NLP︱词向量经验总结(功能作用、高维可视化、R语言实现、大规模语料、延伸拓展)
R语言由于效率问题,实现自然语言处理的分析会受到一定的影响,如何提高效率以及提升词向量的精度是在当前软件环境下,比较需要解决的问题。
笔者认为还存在的问题有:
1、如何在R语言环境下,大规模语料提高运行效率?
2、如何提高词向量的精度,或者说如何衡量词向量优劣程度?
3、词向量的功能性作用还有哪些值得开发?
4、关于语义中的歧义问题如何消除?
5、词向量从”词“往”短语“的跨越?
转载请注明出处以及作者(Matt),欢迎喜欢自然语言处理一起讨论~
————————————————————————————————————————————————
一、大规模语料提高运行效率
从训练参数、优化训练速度入手。
1、训练参数
训练参数的选择是提高效率的关键之处,一些经验参数训练的经验(一部分来源小桥流水博客):
- window在5~8,我用的8,感觉还不错,CBOW一般在5,SKIP在10左右比较适合;
- 其他的可以参考:
· 架构:skip-gram(慢、对罕见字有利)vs CBOW(快)
· 训练算法:分层softmax(对罕见字有利)vs 负采样(对常见词和低纬向量有利)
· 欠采样频繁词:可以提高结果的准确性和速度(适用范围1e-3到1e-5)
· 文本(window)大小:skip-gram通常在10附近,CBOW通常在5附近
词嵌入的质量也非常依赖于上下文窗口大小的选择。通常大的上下文窗口学到的词嵌入更反映主题信息,而小的上下文窗口学到的词嵌入更反映词的功能和上下文语义信息。
1、维数,一般来说,维数越多越好(300维比较优秀),当然也有例外;
2、训练数据集大小与质量。训练数据集越大越好,覆盖面广,质量也要尽量好。
3、参数设置,一般如windows,iter、架构选择比较相关。
2、优化训练速度
(一部分来源小桥流水博客)
选择cbow模型,根据经验cbow模型比skip-gram模型快很多,并且效果并不比skip-gram差,感觉还好一点;
线程数设置成跟cpu核的个数一致;
迭代次数5次差不多就已经可以了;
3、使用Glove训练词向量(text2vec包)
参考博客:text2vec(参考博客:重磅︱R+NLP:text2vec包——New 文本分析生态系统 No.1(一,简介))
————————————————————————————————————————————————
二、词向量表示精度
不同的词向量表达方式也有着不同的优劣势,
1、NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
2、NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
3、NLP︱高级词向量表达(三)——WordRank(简述)
现在比较多见的词向量表示方式:GloVe、fasttext、wordRank、tfidf-BOW、word2vec
根据Ranking算法得到的wordRank,与 word2vec、fastText三者对比
![]()
相似词的寻找方面极佳,词类比方面不同数据集有不同精度。
![]()
不过,上述都是实验数据,从实际效果来看,TFIDF-BOW的效果,在很多情况下比这些高阶词向量表示的方式还要好,而且操作简单,值得推广!
——————————————————————————————————————————————————————
三、词向量的功能、作用
1、词向量的可加性
词向量有一个潜力非常大的性质,就是向量之间的可加性,比如两个案例:
Vector(巴黎)-Vector(法国)+Vector(意大利)≈Vector(罗马)
Vector(king)-Vector(man)+Vector(woman)≈Vector(queen)
大致的流程就是king的woman约等于queen,当然为什么要减去man,这里man会干扰king词,所以减去。
差即是投影,就是一个单词在不同上下文中的相对出现。平均两个向量更好,而不是取其总和。
2、消除歧义
上面king-man就是消除歧义的一种方式,这里要用到线性代数的方式,king-man之后就把man这层意思消除掉了。
不过,得先大规模识别歧义词,有待后续研究。
也许你寄希望于一个词向量能捕获所有的语义信息(例如run即是动车也是名词),但是什么样的词向量都不能很好地进行凸显。
这篇论文有一些利用词向量的办法:Improving Word Representations Via Global Context And Multiple Word Prototypes(Huang et al. 2012)
解决思路:对词窗口进行聚类,并对每个单词词保留聚类标签,例如bank1, bank2等
来源博客:NLP︱Glove词向量表达(理论、相关测评结果、R&python实现提及)
3、词聚类
通过聚类,可以去挖掘一些关于某词的派生词;或者寻找相同主题时,可以使用。
4、词向量的短语组合word2phrase
通过词向量构造一些短语组合,要分成两步来探索:
(1)词语如何链接起来?(参考论文)
(2)链接起来,用什么方法来记录组合短语?——平均数
比如”中国河“要变成一个专用短语,那么可以用”中国“+”河“向量的平均数来表示,然后以此词向量来找一些近邻词。
5、sense2vec
利用spacy把句子打散变成一些实体短语(名词短语提取),然后利用word2vec变成sense向量,这样的向量就可以用来求近似。譬如输入nlp,出现的是ml,cv。
![]()
关于spacy这个python模块的介绍,可以看自然语言处理工具包spaCy介绍
关于Sense2vec可以参考博客:https://explosion.ai/blog/sense2vec-with-spacy
sense2vec的demo网站
6、近义词属性
词向量通过求近似,可以获得很好的一个性质,除了可加性,就是近似性。可以将附近的近义词进行聚合,当然词向量的质量取决于训练语料的好坏。同时,近义词之中,反义词是否能够识别出来,也还是一个值得研究的话题。
7、词的类比和线性空间
如果我们想要进行单词比较(由a得到b,是因为由A得到B),可以认为对于每个词w,我们有条件概率比的等式
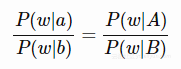
以下就是一个案例:
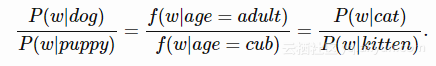
类比是可以找到单词之间对等关系。条件概率比的等式如何转换为单词向量?
