DNA核苷酸含量计算
分子生物学简介
构成所有生物原料的细胞被认为是生命的基石。细胞核是大多数真核细胞的组成部分,150年前被确定为细胞活动的中心。
在光学显微镜下观察,细胞核仅作为细胞的较暗区域出现,但随着我们增加放大倍数,我们发现细胞核密集地充满了称为染色质的大分子物质。在有丝分裂期间(真核细胞分裂),大多数染色质浓缩成长而细的细胞串,称为染色体。有关有丝分裂不同阶段的细胞图见下图。

图1. 在1900年Emmund Wilson在有丝分裂不同阶段绘制的洋葱细胞图。由于样品已被染色,导致细胞中的染色质(吸收染料)与细胞的其他部分形成鲜明对比。
染色质中含有的一类大分子称为核酸。20世纪早期对核酸化学特性的研究最终得出结论:核酸是聚合物,或者将这种重复结构的称为单体。由于它们细而长,核酸聚合物通常被称为链。
核酸单体称为核苷酸,并作为链长度的单位(缩写为nt)。每个核苷酸由三部分组成:糖分子,带有负离子的磷酸盐,和核碱基化合物(简称“碱基”)。当一个核苷酸的糖与链中下一个核苷酸的磷酸键合时开始聚合,其形成核酸链的糖-磷酸骨架。关键点在于特定类型核酸的核苷酸总是含有相同的糖和磷酸盐分子,它们的区别仅在于它们对碱基的选择。因此,核酸的一条链可以仅基于其碱基的顺序与另一条链区分开;碱基的这种排序定义了核酸的一级结构。
例如,图2显示了脱氧核糖核酸(DNA)链,其中糖被称为脱氧核糖,分别有四种碱基:腺嘌呤(A),胞嘧啶(C),鸟嘌呤(G)和胸腺嘧啶(T)。
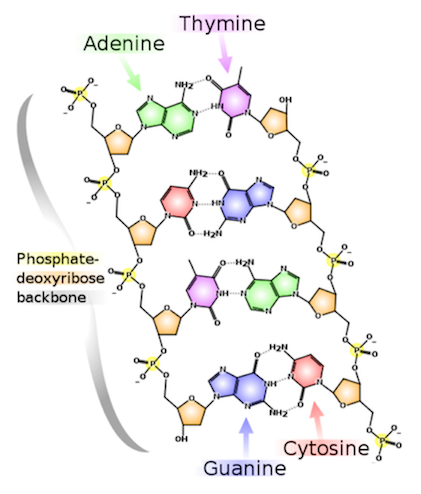
图2. DNA的一级结构示意图。
DNA存在于地球上的所有生物体中,包括细菌;它甚至存在于许多通常被认为是非生命的病毒中。由于其重要性,我们使用“基因组”来指代生物体染色体中包含的DNA的总和。
问题
在探索分子生物学的道路上,DNA中所蕴含的信息是至关重要的,由前文我们可以知道一条DNA链仅有A,T,C,G四种碱基决定的核苷酸序列构成,因此了解一条DNA链中四种核苷酸的含量是非常关键的一步!
Given: A DNA string s of length at most 1000 nt.
Return: Four integers (separated by spaces) counting the respective number of times that the symbols 'A', 'C', 'G', and 'T' occur in s.
样本数据集
AGCTTTTCATTCTGACTGCAACGGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTGTCTGATAGCAGC
样本输出
20 12 17 21
![]()
## 加载样本数据
with open("F:\Python\dna.txt", "r") as r_dna:r_dna = r_dna.read()## 在这里我们可以使用python的字符串自带的一个属性(.count())来实现此算法
print(r_dna.count("A"))def count_DNA(string):return string.count("A"), string.count("C"), string.count("G"), string.count("T")
print(count_DNA(r_dna))In [1]:
## 加载样本数据
with open("Bioinformatics_Stronghold/data/rosalind_dna.txt", "r") as r_dna:r_dna = r_dna.read()
In [2]:
## 在这里我们可以使用python的字符串自带的一个属性(.count())来实现此算法
print(r_dna.count("A"))
Out[2]:
243
In [3]:
def count_DNA(string):return string.count("A"), string.count("C"), string.count("G"), string.count("T")
In [4]:
print(count_DNA(r_dna))
Out[4]:
(243, 228, 221, 231)
最后如果对生物信息学算法感兴趣的小伙伴可以关注我在github上的项目Bioinfo:
https://github.com/zomath/python/tree/master/BioinfoDNA核苷酸含量计算相关推荐
- 生物信息学算法之Python实现|Rosalind刷题笔记:010 DNA一致性序列计算
经常碰到需要计算一组 DNA 序列的一致性序列,比如去除测序数据中的 PCR 错误,最简单的方法就是通过计算它们之间的一致性序列. 图源:rosalind.info 计算一致性序列,通常借助一个中间矩 ...
