB巨杉数据库2.6最新版下载
SequoiaDB巨杉数据库技术博客
SequoiaDB巨杉数据库社区
转载于:https://my.oschina.net/u/2444165/blog/798846
【应用案例】SequoiaDB+Spark搭建医院临床知识库系统相关推荐
- 应用案例:SequoiaDB+Spark搭建医院临床知识库系统
1.背景介绍 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(H ...
- 【巨杉案例】SequoiaDB+Spark搭建医院临床知识库系统
1.背景介绍 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(H ...
- SequoiaDB+Spark搭建医院临床知识库系统
1.背景介绍 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(H ...
- 大数据项目实践:基于hadoop+spark+mongodb+mysql开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS).影像存 ...
- 行业大数据 -- 基于hadoop+spark+mongodb+mysql开发医院临床知识库系统(建议收藏)
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- SequoiaDB数据库搭建Spark
先介绍我的Sequoiadb集群环境: 192.168.31.16 192.168.31.17192.168.31.18 这三台机器搭建的集群,准备将192.168.31.16 这台机器作为我的sp ...
- 视频教程-大数据电视收视率实战项目教程(企业级案例)-Spark
大数据电视收视率实战项目教程(企业级案例) 张长志技术全才.擅长领域:区块链.大数据.Java等.10余年软件研发及企业培训经验,曾为多家大型企业提供企业内训如中石化,中国联通,中国移动等知名企业.拥 ...
- spring原理案例-基本项目搭建 01 spring framework 下载 官网下载spring jar包
下载spring http://spring.io/ 最重要是在特征下面的这段话,需要注意: All avaible features and modules are described in the ...
最新文章
- 大数据人力资源服务平台正式上线
- html 字符串最后加空格,js给字符串每个字符中间加空格
- CSS Grid布局(2)
- 【译】Immutable.js : 操作 Set -8
- android 系统 ---(1) 框架的代码组织介绍
- [设计模式-结构型]装饰模式(Decorator)
- Pandas入门教程(二)
- smarty中的几个常用函数 templateExists() fetch() include
- C语言课程设计——工资管理系统
- koreader下载_kindle koreader
- Dell Inspiron 14 3437装win7系统没有网卡驱动解决办法
- 如何搜索自己博客内的文章
- 米4android6.0 root,小米4怎么root权限获取?miui6获取root权限方法
- 计算机考研408哪个视频好,计算机408考研视频哪个好
- Google AppOps
- 灵魂书籍 | 《记忆力心理学 | 赫尔曼·艾宾浩斯》
- 分布式监控apm_Datadog:APM和分布式跟踪的新Java支持
- unity打包报错,又是血压升高的一天
- TO_DATE使用詳解
- ESP8266 MP3制作——关于SelectionList从源码中改代码的一次经历