我们可以使用类比来表示单词意思(如用向量改变性别),语法(如改变时态)或其他类比(如城市与其邮政编码)。似乎类比不仅是单方面的技巧-我们可能可以一直使用它们来考虑问题,详见:
George Lakoff, Mark Johnson,Metaphors We Live By(1980)
8、高维可视化
一些工具可以实现,譬如Embedding Projector
我们可以load自己的数据上去。官网在可视化高维数据的工具 - 谷歌研究博客
![]()
——————————————————————————————————————————————————————
R语言中Word2vec的包有哪些?
R语言中的词向量的包还是比较少的,而且大多数的应用都还不够完善,笔者之前发现有李舰老师写的tm.word2vec包
重磅︱文本挖掘深度学习之word2vec的R语言实现
tm.word2vec包里面的内容太少了,只有一个调用函数比较有效,于是李舰老师又在github上自己写了一个word2vec的函数,但是这个函数调用起来还不是特别方便。
于是国外有一神人,在李舰老师基础上,借鉴李舰老师word2vec函数,开发了自己的包,wordVectors包(1000W单词,4线程,20min左右),这个包相当优秀,不仅全部集成了李舰老师函数的优势(可以多线程操作、自定义维度、自定义模型),还解决了如何读取输出文件、消除歧义、词云图、词相似性等问题。
近日发现了其他两个:一个是text2vec,一个是rword2vec。其中text2vec是现在主要的研究方向:
重磅︱R+NLP:text2vec包简介(GloVe词向量、LDA主题模型、各类距离计算等)
——————————————————————————————————————————————————————
延伸一:大规模语料训练方式
在大量语料下,进行训练R语言效率超级低,而python相对较快。
一般来说用python的gensim和spark的mlib比较好。
但是笔者在使用过程中出现的情况是:
python的gensim好像只有cbow版本,
R语言,word2vec和glove好像都不能输出txt格式,只有bin文件。
同时大规模语料下,fasttext支持ngram向量化,用来搞文本分类还是很棒的。
——————————————————————————————————————————————————————
延伸二 : 论文经验解读《Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms》
文章来源:基线系统需要受到更多关注:基于词向量的简单模型 | ACL 2018论文解读
■ 论文 | Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms
■ 链接 | https://www.paperweekly.site/papers/1987
■ 源码 |https://github.com/dinghanshen/SWEM
简单的词向量模型(Simple word-embedding model,SWEM),作者提出了下面几种方法。
![]()
SWEM-aver:就是平均池化,对词向量的按元素求均值。这种方法相当于考虑了每个词的信息。
SWEM-max:最大池化,对词向量每一维取最大值。这种方法相当于考虑最显著特征信息,其他无关或者不重要的信息被忽略。
SWEM-concat:考虑到上面两种池化方法信息是互补的,这种变体是对上面两种池化方法得到的结果进行拼接。
SWEM-hier:上面的方法并没有考虑词序和空间信息,提出的层次池化先使用大小为 n 局部窗口进行平均池化,然后再使用全局最大池化。该方法其实类似我们常用的 n-grams 特征。
1 几款SWEM特点
SWEM-aver:综合信息
SWEM-max:互补的信息,比较稀疏,个别词语贡献大;虽然效果一般,但是解释力度很大,因为贡献最大的就是几个核心关键词。
SWEM-concat:aver + max,综合了前面两者的优势
SWEM-hier:N-grams的思想,在以上加入了一些词序信息
一般来说是:concat>aver>max
2 几大任务
文档分类:主题分类
主题分类主要在意的是词粒度,所以SWEM效果非常好(其中concat最好),CNN/LSTM
![]()
文档分类:情感分类
情感分类,词序信息比较重要,那么CNN/LSTM更能够捕捉。
其中SWEM-hier也有词序信息的考量,不过效果没有CNN/LSTM好。
文档分类:本体分类
词粒度的,SWEM-concat比较好
文本序列匹配(主要包括自然语言推理,问答中答案句选择和复述识别任务)
序列匹配对于关键词更加敏感,所以SWEM更好。
![]()
序列标注:命名实体识别等任务
考虑词序信息,CNN/LSTM更好。
3、其他一些情况
词向量维度
虽然维度越大,信息越大,效果越好,但是差异不明显。
![]()
数据集大小
小数据集对于词序的考量更好,关键词密度较低,所以CNN/LSTM更好。而SWEM模型,在长文本上效果更佳。
——————————————————————————————————————————————————————
延伸三:文本嵌入的经典模型与最新进展
强/快的基线模型:FastText,Bag-of-Words(词袋)
