菜鸟学概率统计——最大后验概率(MAP)
最大似然估计:把待估计的参数看作是确定性的量(只是其取值未知),其最佳估计就是使得产生已观察到的样本(即训练样本)的概率为最大的那个值。(即求条件概率密度p(D|$)为最大时的$,其中D为样本集,$为条件概率密度分布的参数)。特点:简单适用;在训练样本增多时通常收敛得很好。只考虑某个模型能产生某个给定观察序列的概率,而未考虑该模型本身的概率,这点与贝叶斯估计区别。
目标是寻求能最大化likehood:的值。可以写出目标函数:
一般使用对数来进行简化处理:
要最大化L,对L求导数并令导数为0即可求解。
最大后验估计(MAP-Maxaposterior):求p(D|$)*p($)取最大值的那个参数向量$,最大似然估计可以理解为当先验概率p($)为均匀分布时的MAP估计器。(MAP缺点:如果对参数空间进行某些任意非线性变换,如旋转变换,那么概率密度p($)就会发生变化,其估计结果就不再有效了。)根据经验数据获得对难以观察的量的点估计。与最大似然估计类似,但是最大的不同时,最大后验估计的融入了要估计量的先验分布在其中,可看做是规则化的最大似然估计。
和极大似然估计不同的是,MAP寻求的是能使后验概率最大的
值。
之所以可以省略分母p(X),是因为p(X)和没有关系。注意当前验 p 是 uniform(也就是常函数)时最大后验估计与最大似然估计重和。
加上对数处理后,上面公式可以表达为:
的先验分布
,在实际应用中,这个先验可以用来描述人们已经知道或者接受的普遍规律。例如在扔硬币的试验中,每次抛出正面发生的概率应该服从一个概率分布,这个概率在0.5处取得最大值,这个分布就是先验分布。先验分布的参数我们称为超参数(hyperparameter)即
至于上面目标函数的求解,也和极大似然估计是一样的,对目标函数求导并令导数为0来求解。
以扔硬币的伯努利实验为例子,N次实验的结果服从二项分布,参数为P,即每次实验事件发生的概率,不妨设为是得到正面的概率。为了估计P,采用最大似然估计,似然函数可以写作
其中表示实验结果为i的次数。下面求似然函数的极值点,有
得到参数p的最大似然估计值为
可以看出二项分布中每次事件发的概率p就等于做N次独立重复随机试验中事件发生的概率。
如果我们做20次实验,出现正面12次,反面8次
那么根据最大似然估计得到参数值p为12/20 = 0.6。
下面我们仍然以扔硬币的例子来说明,我们期望先验概率分布在0.5处取得最大值,我们可以选用Beta分布即
其中Beta函数展开是
当x为正整数时
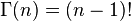
Beta分布的随机变量范围是[0,1],所以可以生成normalised probability values。
我们取,这样先验分布在0.5处取得最大值,现在我们来求解MAP估计函数的极值点,同样对p求导数我们有
得到参数p的的最大后验估计值为
和最大似然估计的结果对比可以发现结果中多了这样的pseudo-counts,这就是先验在起作用。并且超参数越大,为了改变先验分布传递的belief所需要的观察值就越多,此时对应的Beta函数越聚集,紧缩在其最大值两侧。
如果我们做20次实验,出现正面12次,反面8次,那么
那么根据MAP估计出来的参数p为16/28 = 0.571,小于最大似然估计得到的值0.6,这也显示了“硬币一般是两面均匀的”这一先验对参数估计的影响。
假设![]() 为独立同分布的
为独立同分布的![]() ,μ有一个先验的概率分布为
,μ有一个先验的概率分布为![]() 。那么我们想根据
。那么我们想根据![]() 来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:
来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:
![]()
此时我们在两边取对数可知。所求上式的最大值可以等同于求
![]()
的最小值。求导可得所求的μ为
![]()
以上便是对于连续变量的MAP求解的过程。
MAP与MLE最大区别是MAP中加入了模型参数本身的概率分布,或者说,MLE中认为模型参数本身的概率的是均匀的,即该概率为一个固定值。MAP允许我们把先验知识加入到估计模型中,这在样本很少的时候是很有用的,因为样本很少的时候我们的观测结果很可能出现偏差,此时先验知识会把估计的结果“拉”向先验,实际的预估结果将会在先验结果的两侧形成一个顶峰。通过调节先验分布的参数,比如beta分布的,我们还可以调节把估计的结果“拉”向先验的幅度,
越大,这个顶峰越尖锐。这样的参数,我们叫做预估模型的“超参数”。
MAP与Bayesian区别:尽管最大后验估计与 Bayesian 统计共享前验分布的使用,通常并不认为它是一种 Bayesian 方法
举例:
1.考虑一个医疗诊断问题,有两种可能的假设:(1)病人有癌症。(2)病人无癌症。样本数据来自某化验测试,它也有两种可能的结果:阳性和阴性。假设我们已经有先验知识:在所有人口中只有0.008的人患病。此外,化验测试对有病的患者有98%的可能返回阳性结果,对无病患者有97%的可能返回阴性结果。假设现在有一个新病人,化验测试返回阳性,是否将病人断定为有癌症呢?