- dna计算机量子计算,量子算法、DNA计算与后经典计算时代
原标题:量子算法.DNA计算与后经典计算时代 资本实验室·今日创新观察 聚焦前沿科技创新与传统产业升级 二进制与伟大的计算机相结合,推动人类进入了信息化时代.在这个基于物质世界的,由0和1构成的新世界 ...
- 计算碱基出现次数DNA
计算碱基出现次数 编写一个程序,从文本文件gene.dat中读取DNA序列,计算碱基出现频率 哈哈第一次编文案 这思路很简单:就是比较字母是否相等 import os # 读取及打开文件 f=open ...
- 论文解读:基于共享混合深度学习架构的DNA形状特征预测转录因子结合位点
Predicting transcription factor binding sites using DNA shape features based on shared hybrid deep l ...
- 易基因:植物DNA甲基化专题 |玉米:从群体水平揭示DNA甲基化变异对表型的贡献
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因. 植物DNA甲基化研究: NAR: 拟南芥AtHDA6与着丝粒周围DNA甲基化关系研究 nature:油棕Karma转座子表观遗传重要发现 ...
- 计算机与生物技术的论文,DNA计算机生物技术论文
<DNA计算机生物技术论文.doc>由会员分享,可免费在线阅读全文,更多与<DNA计算机生物技术论文>相关文档资源请在帮帮文库(www.woc88.com)数亿文档库存里搜索. ...
- 密码学------DNA密码学发展概述
密码学是研究编译和破译密码的一门科学,作为保证所有信息安全传递的基础,其涉及到数学.计算机等众多领域.随着互联网的发展,重要数据通过互联网传递往往会受到一些安全攻击,如IP地址欺骗.中间人攻击以及拒绝 ...
- Genome Biology:人体各部位微生物组时间序列分析Moving Pictures
人体各部位微生物组初探 Moving pictures of the human microbiome Genome Biology, [14.028] 2011-05-30 Articles DO ...
- Genome Biology:人体各部位微生物组时间序列分析
文章目录 人体各部位微生物组初探 摘要 背景 结果 结论 点评 主要结果 图1. 基于无权重UniFrac距离的PCoA 图2. 时间上的核心微生物组 图3. 群落中的成员关联 猜你喜欢 写在后面 人 ...
最新文章
- linux命令之date
- WebService站点服务的地址
- 验证用户输入的是不是中文名字 淘宝精品案例 元素样式设置的方式 链式编程
- 阿里安全图灵实验室再次刷新世界顶级算法比赛成绩
- 织梦dede 5.7系统基本参数无法修改保存,提示Token mismatch!
- C语言: GDB调试技术(一)
- tornado学习笔记day02-进阶与提升
- mysql排序行号_mysql 取得行号后再排序
- 社会计算:服务群体社会的大数据科学
- 震惊 | 某公司实习生跑路,竟为了学习偷盗面试题
- [译] 用 Redis 和 Python 构建一个共享单车的 app
- 3.深入了解listen函数
- 2021年注册土木工程师岩土基础考试历年真题
- 熵权法、极差法标准化简介与实战
- 龙芯 python_html页面转PDF、图片操作记录,Vue项目入门实例
- Perl CGI重构原则
- WebStorm英文版汉化
- 发送邮件错误常见错误码
- 重塑汽车的最新5G标准
- 论坛软文撰写技巧之做一个合格的标题党