最先进的模型:ELMo,Skip-Thoughts,Quick-Thoughts,InferSent,MILA/ MSR 的通用句子表示和 Google 的通用句子编码器。
句向量的代表:
Google 的通用句子编码器(https://arxiv.org/abs/1803.11175),于2018年初发布,采用相同的方法。他们的编码器使用一个转换网络,该网络经过各种数据源和各种任务的训练,目的是动态地适应各种自然语言理解任务。他们也给 TensorFlow 提供了一个预训练的版本 https://www.tensorflow.org/hub/modules/google/universal-sentence-encoder/1。
NLP︱词向量经验总结(功能作用、高维可视化、R语言实现、大规模语料、延伸拓展)相关推荐
- NLP(词向量、word2vec和word embedding)
最近在做一些文本处理相关的任务,虽然对于相关知识有所了解,而且根据相关开源代码也可以完成相应任务:但是具有有些细节,尤其是细节之间的相互关系,感觉有些模糊而似懂非懂,所以找到相关知识整理介绍,分享如下 ...
- NLP词向量模型总结:从Elmo到GPT,再到Bert
词向量历史概述 提到NLP,总离开不了词向量,也就是我们经常说的embedding,因为我们需要把文字符号转化为模型输入可接受的数字向量,进而输入模型,完成训练任务.这就不得不说这个转化的历史了. 起 ...
- 莫烦nlp——词向量—CBOW
由于不是第一次接触,本文只摘录莫烦关于词向量的观点.更多的关注代码. 上一次系统学习莫烦教程已经一年半了,时间过得太快了. 转载:https://mofanpy.com/tutorials/machi ...
- NLP:词向量与ELMo模型笔记
目录: 基础部分回顾(词向量.语言模型) NLP的核心:学习不同语境下的语义表示 基于LSTM的词向量学习 深度学习中的层次表示以及Deep BI-LSTM ELMo模型 总结 1. 基础部分回顾(词 ...
- c语言例题功能作用,一篇C语言面试题的汇总
2015-03-21 06:30:02 阅读( 107 ) 1. 找错 void test1() { char string[10]; //string的长度应该设为11,要给"留出位 ...
- 数据分享|R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化...
全文链接:http://tecdat.cn/?p=22262 在讨论分类时,我们经常分析二维数据(一个自变量,一个因变量)(点击文末"阅读原文"获取完整代码数据). 但在实际生活中 ...
- 深度学习与自然语言处理教程(1) - 词向量、SVD分解与Word2Vec(NLP通关指南·完结)
作者:韩信子@ShowMeAI 教程地址:https://www.showmeai.tech/tutorials/36 本文地址:https://www.showmeai.tech/article-d ...
- NLP 利器 Gensim 来训练 word2vec 词向量模型的参数设置
使用 Gensim 来训练 word2vec 词向量模型的参数设置 文章目录 一.最小频次 min_count 二.词向量维度 size 三.并行处理核心数 workers 我们可以使用一些参数设置来 ...
- 自然语言处理(NLP)——词向量
一.Word Embedding概述 简单来说,词嵌入(Word Embedding)或者分布式向量(Distributional Vectors)是将自然语言表示的单词转换为计算机能够理解的向量或矩 ...
- Deep learning 词向量
这篇文章来自 beck_zhou的博客 以下文章转载于 http://blog.csdn.net/zhoubl668/article/details/23271225 Deep Learning 算法 ...
最新文章
- Confluence5.1 最新版的安装破解汉化
- 四:(之六_镜像发布)Dockerfile语法梳理和实践
- day22 time模块
- 万字长文 | 一文带你读懂账号体系
- 什么是方向图乘积定理_初中数学竞赛试题——正多边形与托勒密定理
- android UI
- 2017/3/8 函数指针/事件/委托....
- leetcode1247. 交换字符使得字符串相同(贪心)
- STM8学习笔记---union联合体的应用
- iptables官方文档
- 谷歌如何获取了我们的个人数据?
- 函数专题:sum、row_number、count、rank\dense_rank over
- Django视图与模板+vs2019
- 简单html源码_HTML 文本格式化
- 数据库中字段为CLOB的属性,在Java实体类中将CLOB转化为String
- MagicZoom bug-Strict Standards: Only variables should be assigned by reference Error
- LINUX编译alsa
- SPSS篇—方差分析
- ASO优化选词:三种方法教你精准定位关键词
- Something about ...