上面的数据可以用以下概率式子表示:
我们可以来计算极大后验假设:
因此,应该判断为无癌症。
确切的后验概率可将上面的结果归一化以使它们的和为1:
2.假设有五个袋子,各袋中都有无限量的饼干(樱桃口味或柠檬口味),已知五个袋子中两种口味的比例分别是
樱桃 100%
樱桃 75% + 柠檬 25%
樱桃 50% + 柠檬 50%
樱桃 25% + 柠檬 75%
柠檬 100%
如果只有如上所述条件,那问从同一个袋子中连续拿到2个柠檬饼干,那么这个袋子最有可能是上述五个的哪一个?
我们首先采用最大似然估计来解这个问题,写出似然函数。假设从袋子中能拿出柠檬饼干的概率为p(我们通过这个概率p来确定是从哪个袋子中拿出来的),则似然函数可以写作
![]()
由于p的取值是一个离散值,即上面描述中的0,25%,50%,75%,1。我们只需要评估一下这五个值哪个值使得似然函数最大即可,得到为袋子5。这里便是最大似然估计的结果。
上述最大似然估计有一个问题,就是没有考虑到模型本身的概率分布,下面我们扩展这个饼干的问题。
假设拿到袋子1或5的机率都是0.1,拿到2或4的机率都是0.2,拿到3的机率是0.4,那同样上述问题的答案呢?这个时候就变MAP了。我们根据公式
![]()
写出我们的MAP函数。
![]()
根据题意的描述可知,p的取值分别为0,25%,50%,75%,1,g的取值分别为0.1,0.2,0.4,0.2,0.1.分别计算出MAP函数的结果为:0,0.0125,0.125,0.28125,0.1.由上可知,通过MAP估计可得结果是从第四个袋子中取得的最高。
菜鸟学概率统计——最大后验概率(MAP)相关推荐
- 为什么计算机专业要学概率统计,计算机类专业概率统计的教学
计算机类专业概率统计的教学 来源:职称阁时间:2018-12-04 11:09热度: 这篇论文主要介绍的是计算机类专业概率统计的教学的相关内容,本文作者就是通过对计算机专业的统计学内容做出详细的阐述与 ...
- 为什么计算机专业要学概率统计,计算机类专业概率统计教学探讨与尝试
第 32卷第 1期 VoL32 No.1 长春师范学院学报(自然科学版) Journal of Changchun Normal University(Natural Science) 2013年 2 ...
- 概率统计极简入门:通俗理解微积分/期望方差/正态分布前世今生(23修订版)
原标题:数据挖掘中所需的概率论与数理统计知识(12年首次发布,23年重编公式且反复改进) 修订背景 本文初稿发布于12年年底,十年后的22年底/23年初ChatGPT大火,在写ChatGPT通俗笔记的 ...
- 深度学习中需要掌握的数学1之概率统计
深度学习中需要掌握的概率统计 1.常见的概率分布 1.1伯努利分布(二值分布,0-1分布) 1.2二项分布(离散的) 1.3均匀分布 1.4`高斯分布`(连续) 2.独立事件的解释 3.多变量概率分布 ...
- 机器学习中的数学:概率统计
内容亮点 详解 6 大核心板块:概率思想.随机变量.统计推断.随机过程.采样理论.概率模型,筑牢机器学习核心基础. 教你熟练使用 Python 工具库:依托 NumPy.SciPy.Matplotli ...
- 菜鸟学Linux 第034篇笔记 vmlinuz, initrd, modules, script
菜鸟学Linux 第034篇笔记 vmlinuz, initrd, modules, script 内核两部分 核心 /boot/vmlinuz-version 内核模块 /lib/modules/ ...
- 概率与计算机论文,数学概率统计论文范文
一.引言 如本校数学与应用数学专业和信息与计算科学专业,该课程实践教学主要是利用计算机对理论知识的模拟和实证.这样的实践教学对理论知识的理解有一定的帮助,但对于实际的运用却缺少训练.基于此,在实践教. ...
- 概率分布分位点_概率统计计量经济学_假设检验中的重要概念_分位点/p值
在学完了几个重要分布之后,紧接着的内容就是这几个分布的使用,实际上这就是假设检验的过程 其中有一些概念: 分位点和分位数,p值,分布表,置信区间 因为是新概念, 我这种蒻蒻就是看得很不清楚,理解起来总 ...
- 概率统计16——均匀分布、先验与后验
相关阅读: 最大似然估计(概率10) 重要公式(概率4) 概率统计13--二项分布与多项分布 贝叶斯决策理论(1)基础知识 | 数据来自于一个不完全清楚的过程-- 均匀分布 简单来说,均匀分布是指事件 ...
最新文章
- ECMAScript 引用类型
- python怎么导入视频-Python读取视频的两种方法(imageio和cv2)
- python Logging日志记录模块详解
- sklearn机器学习常用数据处理总结
- 机器视觉支架制作(带效果测试)
- 人脸识别的前世今生:从人工特征的百花齐放到深度学习的一统江湖
- 透析 | 卷积神经网络CNN究竟是怎样一步一步工作的?
- 推翻相对论的专家,就差安排明天几点日出了
- 剑指Offer之复杂链表的复制
- PHP设计模式之----观察者模式
- 优雅的使用Python之软件管理
- 捕捞季节 通达信副图指标公式 源码
- 英国云主机节点是欧美五大节点之一
- 百度文库文章提取器(下)
- Markdown转pdf分页
- 手机网络延迟测试软件,手机网速延迟测试在线(手机网络延迟测试工具)
- 量化中获取A股交易日信息
- Android 手机上利用adb shell模拟手机相关操作
- Go XP开发,以GoLand为例
- python在一个函数中调用另一函数中的变量